
2021年 第7卷 第9期
《工程(英文)》 >> 2021年 第7卷 第9期 doi: 10.1016/j.eng.2021.04.020
机器学习和数据驱动算法在智慧发电系统中的应用——一种不确定性处理的视角
a Key Lab of Thermal Science and Power Engineering of the Ministry of Education, School of Energy and the Environment, Southeast University, Nanjing 210096, China
b Robert Frederick Smith School of Chemical and Biomolecular Engineering, Cornell University, Ithaca, NY 14853, USA
下一篇 上一篇
摘要
由于人们对气候变化和环境保护的日益关注,智慧发电已成为常规火力发电厂和可再生能源系统经济安全运行的关键。面对日益增长的系统规模及其各种不确定性,传统的基于模型的第一定律方法已难以满足系统控制的要求。机器学习(ML)和数据驱动控制(DDC)技术的蓬勃发展为这些传统方法提供了一种替代方案。本文回顾了机器学习和数据驱动控制技术在发电系统监测、控制、优化和故障检测方面的典型应用,特别着重于揭示这些方法在评价、消除或耐受相关不确定性影响方面的作用。本文为智慧发电控制技术提供了一个从调节层到规划层的总体视角,分别从可见性、机动性、灵活性、经济性和安全性(简称“五性”)方面对机器学习和数据驱动控制技术的优势进行阐释。最后,对未来研究和应用进行了展望。
图片
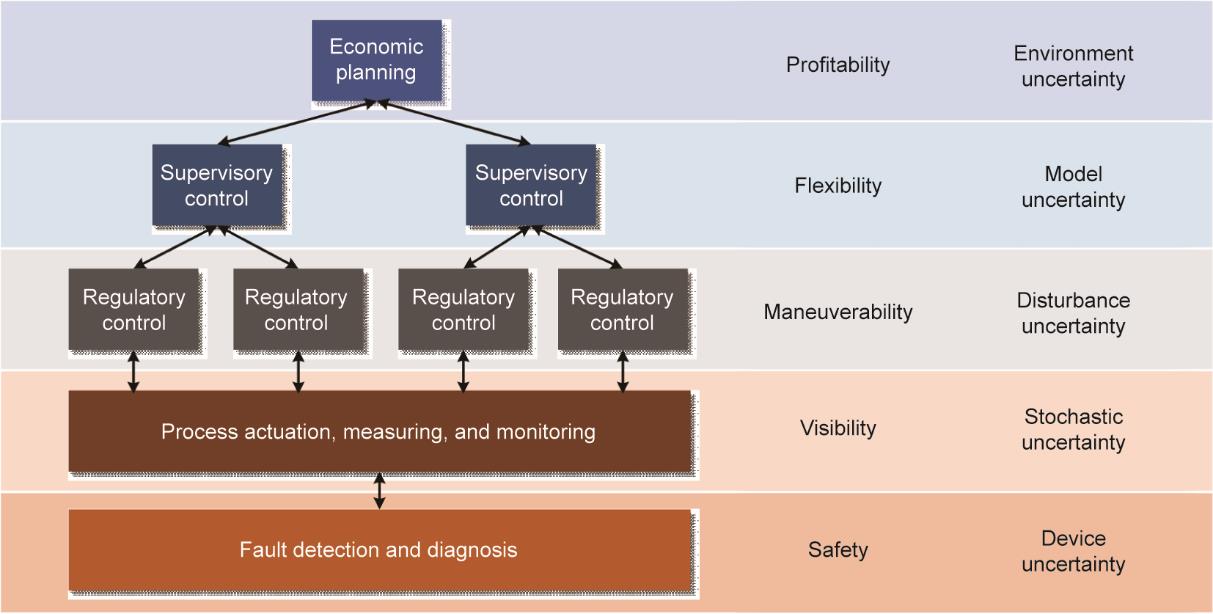
图1

图2
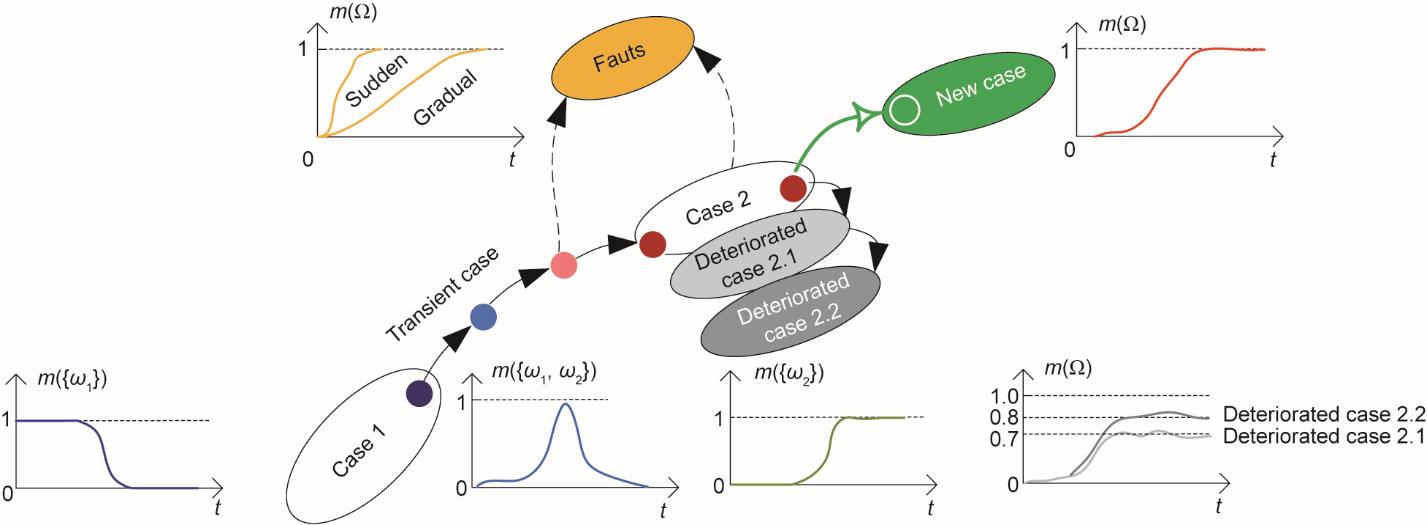
图3
参考文献
[ 1 ] Ma X, Wang C, Dong B, Gu G, Chen R, Li Y, et al. Carbon emissions from energy consumption in China: its measurement and driving factors. Sci Total Environ 2019;648:1411–510. 链接1
[ 2 ] International Energy Agency. Global energy & CO2 status report 2019: emissions [Internet]. Paris: International Energy Agency; 2020 [cited 2020 Jul 12]. Available from: https://www.iea.org/reports/global-energy-co2- status-report-2019/emissions. 链接1
[ 3 ] Rogelj J, den Elzen M, Höhne N, Fransen T, Fekete H, Winkler H, et al. Paris Agreement climate proposals need a boost to keep warming well below 2 C. Nature 2016;534(7609):631–9. 链接1
[ 4 ] O’Dwyer E, Pan I, Acha S, Shah N. Smart energy systems for sustainable smart cities: current developments, trends and future directions. Appl Energy 2019;237:581–97. 链接1
[ 5 ] Kong X, Liu X, Ma L, Lee KY. Hierarchical distributed model predictive control of standalone wind/solar/battery power system. IEEE Trans Syst Man Cybern 2019;49(8):1570–81. 链接1
[ 6 ] Wu X, Shen J, Li Y, Lee KY. Steam power plant configuration, design, and control. Wiley Interdiscip Rev Energy Environ 2015;4(6):537–63. 链接1
[ 7 ] Mukati K, Rasch M, Ogunnaike BA. An alternative structure for next generation regulatory controllers. Part II: stability analysis, tuning rules and experimental validation. J Process Contr 2009;19(2):272–87. 链接1
[ 8 ] Ellis M, Durand H, Christofides PD. A tutorial review of economic model predictive control methods. J Process Contr 2014;24(8):1156–78. 链接1
[ 9 ] Bindlish R. Power scheduling and real-time optimization of industrial cogeneration plants. Comput Chem Eng 2016;87:257–66. 链接1
