
2023, Volume 21, Issue 2
Engineering >> 2023, Volume 21, Issue 2 doi: 10.1016/j.eng.2022.05.017
Toward Human-in-the-loop AI: Enhancing Deep Reinforcement Learning Via Real-time Human Guidance for Autonomous Driving
School of Mechanical and Aerospace Engineering, Nanyang Technological University, Singapore 639798, Singapore
Next Previous
Abstract
Due to its limited intelligence and abilities, machine learning is currently unable to handle various situations thus cannot completely replace humans in real-world applications. Because humans exhibit robustness and adaptability in complex scenarios, it is crucial to introduce humans into the training loop of artificial intelligence (AI), leveraging human intelligence to further advance machine learning algorithms. In this study, a real-time human-guidance-based (Hug)-deep reinforcement learning (DRL) method is developed for policy training in an end-to-end autonomous driving case. With our newly designed mechanism for control transfer between humans and automation, humans are able to intervene and correct the agent's unreasonable actions in real time when necessary during the model training process. Based on this human-in-the-loop guidance mechanism, an improved actor-critic architecture with modified policy and value networks is developed. The fast convergence of the proposed Hug-DRL allows real-time human guidance actions to be fused into the agent's training loop, further improving the efficiency and performance of DRL. The developed method is validated by human-in-the-loop experiments with 40 subjects and compared with other state-of-the-art learning approaches. The results suggest that the proposed method can effectively enhance the training efficiency and performance of the DRL algorithm under human guidance without imposing specific requirements on participants' expertise or experience.
SupplementaryMaterials
Figures

Fig. 1

Fig. 2

Fig. 3
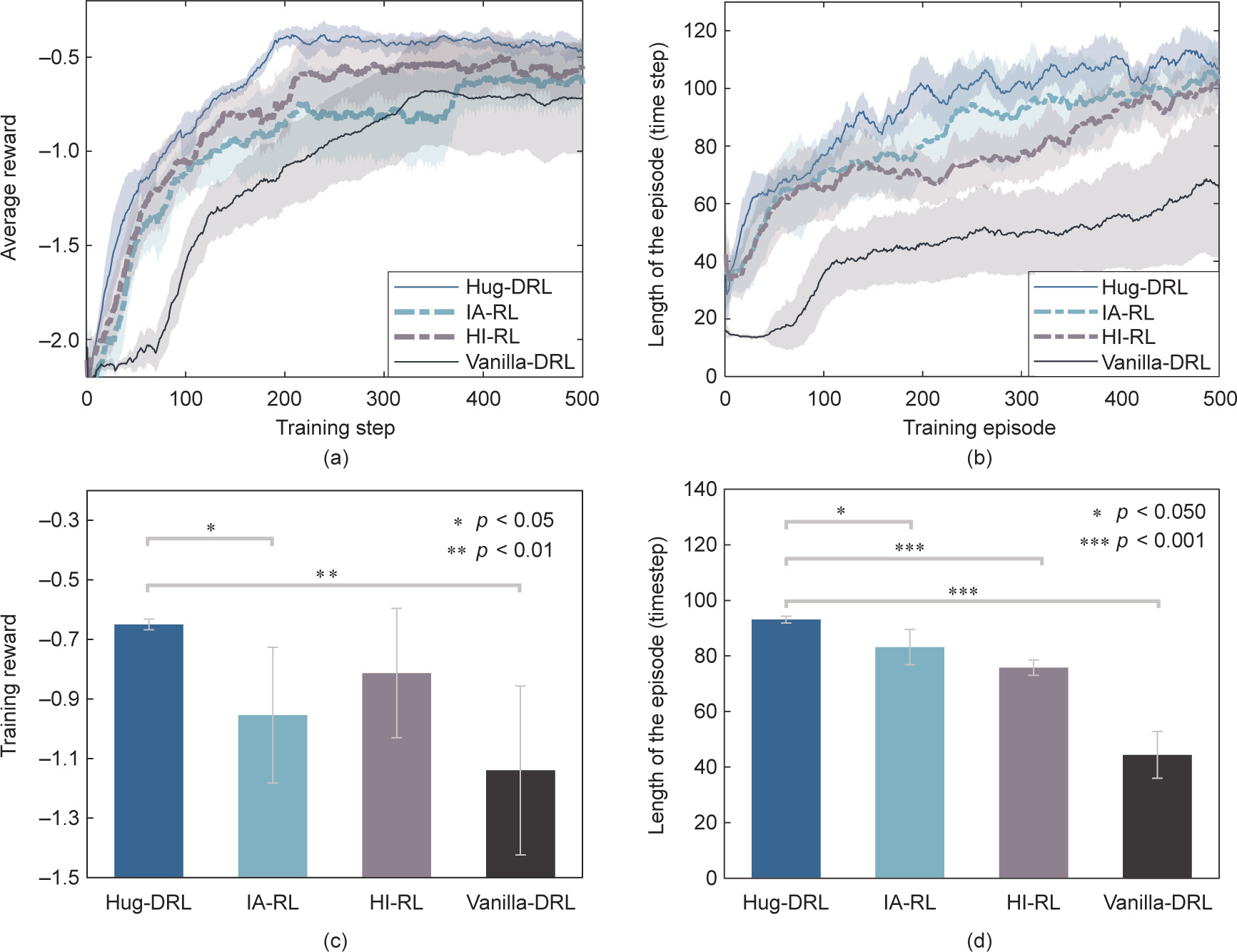
Fig. 4

Fig. 5
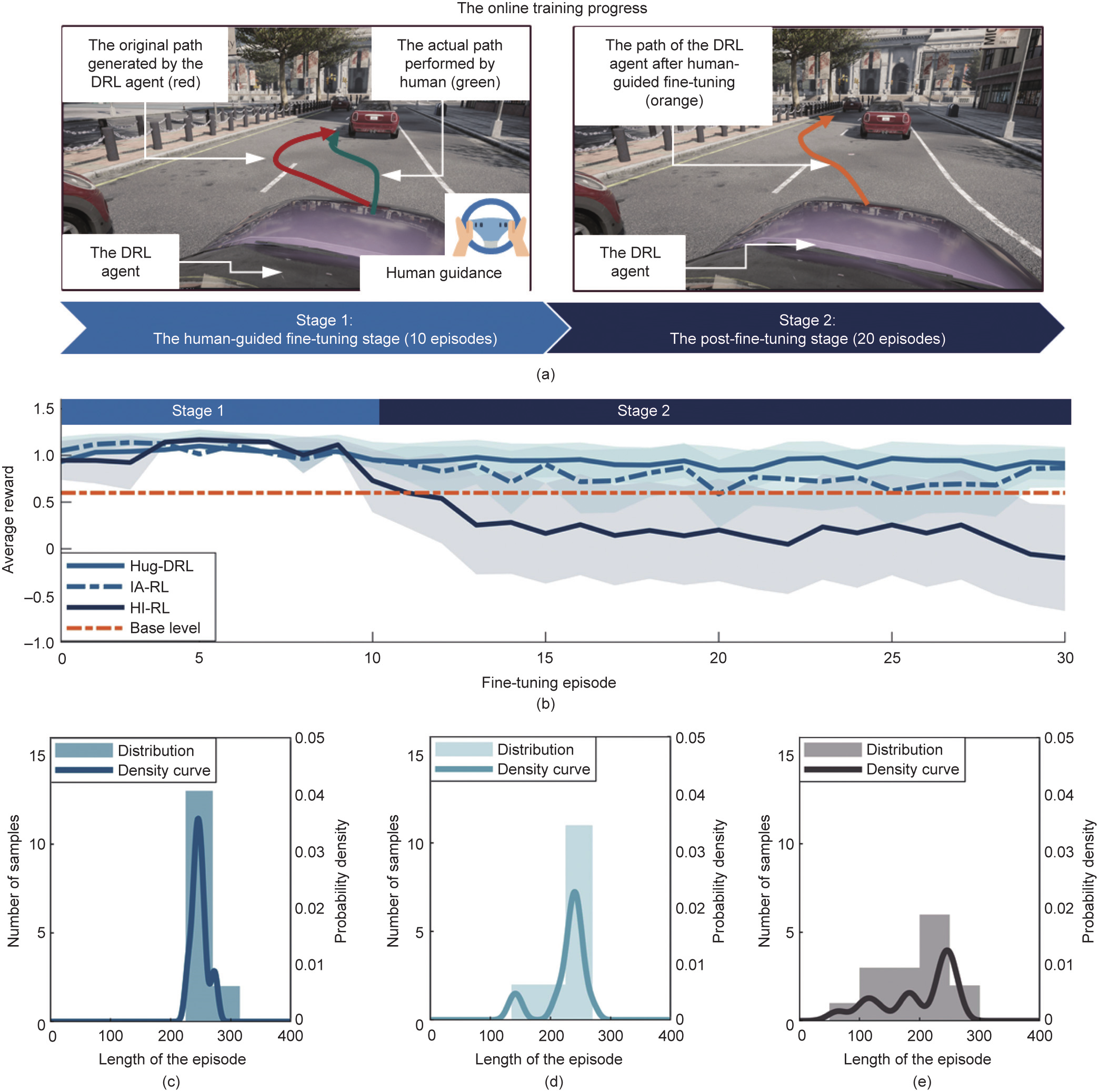
Fig. 6
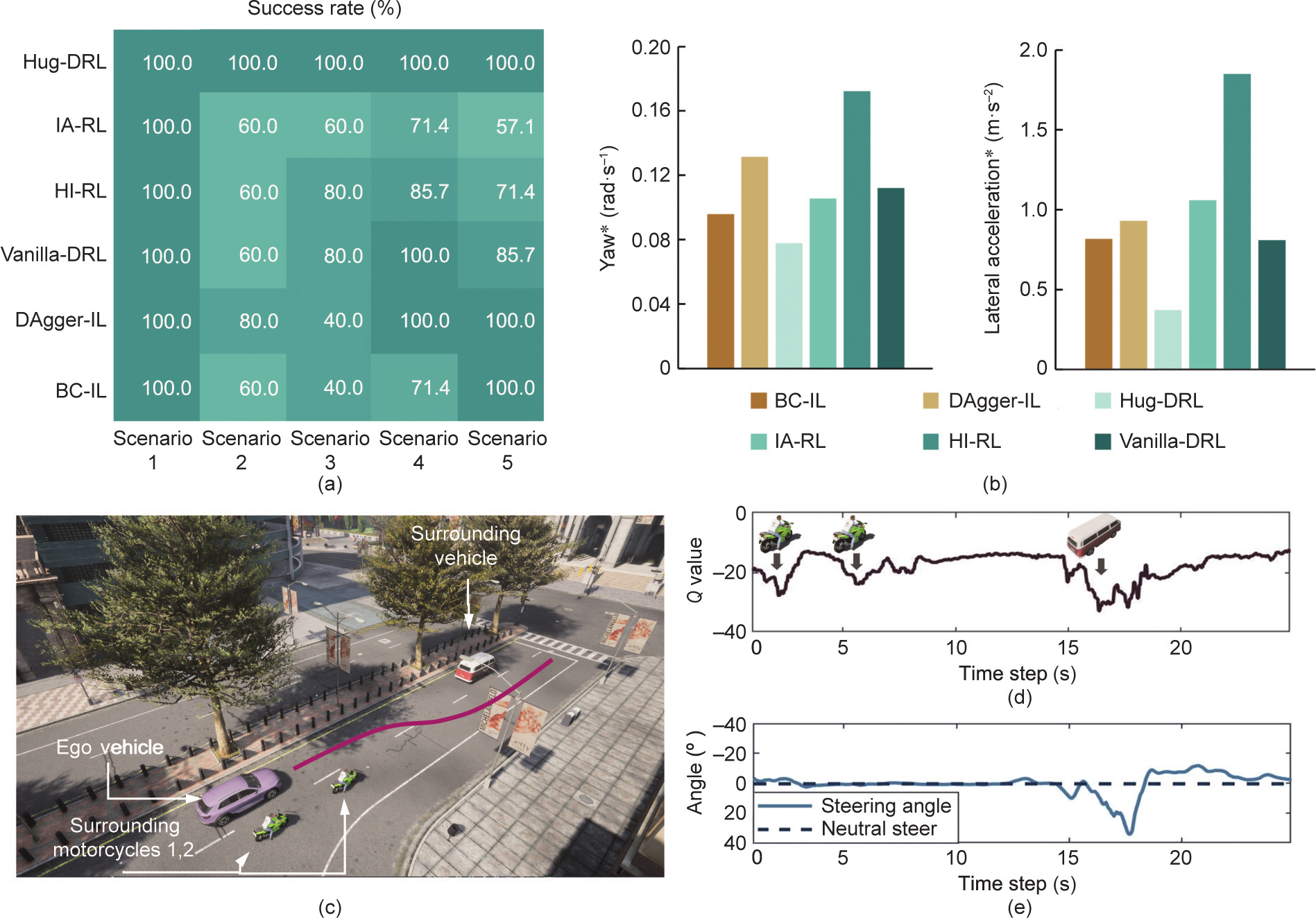
Fig. 7
References
[ 1 ] Stilgoe J. Self-driving cars will take a while to get right. Nat Mach Intell 2019;1(5):202–3.
