
2016年 第2卷 第2期
《工程(英文)》 >> 2016年 第2卷 第2期 doi: 10.1016/J.ENG.2016.02.008
大数据的分布式机器学习的策略与原则
School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA
下一篇 上一篇
摘要
大数据的发展已经引领了对能够学习包含数百万至数十亿参数的复杂模型的机器学习系统的新需求,以保证足够的能力来消化海量的数据集,提供强大的预测分析(如高维潜特征、中介表示和决策功能)。为了在这样的尺度上,在成百上千台的分布式机器集群中运行机器学习算法,关键往往是要投入显著的工程性的努力——有人可能会问,这样的工程是否还属于机器学习的研究领域?考虑到如此“大”的机器学习系统可以极大地从根植于机器学习的统计和算法的理解中受益——因此,机器学习的研究人员应该不会回避这样的系统设计——我们讨论了一系列从我们近来对工程尺度的机器学习解决方案的研究中提炼的原则和策略。这些原则和策略从机器学习的应用连续跨越到它的工程和理论研究,以及大型机器学习的系统和架构的发展,目标是了解如何使其有效、广泛地适用,并以收敛和缩放保证支持。它们关注的是机器学习研究传统上注意较少的四个关键问题:一个机器学习程序怎样能分布到一个集群中去?机器学习计算怎样能通过机器间的交流连接起来?这样的交流是如何被执行的?机器间应该交流的内容是什么?通过揭示机器学习程序所独有的,而非常见于传统计算机程序中的基础性的统计和算法上的特点,并通过剖析成功案例,以揭示我们如何利用这些原则来同时设计和开发高性能的分布式机器学习软件以及通用的机器学习框架,我们为机器学习的研究人员和从业者提供了进一步塑造并扩大机器学习与系统之间的领域的机会。
图片
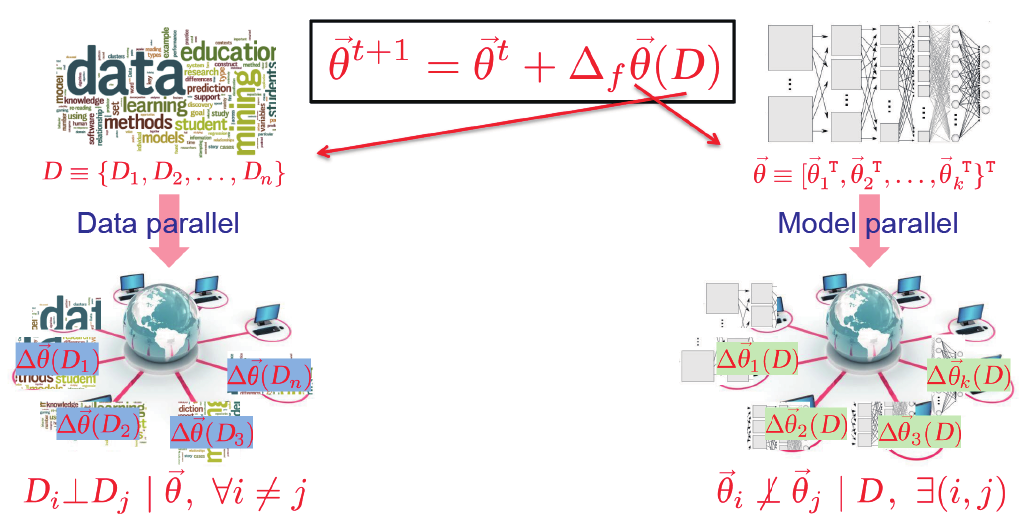
图1
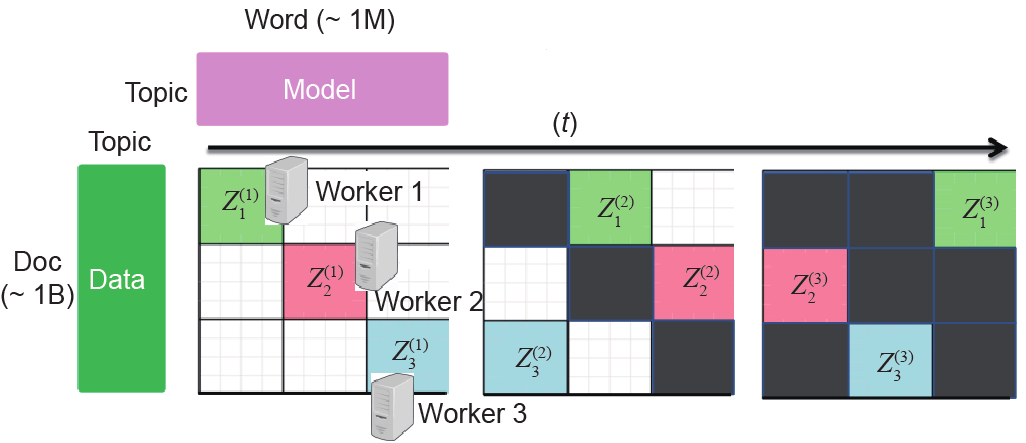
图2
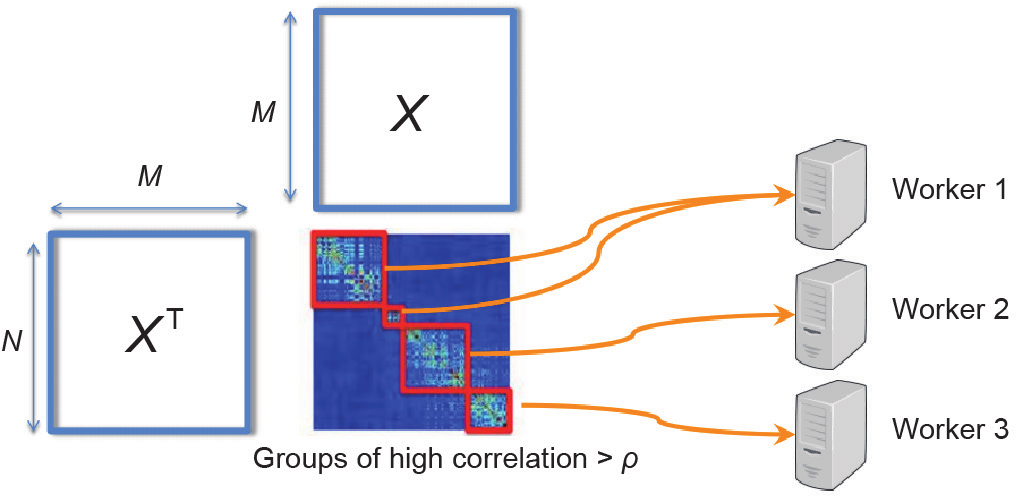
图3
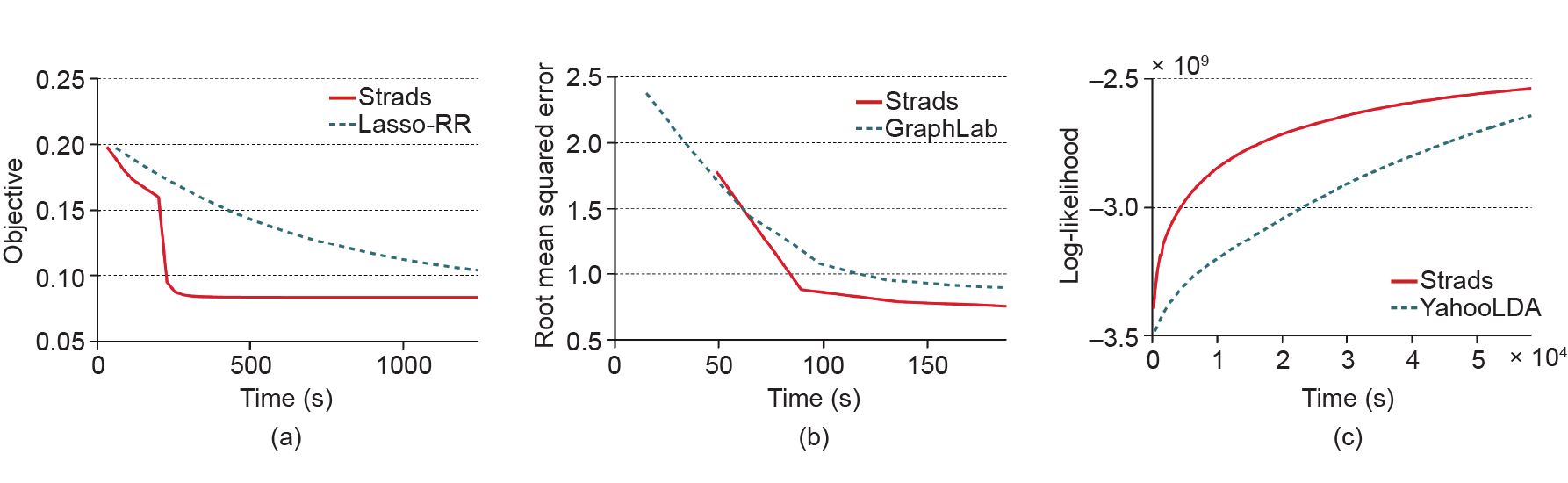
图4
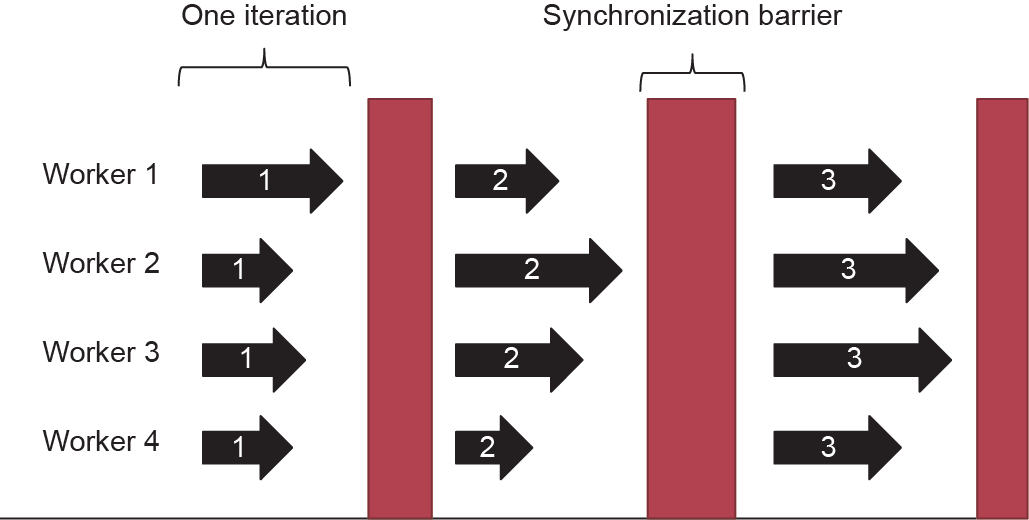
图5
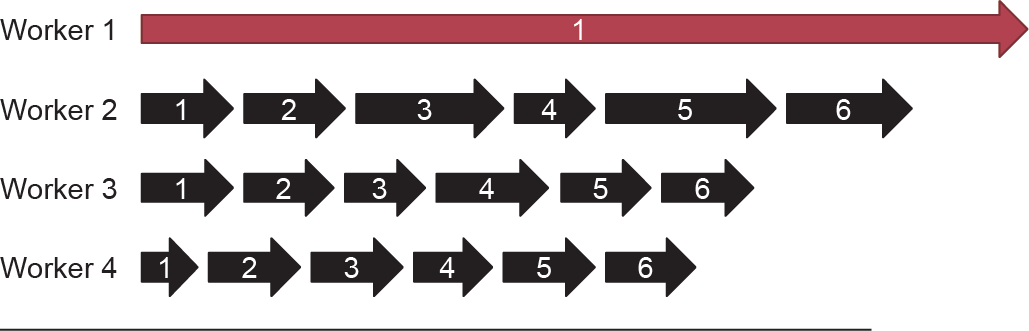
