
2019, Volume 5, Issue 1
Engineering >> 2019, Volume 5, Issue 1 doi: 10.1016/j.eng.2018.11.018
Wasserstein GAN-Based Small-Sample Augmentation for New-Generation Artificial Intelligence: A Case Study of Cancer-Staging Data in Biology
a College of Life Science and Technology, Huazhong University of Science and Technology, Wuhan 430074, China
b School of Public Policy and Management, Tsinghua University, Beijing 100084, China
c School of Mechanical Science and Engineering, Huazhong University of Science and Technology, Wuhan 430074, China
d Center for Strategic Studies, Chinese Academy of Engineering, Beijing 100088, China
Next Previous
Abstract
It is essential to utilize deep-learning algorithms based on big data for the implementation of the new generation of artificial intelligence. Effective utilization of deep learning relies considerably on the number of labeled samples, which restricts the application of deep learning in an environment with a small sample size. In this paper, we propose an approach based on a generative adversarial network (GAN) combined with a deep neural network (DNN). First, the original samples were divided into a training set and a test set. The GAN was trained with the training set to generate synthetic sample data, which enlarged the training set. Next, the DNN classifier was trained with the synthetic samples. Finally, the classifier was tested with the test set, and the effectiveness of the approach for multi-classification with a small sample size was validated by