
2018, Volume 4, Issue 6
Engineering >> 2018, Volume 4, Issue 6 doi: 10.1016/j.eng.2018.10.005
A Dual-Platform Laser Scanner for 3D Reconstruction of Dental Pieces
State Key Laboratory for Manufacturing System Engineering, Xi’an Jiaotong University, Xi’an 710049, China
Next Previous
Abstract
This paper presents a dual-platform scanner for dental reconstruction based on a three-dimensional (3D) laser-scanning method. The scanner combines translation and rotation platforms to perform a holistic scanning. A hybrid calibration method for laser scanning is proposed to improve convenience and precision. This method includes an integrative method for data collection and a hybrid algorithm for data processing. The integrative method conveniently collects a substantial number of calibrating points with a stepped gauge and a pattern for both the translation and rotation scans. The hybrid algorithm, which consists of a basic model and a compensation network, achieves strong stability with a small degree of errors. The experiments verified the hybrid calibration method and the scanner application for the measurement of dental pieces. Two typical dental pieces were measured, and the experimental results demonstrated the validity of the measurement that was performed using the dual-platform scanner. This method is effective for the 3D reconstruction of dental pieces, as well as that of objects with irregular shapes in engineering fields.
Keywords
Laser scanning ; Hybrid calibration ; Neural network ; Dental pieces
Figures
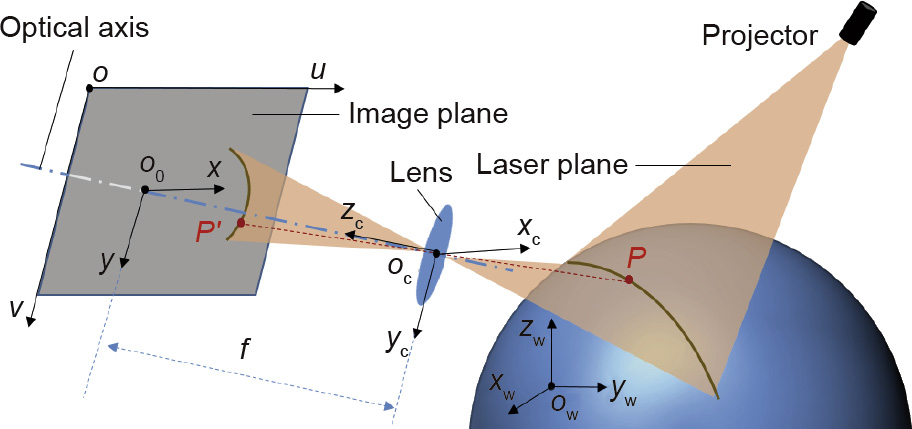
Fig.1

