
《1 引言》
1 引言
在决策过程中, 通常都会面对若干不确定性因素。为了做出合理决策、采取最佳行动方案, 决策者需要收集这些不确定性因素的相关信息, 以消除不确定性。如果所收集的信息在一定程度上消除了不确定性, 但并没有完全消除不确定性, 则为不完全信息 (imperfect information) , 此种情况下的决策为风险性决策。如果所收集的信息能够完全而确切地判断不确定因素的状态, 则为完全信息 (perfect information) , 此种情况下的决策为确定性决策。
在实际决策过程中, 决策者所面临的绝大部分都是风险性决策。由于根据完全信息, 决策者可以确定绝对最优行动方案, 但是, 信息的收集又需要消耗资源如花费一定的时间、投入相当的人力、耗费相当的财力等, 因此, 在决策前, 决策者通常还面临一个信息收集的问题。信息收集是否值得, 是否进行信息收集工作, 需要选定一个标准量作为参照。将信息收集工作量 (含时间、人力、物力、财力等) 全部折算为费用, 那么信息收集费用绝对不能高于信息价值。因此, 信息价值的计算对于决策具有重要的意义。
传统的决策分析中, 完全信息价值的计算常采用翻转决策树法, 但是这种方法可能会遗漏某些情景, 用影响图则可以避免这个问题。但是, 影响图中的Howard正则型定义还存在问题, 这也影响了完全信息价值影响法的正确求解
《2 完全信息价值的定义及数学表述》
2 完全信息价值的定义及数学表述
完全信息价值 (VPI, value of perfect information) , 即针对一个随机事件, 拥有此随机事件的完全信息时的最大期望值 (即完全信息期望值, EVPI, expected value with perfect information) 与未拥有此随机事件完全信息时的最大期望值之差。