图6
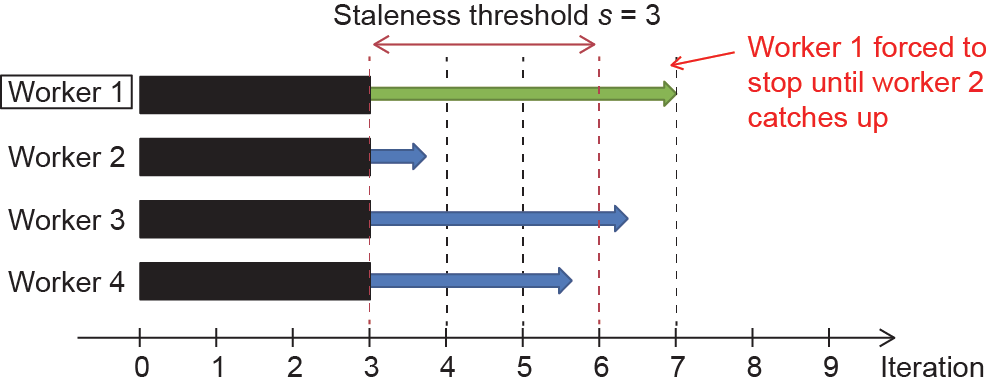
图7
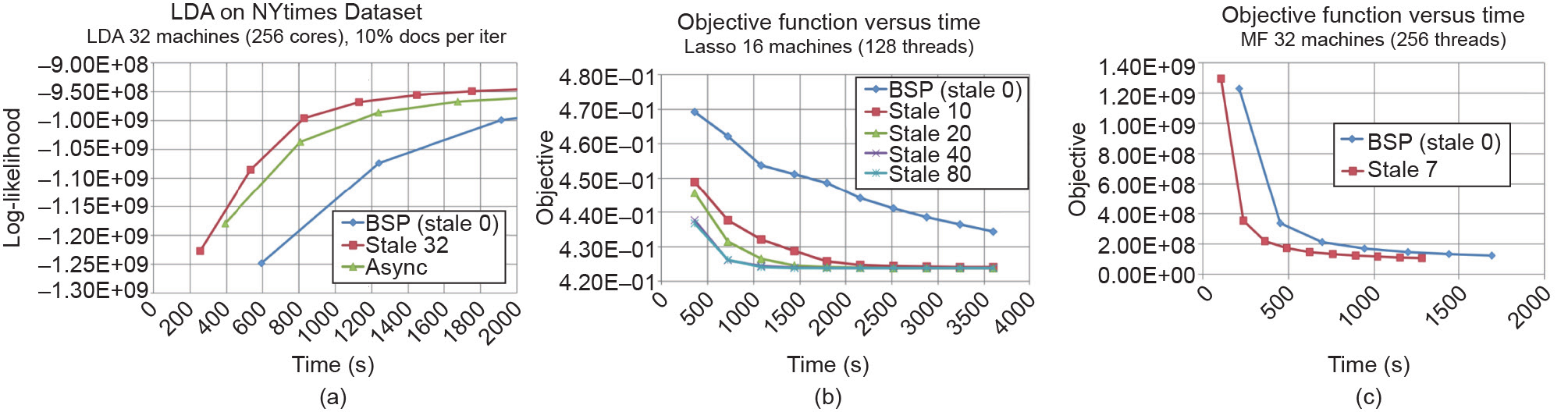
图8
图9
图10
图11
图12
图13
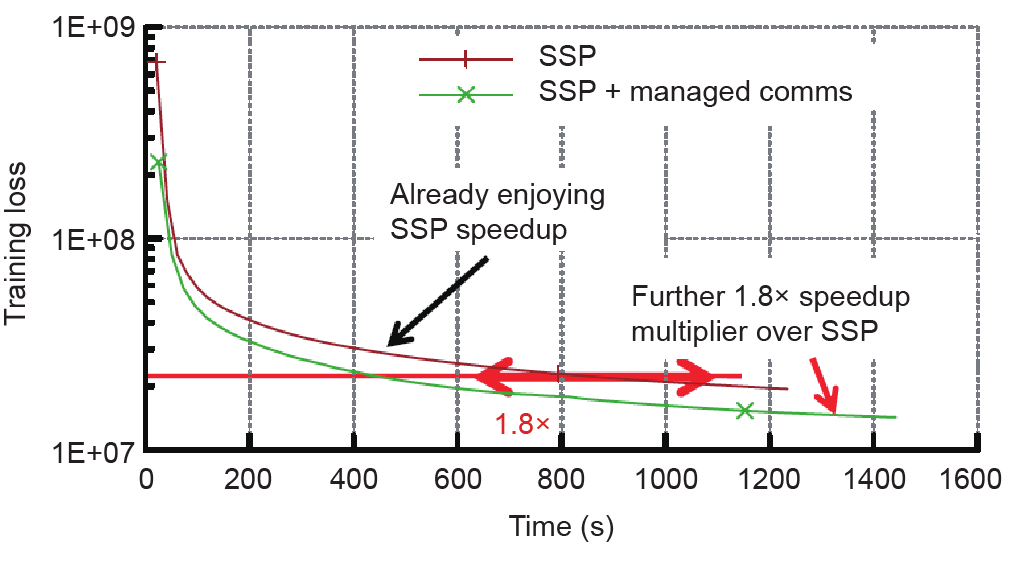
图14
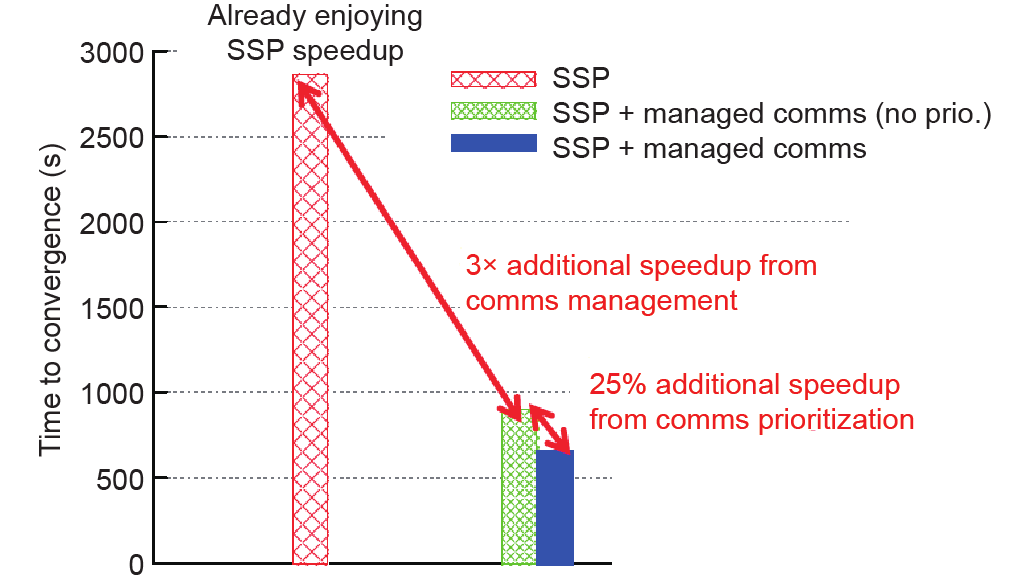
图15
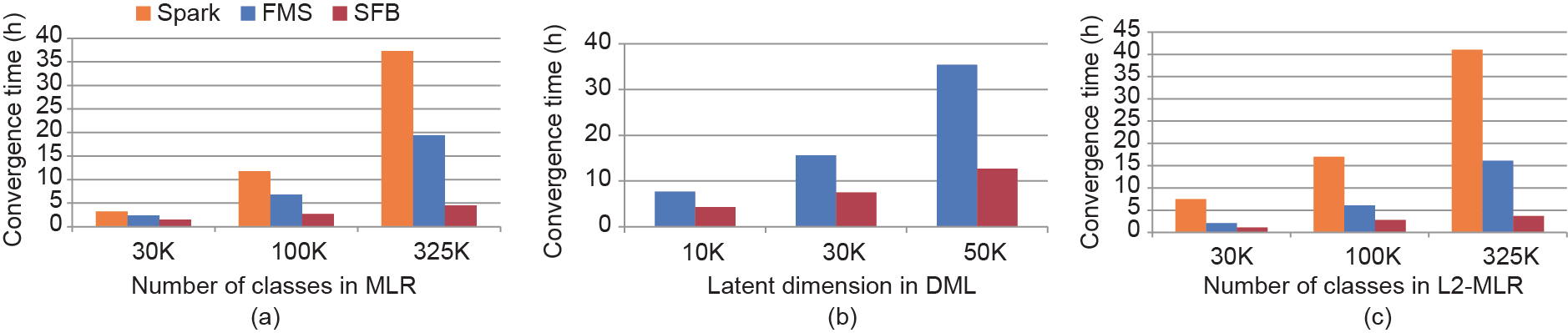
图16
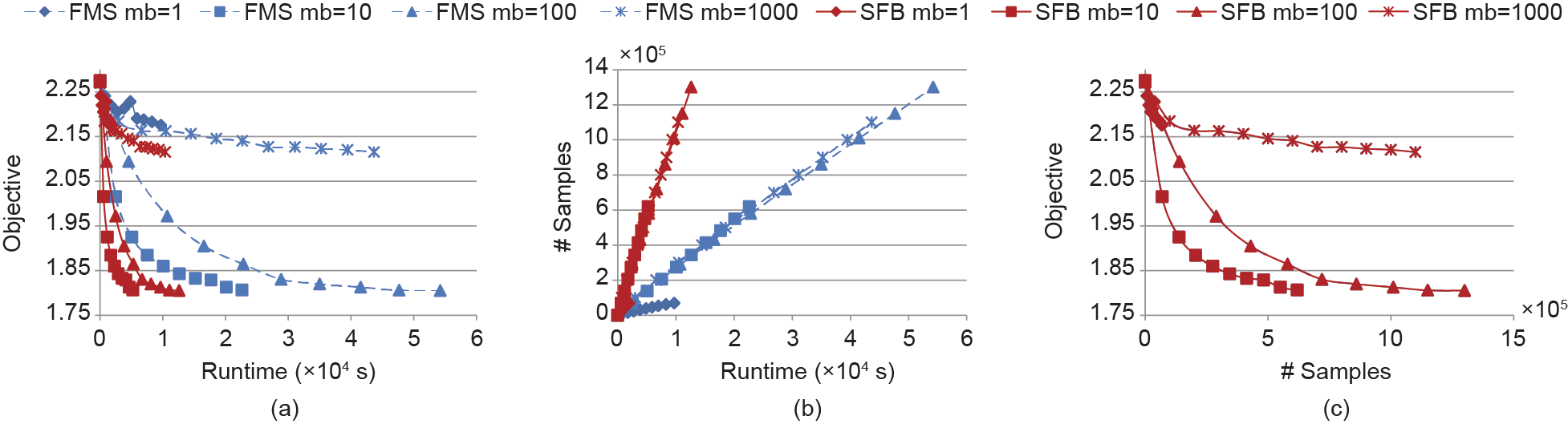
图17
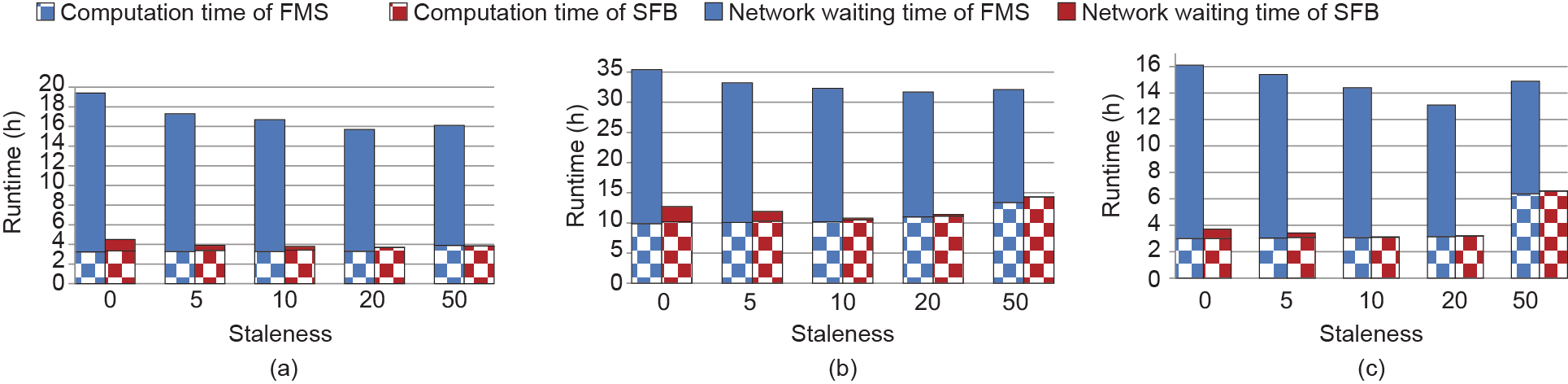
图18
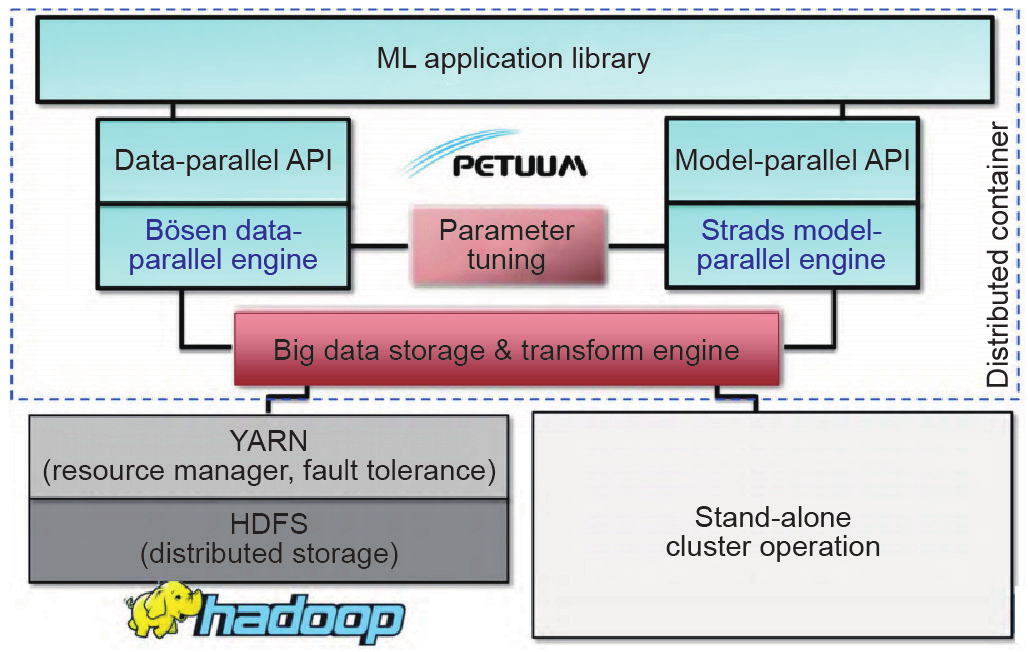
图19
参考文献
[ 1 ] Airoldi EM, Blei DM, Fienberg SE, Xing EP. Mixed membership stochastic blockmodels. J Mach Learn Res 2008;9:1981–2014.