[ 2 ] Mo X, Huang Z, Xing Y, Lv C. Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network. IEEE Trans Intell Transp Syst. In press.
[ 3 ] Huang Z, Wu J, Lv C. Efficient deep reinforcement learning with imitative expert priors for autonomous driving. IEEE Trans Neural Netw Learn Syst. In press.
[ 4 ] Feng S, Yan X, Sun H, Feng Y, Liu HX. Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment. Nat Commun 2021;12:748.
[ 5 ] Codevilla F, Müller M, López A, Koltun V, Dosovitskiy A. End-to-end driving via conditional imitation learning. In: Proceedings of 2018 IEEE International Conference on Robotics and Automation (ICRA); 2018 May 21–25; Brisbane, QLD, Australia. IEEE; 2018. p. 4693–700.
[ 6 ] Huang Z, Wu J, Lv C. Driving behavior modeling using naturalistic human driving data with inverse reinforcement learning. IEEE Trans Intell Transp Syst. In press.
[ 7 ] Codevilla F, Santana E, López AM, Gaidon A. Exploring the limitations of behavior cloning for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2019 Oct 27–Nov 2; Seoul, Republic of Korea. IEEE; 2019. p. 9329–38.
[ 8 ] Ross S, Gordon GJ, Bagnell JA. A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS); 2011 Apr 11–13; Fort Lauderdale, FL, USA. PMLR; 2011. p. 627–35.
[ 9 ] Ho J, Ermon S. Generative adversarial imitation learning. In: Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016); 2016 Dec 5–10; Barcelona, Spain. NIPS; 2016. p. 1–9.
[10] Silver D, Huang A, Maddison CJ, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016;529(7587):484–9.
[11] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature 2017;550(7676):354–9.
[12] Silver D, Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018;362(6419):1140–4.
[13] Sutton RS, Barto AG. Reinforcement learning: an introduction. 2nd ed. Cambridge: MIT press; 2018.
[14] Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, et al. Human-level control through deep reinforcement learning. Nature 2015;518(7540):529–33.
[15] Wolf P, Hubschneider C, Weber M, Bauer A, Härtl J, Dürr F, et al. Learning how to drive in a real world simulation with deep Q-Networks. In: Proceedings of 2017 IEEE Intelligent Vehicles Symposium (IV); 2017 Jun 11–14; Los Angeles, CA, USA. IEEE; 2017. p. 244–50.
[16] Sallab AE, Abdou M, Perot E, Yogamani S. Deep reinforcement learning framework for autonomous driving. Electron Imaging 2017;29:70–6.
[17] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning; 2018 Jul 10–15; Stockholm, Sweden. PMLR; 2018. p. 1861–70.
[18] Fujimoto S, van Hoof H, Meger D. Addressing function approximation error in actor-critic methods. In: Proceedings of the 35th International Conference on Machine Learning; 2018 Jul 10–15; Stockholm, Sweden. PMLR; 2018. p. 1587–96.
[19] Cai P, Mei X, Tai L, Sun Y, Liu M. High-speed autonomous drifting with deep reinforcement learning. IEEE Robot Autom Lett 2020;5(2):1247–54.
[20] Neftci EO, Averbeck BB. Reinforcement learning in artificial and biological systems. Nat Mach Intell 2019;1(3):133–43.
[21] Harutyunyan A, Dabney W, Mesnard T, Azar MG, Piot B, Heess N, et al. Hindsight credit assignment. In: Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019); 2019 Dec 9–14; Vancouver, BC, Canada. NeurIPS; 2019. p. 12498–507.
[22] Huang Z, Lv C, Xing Y, Wu J. Multi-modal sensor fusion-based deep neural network for end-to-end autonomous driving with scene understanding. IEEE Sens J 2021;21(10):11781–90.
[23] Lv C, Cao D, Zhao Y, Auger DJ, Sullman M, Wang H, et al. Analysis of autopilot disengagements occurring during autonomous vehicle testing. IEEE/CAA J Autom Sin 2018;5(1):58–68.