不完全信息价值 (VII, value of imperfect information) , 即针对一个随机变量, 若所收集的信息为不完全信息, 则在拥有不完全信息后的最大期望值 (即不完全信息期望值, EVII, expected value with imperfect information) 与未拥有此不完全信息时的最大期望值之差。
完全信息价值可用数学表述。设决策者的行动方案集为D{d1, d2, …, dm}, 影响行动方案选择随机变量为C{c1, c2, …, cn}, 与随机变量ci对应的状态集合为Si{s1, s2, …, sp}。对于ci的状态Si, 决策者根据现有信息可确定其概率分布为pi (Si) , 若采取行动方案dj, 则其收益值为r (Si, dj) , 期望收益值为E[r (Si, dj) ]。采取行动方案d (Si) 时, 可获得最大期望收益值为
如果花费Mi (Si) 费用可以收集到cx状态的完全信息, 此时ci的确定状态为Si, 采取行动方案d (Si) 时可获得最大期望收益值, 即
则ci状态的完全信息价值为
由于收集该信息需要消耗费用Mi (Si) , 因此, ci状态的完全信息净价值 (NVPI, net value of perfect information) 为
若NVPISi为负, 则该随机变量的完全信息没有收集价值。对于该决策中的随机变量c1, c2, …, cn, NVPISi越大, 相对应ci的完全信息越有收集的必要。
《3 完全信息价值的翻转决策树法分析》
3 完全信息价值的翻转决策树法分析
完全信息价值概念来源于决策分析。完全信息价值一般是利用决策树求解