[ 2 ]
Ahmed A, Ho Q, Eisenstein J, Xing EP, Smola AJ, Teo CH. Unified analysis of streaming news. In: Proceedings of the 20th International Conference on World Wide Web;
[ 3 ]
Zhao B, Xing EP. Quasi real-time summarization for consumer videos. In:?Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR);
[ 4 ] Lee S, Xing EP. Leveraging input and output structures for joint mapping of epistatic and marginal eQTLs. Bioinformatics 2012;28(12):i137–46. 链接1
[ 5 ] Thrun S, Montemerlo M, Dahlkamp H, Stavens D, Aron A, Diebel J, . Stanley: the robot that won the DARPA Grand Challenge. J Field Robot 2006;23(9):661–92. 链接1
[ 6 ] Chandola V, Banerjee A, Kumar V. Anomaly detection: a survey. ACM Comput Surv 2009;41(3):15:1–15:58.
[ 7 ] Wainwright MJ, Jordan MI. Graphical models, exponential families, and variational inference. Hanover: Now Publishers Inc.; 2008.
[ 8 ] Koller D, Friedman N. Probabilistic graphical models: principles and techniques. Cambridge: MIT Press; 2009.
[ 9 ]
Xing EP. Probabilistic graphical models [Internet]. [
[10] Zhu J, Xing EP. Maximum entropy discrimination markov networks. J Mach Learn Res 2009;10:2531–69.
[11]
Zhu J, Ahmed A, Xing EP. MedLDA: maximum margin supervised topic models for regression and classication. In: Proceedings of the 26th Annual International Conference on Machine Learning;
[12] Zhu J, Chen N, Xing EP. Bayesian inference with posterior regularization and applications to innite latent SVMs. J Mach Learn Res 2014;15(1):1799–847.
