
2018, Volume 4, Issue 1
Engineering >> 2018, Volume 4, Issue 1 doi: 10.1016/j.eng.2018.02.005
Toward Privacy-Preserving Personalized Recommendation Services
a Department of Computer Science, City University of Hong Kong, Hong Kong, China
b City University of Hong Kong, Shenzhen Research Institute, Shenzhen, Guangdong 518057, China
c Department of Computer Science and Technology, Xi’an Jiaotong University, Xi’an 710049, China
d Institute of Cyber Security Research, Zhejiang University, Hangzhou, Zhejiang 310058, China
Next Previous
Abstract
Recommendation systems are crucially important for the delivery of personalized services to users. With personalized recommendation services, users can enjoy a variety of targeted recommendations such as movies, books, ads, restaurants, and more. In addition, personalized recommendation services have become extremely effective revenue drivers for online business. Despite the great benefits, deploying personalized recommendation services typically requires the collection of users’ personal data for processing and analytics, which undesirably makes users susceptible to serious privacy violation issues. Therefore, it is of paramount importance to develop practical privacy-preserving techniques to maintain the intelligence of personalized recommendation services while respecting user privacy. In this paper, we provide a comprehensive survey of the literature related to personalized recommendation services with privacy protection. We present the general architecture of personalized recommendation systems, the privacy issues therein, and existing works that focus on privacy-preserving personalized recommendation services. We classify the existing works according to their underlying techniques for personalized recommendation and privacy protection, and thoroughly discuss and compare their merits and demerits, especially in terms of privacy and recommendation accuracy. We also identity some future research directions.
Keywords
Privacy protection ; Personalized recommendation services ; Targeted delivery ; Collaborative filtering ; Machine learning
Figures
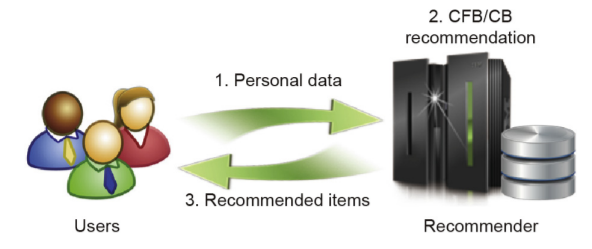
Fig.1
References
[ 1 ] Mackenzie I, Meyer C, Noble S. How retailers can keep up with consumers [Internet]. Chicago: McKinsey & Company; 1996–2018 [cited 2017 Mar 22]. Available from: http://www.mckinsey.com/industries/retail/our-insights/ how-retailers-can-keep-up-with-consumers. link1
[ 2 ] Hassler J. The power of personalized product recommendations [Internet]. Carrollton: Intelliverse; 2018 [updated 2017 Aug 22; cited 2017 28 C. Wang et al. / Engineering 4 (2018) 21–28 Mar 22]. Available from: http://www.intelliverse.com/blog/the-power-of-personalized-product-recommendations/.
[ 3 ] Leskovec J, Rajaraman A, Ullman J. Mining of massive datasets. 2nd ed. Cambridge: Cambridge University Press; 2014.