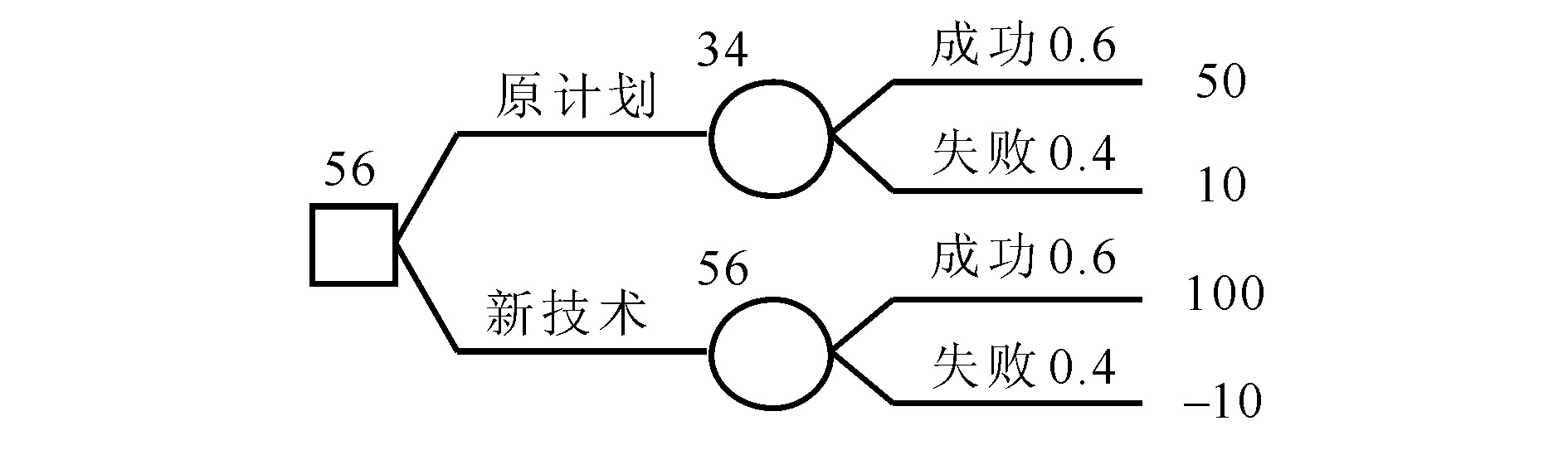
例1 某项目中仪表控制分析人员估计按原计划成功解决技术难题的概率为0.6, 失败概率为0.4, 成功解决的价值为50×104元, 失败则为10×104元。若采用新技术, 成功概率相同, 但价值为100×104元, 失败价值为-10×104元。决策者风险中性态度。
用决策树求解此问题的图示方法如图1所示。
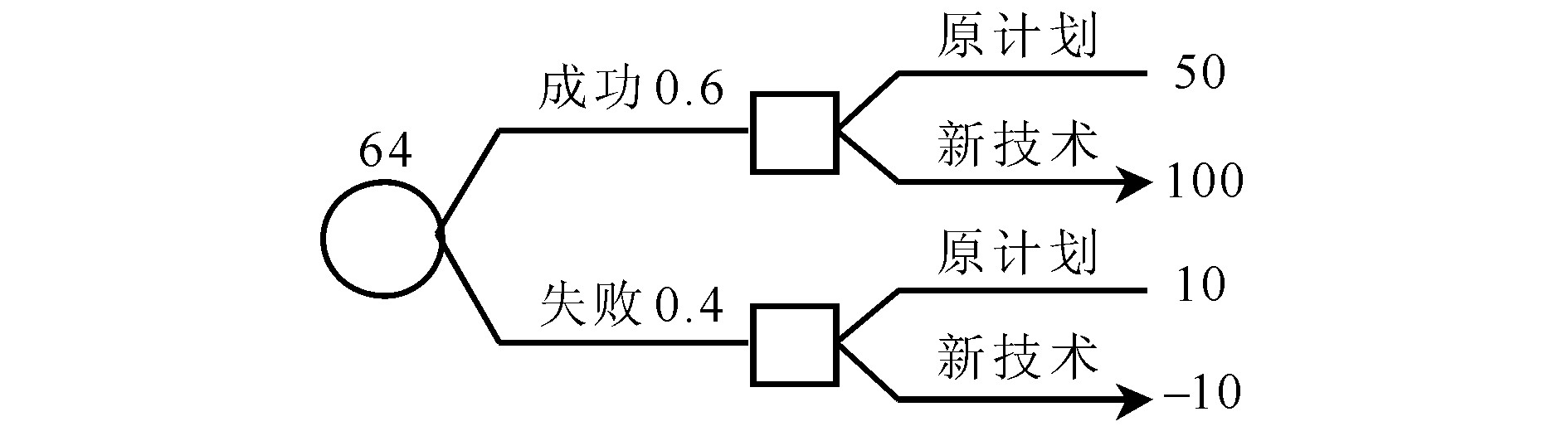
若将决策树中的随机变量节点移至树的最左边, 用图2的树来求解完全信息价值问题。
文献
实际上, 用翻转决策树法可以正确地计算出完全信息价值, 这在文献
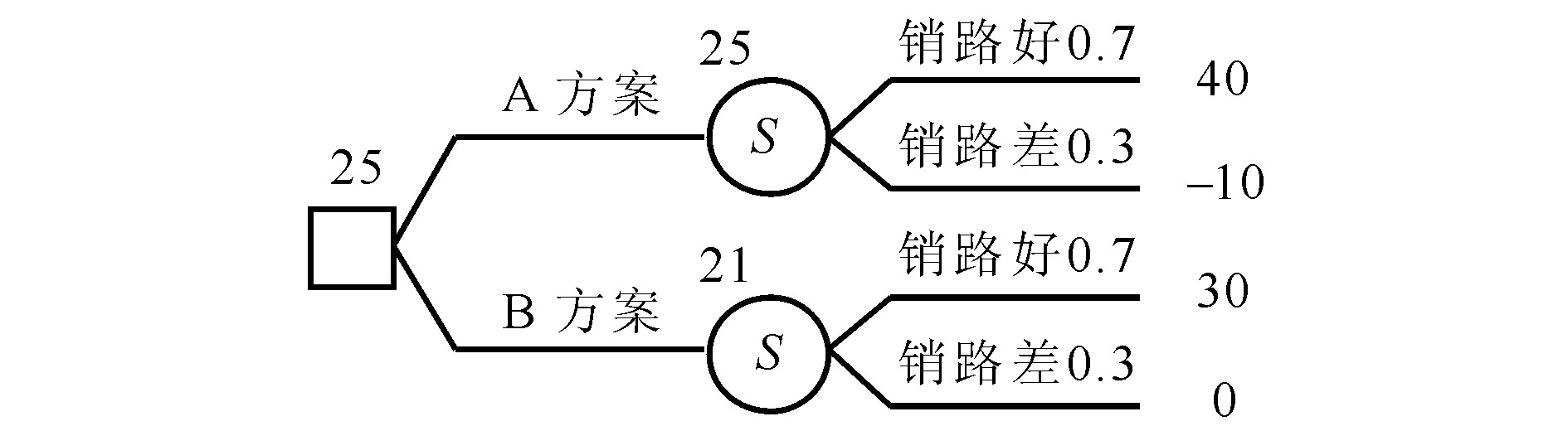
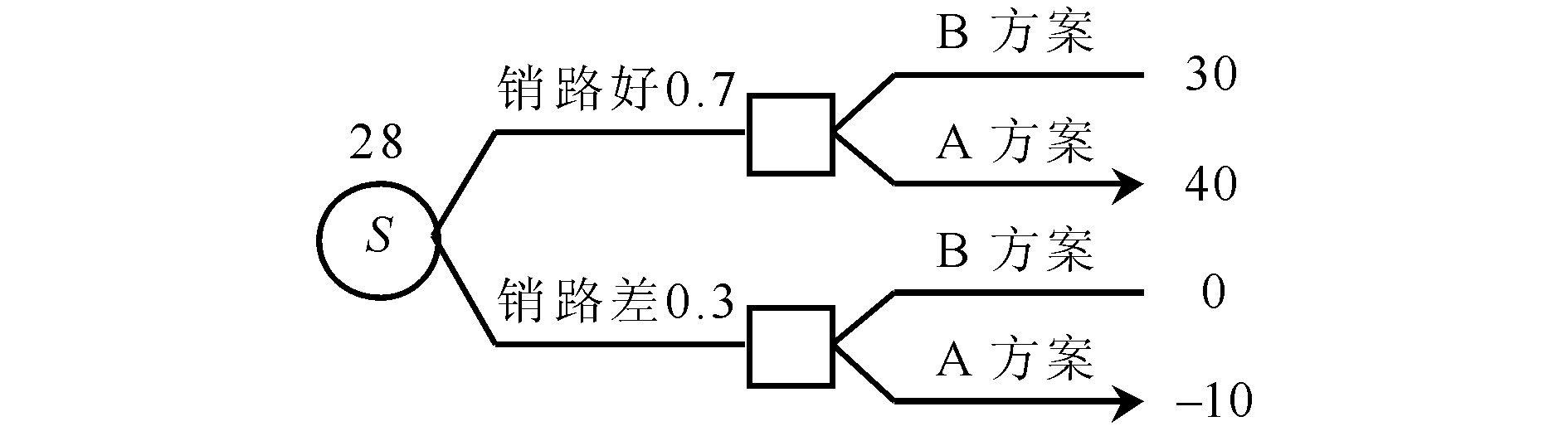
例2 据市场分析, 现有某种产品需求, 销路好的概率为0.7, 销路差的概率为0.3。某公司有两种方案可生产此种产品, 若实行方案A, 销路好, 可赢利40×104元, 销路差, 则损失10×104元;若实行方案B, 销路好, 可赢利30×104元, 销路差, 则无赢亏, 其决策树见图3, 翻转决策树的VPI求解法见图4。
例2中, 随机事件即销路S的完全信息价值 (VPIS) 为28-25=3 (×104元) 。因此, 如果有某种方式可以获得该销路好坏的完全信息, 为使NVPISi≥0即使得完全信息净价值非负, 为该方式所付出的费用不应超过3×104元。在例2中, 随机事件的发生概率 (销路好或销路差的概率) 与决策事件本身 (用方案A或方案B生产产品) 无关, 因此, 用翻转决策树法计算完全信息价值时不存在问题。