the indicators. As an empirical case, the approach was then applied to identify the stages of cancers with a small labeled sample size. The experimental results verified that the proposed approach achieved a greater accuracy than traditional methods. This research was an attempt to transform the classical statistical machine-learning classification method based on original samples into a deep-learning classification method based on data augmentation. The use of this approach will contribute to an expansion of application scenarios for the new generation of artificial intelligence based on deep learning, and to an increase in application effectiveness. This research is also expected to contribute to the comprehensive promotion of new-generation artificial intelligence.
Keywords
Artificial intelligence ; Generative adversarial network ; Deep neural network ; Small sample size ; Cancer
Figures
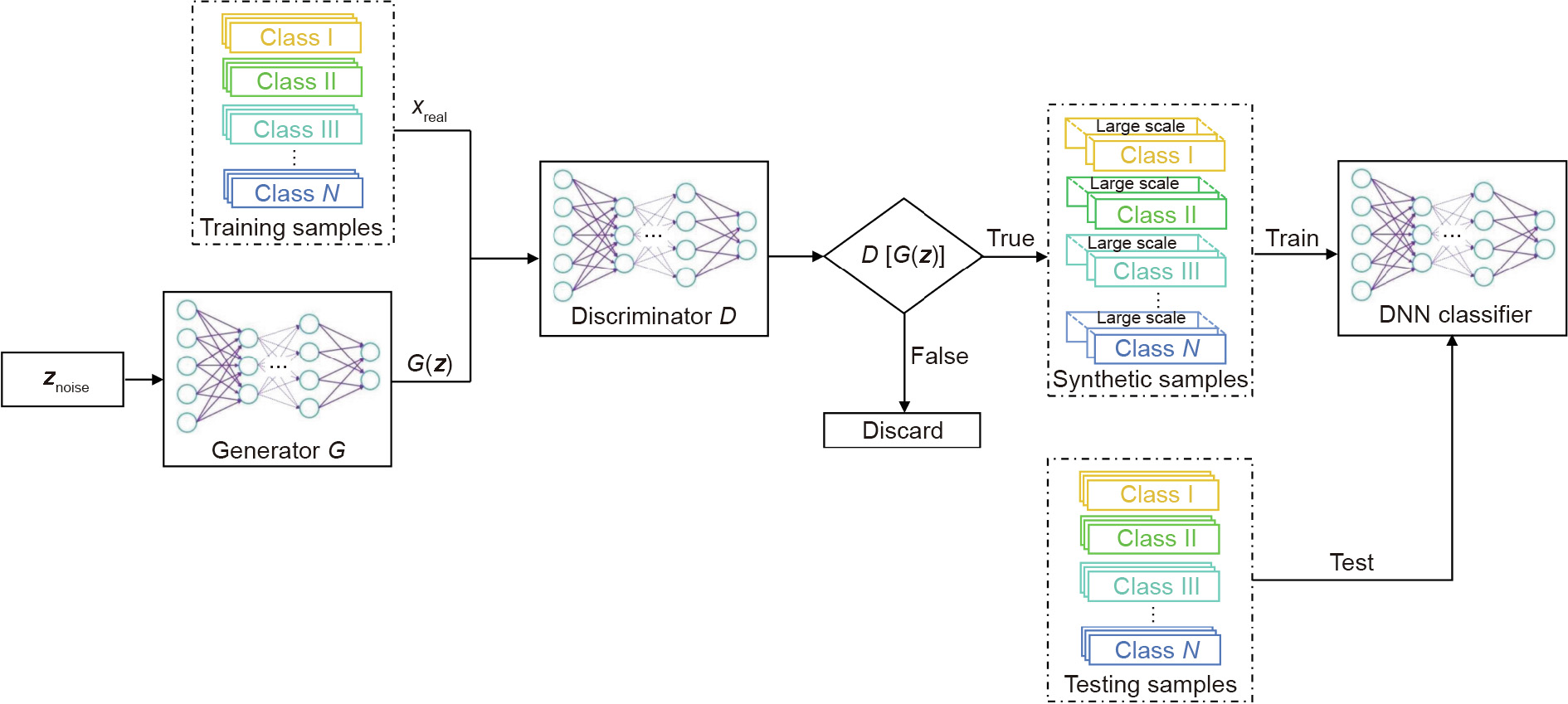
Fig. 1

Fig. 2

Fig. 3
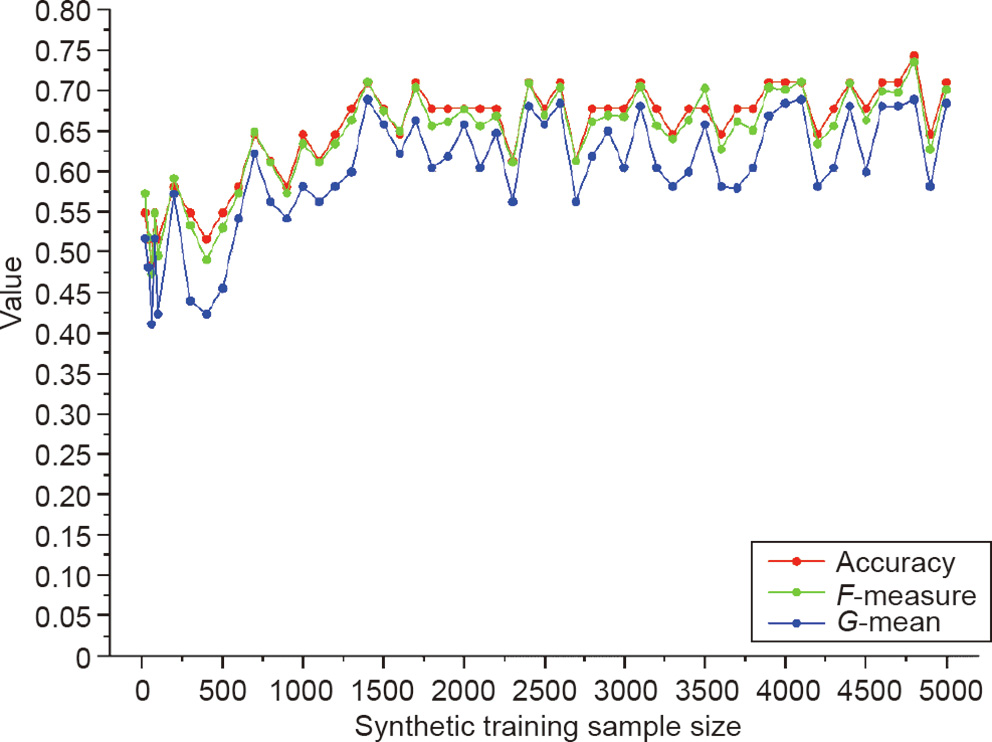
Fig. 4
References
[ 1 ] Crevier D. AI: the tumultuous history of the search for artificial intelligence. New York: Basic Books, Inc.; 1993. link1
[ 2 ] Pan Y. Heading toward Artificial Intelligence 2.0. Engineering 2016;2 (4):409–13. link1
[ 3 ] State Council of the People’s Republic of China. Development Plan for a NextGeneration Artificial Intelligence [Internet]. Beijing: www.gov.cn. [cited 2018 Mar 5]. Available from: http://english.gov.cn/policies/latest_releases/2017/07/ 20/content_281475742458322.htm.