[10] Ma J, Jiang J. Applications of fault detection and diagnosis methods in nuclear power plants: a review. Prog Nucl Energy 2011;53(3):255–66. 链接1
[11] Sun L, Sun W, You F. Core temperature modelling and monitoring of lithiumion battery in the presence of sensor bias. Appl Energy 2020;271:115243. 链接1
[12] Sun L, Li D, Lee KY. Optimal disturbance rejection for PI controller with constraints on relative delay margin. ISA Trans 2016;63:103–11. 链接1
[13] Ponce CV, Saez D, Bordons C, Núñez A. Dynamic simulator and model predictive control of an integrated solar combined cycle plant. Energy 2016;109:974–86. 链接1
[14] Facci AL, Andreassi L, Ubertini S. Optimization of CHCP (combined heat power and cooling) systems operation strategy using dynamic programming. Energy 2014;66:387–400. 链接1
[15] Marano V, Rizzo G, Tiano FA. Application of dynamic programming to the optimal management of a hybrid power plant with wind turbines, photovoltaic panels and compressed air energy storage. Appl Energy 2012;97:849–59. 链接1
[16] Liu J, Luo W, Yang X, Wu L. Robust model-based fault diagnosis for PEM fuel cell air-feed system. IEEE Trans Ind Electron 2016;63(5):3261–70. 链接1
[17] Liu X, Cui J. Economic model predictive control of boiler–turbine system. J Process Contr 2018;66:59–67. 链接1
[18] Kuboth S, Heberle F, König-Haagen A, Brüggemann D. Economic model predictive control of combined thermal and electric residential building energy systems. Appl Energy 2019;240:372–85. 链接1
[19] Zhou T, Song Z, Sundmacher K. Big data creates new opportunities for materials research: a review on methods and applications of machine learning for materials design. Engineering 2019;5(6):1017–26. 链接1
[20] Radovic A, Williams M, Rousseau D, Kagan M, Bonacorsi D, Himmel A, et al. Machine learning at the energy and intensity frontiers of particle physics. Nature 2018;560(7716):41–8. 链接1
[21] Yosipof A, Nahum OE, Anderson AY, Barad HN, Zaban A, Senderowitz H. Data mining and machine learning tools for combinatorial material science of alloxide photovoltaic cells. Mol Inform 2015;34(6–7):367–79. 链接1
[22] Shang C, You F. Data analytics and machine learning for smart process manufacturing: recent advances and perspectives in the big data era. Engineering 2019;5(6):1010–6. 链接1
[23] Dey A. Machine learning algorithms: a review. Int J Comput Sci Inf Technol 2016;7(3):1174–9. 链接1
[24] Liu Q, Jin QB, Huang B, Liu M. Iteration tuning of disturbance observer-based control system satisfying robustness index for FOPTD processes. IEEE Trans Control Syst Technol 2017;25(6):1978–88. 链接1