而在例1中, 随机事件的发生概率 (成功或失败的概率) 与决策事件 (选用原计划或新技术) 相关, 因此, 若采用直接翻转决策树即将随机变量移到决策变量的左边, 会出现遗漏某些可能事件, 从而导致完全信息价值的计算出现偏差。
因此可得出结论:如果需要确定完全信息价值的随机事件发生概率与决策事件无关, 则可以直接用翻转决策树法求解完全信息价值。如果需要确定完全信息价值的随机事件发生概率与决策事件相关, 设随机事件有m种结局, 决策事件可有n种行动, 则翻转决策树后需引入mn个分枝;或用影响图法来确定随机事件的完全信息价值。
《4 完全信息价值的影响图求解法分析》
4 完全信息价值的影响图求解法分析
《4.1影响图的基本概念》
4.1影响图的基本概念
影响图 (ID, influence diagram) 由有向弧与储存了数据结构的结点集组成。影响图用G= (N, A) 表示, N是结点集, A是连接结点的有向弧集, 即
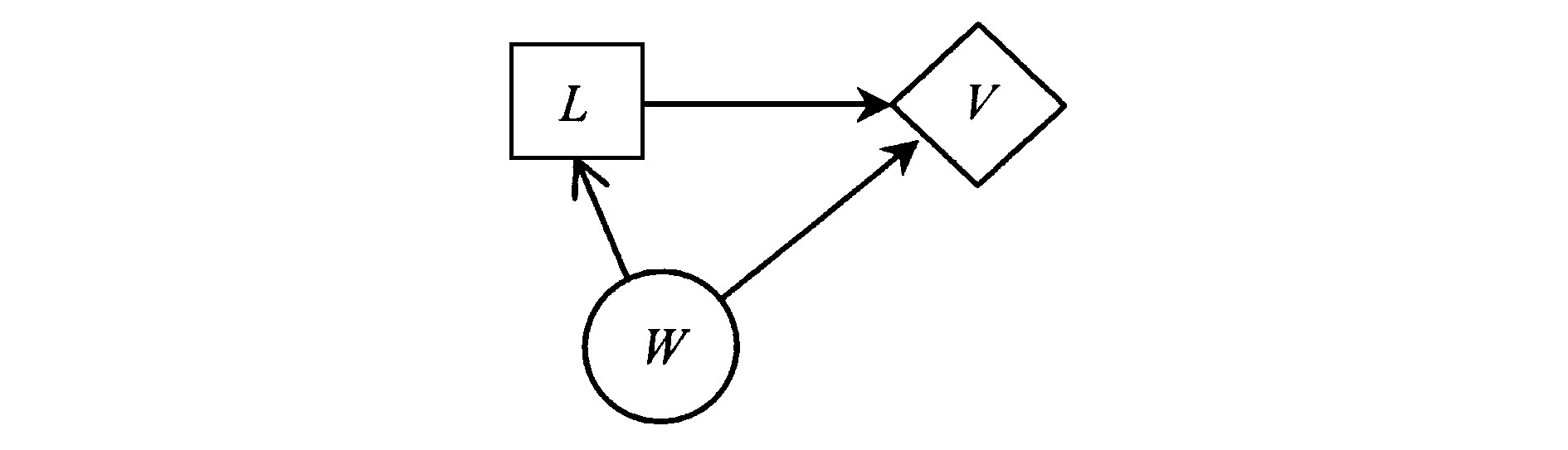
影响图中的结点集代表了决策事件、随机事件与决策者偏好。因此, 影响图中的结点可以分为3类, 即决策结点、机会结点与价值结点。决策结点代表决策者进行选择的状态。机会结点代表客观状态的不确定性。价值结点作为一种确定型机会结点, 代表了决策者的偏好。
影响图中不同结点间的弧向代表了概率相关、信息传递、因果关系与决策顺序等。自机会结点到机会结点或价值结点的弧为关联弧, 意味着2个结点之间存在概率相关性。进入决策结点的弧表明决策者在选择行动之前已经知道了连接箭尾结点的结果, 为信息弧。自决策结点到价值结点或机会结点的弧意味着结点之间存在因果关系, 为影响弧。自决策结点到决策结点的弧意味着2个决策结点之前存在着先后决策关系, 为勿忘弧。因此, 影响图直观而紧凑地显示了决策变量、机会状态与偏好之间的时序关系、信息关系以及概率关系。
