
2018年 第20卷 第4期
《中国工程科学》 >> 2018年 第20卷 第4期 doi: 10.15302/J-SSCAE-2018.04.017
群智进化理论及其在智能机器人中的应用
1. 北京深度奇点科技有限公司,北京100086;
2. 复旦大学智能机器人研究院,上海 200433
下一篇 上一篇
摘要
群体智能(CI)已经在过去的几十年里被广泛研究。最知名的CI算法就是蚁群算法(ACO),它被用来通过CI涌现解决复杂的路径搜索问题。最近,DeepMind发布的AlphaZero程序,通过从零开始的自我对弈强化学习,在围棋、国际象棋、将棋上都取得了超越人类的成绩。通过在五子棋上试验并实现AlphaZero系列程序,以及对蒙特卡洛树搜索(MCTS)和ACO两种算法的分析和比较,AlphaZero的成功原因被揭示,它不仅是因为深度神经网络和强化学习,而且是因为MCTS算法,该算法实质上是一种CI涌现算法。在上述研究基础上,本文提出了一个CI进化理论,并将其作为走向人工通用智能(AGI)的通用框架。该算法融合了深度学习、强化学习和CI算法的优势,使得单个智能体能够通过CI涌现进行高效且低成本的进化。此CI进化理论在智能机器人中有天然的应用。一个云端平台被开发出来帮助智能机器人进化其智能模型。作为这个概念的验证,一个焊接机器人的焊接参数优化智能模型已经在云端平台上实现。
图片

图 1

图 2
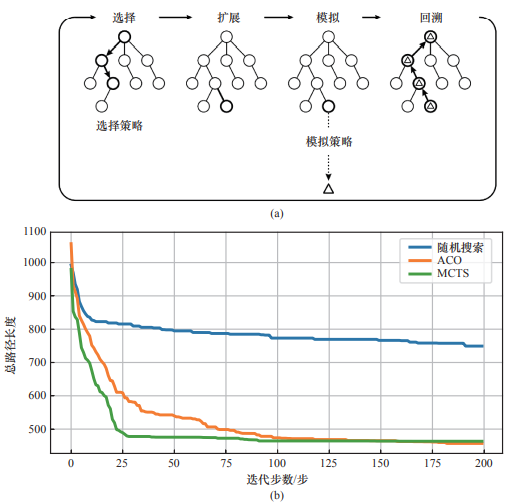
图 3
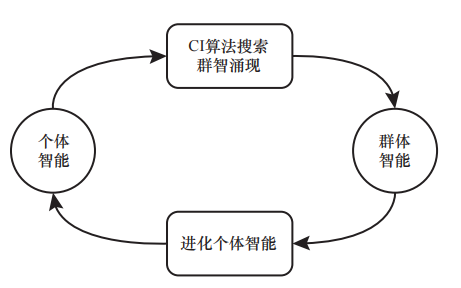
图 4
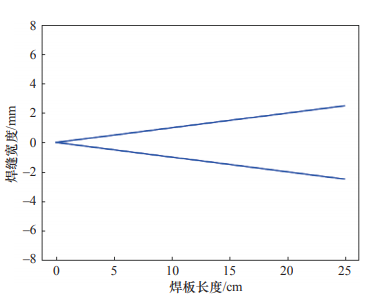
图 5