[25] Hou Z, Gao H, Lewis FL. Data-driven control and learning systems. IEEE Trans Ind Electron 2017;64(5):4070–5. 链接1
[26] Hou ZS, Wang Z. From model-based control to data-driven control: survey, classification and perspective. Inf Sci 2013;235:3–35. 链接1
[27] Brockett R. New issues in the mathematics of control. In: Engquist B, Schmid W, editors. Mathematics unlimited—2001 and beyond. Berlin: Springer; 2001. p. 189–219. 链接1
[28] Unbehauen H, Rao GP. A review of identification in continuous-time systems. Annu Rev Control 1998;22:145–71. 链接1
[29] Sun L, Li D, Hu K, Lee KY, Pan F. On tuning and practical implementation of active disturbance rejection controller: a case study from a regenerative heater in a 1000 MW power plant. Ind Eng Chem Res 2016;55(23):6686–95. 链接1
[30] Sun L, Li G, Hua QS, Jin Y. A hybrid paradigm combining model-based and data-driven methods for fuel cell stack cooling control. Renew Energy 2020;147:1642–52. 链接1
[31] Zhu H, Shen J, Lee KY, Sun L. Multi-model based predictive sliding mode control for bed temperature regulation in circulating fluidized bed boiler. Control Eng Pract 2020;101:104484. 链接1
[32] Åström KJ, Hägglund T. Advanced PID control. Research Triangle Park: The Instrumentation, Systems, and Automation Society; 2006. 链接1
[33] Jin Y, Sun L, Hua Q, Chen S. Experimental research on heat exchanger control based on hybrid time and frequency domain identification. Sustainability 2018;10(8):2667. 链接1
[34] Wu X, Wang M, Liao P, Shen J, Li Y. Solvent-based post-combustion CO2 capture for power plants: a critical review and perspective on dynamic modelling, system identification, process control and flexible operation. Appl Energy 2020;257:113941. 链接1
[35] Ettihir K, Boulon L, Agbossou K. Energy management strategy for a fuel cell hybrid vehicle based on maximum efficiency and maximum power identification. IET Electr Syst Transp 2016;6(4):261–8. 链接1
[36] Belmokhtar K, Ibrahim H, Merabet A. Online parameter identification for a DFIG driven wind turbine generator based on recursive least squares algorithm. In: Proceedings of 2015 IEEE 28th Canadian Conference on Electrical and Computer Engineering (CCECE); 2015 May 3–6; Halifax, NS, Canada. New York: IEEE; 2015. p. 965–9. 链接1
[37] Xiao W, Lind MGJ, Dunford WG, Capel A. Real-time identification of optimal operating points in photovoltaic power systems. IEEE Trans Ind Electron 2006;53(4):1017–26. 链接1
