

《1 前言》
1 前言
Boosting 是提高分类器识别性能的一般性框架,Adaboost 是 Boosting 算法的典型代表,并在近年来得到越来越多的关注。它在不同的样本分布下,根据相同的学习算法构建多个“弱学习器”,并采用加法模型将这些“弱学习器”集成为“强学习器”。在每一轮的样本权重更新中,都是提高识别错误样本的权重,降低识别正确样本的权重,这使得后续基元分类器能够更加关注那些被前级分类器错分的样本。Adaboost 原本用于处理两类问题,之后又出现了很多用于处理多类问题的扩展算法,如 Adaboost. M1,Adaboost. M2,Adaboost. MH,Adaboost. OC 以及Adaboost. ECC 等[1~5]。虽然这些算法已被应用于数字识别等小类别数多类分类问题,但对于汉字识别这种大类别分类问题,大部分多类 Adaboost 算法由于其过高的训练复杂度而难以被应用。笔者提出了一种新的改型多类Adaboost 算法,它具有较低的训练复杂度,可以有效提高手写汉字的识别率。
总的来说,Adaboost 算法中有两个关键要素。a. 样本权重的更新算法;b. 基元分类器。样本权重更新算法可分为两大类:一类是根据基元分类器的识别率进行权重更新,如 Discrete Adaboost;另一类是根据样本的识别可信度进行权重更新,如 Real Adaboost 。一般来说,第二类方法比第一类方法更加精细,因此具有更好的性能。但是,第二类算法中需要估计识别结果的后验概率,在很多实际应用中,识别结果后验概率的估计往往比较复杂,也比较困难。
多类 Adaboost 算法中使用的基元分类器可以分为两类。a. 采用多类分类器进行直接的多类分类,如 Adaboost. M1;b. 将多类问题转化为多个两类问题,进而应用多个两类分类器实现多类分类。现有大部分多类 Adaboost 算法均属于第二类。目前主要有 3 种策略实现将多类问题转化为多个两类问题,即一类对一类策略 (1 v 1); 一类对余类策略(1 v L); 编码策略(Output Code)。Adaboost. M2 和 Adaboost. MH 采用一类对余类策略;Adaboost. OC 和 Adaboost. ECC 采用编码策略。记训练样本总数为 N,类别总数为 C 。 设训练复杂度与训练中所使用的样本总样次成正比,则一类对一类及一类对余类策略的训练复杂度约为 O(N × C);编码策略的训练复杂度至少为 O ( N × log ( C ))。 对于汉字识别来说,C = 3755,因此一类对一类以及一类对余类策略都由于过高的训练复杂度而难以被应用。虽然编码策略的训练复杂度比其他两种策略低很多,但是在大类别分类问题中,如何构造合理有效的码表仍未被很好的解决。总之,将多类分类转化为多个两类分类来处理汉字识别仍存在很多问题。因此,笔者算法中采用多类分类器作为基元分类器。
文章第一节对此算法进行概述,比较了所提算法与现有算法的不同;第二节介绍算法的具体流程;第三节介绍基元分类器组的删减;第四节和第五节分别为实验和结论。
《2 改型 Adaboost 算法概述》
2 改型 Adaboost 算法概述
基于描述性模型的多类分类器(modified quadratic discriminant function,MQDF) 分类器由于其优良的识别率、简单的训练流程、较低的训练复杂度以及稳定的表现被广泛应用于汉字识别领域[6]。文章算法中采用 MQDF 作为基元分类器,并根据广义置信度进行权重更新。它与传统多类 Adaboost 算法相比主要有如下特点:
《2.1 采用的基元分类器类型不同》
2.1 采用的基元分类器类型不同
1) 大部分现有 Adaboost 算法都采用诸如线性分类器、SVM 等基于鉴别性模型的分类器作为基元分类器;在处理多类问题时大都是将多类分类转化为多个两类分类去处理,训练复杂度较高。