[ 4 ] Li D, Lv Q, Shang L, Gu N. Efficient privacy-preserving content recommendation for online social communities. Neurocomputing 2017;219:440–54. link1
[ 5 ] Ramakrishnan N, Keller BJ, Mirza BJ, Grama AY, Karypis G. Privacy risks in recommender systems. IEEE Internet Comput 2001;5(6):54–62. link1
[ 6 ] Erkin Z, Veugen T, Toft T, Lagendijk RL. Generating private recommendations efficiently using homomorphic encryption and data packing. IEEE Trans Inf Foren Sec 2012;7(3):1053–66. link1
[ 7 ] Xu K, Yan Z. Privacy protection in mobile recommender systems: A survey. In: Wang G, Ray I, Alcaraz Calero J, Thampi S, editors Proceedings of the 9th International Conference on Security, Privacy and Anonymity in Computation, Communication, and Storage; 2016 Nov 16–18; Zhangjiajie, China. Cham: Springer; 2016. p. 305–18. link1
[ 8 ] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer 2009;42(8):30–7. link1
[ 9 ] Aïmeur E, Brassard G, Fernandez JM, Onana FSM. Alambic: A privacy-preserving recommender system for electronic commerce. Int J Inf Secur 2008;7(5):307–34. link1
[10] Badsha S, Yi X, Khalil I. A practical privacy-preserving recommender system. Data Sci Eng 2016;1(3):161–77. link1
[11] Badsha S, Yi X, Khalil I, Bertino E. Privacy preserving user-based recommender system. In: Proceedings of the 37th IEEE International Conference on Distributed Computing Systems; 2017 Jun 5–8; Atlanta, GA, USA. Los Alamitos: IEEE Computer Society Press; 2017. p. 1074–83. link1
[12] Polat H, Du W. Privacy-preserving collaborative filtering using randomized perturbation techniques. In: Proceedings of the 3rd IEEE International Conference on Data Mining; 2003 Nov 19–22; Melbourne, FL, USA. Los Alamitos: IEEE Computer Society Press; 2003. p. 625–8. link1
[13] Shokri R, Pedarsani P, Theodorakopoulos G, Hubaux JP. Preserving privacy in collaborative filtering through distributed aggregation of offline profiles. In: Proceedings of the 3rd ACM Conference on Recommender Systems; 2009 Oct 23–25; New York, NY, USA. New York: Association for Computing Machinery, Inc.; 2009. p. 157–64. link1
[14] Chow R, Pathak MA, Wang C. A practical system for privacy-preserving collaborative filtering. In: Proceedings of the 12th IEEE International Conference on Data Mining Workshops; 2012 Dec 10; Brussels, Belgium. Los Alamitos: IEEE Computer Society Press; 2012. p. 547–54. link1
[15] Huang Z, Du W, Chen B. Deriving private information from randomized data. In: Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data; 2005 Jun 14–16; Baltimore, MD, USA. New York: Association for Computing Machinery, Inc.; 2005. p. 37–48. link1
[16] Zhang S, Ford J, Makedon F. Deriving private information from randomly perturbed ratings. In: Ghosh J, Lambert D, Skillicorn D, Srivastava J, editors Proceedings of the 2006 SIAM International Conference on Data Mining; 2006 Apr 20–22; Bethesda, MD, USA. Philadelphia: Society for Industrial and Applied Mathematics; 2006. p. 59–69. link1
[17] Aggarwal CC. On randomization, public information and the curse of dimensionality. In: Proceedings of the 23rd International Conference on Data Engineering; 2007 Apr 15–20; Istanbul, Turkey. Los Alamitos: IEEE Computer Society Press; 2007. p. 136–45. link1
[18] Nikolaenko V, Ioannidis S, Weinsberg U, Joye M, Taft N, Boneh D. Privacy-preserving matrix factorization. In: Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications Security; 2013 Nov 4–8; Berlin, Germany. New York: Association for Computing Machinery, Inc.; 2013. p. 801–12.
[19] Kim S, Kim J, Koo D, Kim Y, Yoon H, Shin J. Efficient privacy-preserving matrix factorization via fully homomorphic encryption: Extended abstract. In: Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security; 2016 May 30–Jun 3; Xi’an, China. New York: Association for Computing Machinery, Inc.; 2016. p. 617–28. link1
[20] Nikolaenko V, Weinsberg U, Ioannidis S, Joye M, Boneh D, Taft N. Privacy-preserving ridge regression on hundreds of millions of records. In: Proceeding of the 2013 IEEE Symposium on Security and Privacy; 2013 May 19–22; Berkeley, CA, USA. Los Alamitos: IEEE Computer Society Press; 2013. p. 334–48. link1
[21] Hu S, Wang Q, Wang J, Chow SSM, Zou Q. Securing fast learning! Ridge regression over encrypted big data. In: Proceedings of the 2016 IEEE Trustcom/ BigDataSE/ISPA; 2016 Aug 23–26; Tianjin, China. Los Alamitos: IEEE Computer Society Press; 2016. p. 19–26. link1
[22] Toubiana V, Narayanan A, Boneh D, Nissenbaum H, Barocas S. Adnostic: Privacy preserving targeted advertising. In: Proceedings of the 2010 Network and Distributed System Security Symposium; 2010 Feb 28–Mar 3; San Diego, CA, USA. Reston: Internet Society; 2010. p. 1–16. link1
[23] Wang W, Yang L, Chen Y, Zhang Q. A privacy-aware framework for targeted advertising. Comput Netw 2015;79:17–29.