Fig.2

Fig.3

Fig.4
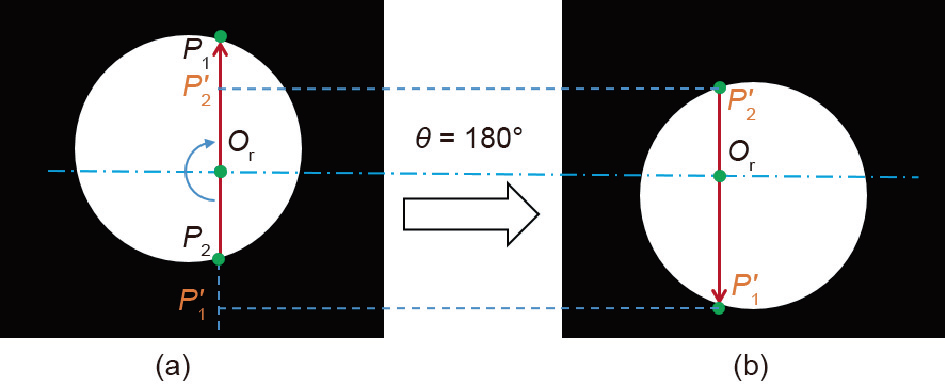
Fig.5

Fig.6

Fig.7
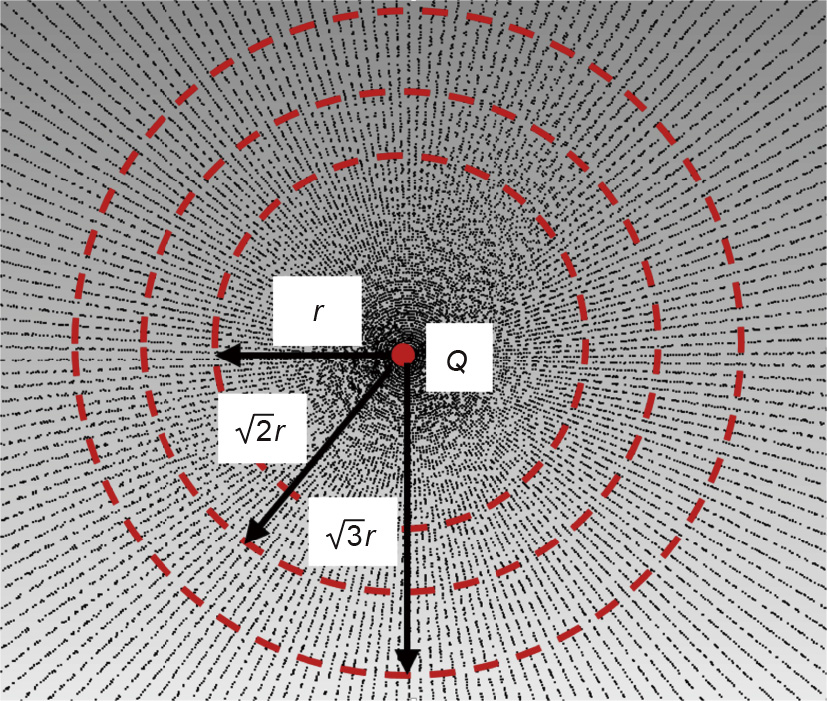
Fig.8
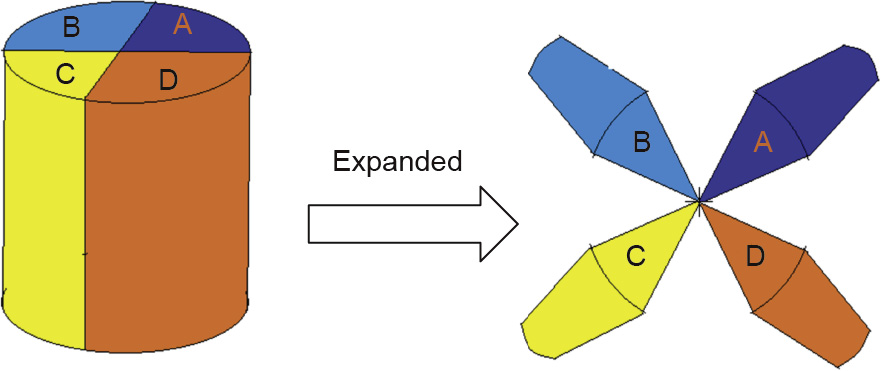
Fig.9