2) 文章算法采用基于描述性模型的多类分类器 MQDF 作为基元分类器。它可以直接进行多类分类,无需将多类问题转化为多个两类问题处理,具有较低的训练复杂度,这使得它可以被用于汉字识别这种大类别分类问题。
《2.2 样本权重更新算法不同》
2.2 样本权重更新算法不同
1) Adaboost. M1 是一种采用多类分类器作为基元分类器的典型算法。与 Discrete Adaboost 相同,它根据基元分类器的识别率进行样本权重更新,忽略了不同样本识别结果可信度的差异。但 MQDF 与传统 Adaboost 算法中的“弱学习器”不同,它的分类性能比较强:对于任意书写汉字的识别率已经接近 90 %,对于较规整书写汉字的识别率甚至达到 95 % 以上。通过实验发现,根据基元分类器识别率更新样本权重的做法不适合 MQDF 这种分类性能很好的基元分类器。
2) 文章借鉴两类分类中 Real Adaboost 算法的思想,根据各样本识别结果的可信度对其进行权重更新。但是 Real Adaboost 需要估计样本识别结果的后验概率,这通常比较困难,计算也比较复杂。笔者引进一种可简便计算的广义置信度作为评价识别结果优劣的度量,并根据广义置信度对样本进行权重更新。实验证明这种方式简便有效。
当使用笔者的改型 Adaboost 算法训练得到一组基元分类器后,为了提高识别速度以满足实际应用的需要,从基元分类器组中挑选一个最优的基元分类器作为最终的分类器。
《3 改型多类 Adaboost 算法流程》
3 改型多类 Adaboost 算法流程
由于文章算法与 Real Adaboost 具有紧密联系,因此先给出 Real Adaboost 的流程。然后将它推广到多类,并对权重更新系数的计算方法做一定改型。记训练样本集合为 {(xi ,yi ) |1  i
i  N} ,xi 为特征向量,yi 为其所属类别标号;记 T 为迭代总轮数。
N} ,xi 为特征向量,yi 为其所属类别标号;记 T 为迭代总轮数。
《3.1 Real Adaboost 算法流程》
3.1 Real Adaboost 算法流程
在 Real Adaboost 算法中, yi ∈ { -1, +1} ,它的流程如下:
1) 初始化:t =1;对样本赋初始权重 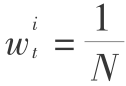 。
。
2) 对于 t=1,2,…,T,在样本分布 wt 下估计如下后验概率为:
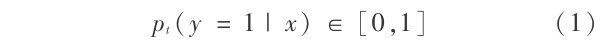
根据式(1),得到本轮的基元分类器 ht(x)
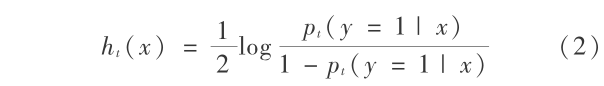
更新样本权重:
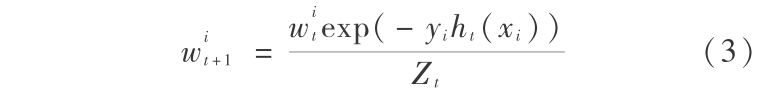
式(4)中, Zt 是归一化因子,它使得 wt +1 是一个概率分布,即满足  = 1 。
= 1 。
3) 最终的分类器为 H(x)。
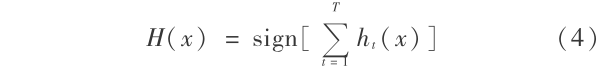
在 Real Adaboost 中,ht(x)含有两层含义,其符号表示了识别结果的类别;其绝对值表示了识别结果的可信度。
《3.2 改型 Adaboost 算法流程》
3.2 改型 Adaboost 算法流程
在多类情况下,将第 t 轮的基元分类器记为(ht , st )。ht (x)表示样本 x 的识别结果,ht(x)∈{1,2,...,C}; st(x)表示其广义置信度。
1) 初始化:t =1;对样本赋初始权重 。
2) 对于 t=1,2,…,T,在样本分布 wt 下训练得到第 t 级基元分类器( ht , st )。更新样本权重:
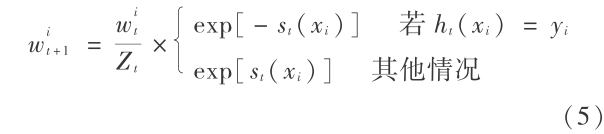
式(5)中,Zt 是归一化因子,它使得 wt +1 是一个概率分布,即满足 = 1 。
3) 对于待测样本 x,将累计广义置信度最大的类别作为其识别结果,如式(6)所示:

《3.3 基元分类器训练流程》
3.3 基元分类器训练流程
文章使用的原始特征是梯度方向直方图特征[7]。原始特征维数是 392 维,过高的特征维数往往会影响分类器的泛化能力;此外原始特征中含有大量与鉴别无关的信息,这些无用信息会对识别产生干扰。为了去除原始特征中那些与鉴别无关的信息,提高分类器的识别率及泛化能力,需要采用特征压缩方法从原始特征中提取鉴别特征,降低特征维数。
最常用的特征压缩方法是线性鉴别分析方法(linear discriminant analysis, LDA)。但 LDA 假设各类样本具有相同的协方差矩阵,这对于汉字识别并不合适。其是在文章算法中,各类样本分布在不断变化,这一假设更加无法保证。文献[8]提出了适用于异方差情况下的特征压缩算法,即改进的异方差线性鉴别分析方法(modified heteroscedastic lin - ear discriminant analysis, M - HLDA)。在笔者等实验中,LDA 和 M - HLDA 均被使用。
通过特征压缩方法,可以将原始特征向量进行维数压缩,成为特征向量。然后在特征向量集合上训练 MQDF 分类器[9]。对于特征向量 x,可根据式(8)计算得到 MQDF 分类器输出的识别距离。其中, gi (x) 表示 x 到 ωi 类的识别距离,mi 是类 ωi 的均值向量, λij 和 φij 分别为类 ωi 协方差矩阵  的第 j 个特征值(按照从大到小排序)和对应的特征向量,d 是特征维数,q 是截断维数, σ 是一个常数。各类均值向量及协方差矩阵可由最大似然估计得到。
的第 j 个特征值(按照从大到小排序)和对应的特征向量,d 是特征维数,q 是截断维数, σ 是一个常数。各类均值向量及协方差矩阵可由最大似然估计得到。
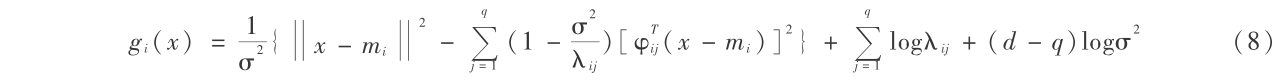
《3.4 广义置信度计算方法》
3.4 广义置信度计算方法
根据 Real Adaboost 算法,在多类情况下样本的识别可信度可由式(9)进行计算。