影响图可用3个不同的层面表述问题, 即拓扑层、函数层和数值层。在拓扑层, 很多信息包含在图形结构中, 因为有向无环图不仅可以表述变量之间的概率相关性、因果关系、信息关系、决策时序关系, 还可直观显示进入结点的联合概率分布以及联合效用函数。
在函数层次, 影响图中, 每个结点 (除了价值结点外) 的条件概率分布为
其中pa (xi) 是结点xi的直接前序节点集合。
在数值层次, 概率分布、元情景分布 (atomic scenario distribution) 以及效用的数值细节都可储存在影响图的结点中。带情景的分布树可以表达出元分布的条件情景。每一个决策结点的分布树描述了决策者在每一种条件情景下的可选方案分布。每一个机会结点分布树表达了联合概率分布。价值结点的分布树显示了联合效用函数。
《4.2完全信息价值的影响图求解法分析》
4.2完全信息价值的影响图求解法分析
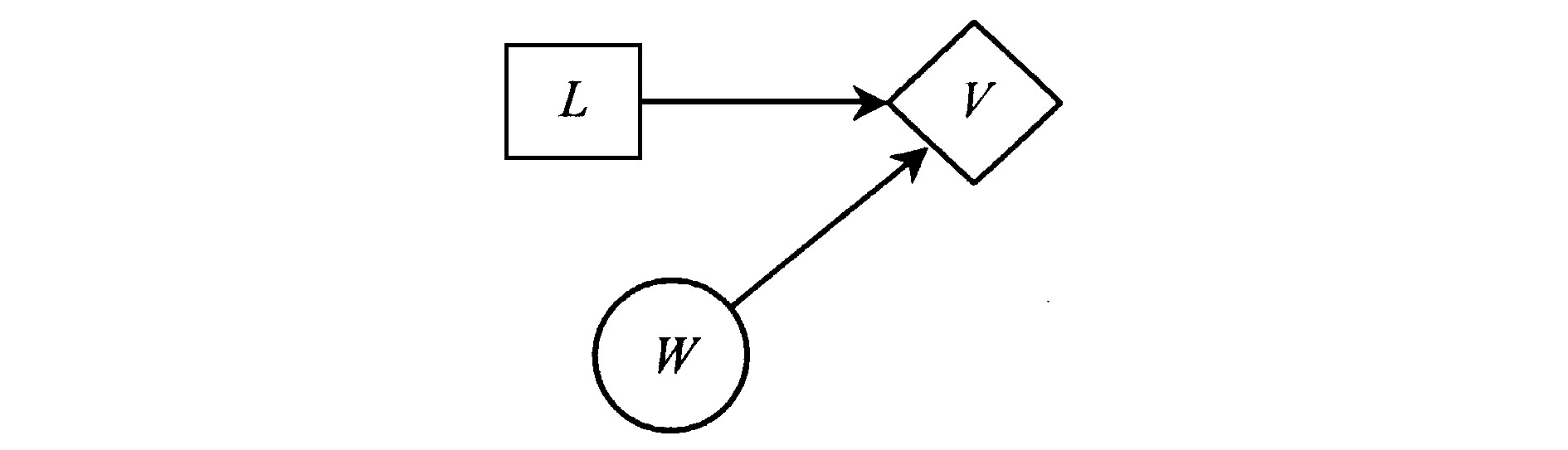
如果给出了某问题的影响图, 要求求解某随机事件的完全信息价值, 也就是说, 需要求解给出随机事件确切情况后, 对决策产生了影响从而引起的期望值变化。而在影响图中, 自机会结点指向决策结点的弧为信息弧, 它表明随机事件为决策事件提供了信息。因此, 根据影响图理论, 完全信息价值的计算在影响图中可以简单而直观地描述:添加自随机事件至决策事件的箭线, 得到新影响图;新影响图中的期望值与原影响图中的期望值之差, 为该随机事件的完全信息价值。这个计算完全信息价值的影响图法的理念简单明了, 但是在应用中会存在一些问题。