[24] Mao J, Gan C, Kohli P, Tenenbaum JB, Wu J. The neuro-symbolic concept learner: interpreting scenes, words, and sentences from natural supervision. In: Proceedings of the 7th International Conference on Learning Representations (ICLR); 2019 May 6–9; New Orleans, LA, USA. ICLR; 2019. p. 1–28.
[25] Knox WB, Stone P. Reinforcement learning from human reward: discounting in episodic tasks. In: Proceedings of 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication; 2012 Sep 9–13; Paris, France. IEEE; 2012. p. 878–85.
[26] MacGlashan J, Ho MK, Loftin R, Peng B, Wang G, Roberts DL, et al. Interactive learning from policy-dependent human feedback. In: Proceedings of the 34th International Conference on Machine Learning; 2017 Aug 6–11; Sydney, NSW, Australia. PMLR; 2017. p. 2285–94.
[27] Vecerik M, Hester T, Scholz J, Wang F, Pietquin O, Piot B, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards. 2017. arXiv:1707.08817.
[28] Rajeswaran A, Kumar V, Gupta A, Vezzani G, Schulman J, Todorov E, et al. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. In: Proceedings of Robotics: Science and Systems; 2018 Jun 26–30; Pittsburgh, PA, USA. RSS; 2018. p. 1–9.
[29] Ibarz B, Leike J, Pohlen T, Irving G, Legg S, Amodei D. Reward learning from human preferences and demonstrations in Atari. In: Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS); 2018 Dec 3– 8; Montreal, QC, Canada. NeurIPS; 2018. p. 8011–23.
[30] Ziebart BD, Maas A, Bagnell JA, Dey AK. Maximum entropy inverse reinforcement learning. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence; 2008 Jul 13–17; Chicago, IL, USA. AAAI Press; 2008. p. 1433–8.
[31] Hester T, Vecerik M, Pietquin O, Lanctot M, Schaul T, Piot B, et al. Deep Qlearning from demonstrations. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence; 2018 Feb 2–7; New Orleans, LA, USA. AAAI Press; 2018. p. 3223–30.
[32] Saunders W, Sastry G, Stuhlmüller A, Evans O. Trial without error: towards safe reinforcement learning via human intervention. In: Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems; 2018 Jul 10–15; Stockholm, Sweden. AAMAS; 2018. p. 2067–9.
[33] Krening S, Harrison B, Feigh KM, Isbell CL, Riedl M, Thomaz A. Learning from explanations using sentiment and advice in RL. IEEE Trans Cogn Dev Syst 2017;9(1):44–55.
[34] Nair A, McGrew B, Andrychowicz M, Zaremba W, Abbeel P. Overcoming exploration in reinforcement learning with demonstrations. In: Proceedings of 2018 IEEE International Conference on Robotics and Automation (ICRA); 2018 May 21–25; Brisbane, QLD, Australia. IEEE; 2018. p. 6292–9.
[35] Wang F, Zhou B, Chen K, Fan T, Zhang X, Li J, et al. Intervention aided reinforcement learning for safe and practical policy optimization in navigation. In: Proceedings of the 2nd Conference on Robot Learning; 2018 Oct 29–31; Zürich, Switzerland. PMLR; 2018. p. 410–21.
[36] Littman ML. Reinforcement learning improves behaviour from evaluative feedback. Nature 2015;521(7553):445–51.
[37] Droz´dziel P, Tarkowski S, Rybicka I, Wrona R. Drivers’ reaction time research in the conditions in the real traffic. Open Eng 2020;10(1):35–47.
[38] Hu Z, Zhang Y, Xing Y, Zhao Y, Cao D, Lv C. Toward human-centered automated driving: a novel spatiotemporal vision transformer-enabled head tracker. IEEE Veh Technol Mag. In press.
[39] Machado MC, Bellemare MG, Bowling M. Count-based exploration with the successor representation. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence; 2020 Feb 7–12; New York City, NY, USA. AAAI Press; 2020. p. 5125–33.
[40] Badia AP, Sprechmann P, Vitvitskyi A, Guo D, Piot B, Kapturowski S, et al. Never give up: learning directed exploration strategies. In: Proceedings of the 8th International Conference on Learning Representations (ICLR 2020); 2020 Apr 26–May 1; Addis Ababa, Ethiopia. ICLR; 2020. p. 1–26.











 京公网安备 11010502051620号
京公网安备 11010502051620号