图 6

图 7

图 8

图 9
参考文献
[ 1 ] Landemore H. Democratic reason: Politics, collective intelligence, and the rule of the many [M]. Princeton: Princeton University Press, 2012. 链接1 链接2
[ 2 ] Wolpert D H, Tumer K, Frank J. Using collective intelligence to route internet traffic [M]. Cambridge: MIT Press, 1999. 链接1 链接2
[ 3 ] Wolpert D H, Tumer K. Collective intelligence, data routing and braess’paradox [J]. Journal of Artificial Intelligence Research, 2002, 16(4): 708–714. 链接1 链接2
[ 4 ] Tumer K, Wolpert D H. Collectives and the design of complex systems [M]. Berlin: Springer-Verlag, 2004. 链接1 链接2
[ 5 ] Ng A Y, Harada D, Russell S J. Policy invariance under reward transformations: Theory and application to reward shaping [C]. San Francisco: ICML’99 Proceedings of the Sixteenth International Conference on Machine Learning, 1999. 链接1 链接2
[ 6 ] Marden J R, Shamma J S. Game theoretic learning in distributed control—Handbook of dynamic game theory [M]. Berlin: Springer International Publishing, 2017.
[ 7 ] Samuel A L. Some studies in machine learning using the game of checkers II—Recent progress [J]. IBM Journal of Research and Development, 1967, 11: 601–617. 链接1
[ 8 ] Bon G L. The crowd: A study of the popular mind [M]. Berlin: Springer-Verlag, 2009. 链接2
[ 9 ] Thomas R L, Malone W, Dellarocas C. The collective intelligence genome [J]. IEEE Engineering Management Review, 2010, 55(1): 21–31.
[10] Woolley A W, Chabris C F, Pentland A, et al. Evidence for a collective intelligence factor in the performance of human groups [J]. Science, 2010, 330(6004): 686–688.
[11] Colorni A, Dorigo M, Maniezzo, et al. Distributed optimization by ant colonies [C]. Berlin: The 1st European Conference on Artificial Life, 1992.
[12] Stutzle T, Hoos H H. Max-min ant system [J]. Future Generation Computer Systems, 2000,16(8): 889–914.
[13] Zlochin M, Birattari M, Meuleau N, et al. Model-based search for combinatorial optimization: A critical survey [J]. Annals of Operations Research, 2004, 131(1–4): 373–395. 链接1 链接2
[14] Dorigo M, Birattari M, Stutzle T. Ant colony optimization [J]. IEEE Computational Intelligence Magazine, 2006, 1(1): 28–39.
[15] Rego C, Gamboa D, Glover F, et al. Traveling salesman problem heuristics: Leading methods, implementations and latest advances [J]. European Journal of Operational Research, 2011, 211(3): 427–441. 链接1 链接2
[16] Rabiner L R. Combinatorial optimization: Algorithms and complexity [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1258–1259. 链接2
[17] Poli R, Kennedy J, Blackwell T. Particle swarm optimization an overview [J]. Swarm Intelligence, 2007, 1(1): 33–57.
[18] Rodrigues F, Pereira F C, Ribeiro B. Learning from multiple annotators: Distinguishing good from random labelers [J]. Pattern Recognition Letters, 2013, 34(12): 1428–1436. 链接1 链接2
[19] Yan Y, Fung G, Rosales R M, et al. Active learning from crowds [C]. Bellevue: The 28th International Conference on Machine Learning, 2011.
[20] Long C, Hua G, Kapoor A. Active visual recognition with expertise estimation in crowd sourcing [C]. Sydney: The IEEE International Conference on Computer Vision, 2013. 链接1 链接2
[21] Zhao Z, Yan D, Ng W, et al. A transfer learning based framework of crowd-selection on twitter [C]. Birmingham: The 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2013. 链接1 链接2
[22] Fang M, Yin J, Zhu X. Knowledge transfer for multi-labeler active learning [C]. Prague: The Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 2013. 链接1 链接2
[23] Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search [J]. Nature, 2016, 529(7587): 484–489. 链接1 链接2
[24] Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of Go without human knowledge [J]. Nature, 2017, 550(7676): 354–359. 链接1 链接2
[25] Dorigo M, Gambardella L M. Ant colony system: A cooperative learning approach to the traveling salesman problem [J]. IEEE Transactions on evolutionary computation, 1997, 1(1): 53–66. 链接1 链接2
[26] Dorigo M, Blum C. Ant colony optimization theory: A survey [J]. Theoretical Computer Science, 2005, 344(3): 243–278. 链接1 链接2
[27] Dorigo M, Maniezzo V, Colorni A. The ant system: Optimization by a colony of cooperating agents [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 1996, 26(1): 29–41. 链接1 链接2
[28] Browne C B, Powley E, Whitehouse D, et al. A survey of Monte Carlo tree search methods [J]. IEEE Transactions on Computational Intelligence and AI in games, 2012, 4(1): 1–43. 链接1 链接2
[29] Coulom R. Efficient selectivity and backup operators in Monte-Carlo tree search [C]. Turin: International Conference on Computers and Games, 2006.
[30] Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning [C]. Berlin: European Conference on Machine Learning, 2006. 链接1 链接2
[31] Brémaud P. An introduction to probabilistic modeling [M]. Berlin: Springer Science & Business Media, 2012. 链接1 链接2
[32] Gutjahr W J. A graph-based ant system and its convergence [J]. Future Generation Computer Systems, 2000, 16(8): 873–888. 链接1 链接2
[33] Stutzle T, Dorigo M. A short convergence proof for a class of ant colony optimization algorithms [J]. IEEE Transactions on Evolutionary Computation, 2002, 6(4): 358–365. 链接1 链接2
[34] Auer P, Cesa-Bianchi N, Fischer P. Finite-time analysis of the multiarmed bandit problem [J]. Machine Learning, 2002, 47(2–3): 235–256.
[35] Rosin C D. Multi-armed bandits with episode context [J]. Annals of Mathematics and Artificial Intelligence, 2011, 61(3): 203–230. 链接1 链接2











 京公网安备 11010502051620号
京公网安备 11010502051620号