[ 4 ] State Council Information Office of the People’s Republic of China. The policy interpretation of Development Planning for a Next-Generation Artificial Intelligence [Internet]. Beijing: www.scio.gov.cn. [cited 2018 Mar 5]. Available from: http://www.scio.gov.cn/34473/34515/Document/1559231/ 1559231.htm. Chinese.
[ 5 ] Hinton GE, Salakhutdinov RR. Reducing the dimensionality of data with neural networks. Science 2006;313(5786):504–7. link1
[ 6 ] Zhuang Y, Chen C, Pan Y. Challenges and opportunities: from big data to knowledge in AI 2.0. Front Inf Technol Electronic Eng 2017;18(1):3–14. link1
[ 7 ] Al-Qizwini M, Barjasteh I, Al-Qassab H, Radha H. Deep learning algorithm for autonomous driving using GoogLeNet. In: Proceedings of the 2017 IEEE Intelligent Vehicles Symposium; 2017 Jun 11–14; Los Angeles, CA, USA. New York: IEEE; 2017. p. 89–96. link1
[ 8 ] Wang L, Sng D. Deep learning algorithms with applications to video analytics for a smart city: a survey. 2016: arXiv:1511.06434.
[ 9 ] Mohamed A, Dahl G, Hinton G. Acoustic modeling using deep belief networks. IEEE Trans Audio Speech Lang Process 2012;20(1):14–22. link1
[10] Jones N. Artificial-intelligence institute launches free science search engine [Internet]. Heidelberg: Springer Nature. c2018 [cited 2018 Mar 5]. Available from: https://www.nature.com/news/artificial-intelligence-institute-launchesfree-science-search-engine-1.18703.
[11] Goodfellow I, Bengio Y, Courville A. Deep learning. Cambridge: The MIT Press; 2016. link1
[12] Zhuang F, Luo P, Qing H, Shi Z. Survey on transfer learning research. J Software 2015;26:26–39. Chinese. link1
[13] Chen J, Yang J, Zhou H, Xiang H, Zhu Z, Li Y, et al. CPS modeling of CNC machine tool work processes using an instruction-domain based approach. Engineering 2015;1(2):247–60. link1
[14] Urban F, Zhou Y, Nordensvard J, Narain A. Firm-level technology transfer and technology cooperation for wind energy between Europe, China and India: from north–south to south–north cooperation? Energy Sustainable Dev 2015;28:29–40. link1
[15] Zhou Y, Zhang H, Ding M, Su J. How public demonstration project affects the emergence of a new industry: an empirical study on electric vehicle demonstration project in China. In: Proceedings of the 2013 Suzhou Silicon Valley–Beijing International Innovation Conference; 2013 Jul 8–9. New York: IEEE; 2013. p. 234–9. link1
[16] Zhou Y, Minshall T. Building global products and competing in innovation: the role of Chinese university spin–outs and required innovation capabilities. Int J Technol Manage 2014;64(2):180–209. link1
[17] Xu G, Wu Y, Minshall T, Zhou Y. Exploring innovation ecosystems across science, technology, and business: a case of 3D printing in China. Technol Forecast Social Change 2017;136:180–221. link1
[18] Li X, Zhou Y, Xue L, Huang L. Roadmapping for industrial emergence and innovation gaps to catch-up: a patent analysis of OLED industry in China. Int J Technol Manage 2016;7(1–3):105–43. link1
[19] Li X, Zhou Y, Xue L, Huang L. Integrating bibliometrics and roadmapping methods: a case of dye-sensitized solar cell technology-based industry in China. Technol Forecast Social Change 2015;97:205–22. link1
[20] Zhou Y, Pan M, Urban F. Comparing the international knowledge flow of China’s wind and solar photovoltaic (PV) industries: patent analysis and implications for sustainable development. Sustainability 2018;10(6):1883. link1
[21] Theodoridis S, Koutroumbas K. Pattern recognition. 3rd ed. Orlando: Academic Press; 2006. link1
[22] Nordensvard J, Zhou Y, Zhang X. Innovation core, innovation semi-periphery and technology transfer: the case of wind energy patents. Energy Policy 2018;120:213–27. link1
[23] Pan M, Zhou Y, Zhou DK. Comparing the innovation strategies of Chinese and European wind turbine firms through a patent lens. Environ Innovation Societal Transitions. Epub 2017 Dec 27.