[38] Xu Y, Jin W, Zhu X. Parameter identification of photovoltaic cell based on improved recursive least square method. In: Proceedings of 2017 20th International Conference on Electrical Machines and Systems (ICEMS); 2017 Aug 11–14; Sydney, NSW, Australia. New York: IEEE; 2017. p. 1–5. 链接1
[39] Lu H, Zhang Y, Wu C, Sun W. Dynamic model identification of the main steam temperature for supercritical once-through boiler. Energy Procedia 2012;17 (Pt B):1704–9. 链接1
[40] Dai H, Xu T, Zhu L, Wei X, Sun Z. Adaptive model parameter identification for large capacity Li-ion batteries on separated time scales. Appl Energy 2016;184:119–31. 链接1
[41] Lebbal ME, Lecœuche S. Identification and monitoring of a PEM electrolyser based on dynamical modelling. Int J Hydrogen Energy 2009;34(14): 5992–9. 链接1
[42] Xia B, Zhao X, De Callafon R, Garnier H, Nguyen T, Mi C. Accurate lithium-ion battery parameter estimation with continuous-time system identification methods. Appl Energy 2016;179:426–36. 链接1
[43] Song Z, Hofmann H, Lin X, Han X, Hou J. Parameter identification of lithiumion battery pack for different applications based on Cramer–Rao bound analysis and experimental study. Appl Energy 2018;231:1307–18. 链接1
[44] Song Z, Hou J, Hofmann HF, Lin X, Sun J. Parameter identification and maximum power estimation of battery/supercapacitor hybrid energy storage system based on Cramer–Rao bound analysis. IEEE Trans Power Electron 2019;34(5):4831–43. 链接1
[45] Yang B, Wang J, Zhang M, Shu H, Yu T, Zhang X, et al. A state-of-the-art survey of solid oxide fuel cell parameter identification: modelling, methodology, and perspectives. Energy Convers Manage 2020;213:112856. 链接1
[46] Yang B, Wang J, Zhang X, Yu T, Yao W, Shu H, et al. Comprehensive overview of meta-heuristic algorithm applications on PV cell parameter identification. Energy Convers Manage 2020;208:112595. 链接1
[47] Chen Z, Yuan X, Tian H, Ji B. Improved gravitational search algorithm for parameter identification of water turbine regulation system. Energy Convers Manage 2014;78:306–15. 链接1
[48] Buchholz M, Eswein M, Krebs V. Modelling PEM fuel cell stacks for FDI using linear subspace identification. In: Proceedings of 2008 IEEE International Conference on Control Applications; 2008 Sep 3–5; San Antonio, TX, USA. New York: IEEE; 2008. p. 341–6. 链接1
[49] Chen S, Xi Z, Yong H. Model identification of reheated steam temperature in 600 MW ultra-supercritical unit. In: Proceedings of 2015 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration; 2015 Dec 3–4; Wuhan, China. New York: IEEE; 2015. p. 148–51.