Fig.10

Fig.11
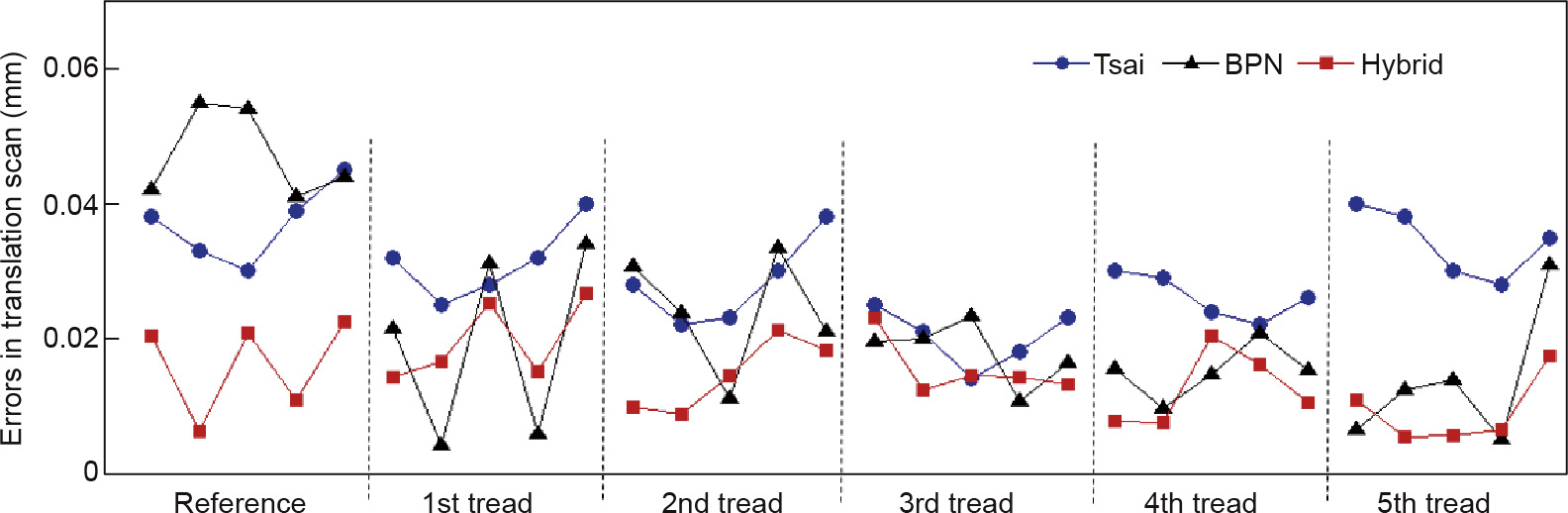
Fig.12

Fig.13

Fig.14

Fig.15

Fig.16

Fig.17
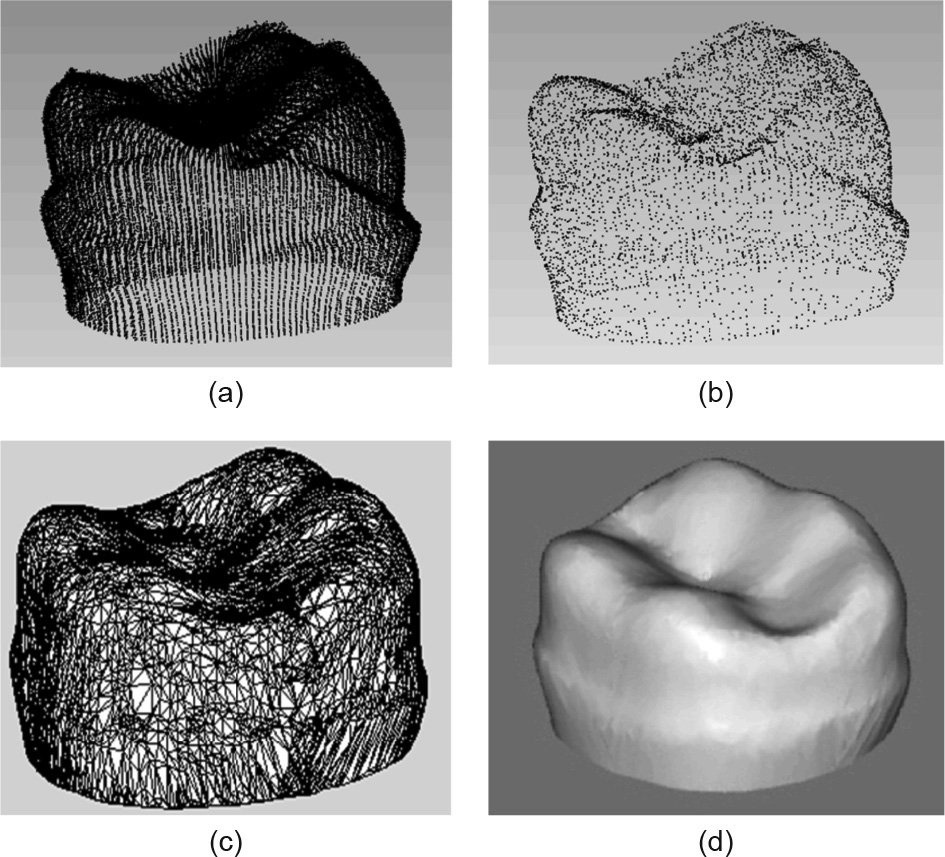
Fig.18
References
[ 1 ] Welk A, Rosin M, Seyer D, Splieth C, Siemer M, Meyer G. German dental faculty attitudes towards computer-assisted learning and their correlation with personal and professional profiles. Eur J Dent Educ 2005;9(3):123–30. link1
[ 2 ] Munera N, Lora GJ, Garcia-Sucerquia J. Evaluation of fringe projection and laser scanning for 3D reconstruction of dental pieces. Dyna 2012;79(171):65–73. link1
[ 3 ] Geng J. Structured-light 3D surface imaging: a tutorial. Adv Opt Photonics 2011;3(2):128–60. link1
[ 4 ] Zhou W, Guo H, Li Q, Hong T. Fine deformation monitoring of ancient building based on terrestrial laser scanning technologies. IOP Conf Ser Earth Environ Sci 2014;17:012166. link1
[ 5 ] Andersen UV, Pedersen DB, Hansen HN, Nielsen JS. In-process 3D geometry reconstruction of objects produced by direct light projection. Int J Adv Manuf Technol 2013;68(1–4):565–73. link1
[ 6 ] Choi S, Kim P, Boutilier R, Kim MY, Lee YJ, Lee H. Development of a high speed laser scanning confocal microscope with an acquisition rate up to 200 frames per second. Opt Express 2013;21(20):23611–8. link1
[ 7 ] Dewar R. Self-generated targets for spatial calibration of structured light optical sectioning sensors with respect to an external coordinate system. Cleveland: Society of Manufacturing Engineers; 1988.
[ 8 ] Duan FJ, Liu FM, Ye SH. A new accurate method for the calibration of line structured light sensor. Chin J Sci Instrum 2000;21:108–13. Chinese.
[ 9 ] Huynh DQ, Owens RA, Hartmann PE. Calibration a structured light stripe system: a novel approach. Int J Comput Vis 1999;33(1):73–86. link1
[10] Zhou F, Zhang G. Complete calibration of a structured light stripe vision sensor through planar target of unknown orientations. Image Vis Comput 2005;23 (1):59–67. link1
[11] Sun Q, Hou Y, Tan Q, Li G. A flexible calibration method using the planar target with a square pattern for line structured light vision system. PLoS One 2014;9 (9):e106911. link1