[24] Zhou Y, Pan M, Zhou DK, Xue L. Stakeholder risk and trust perceptions in the diffusion of green manufacturing technologies: evidence from China. J Environ Dev 2017;27(1):46–73. link1
[25] Zhou Y, Li X, Lema R, Urban F. Comparing the knowledge bases of wind turbine firms in Asia and Europe: patent trajectories, networks, and globalisation. Sci Public Policy 2016;43(2):476–91. link1
[26] Chen L, Xu J, Zhou Y. Regulating the environmental behavior of manufacturing SMEs: interfirm alliance as a facilitator. J Cleaner Prod 2017;165:393–404. link1
[27] DeRouin E, Brown J. Neural network training on unequally represented classes. New York: ASME Press; 1991. link1
[28] Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 2002;16(1):321–57. link1
[29] Han H, Wang WY, Mao BH. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Huang DS, Zhang XP, Huang GB, editors. Advances in intelligent computing. Berlin: Springer; 2005. p. 878–87. link1
[30] He H, Bai Y, Garcia EA, Shutao L. ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: Proceedings of the 2008 IEEE International Joint Conference on Neural Networks; 2008 Jun 1–8; Hong Kong, China. New York: IEEE; 2008. p. 1322–8. link1
[31] Barua S, Islam MM, Yao X, Kazuyuki M. MWMOTE–majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans Knowl Data Eng 2014;26(2):405–25. link1
[32] Xie Z, Jiang L, Ye T, Li X. A synthetic minority oversampling method based on local densities in low-dimensional space for imbalanced learning. In: Renz M, Shahabi C, Zhou X, Cheema M, editors. Database systems for advanced applications. Cham: Springer; 2015. p. 3–18. link1
[33] Douzas G, Bacao F. Self-Organizing Map Oversampling (SOMO) for imbalanced data set learning. Expert Syst Appl 2017;82:40–52. link1
[34] Bishop CM. Training with noise is equivalent to Tiknonov regularization. Neural Comput 1995;7(1):108–16. link1
[35] Zhou Z, Jiang Y. Nec4.5: neural ensemble based C4.5. IEEE Trans Knowl Data Eng 2004;16(6):770–3. link1
[36] Li DC, Lin YS. Using virtual sample generation to build up management knowledge in the early manufacturing stages. Eur J Operat Res 2006;175 (1):413–34. link1
[37] Li D, Fang Y. A non-linearly virtual sample generation technique using group discovery and parametric equations of hypersphere. Exp Syst Appl 2009;36 (1):844–51. link1
[38] Wang K, Gou C, Duan Y, Lin Y, Zheng X, Wang F. Generative adversarial networks: introduction and outlook. IEEE/CAA J Autom Sin 2017;4(4):588–98. link1
[39] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Ghahramani Z, Welling M, Cortes C, Lawrence ND, Weinberger KG, editors. Advances in neural information processing systems. La Jolla: Neural Information Processing Systems Foundation, Inc.; 2014. p. 2672–80. link1
[40] Creswell A, White T, Dumoulin V, Arulkumaran K, Sengupta B, Bharath AA. Generative adversarial networks: an overview. IEEE Signal Process Mag 2018;35(1):53–65. link1
[41] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. 2015:arXiv:1512.03131.