式(9) 中,ht (x) 是基元分类器的识别结果;pt (ht (x)|x) 是估计所得的识别结果的后验概率。在多类情况下,pt (ht (x)|x)很有可能会小于 0.5,这会使得式(9)计算得到的权重更新系数为负数。根据权重更新算法,对于那些权重更新系数为负数的样本来说,如果他们被识别正确,则会增加其权重;如果识别错误,则会降低其权重。 这显然与 Ada - boost 的基本出发点相矛盾。为了避免这种矛盾,需要保证权重更新系数 st (x)为非负值,但式(9)并不能保证这一点。此外,式(9)中后验概率的估计也比较困难。 因此,利用式(9)来计算权重更新系数 st (x)在多类情况下存在一定的问题。
笔者引入一种广义置信度作为权重更新系数 st(x),它既能保证 st (x)为非负值,又无需估计后验概率,实验证明此方法简单有效。广义置信度的定义如下:若存在一个函数 e(h(x)|x),以及一个单调递增函数 f(·) ,满足式(10),则称 e(h(x)|x)为 x 的广义置信度。笔者等使用的广义置信度计算方法如式(11)所示[10],其中 gk(x) 表示 x 的第 k 候选识别结果的识别距离。

《4 分类器组的删减》
4 分类器组的删减
通过改型 Adaboost 算法,得到 T 个基元分类器,每个基元分类器均包含一个特征降维 LDA 或 M - HLDA 矩阵,以及一个 MQDF 分类器。基元分类器与目前汉字识别中广泛使用的 LDA + MQDF 方法具有相同的识别复杂度。因此,改型 Adaboost 算法的整体识别复杂度是传统 LDA + MQDF 的 T 倍。为了保持与传统算法相同的识别复杂度,对训练得到的分类器组进行删减。根据 T 个基元分类器在训练集上的识别性能,挑选一个最优的基元分类器作为最终的分类器。 在识别时仅使用最优基元分类器进行识别。记第 t 个基元分类器在训练集上的识别率为 CRt 。最优基元分类器所对应的序号 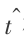 根据式(12)得到。
根据式(12)得到。
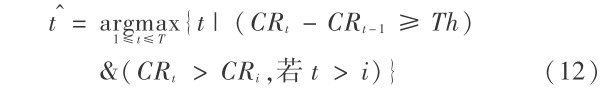
《5 实验》
5 实验
《5.1 手写汉字样本库》
5.1 手写汉字样本库
文章使用两个手写汉字样本库,HCL2000 和THOCR - HCD 。HCL2000 样本库由北京邮电大学在国家“八六三”计划的资助下收集,该样本库收集了由不同年龄、职业和文化程度的人书写的 1600套汉字样本,每套样本中均包含 GB2312 - 1980 中的 3755 个一级汉字的字符图像。笔者获得了该数据库的前 1000 套样本,将其中的 700 套样本(标号为 xx001 ~ xx700)作为训练集,而另外的 300 套样本(标号为 hh001 ~ hh300)作为测试集使用。HCL2000 的示例样本图像如图 1 所示。THOCR - HCD 样本库由清华大学电子工程系智能图文信息处理研究室历年来收集的手写汉字样本组成。同 HCL2000 库 一 样, THOCR -HCD 库也只包含GB2312 -1980 中的 3755 个一级汉字样本,但无论是样本规模还是样本采集的时间跨度都更大,包含的样本风格也更多。THOCR - HCD 样本库分为 10 个子 集,按照其质量标为好、中和差三级(见表 1)。在试验中,HCD4 和 HCD9 作为两个测试集,其他 1870套样本作为训练集。HCD4 为测试集 1,含有 100 套书写质量一般的样本,HCD9 为测试集 2 ,含有 20 套书写非常潦草的样本,示例样本图像如图 2所示。
《图1》

图1 HCL2000 库样本图像示例
Fig.1 Samples of HCL2000 database
《表1》
表1 THOCR-HCD 库子集信息
Table1 THOCR-HCD database subset information
《图2》

图2 THOCR-HCD 库样本图像示例
Fig.2 Samples of THOCR-HCD database
《5.2 算法识别率实验》
5.2 算法识别率实验
使用 LDA + MQDF 作为基元分类器,用改型 Adaboost 算法在 THOCR - HCD 库上进行 40 轮迭代训练,所得的 40 个基元分类器在训练集和两个测试集上的识别率分别如图 3 、图 4 和图 5 所示;在HCL2000 库上进行 40 轮迭代,所得 40 个基元分类器在训练集和测试集上的识别率分别如图 6 和图 7 所示。在每幅图中,均有两条识别率曲线,分别表示了前 T 个基元分类器进行集成后的整体分类器的识别率和各单独基元分类器的识别率。
《图3》

图3 分类器在 THOCR-HCD训练集的识别率
Fig.3 The recognition rate on THOCR-HCD training set
《图4》
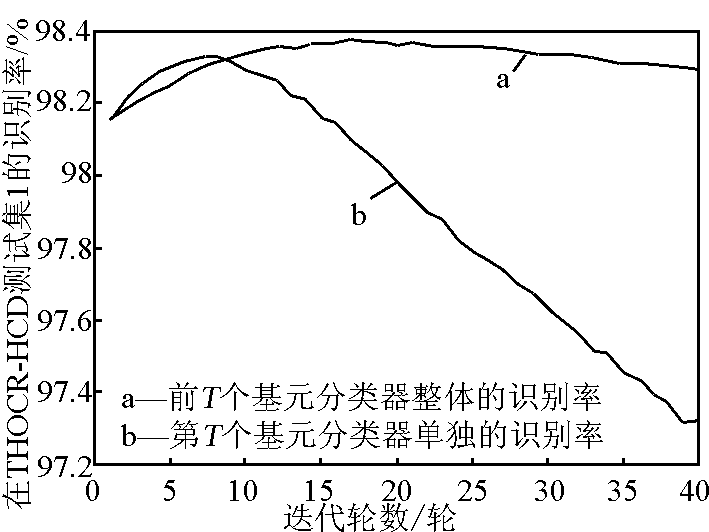
图4 分类器在 THOCR-HCD测试集 1 的识别率
Fig.4 The recognition rate on THOCR-HCD testing set 1
《图5》