文献
定义1 Howard正则型 在一个构造完好的影响图中, 如果机会结点的直接前序结点中无决策结点, 则为Howard正则型影响图。
将非Howard正则型影响图转化为正则Howard型影响图。其具体作法:针对需要确定完全信息价值的随机事件, 引入一个假想的洞察者 (假设他可以确切预报随机事件) ;由洞察者预报的事件, 引出一组不受决策者影响的新事件, 以取代决策结点对机会结点的影响, 并且避免由机会结点向决策结点引信息弧线产生环路。
计算改造后的Howard正则型影响图中的期望值与原影响图中的期望值之差, 则为该随机事件的完全信息价值。
文献
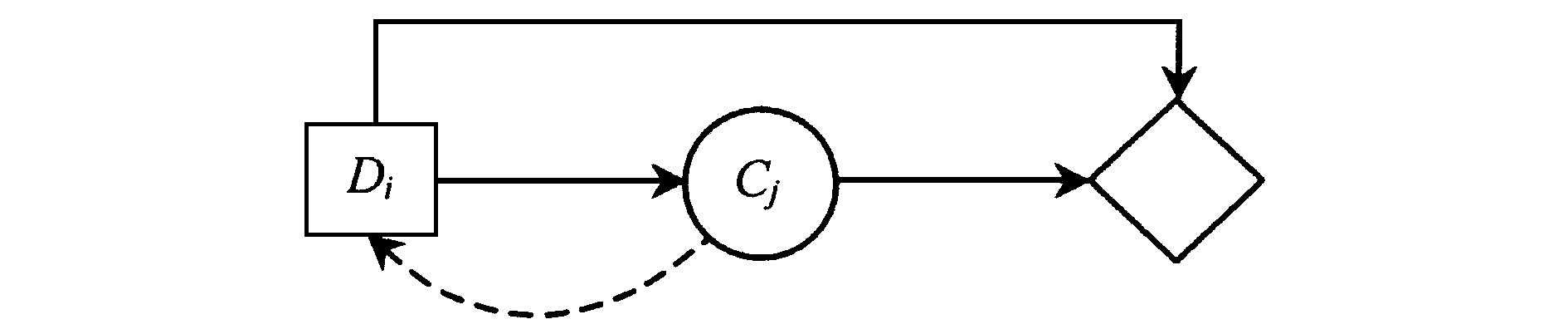
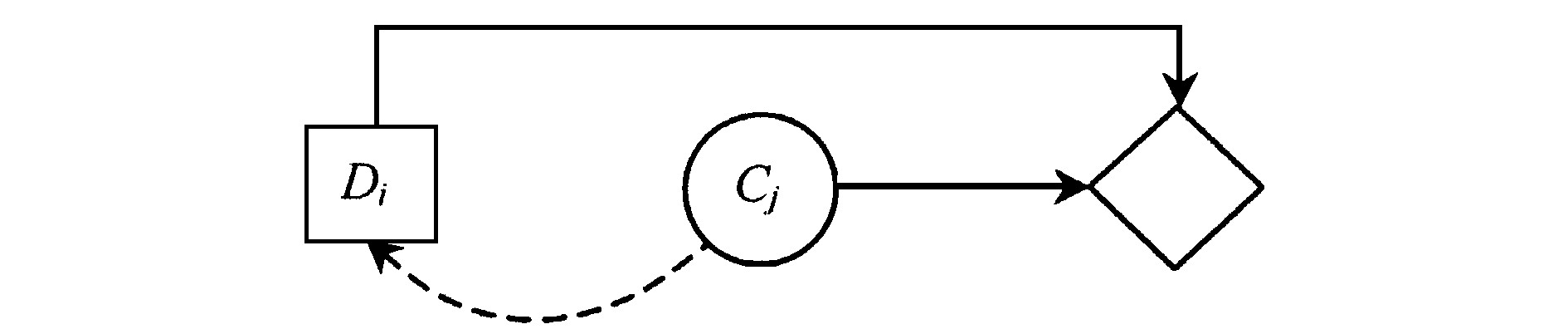
定理1 如果决策结点Di是需要确定完全信息价值的机会结点Cj的前序结点, 则添加自机会结点Cj至决策结点Di的信息弧将产生环路。
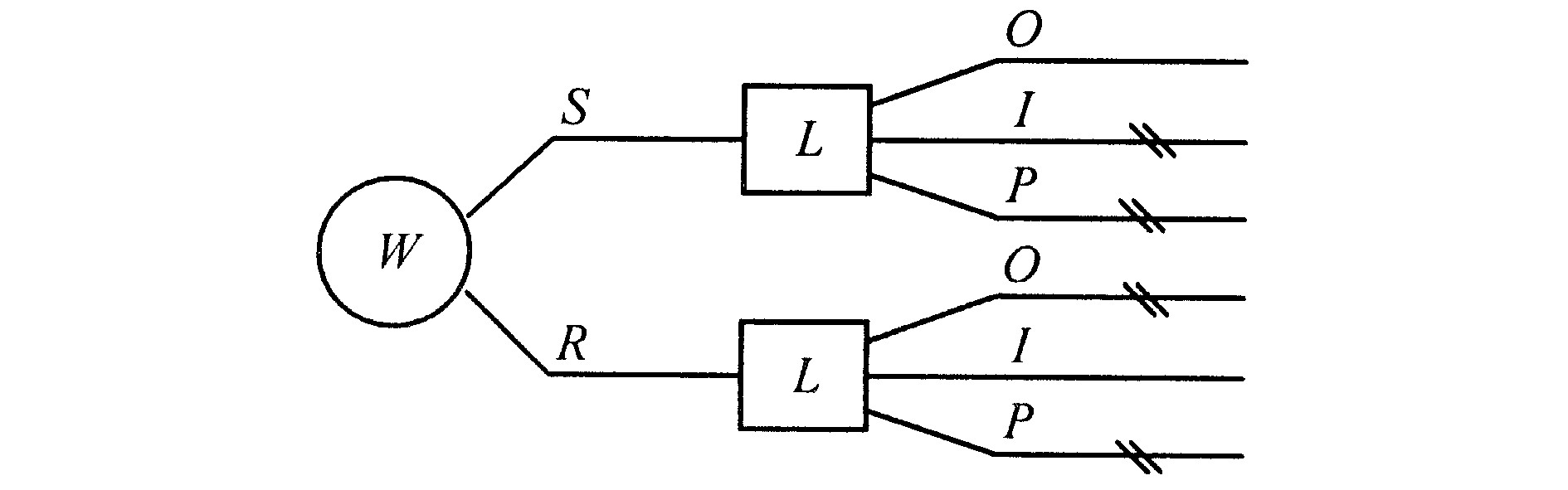
证明 若决策结点Di是机会结点Cj的直接前序结点, 说明有自决策结点至机会结点的影响弧, 若再添加自机会结点Cj至决策结点Di的信息弧, 必将形成环路, 如图5所示。
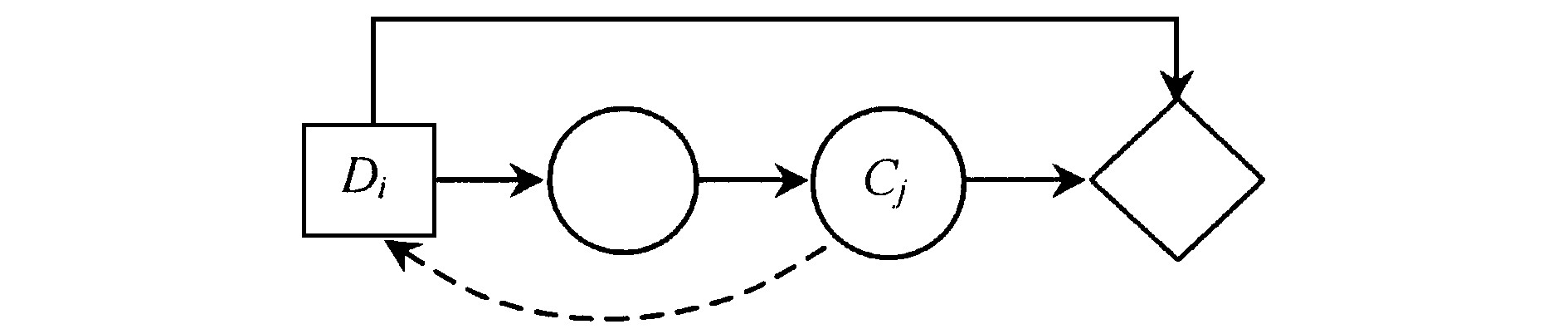
若决策结点Di是机会结点Cj的间接前序结点, 则必存在至少一条连续的有向路径, 自Di可以到达Cj。为计算完全信息价值, 当直接引入自Cj到Di的有向弧时, 则在新影响图中至少构成一个环。如图6所示。
此外, Howard正则型是针对某个随机事件而言的。因此, Howard正则型定义应该修正。