[42] Santana E, Hotz G. Learning a driving simulator. 2016:arXiv:1608.01230.
[43] Gou C, Wu Y, Wang K, Wang F, Ji Q. Learning-by-synthesis for accurate eye detection. In: Proceedings of the 23rd International Conference on Pattern Recognition; 2016 Dec 4–8; Cancun, Mexico. New York: IEEE; 2017. p. 3362–7. link1
[44] Li J, Monroe W, Shi T, Jean S, Ritter A, Jurafsky D. Adversarial learning for neural dialogue generation. 2017:arXiv:1701.06547.
[45] Pascual S, Bonafonte A, Serrà J. SEGAN: speech enhancement generative adversarial network. 2017:arXiv:1703.09452.
[46] Fiore U, Santis AD, Perla F, Zanetti P, Palmieri F. Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf Sci 2019;479:448–55. link1
[47] Douzas G, Bacao F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst Appl 2017;91:464–71. link1
[48] Bloice MD, Stocker C, Holzinger A. Augmentor: an image augmentation library for machine learning. 2017:arXiv:1708.04680
[49] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. 2017:arXiv:1701.07875.
[50] Ratliff LJ, Burden SA, Sastry SS. Characterization and computation of local Nash equilibria in continuous games. In: Proceedings of the 51st Annual Allerton Conference on Communication, Control, and Computing; 2013 Oct 2–4; Monticello, IL, USA. New York: IEEE; 2006. p. 917–24. link1
[51] Danihelka I, Lakshminarayanan B, Uria B, Wierstra D, Dayan P. Comparison of maximum likelihood and GAN-based training of real NVPs. 2017: arXiv:1705.05263.
[52] Yang Q, Yan P, Zhang Y, Yu H, Shi Y, Mou X, et al. Low dose CT Image denoising using a generative adversarial network with Wasserstein distance and perceptual loss. IEEE Trans Med Imaging 2017;37(6):1348–57. link1
[53] Mcdaniel P, Papernot N, Celik ZB. Machine learning in adversarial settings. IEEE Secur Privacy 2016;14(3):68–72. link1
[54] Sousa LR, Miranda T, Sousa RL, Tinoco J. The use of data mining techniques in rockburst risk assessment. Engineering 2017;3(4):552–8. link1
[55] Sun Y, Kamel MS, Wong AKC, Wang Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit 2007;40(12):3358–78. link1
[56] Farazi AP, DePinho RA. Hepatocellular carcinoma pathogenesis: from genes to environment. Nat Rev Cancer 2006;6(9):674–87. link1
[57] Arzumanyan A, Reis HMGPV, Feitelson MA. Pathogenic mechanisms in HBVand HCV-associated hepatocellular carcinoma. Nat Rev Cancer 2013;13 (2):123–35. link1
[58] Mechref Y, Hu Y, Garcia A, Zhou S, Desantos-Garcia JL, Hussein A. Defining putative glycan cancer biomarkers by MS. Bioanalysis 2012;4(20):2457–69. link1
[59] Tang Z, Varghese RS, Bekesova S, Loffredo CA, Hamid MA, Kyselova Z, et al. Identification of N-glycan serum markers associated with hepatocellular carcinoma from mass spectrometry data. J Proteome Res 2010;9(1):104–12. link1
[60] Kronewitter SR, De Leoz MLA, Strum JS, An HJ, Dimapasoc LM, Guerrero A, et al. The glycolyzer: automated glycan annotation software for high performance mass spectrometry and its application to ovarian cancer glycan biomarker discovery. Proteomics 2012;12(15–16):2523–38. link1
[61] Pierce M, Buckhaults P, Chen L, Fregien N. Regulation of Nacetylglucosaminyltransferase V and Asn-linked oligosaccharide b(1,6) branching by a growth factor signaling pathway and effects on cell adhesion and metastatic potential. Glycoconjugate J 1997;14(5):623–30. link1