[50] Hadavand A, Jalali AA, Famouri P. An innovative bed temperature-oriented modeling and robust control of a circulating fluidized bed combustor. Chem Eng J 2008;140(1–3):497–508. 链接1
[51] Buchholz M, Krebs V. Dynamic modelling of a polymer electrolyte membrane fuel cell stack by nonlinear system identification. Fuel Cells 2007;7 (5):392–401. 链接1
[52] Da Costa LF, Watanabe EH, Rolim LGB. A control-oriented model of a PEM fuel cell stack based on NARX and NOE neural networks. IEEE Trans Ind Electron 2015;62(8):5155–63. 链接1
[53] Liu XJ, Kong XB, Hou GL, Wang JH. Modeling of a 1000 MW power plant ultra super-critical boiler system using fuzzy-neural network methods. Energy Convers Manage 2013;65:518–27. 链接1
[54] Kouadri A, Namoun A, Zelmat M. Modelling the nonlinear dynamic behaviour of a boiler–turbine system using a radial basis function neural network. Int J Robust Nonlinear Control 2014;24(13):1873–86. 链接1
[55] Gunasekar N, Mohanraj M, Velmurugan V. Artificial neural network modeling of a photovoltaic–thermal evaporator of solar assisted heat pumps. Energy 2015;93(Pt 1):908–22. 链接1
[56] Kang YW, Li J, Cao GY, Tu HY, Li J, Yang J. Dynamic temperature modeling of an SOFC using least squares support vector machines. J Power Sources 2008;179(2):683–92. 链接1
[57] Marugán AP, Márquez FPG, Perez JMP, Ruiz-Hernández D. A survey of artificial neural network in wind energy systems. Appl Energy 2018;228:1822–36. 链接1
[58] Li CH, Zhu XJ, Cao GY, Sui S, Hu MR. Identification of the Hammerstein model of a PEMFC stack based on least squares support vector machines. J Power Sources 2008;175(1):303–16. 链接1
[59] Tan P, He B, Zhang C, Rao D, Li S, Fang Q, et al. Dynamic modeling of NOX emission in a 660 MW coal-fired boiler with long short-term memory. Energy 2019;176:429–36. 链接1
[60] Patwardhan SC, Prakash J, Shah SL. Soft sensing and state estimation: review and recent trends. IFAC Proc 2007;40(19):65–72. 链接1
[61] Kadlec P, Grbic´ R, Gabrys B. Review of adaptation mechanisms for data-driven soft sensors. Comput Chem Eng 2011;35(1):1–24. 链接1
[62] Kadlec P, Gabrys B, Strandt S. Data-driven soft sensors in the process industry. Comput Chem Eng 2009;33(4):795–814. 链接1
[63] Su Z, Wang P, Shen J, Yu X, Lv Z, Lu L. Multi-model strategy based evidential soft sensor model for predicting evaluation of variables with uncertainty. Appl Soft Comput 2011;11(2):2595–610. 链接1
[64] Gao XH, Su ZG. Artificial bee colony optimization of NOx emission and reheat steam temperature in a 1000 MW boiler. Math Probl Eng 2019;2019:1–13. 链接1
[65] Shinskey FG. Process control: as taught vs as practiced. Ind Eng Chem Res 2002;41(16):3745–50. 链接1
[66] Yang ZK, Liu CY, Song XL, Song ZY, Wang ZS. Application of RBF neural network PID in wet flue gas desulfurization of thermal power plant. In: Proceedings of 2016 International Conference on Machine Learning and Cybernetics (ICMLC). 2016 Jul 10–13; Jeju, Republic of Korea. New York: IEEE; 2016. p. 301–6.