[24] Guha S, Cheng B, Francis P. Privad: Practical privacy in online advertising. In: Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation; 2011 Mar 30–Apr 1; Boston, MA, USA. Berkeley: USENIX Association; 2011. p. 169–82. link1
[25] Backes M, Kate A, Maffei M, Pecina K. ObliviAd: Provably secure and practical online behavioral advertising. In: Proceedings of the 2012 IEEE Symposium on Security and Privacy; 2012 May 20–23; San Francisco, CA, USA. Los Alamitos: IEEE Computer Society Press; 2012. p. 257–71. link1
[26] Artail H, Farhat R. A privacy-preserving framework for managing mobile ad requests and billing information. IEEE Trans Mobile Comput 2015;14 (8):1560–72. link1
[27] Jiang J, Gui X, Shi Z, Yuan X, Wang C. Towards secure and practical targeted mobile advertising. In: Proceedings of the 11th International Conference on Mobile Ad-hoc and Sensor Networks; 2015 Dec 16–18; Shenzhen, China. Los Alamitos: IEEE Computer Society Press; 2015. p. 79–88. link1
[28] Chow R, Pathak MA, Wang C. A practical system for privacy-preserving collaborative filtering. In: Proceedings of the 12th IEEE International Conference on Data Mining Workshops; 2012 Dec 10; Brussels, Belgium. Los Alamitos: IEEE Computer Society Press; 20 link1
[29] Davidson D, Fredrikson M, Livshits B. MoRePriv: Mobile OS support for application personalization and privacy. In: Proceedings of the 30th Annual Computer Security Applications Conference; 2014 Dec 8–12; New Orleans, LA, USA. New York: Association for Computing Machinery, Inc.; 2014. p. 236–45. link1
[30] Partridge K, Pathak MA, Uzun E, Wang C. PiCoDa: Privacy-preserving smart coupon delivery architecture. In: Proceedings of 5th Workshop on Hot Topics in Privacy Enhancing Technologies; 2012 Jul 11–13; Vigo, Spain; 2012. p. 95–108. link1
[31] Rane S, Uzun E. A fuzzy commitment approach to privacy preserving behavioral targeting. In: Proceedings of the ACM MobiCom Workshop on Security and Privacy in Mobile Environments; 2014 Sep 11; Maui, HI, USA. New York: Association for Computing Machinery, Inc.; 2014. p. 31–6. link1
[32] Jiang J, Zheng Y, Yuan X, Shi Z, Gui X, Wang C, et al. Towards secure and accurate targeted mobile coupon delivery. IEEE Access 2016;4:8116–26. link1
[33] Wu D, Chang RKC. Analyzing Android browser apps for file:// vulnerabilities. In: Chow SSM, Camenisch J, Hui LCK, Yiu SM, editors Proceedings of the 17th International Conference on Information Security; 2014 Oct 12–14; Hong Kong, China. Cham: Springer; 2014. p. 345–63. link1
[34] Son S, Kim D, Shmatikov V. What mobile ads know about mobile users. In: Proceedings of 2016 Network and Distributed System Security Symposium; 2016 Feb 21–24; San Diego, CA, USA. Reston: Internet Society; 2016. p. 1–14. link1
[35] Su X, Zhang D, Li W, Li W. Android app recommendation approach based on network traffic measurement and analysis. In: Proceedings of the IEEE Symposium on Computers and Communication; 2015 Jul 6–9; Larnaca, Cyprus. Piscataway: Institute of Electrical and Electronic Engineers, Inc.; 2015. p. 988–94.
[36] Li F, He Y, Niu B, Li H, Wang H. Match-MORE: An efficient private matching scheme using friends-of-friends’ recommendation. In: Proceedings of the 2016 International Conference on Computing, Networking and Communications; 2016 Feb 15–18; Kauai, HI, USA. Piscataway: Institute of Electrical and Electronic Engineers, Inc.; 2016. p. 1–6. link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