[62] Lau KS, Dennis JW. N-Glycans in cancer progression. Glycobiology 2008;18 (10):750–60. link1
[63] Saldova R, Royle L, Radcliffe CM, Abd Hamid UM, Evans R, Arnold JN, et al. Ovarian cancer is associated with changes in glycosylation in both acute-phase proteins and IgG. Glycobiology 2007;17(12):1344–56. link1
[64] Noda K, Miyoshi E, Gu J, Gao CX, Nakahara S, Kitada T, et al. Relationship between elevated FX expression and increased production of GDP-L-fucose, a common donor substrate for fucosylation in human hepatocellular carcinoma and hepatoma cell lines. Cancer Res 2003;63(19):6282–9. link1
[65] Basu PS, Majhi R, Batabyal SK. Lectin and serum-PSA interaction as a screening test for prostate cancer. Clin Biochem 2003;36(5):373–6. link1
[66] Arnold JN, Saldova R, Hamid UMA, Rudd PM. Evaluation of the serum N-linked glycome for the diagnosis of cancer and chronic inflammation. Proteomics 2008;8(16):3284–93. link1
[67] Adamczyk B, Tharmalingam T, Rudd PM. Glycans as cancer biomarkers. Biochim Biophys Acta Gen Subj 2012;1820(9):1347–53. link1
[68] Deguchi K, Keira T, Yamada K, Ito H, Takegawa Y, Nakagawa H, et al. Twodimensional hydrophilic interaction chromatography coupling anionexchange and hydrophilic interaction columns for separation of 2- pyridylamino derivatives of neutral and sialylated N-glycans. J Chromatography A 2008;1189(1–2):169–74. link1
[69] Siemerink E, Mulder NH, Brouwers AH, Hospers GA. Early prediction of response to sorafenib treatment in patients with hepatocellular carcinoma (HCC) with 18F-fluorodeoxyglucose-positron emission tomography (18F-FDGPET). J Clin Oncol 2008;26(21):1–15. link1
[70] Holzinger A, Malle B, Kieseberg P, Roth PM, Müller H, Reihs R. Machine learning and knowledge extraction in digital pathology needs an integrative approach lecture notes in computer science. In: Holzinger A, Goebel R, Ferri M, Palade V, editors. Towards integrative machine learning and knowledge extraction. Cham: Springer; 2017. link1
[71] Breiman L. Random forests. Mach Learn 2001;45(1):5–32. link1
[72] Mitchell T. Machine learning. Zeng H, Zhang Y, translator. Beijing: China Machine Press; 2003. Chinese. link1
[73] Liu P, Zhou Y, Zhou DK, Xue L. Energy Performance Contract models for the diffusion of green-manufacturing technologies in China: a stakeholder analysis from SMEs’ perspective. Energy Policy 2017;106:59–67. link1
[74] Kong D, Feng Q, Zhou Y, Xue L. Local implementation for green-manufacturing technology diffusion policy in China: from the user firms’ perspectives. J Cleaner Prod 2016;129:113–24. link1
[75] Zhou Y, Xu G, Minshall T, Liu P. How do public demonstration projects promote green-manufacturing technologies? A case study from China. Sustainable Dev 2015;23(4):217–31. link1
[76] Kong D, Zhou Y, Liu Y, Xue L. Using the data mining method to assess the innovation gap: a case of industrial robotics in a catching-up country. Technol Forecasting Social Change 2017;119:80–97. link1
[77] Li M, Zhou Y. Visualizing the knowledge profile on self-powered technology. Nano Energy 2018;51:250–9. link1
[78] Wang B, Liu Y, Zhou Y, Wen Z. Emerging nanogenerator technology in China: a review and forecast using integrating bibliometrics, patent analy and technology roadmapping methods. Nano Energy 2018;46:322–30. link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