[67] Damour C, Benne M, Lebreton C, Deseure J, Grondin-Perez B. Real-time implementation of a neural model-based self-tuning PID strategy for oxygen stoichiometry control in PEM fuel cell. Int J Hydrogen Energy 2014;39 (24):12819–25. 链接1
[68] Azali S, Sheikhan M. Intelligent control of photovoltaic system using BPSOGSA-optimized neural network and fuzzy-based PID for maximum power point tracking. Appl Intell 2016;44(1):88–110. 链接1
[69] Xing Z, Li Q, Su X, Guo H. Application of BP neural network for wind turbines. In: Proceedings of 2009 Second International Conference on Intelligent Computation Technology and Automation; 2009 Oct 10–11; Changsha, China. New York: IEEE; 2009. p. 42–4. 链接1
[70] Asgharnia A, Shahnazi R, Jamali A. Performance and robustness of optimal fractional fuzzy PID controllers for pitch control of a wind turbine using chaotic optimization algorithms. ISA Trans 2018;79:27–44. 链接1
[71] Ou K, Wang YX, Li ZZ, Shen YD, Xuan DJ. Feedforward fuzzy-PID control for air flow regulation of PEM fuel cell system. Int J Hydrogen Energy 2015;40 (35):11686–95. 链接1
[72] Lygouras JN, Botsaris PN, Vourvoulakis J, Kodogiannis V. Fuzzy logic controller implementation for a solar air-conditioning system. Appl Energy 2007;84 (12):1305–18. 链接1
[73] Haji Haji V, Monje CA. Fractional order fuzzy-PID control of a combined cycle power plant using particle swarm optimization algorithm with an improved dynamic parameters selection. Appl Soft Comput 2017;58:256–64. 链接1
[74] Zhang S, Taft CW, Bentsman J, Hussey A, Petrus B. Simultaneous gains tuning in boiler/turbine PID-based controller clusters using iterative feedback tuning methodology. ISA Trans 2012;51(5):609–21. 链接1
[75] Han J. From PID to active disturbance rejection control. IEEE Trans Ind Electron 2009;56(3):900–6. 链接1
[76] Sun L, Zhang Y, Li D, Lee KY. Tuning of active disturbance rejection control with application to power plant furnace regulation. Control Eng Pract 2019;92:104122. 链接1
[77] Sun L, Hua Q, Shen J, Xue Y, Li D, Lee KY. Multi-objective optimization for advanced superheater steam temperature control in a 300 MW power plant. Appl Energy 2017;208:592–606. 链接1
[78] Chakib R, Cherkaoui M, Essadki A. Inertial response used for a short term frequency control for DFIG wind turbine controlled by ADRC. ARPN J Eng Appl Sci 2016;11(5):2916–22. 链接1
[79] Yu Y, Hu X. Active disturbance rejection control strategy for grid-connected photovoltaic inverter based on virtual synchronous generator. IEEE Access 2019;7:17328–36. 链接1
[80] Sun L, Jin Y, You F. Active disturbance rejection temperature control of opencathode proton exchange membrane fuel cell. Appl Energy 2020;261:114381. 链接1
[81] Sun L, Shen J, Hua Q, Lee KY. Data-driven oxygen excess ratio control for proton exchange membrane fuel cell. Appl Energy 2018;231:866–75. 链接1
[82] Ahn HS, Chen YQ, Moore KL. Iterative learning control: brief survey and categorization. IEEE Trans Syst Man Cybern Part C 2007;37(6): 1099–121. 链接1
[83] Pan T, Shen J, Sun L, Lee KY. Thermodynamic modelling and intelligent control of fuel cell anode purge. Appl Therm Eng 2019;154:196–207. 链接1
[84] Tutty OR, Blackwell M, Rogers E, Sandberg R. Computational fluid dynamics based iterative learning control of peak loads in wind turbines. In: Proceedings of 2012 IEEE 51st IEEE Conference on Decision and Control (CDC); 2012 Dec 10–12; Maui, HI, USA. New York: IEEE; 2012. p. 3948–53. 链接1
[85] Liu H, Li S, Chai T. Intelligent decoupling control of power plant main steam pressure and power output. Int J Electr Power Energy Syst 2003;25 (10):809–19. 链接1