定义2 修正的Howard正则型 在一个构造完好的影响图中, 如果某机会结点Cj的前序结点 (含间接前序结点与直接前序结点) 中无决策结点, 则该影响图为机会结点Cj的Howard正则型影响图。
也就是说, 在机会结点Cj的Howard正则型影响图 (以此处及以下的分析中, Howard正则型影响图均是指定义经过本文修正的) 中, 决策结点可以是其他机会结点的前序结点。
完全信息价值的影响图求解法总结如下:
对于Howard正则型, 即需确定完全信息价值的机会结点Cj的前序结点中无决策结点, 如图7所示, 则可以直接添加自随机结点至决策结点的信息弧 (虚线即为添加的信息弧) , 这表明, 随机事件的状态为决策事件提供了信息, 该信息进而会对期望值产生影响, 那么期望值所发生的变化则为该随机事件的完全信息价值。
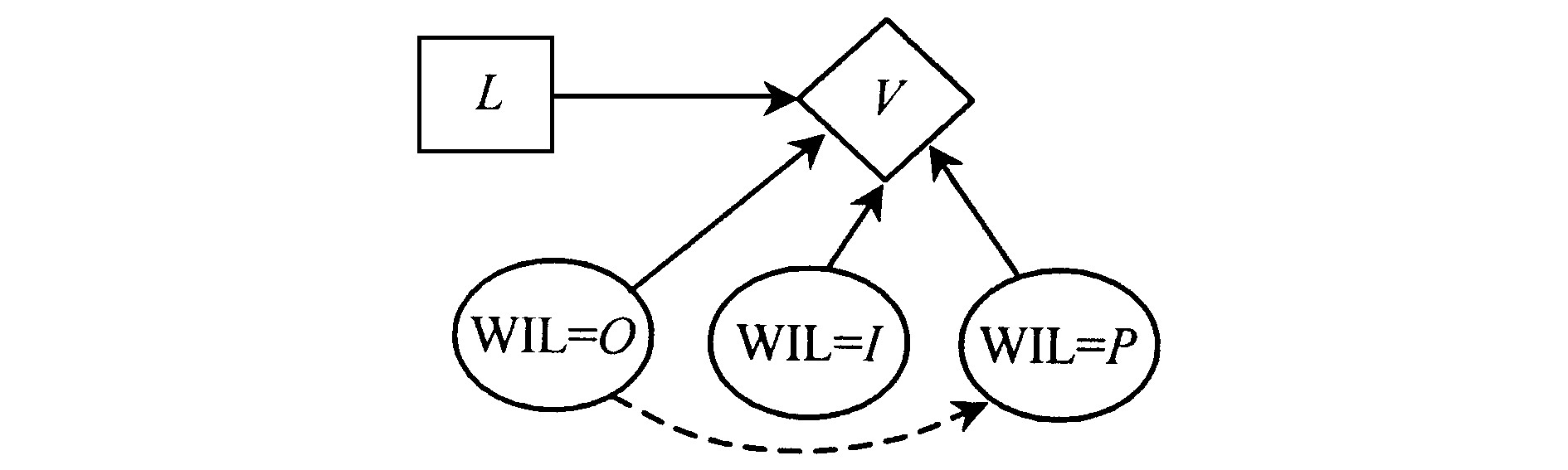
对于非Howard正则型, 如果直接添加自随机事件至决策事件的箭线则会导致一个严重的问题, 问题来自影响图中需要绝对避免产生环路的特性。因此, 必须将非Howard正则型转化Howard正则型, 转化思路为:自需确定完全信息价值的随机事件引出一组不受决策者影响的新事件, 这组新事件是针对每一种可能决策引进一个机会结点而构造的, 以取代决策结点对代表该随机事件的机会结点的影响, 则原机会结点转化为确定型结点;然后添加自新事件至决策事件的信息弧, 从而得到Howard正则型的新影响图。通过分析评估, 计算新影响图与原影响图中的期望值之差, 则为所求随机事件的完全信息价值。
《4.3完全信息价值的排序》
4.3完全信息价值的排序
文献