图5 分类器在 THOCR-HCD测试集 2 的识别率
Fig.5 The recognition rate on THOCR-HCD testing set 2
《图6》
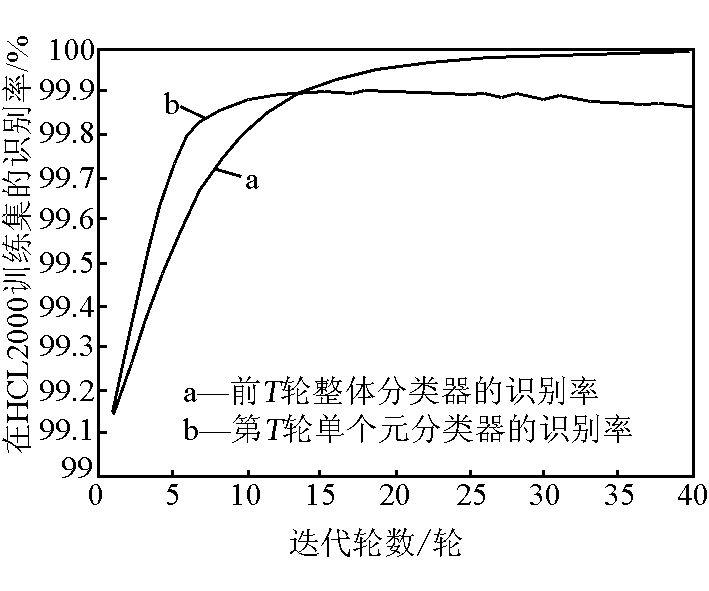
图6 分类器在 HCL2000 训练集的识别率
Fig.6 The recognition rate on HCL2000 training set
《图7》

图7 分类器在 HCL2000 测试集的识别率
Fig.7 The recognition rate on HCL2000 testing set
以上各实验测得的识别率曲线具有如下共同点。a. 在训练集上,前 T 轮整体分类器的识别率随迭代轮数的增加而持续增加,而各轮单独基元分类器的识别率则是先增加后降低。b. 在测试集上,前 T 轮整体分类器和各轮单独基元分类器的识别率随着 T 的增加均呈现先增加后降低的趋势;前 T 轮整体分类器的识别率经过一个峰值后缓慢下降,而各轮单独基元分类器的识别率经过峰值后下降迅速。c. 无论是在训练集还是测试集上,前 T 轮整体分类器识别率的峰值均大于单独基元分类器识别率的峰值, 这两个峰值又均明显高于未经 Adaboost 进行性能提升的分类器的识别率,即第 1 轮基元分类器的识别率。
随后,根据式(12)挑选一个最优的基元分类器作为最终的分类器。以 THOCR - HCD 为例,由图 3 中测得的各单独基元分类器的识别率曲线,最终选择第 9 轮基元分类器为最终的分类器。此外,还采用了 M - HLDA + MQDF 作为基元分类器进行了实验。表 2 列出了不同识别算法的识别率,其中,Boosted LDA + MQDF 和 Boosted M - HLDA + MQDF 都是仅包含一个最优基元分类器,因此与传统 LDA + MQDF 方法具有相同的识别复杂度。实验结果验证了文章算法的有效性,其中 Boosted M - HLDA + MQDF 具有最优的识别结果;与现有的 M - HLDA + MQDF 方法相比,它的相对错误率分别降低了 14.3 %,8.1 % 和 19.5 % 。
《表2》
表2 各算法识别率比较
Table2 The algorithms’recognition rate comparison

《6 结语》
6 结语
1) 采用基于描述性模型的多类分类器作为基元分类器,因此可直接进行多类分类,无需将多类问题转化为多个两类问题,大大降低了训练复杂度,可用于大类别分类问题。
2) 引入式(11)所示的广义置信度作为评价识别结果优劣的度量,并根据它进行权重更新。实验说明这种处理方式简便有效。
3) 首次将 Adaboost 算法应用到超多类手写汉字识别中来,对其他大类别分类问题有借鉴作用。
4) 在不同手写汉字数据库上进行实验,在保持与传统分类算法具有相同识别复杂度的前提下,显著提高了识别率。实验结果显示笔者等算法对于书写质量差的样本,如 THOCR - HCD 测试集 2,效果尤其显著。











 京公网安备 11010502051620号
京公网安备 11010502051620号