[86] Thounthong P, Luksanasakul A, Koseeyaporn P, Davat B. Intelligent modelbased control of a standalone photovoltaic/fuel cell power plant with supercapacitor energy storage. IEEE Trans Sustain Energy 2013;4(1): 240–9. 链接1
[87] Wang W, Li HX, Zhang J. Intelligence-based hybrid control for power plant boiler. IEEE Trans Control Syst Technol 2002;10(2):280–7. 链接1
[88] Sun L, Dong J, Li D, Lee KY. A practical multivariable control approach based on inverted decoupling and decentralized active disturbance rejection control. Ind Eng Chem Res 2016;55(7):2008–19. 链接1
[89] Sun L, Hua Q, Li D, Pan L, Xue Y, Lee KY. Direct energy balance based active disturbance rejection control for coal-fired power plant. ISA Trans 2017;70:486–93. 链接1
[90] Wu X, Shen J, Li Y, Lee KY. Data-driven modeling and predictive control for boiler–turbine unit using fuzzy clustering and subspace methods. ISA Trans 2014;53(3):699–708. 链接1
[91] Wang X, Huang B, Chen T. Data-driven predictive control for solid oxide fuel cells. J Process Contr 2007;17(2):103–14. 链接1
[92] Wu X, Shen J, Sun S, Li Y, Lee KY. Data-driven disturbance rejection predictive control for SCR denitrification system. Ind Eng Chem Res 2016;55 (20):5923–30. 链接1
[93] Wu X, Shen J, Li Y, Wang M, Lawal A. Flexible operation of post-combustion solvent-based carbon capture for coal-fired power plants using multi-model predictive control: a simulation study. Fuel 2018;220:931–41. 链接1
[94] Zeng P, Li HP, He HB, Li SH. Dynamic energy management of a microgrid using approximate dynamic programming and deep recurrent neural network learning. IEEE Trans Smart Grid 2019;10(4):4435–45. 链接1
[95] Kim TY, Kim BS, Park TC, Yeo YK. Model-based control of a molten carbonate fuel cell (MCFC) process. Korean J Chem Eng 2018;35(1):118–28. 链接1
[96] Dong Z, Zhang Z, Dong Y, Huang X. Multi-layer perception based model predictive control for the thermal power of nuclear superheated-steam supply systems. Energy 2018;151:116–25. 链接1
[97] Liu S, Sun L, Zhu S, Li J, Chen X, Zhong W. Operation strategy optimization of desulfurization system based on data mining. Appl Math Model 2020;81:144–58. 链接1
[98] Gu Y, Zhao W, Wu Z. Online adaptive least squares support vector machine and its application in utility boiler combustion optimization systems. J Process Contr 2011;21(7):1040–8. 链接1
[99] More A, Deo MC. Forecasting wind with neural networks. Mar Struct 2003;16 (1):35–49. 链接1
[100] Li F, Ren G, Lee J. Multi-step wind speed prediction based on turbulence intensity and hybrid deep neural networks. Energy Convers Manage 2019;186:306–22. 链接1
[101] Wang Y, Wang H, Srinivasan D, Hu Q. Robust functional regression for wind speed forecasting based on sparse Bayesian learning. Renew Energy 2019;132:43–60. 链接1
[102] Ning C, You F. Data-driven adaptive robust unit commitment under wind power uncertainty: a Bayesian nonparametric approach. IEEE Trans Power Syst 2019;34(3):2409–18. 链接1
[103] Papaefthymiou G, Klockl B. MCMC for wind power simulation. IEEE Trans Energy Convers 2008;23(1):234–40. 链接1
[104] Feng C, Cui M, Hodge BM, Zhang J. A data-driven multi-model methodology with deep feature selection for short-term wind forecasting. Appl Energy 2017;190:1245–57. 链接1
[105] Yildiz B, Bilbao JI, Sproul AB. A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renew Sust Energ Rev 2017;73:1104–22. 链接1
[106] Voyant C, Notton G, Kalogirou S, Nivet ML, Paoli C, Motte F, et al. Machine learning methods for solar radiation forecasting: a review. Renew Energy 2017;105:569–82. 链接1
[107] Sutton RS, Barto AG. Reinforcement learning: an introduction. IEEE Trans Neural Netw 1998;9(5):1054. 链接1