[13]
Griffiths TL, Ghahramani Z. Infinite latent feature models and the Indian buffet process. In: Weiss Y, Schölkopf B, Platt JC, editors Proceedings of the Neural Information Processing Systems 2005;
[14] Teh YW, Jordan MI, Beal MJ, Blei DM. Hierarchical dirichlet processes. J Am Stat Assoc 2006;101(476):1566–81. 链接1
[15] Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. J R Stat Soc B 2006;68(1):49–67. 链接1
[16] Kim S, Xing EP. Tree-guided group lasso for multi-response regression with structured sparsity, with applications to eQTL mapping. Ann Appl Stat 2012;6(3):1095–117. 链接1
[17] Burges CJC. A tutorial on support vector machines for pattern recognition. Wires Data Min Knowl 1998;2(2):121–67. 链接1
[18]
Taskar B, Guestrin C, Koller D. Max-margin Markov networks. In: Thrun S, Saul LK, Schölkopf B, editors Proceedings of the Neural Information Processing Systems 2003;
[19] Hinton G, Deng L, Yu D, Dahl GE, Mohamed A, Jaitly N, . Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Proc Mag 2012;29(6):82–97.
[20]
Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2012;
[21] Lee DD, Seung HS. Learning the parts of objects by non-negative matrix factorization. Nature 1999;401(6755):788–91. 链接1
[22]
Salakhutdinov R, Mnih A. Probabilistic matrix factorization. In: Platt JC, Koller D, Singer Y, Roweis ST, editors Proceedings of the Neural Information Processing Systems 2007;
[23] Olshausen BA, Field DJ. Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision Res 1997;37(23):3311–25.
[24]
Lee H, Battle A, Raina R, Ng AY. Efficient sparse coding algorithms. In: Schölkopf B, Platt JC, Hoffman T, editors Proceedings of the Neural Information Processing Systems 2006;
[25] Zheng X, Kim JK, Ho Q, Xing EP. Model-parallel inference for big topic models. 2014. Eprint arXiv:1411.2305.
[26] Yuan J, Gao F, Ho Q, Dai W, Wei J, Zheng X, . LightLDA: big topic models on modest compute clusters. 2014. Eprint arXiv:1412.1576.
[27]
Coates A, Huval B, Wang T, Wu DJ, Ng AY, Catanzaro B. Deep learning with COTS HPC systems. In: Proceedings of the 30th International Conference on Machine Learning;
[28]
Ahmed A, Aly M, Gonzalez J, Narayanamurthy S, Smola AJ. Scalable inference in latent variable models. In: Proceedings of the 5th International Conference on Web Search and Data Mining;
[29] Moritz P, Nishihara R, Stoica I, Jordan MI. SparkNet: training deep networks in spark. 2015. Eprint arXiv:1511.06051.
[30]
Agarwal A, Duchi JC. Distributed delayed stochastic optimization. In: Shawe-Taylor J, Zemel RS, Bartlett PL, Pereira F, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2011;
[31]
Niu F, Recht B, Re C, Wright SJ. HOGWILD!: a lock-free approach to parallelizing stochastic gradient descent. In: Shawe-Taylor J, Zemel RS, Bartlett PL, Pereira F, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2011;
[32] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters. Commun ACM 2008;51(1):107–13.
[33]
Gonzalez JE, Low Y, Gu H, Bickson D, Guestrin C. PowerGraph: distributed graph-parallel computation on natural graphs. In: Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation;
[34]
Zaharia M, Chowdhury M, Das T, Dave A, Ma J, McCauley M, . Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation;
[35] Xing EP, Ho Q, Dai W, Kim JK, Wei J, Lee S, . Petuum: a new platform for distributed machine learning on big data. IEEE Trans Big Data 2015;1(2):49–67. 链接1
[36]
Li M, Andersen DG, Park JW, Smola AJ, Ahmed A, Josifovski V, . Scaling distributed machine learning with the parameter server. In: Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation;
[37]
Ho Q, Cipar J, Cui H, Kim JK, Lee S, Gibbons PB, . More effective distributed ML via a stale synchronous parallel parameter server. In: Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2013;
[38]
Kumar A, Beutel A, Ho Q, Xing EP. Fugue: slow-worker-agnostic distributed learning for big models on big data. In: Kaski S, Corander J, editors Proceedings of the 17th International Conference on Artificial Intelligence and Statistics (AISTATS) 2014;
[39]
Lee S, Kim JK, Zheng X, Ho Q, Gibson GA, Xing EP. On model parallelization and scheduling strategies for distributed machine learning. In: Ghahramani Z, Welling M, Cortes C, Lawrence ND, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2014;
[40]
Dai W, Kumar A, Wei J, Ho Q, Gibson G, Xing EP. High-performance distributed ML at scale through parameter server consistency models. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence;
[41]
Wei J, Dai W, Qiao A, Ho Q, Cui H, Ganger GR, . Managed communication and consistency for fast data-parallel iterative analytics. In: Proceedings of the 6th ACM Symposium on Cloud Computing;
[42]
Bottou L. Large-scale machine learning with stochastic gradient descent. In: Lechevallier Y, Saporta G, editors Proceedings of COMPSTAT’2010;
[43]
Zhou Y, Yu Y, Dai W, Liang Y, Xing EP. On convergence of model parallel proximal gradient algorithm for stale synchronous parallel system. In: Gretton A, Robert CC, editors Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS) 2016;
[44] Fercoq O, Richtárik P. Accelerated, parallel and proximal coordinate descent. SIAM J Optim 2013;25(4):1997–2023.