定理2 设G= (C, D, V, A) 是决策模型的影响图表示, A为影响图中的有向弧集, D为决策节点集, C为随机结点集, V为价值结点。X∈C和Y∈C是2个不相交的随机节点集, 如果X和Y不是D的后代, X∩Y=∅且Y⊥V⊥X, 即在已知X的情况下Y与V相互间独立, 则有下式成立:
根据此定理, 即可对影响图中随机变量的信息价值进行排序。在正则影响图中, 距离价值结点较远的随机结点相对于较近的随机结点而言, 完全信息价值要低。因此, 在考虑收集随机变量的进一步信息时, 应该考虑最靠近价值结点的随机结点。由于此定理要求影响图相对于随机结点X和Y而言是正则影响图, 因此, 在进行排序时, 需要进行非正则影响图向正则影响图的转换。
《5 完全信息价值计算举例》
5 完全信息价值计算举例
下面举例说明所提出的处理完全信息价值问题的影响图法。
例3 以文献
在文献
如上所述, 该晚会问题属于可以直接添加自随机结点至决策结点的箭线的情形, 不需要引入新事件, 如图10所示。对于图10, 价值结点的数据结构如图11所示。
新影响图10的期望值为88, 因此, 天气状况的完全信息价值为88-54=34。
《6 结论》
6 结论
完全信息价值对于决策分析有重要意义。它可以向决策者提供为减少不确定性而收集新信息适度耗费的尺度。通过对若干随机变量的完全信息价值进行排序, 还可判定哪个随机变量的新信息的收集价值更大。由于在影响图中, 随机事件的完全信息价值可以直观地表述, 计算方式也相对简洁明确;此外, 还可以通过影响图上变量间的拓扑关系而无须经过定量计算, 对完全信息价值的大小直接进行排序, 因此, 处理有关完全信息价值的问题时, 用影响图法比用翻转决策树法更加简便。











 京公网安备 11010502051620号
京公网安备 11010502051620号