[108] Ren Y, Liao Z, Sun J, Jiang B, Wang J, Yang Y, et al. Molecular reconstruction: recent progress toward composition modeling of petroleum fractions. Chem Eng J 2019;357:761–75. 链接1
[109] Liao Z, Hu Y, Wang J, Yang Y, You F. Systematic design and optimization of a membrane–cryogenic hybrid system for CO2 capture. ACS Sustain Chem Eng 2019;7(20):17186–97. 链接1
[110] Jasmin EA, Imthias Ahamed TP, Jagathy Raj VP. Reinforcement learning approaches to economic dispatch problem. Int J Electr Power Energy Syst 2011;33(4):836–45. 链接1
[111] Wei C, Zhang Z, Qiao W, Qu L. Reinforcement-learning-based intelligent maximum power point tracking control for wind energy conversion systems. IEEE Trans Ind Electron 2015;62(10):6360–70. 链接1
[112] Kofinas P, Dounis AI, Vouros GA. Fuzzy Q-learning for multi-agent decentralized energy management in microgrids. Appl Energy 2018;219:53–67. 链接1
[113] Hua H, Qin Y, Hao C, Cao J. Optimal energy management strategies for energy Internet via deep reinforcement learning approach. Appl Energy 2019;239: 598–609. 链接1
[114] Yang T, Zhao L, Li W, Zomaya AY. Reinforcement learning in sustainable energy and electric systems: a survey. Annu Rev Control 2020;49:145–63. 链接1
[115] Odgaard PF, Mataji B. Observer-based fault detection and moisture estimating in coal mills. Control Eng Pract 2008;16(8):909–21. 链接1
[116] Peter O, Lin B, Sten J. Observer-based and regression model-based detection of emerging faults in coal mills. IFAC Proc 2006;39(13):687–92. 链接1
[117] Yin S, Wang G, Karimi HR. Data-driven design of robust fault detection system for wind turbines. Mechanism 2014;24(4):298–306. 链接1
[118] Schlechtingen M, Ferreira SI. Comparative analysis of neural network and regression based condition monitoring approaches for wind turbine fault detection. Mech Syst Signal Process 2011;25(5):1849–75. 链接1
[119] Lowery Natalie LH, Vahdati Maria M, Potthast Roland WE, Holderbaum W. Classification and fault detection methods for fuel cell monitoring and quality control. J Fuel Cell Scl Tech 2013;10(2):021002. 链接1
[120] Salahshoor K, Kordestani M, Khoshro MS. Fault detection and diagnosis of an industrial steam turbine using funsion of SVM (support vector machine) and ANFIS (adaptive neuro-fuzzy inference system) classifiers. Energy 2010;35 (12):5472–82. 链接1
[121] Moradi M, Chaibakhsh A, Ramezani A. An intelligent hybrid technique for fault detection and condition monitoring of a thermal power plant. Appl Math Model 2018;60:34–47. 链接1
[122] Shafer G. A mathematical theory of evidence. Princeton: Princeton University Press; 1976. 链接1
[123] Smets P, Kennes R. The transferable belief model. Artif Intell 1994;66 (2):191–234. 链接1
[124] Denz´ux T. 40 years of Dempster–Shafer theory. Int J Approx Reason 2016;79:1–6. 链接1
[125] Dempster AP. Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat 1967;38(2):325–39. 链接1
[126] Ma S, Jia B, Wu J, Yuan Y, Jiang Y, Li W. Multi-vibration information fusion for detection of HVCB faults using CART and D-S evidence theory. ISA Trans. In press.
[127] Su ZG, Wang PH. Improved adaptive evidential k-NN rule and its application for monitoring level of coal powder filling in ball mill. J Process Contr 2009;19(10):1751–62. 链接1
[128] Su ZG. Research on theory of belief function and modelling for cognizing unmeasured parameters in power system [dissertation]. Nanjing: Southeast University; 2010. Chinese. 链接1
[129] Chen XL, Wang PH, Hao YS, Zhao M. Evidential KNN-based condition monitoring and early warning method with applications in power plant. Neurocomputing 2018;315:18–32. 链接1











 京公网安备 11010502051620号
京公网安备 11010502051620号