[45] Gilks WR. Markov Chain Monte Carlo. In: Encyclopedia of biostatistics. 2nd ed. New York: John Wiley and Sons, Inc., 2005.
[46] Tibshirani R. Regression shrinkage and selection via the lasso. J R Statist Soc B 1996;58(1):267–88.
[47] Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. J Mach Learn Res 2003;3:993–1022.
[48]
Yao L, Mimno DM, McCallum A. Effcient methods for topic model inference on streaming document collections. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining;
[49]
Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters. In: Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation—Volume 6;
[50]
Zhang T. Solving large scale linear prediction problems using stochastic gradient descent algorithms. In: Proceedings of the 21st International Conference on Machine Learning;
[51]
Gemulla R., Nijkamp E, Haas PJ, Sismanis Y. Large-scale matrix factorization with distributed stochastic gradient descent. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining;
[52]
Dean J, Corrado G, Monga R, Chen K, Devin M, Mao M, . Large scale distributed deep networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2012;
[53]
Low Y, Gonzalez J, Kyrola A, Bickson D, Guestrin C, Hellerstein JM. GraphLab: a new framework for parallel machine learning. In: Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence (UAI 2010);
[54] Hinton GE, Salakhutdinov RR. Reducing the dimensionality of data with neural networks. Science 2006;313(5786):504–7. 链接1
[55] Xie P, Kim JK, Zhou Y, Ho Q, Kumar A, Yu Y, . Distributed machine learning via sufficient factor broadcasting. 2015. Eprint arXiv:1409.5705.
[56] Zhang H, Hu Z, Wei J, Xie P, Kim G, Ho Q, . Poseidon: a system architecture for effcient GPU-based deep learning on multiple machines. 2015. Eprint arXiv:1512.06216.
[57]
Bradley JK, Kyrola A, Bickson D, Guestrin C. Parallel coordinate descent for L1-regularized loss minimization. In: Proceedings of the 28th International Conference on Machine Learning;
[58]
Scherrer C, Tewari A, Halappanavar M, Haglin D. Feature clustering for accelerating parallel coordinate descent. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2012;
[59]
Low Y, Gonzalez J, Kyrola A, Bickson D, Guestrin C, Hellerstein JM. Distributed GraphLab: a framework for machine learning and data mining in the cloud. In: Proceedings of the VLDB Endowment;
[60]
Chilimbi T, Suzue Y, Apacible J, Kalyanaraman K. Project Adam: building an efficient and scalable deep learning training system. In: Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation;
[61] Valiant LG. A bridging model for parallel computation. Commun ACM 1990;33(8):103–11.
[62] McColl WF. Bulk synchronous parallel computing. In: Davy JR, Dew PM, editors Abstract machine models for highly parallel computers. Oxford: Oxford University Press; 1995. p. 41–63.
[63]
Malewicz G, Austern MH, Bik AJC, Dehnert JC, Horn I, Leiser N, . Pregel: a system for large-scale graph processing. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data; 2
[64] Terry D. Replicated data consistency explained through baseball. Commun ACM 2013;56(12):82–9.
[65]
Li H, Kadav A, Kruus E, Ungureanu C. MALT: distributed data-parallelism for existing ML applications. In: Proceedings of the 10th European Conference on Computer Systems;
[66]
[66]Xing EP, Jordan MI, Russell SJ, Ng AY. Distance metric learning with application to clustering with side-information. In: Becker S, Thrun S, Obermayer K, editors Proceedings of the Neural Information Processing Systems 2002;
[67] Partalas I, Kosmopoulos A, Baskiotis N, Artieres T, Paliouras G, Gaussier E, . LSHTC: A benchmark for large-scale text classification. 2015. Eprint arXiv:1503.08581.
[68]
Hsieh CJ, Chang KW, Lin CJ, Sathiya Keerthi S, Sundararajan S. A dual coordinate descent method for large-scale linear SVM. In: Proceedings of the 25th International Conference on Machine Learning;
[69] Shalev-Shwartz S, Zhang T. Stochastic dual coordinate ascent methods for regularized loss. J Mach Learn Res 2013;14(1):567–99.
[70]
Yang T. Trading computation for communication: distributed stochastic dual coordinate ascent. In: Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2013;
[71]
Jaggi M, Smith V, Takac M, Terhorst J, Krishnan S, Hofmann T, . Communication-efficient distributed dual coordinate ascent. In: Ghahramani Z, Welling M, Cortes C, Lawrence ND, Weinberger KQ, editors Proceedings of the Neural Information Processing Systems 2014;
[72]
Hsieh CJ, Yu HF, Dhillon IS. PASSCoDe: parallel asynchronous stochastic dual co-ordinate descent. In: Bach F, Blei D, editors Proceedings of the 32nd International Conference on Machine Learning;











 京公网安备 11010502051620号
京公网安备 11010502051620号