[12] Xie Z, Wang X, Chi S. Simultaneous calibration of the intrinsic and extrinsic parameters of structured-light sensors. Opt Lasers Eng 2014;58:9–18. link1
[13] Li J, Chen M, Jin X, Chen Y, Dai Z, Ou Z, et al. Calibration of a multiple axes 3D laser scanning system consisting of robot, portable laser scanner and turntable. Optik 2011;122(4):324–9. link1
[14] Li P, Zhang W, Xiong X. A fast approach for calibrating 3D coordinate measuring system rotation axis based on line-structure light. Microcomput Appl 2015;34:73–5. Chinese.
[15] Wu Q, Li J, Su X, Hui B. An approach for calibration rotor position of threedimensional measurement system for line-structure light. Chin J Lasers 2008;35(8):1224–7. Chinese.
[16] Chang M, Tai WC. 360-deg profile noncontact measurement using a neural network. Opt Eng 1995;34(12):3572–7. link1
[17] Dipanda A, Woo S, Marzani F, Bilbault JM. 3D shape reconstruction in an active stereo vision system using genetic algorithms. Patt Recog 2003;36(9):2143–59. link1
[18] Zhao Y, Ren H, Xu K, Hu J. Method for calibrating intrinsic camera parameters using orthogonal vanishing points. Opt Eng 2016;55(8):084106. link1
[19] Tsai RY. A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses. IEEE J Robot Autom 1987;3(4):323–44. link1
[20] Zhang Z. A flexible new technique for camera calibration. IEEE Trans Pattern Anal Mach Intell 2000;22(11):1330–4. link1
[21] Li XW, Cho SJ, Kim ST. Combined use of BP neural network and computational integral imaging reconstruction for optical multiple-image security. Opt Commun 2014;315(6):147–58. link1
[22] Wei P, Cheng C, Liu T. A photonic transducer-based optical current sensor using back-propagation neural network. IEEE Photonics Technol Lett 2016;28 (14):1513–6. link1
[23] Zhang Y, Liu W, Li X, Yang F, Gao P, Jia Z. Accuracy improvement in laser stripe extraction for large-scale triangulation scanning measurement system. Opt Eng 2015;54(10):105108. link1
[24] Watson DF. Computing the n-dimensional Delaunay tessellation with applications to Voronoi polytopes. Comput J 1981;24(2):167–72. link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




