《1 前言》
1 前言
随着计算机技术的迅速发展, 模式识别由于其科学应用价值, 在自动化技术、人工智能及各种信息处理的研究领域中受到越来越大的重视
[1,2,3]。实质上, 模式识别的主要任务是从数据中发现知识, 它要求能从提供的数据中挖掘数据之间的内在联系, 寻找系统的内在规律, 利用优化计算方法, 进行自组织分类或按某种导师要求分类, 因此分类是模式识别的基础, 一旦分类完成了, 机器就可以根据分类进行自动识别了。
模糊中心聚类作为分类的有力工具, 在以模糊逻辑、人工神经网络等为代表的智能计算
[4,5,6,7,8,9] , 在模式识别的研究领域中获得广泛应用, 主要是利用了这些方法在时空数据统计描述的自组织以及一些相互关联的活动中, 自动获取知识功能的非线性映射和聚类特性, 将输入数据通过某种非线性结构映射到输出空间。因此, 模糊中心聚类作为从提供的数据中挖掘数据之间的内在联系, 寻找系统的内在规律的优化计算方法研究, 具有十分重要的理论意义和实用价值。
传统的模糊中心聚类
[4,10,11] 是根据隶属函数MF的面积中心方法计算的, 通过计算每一个输入矢量与中心的距离来实现聚类。存在隶属函数的构建和解模糊化即MF的面积中心的计算工作量的问题。
首先把计算每一个输入矢量与中心的距离来实现聚类作为一个约束情况下的非线性规划问题, 从优化计算的角度推出聚类中心和构造一个模糊隶属函数MF, 然后从递推计算的角度, 提出无导师的递推学习方法来修改模糊聚类中心和隶属函数;最后提出的一种基于模糊中心聚类学习的神经网络来实现并行数据处理和模式分类。
《2 优化计算与模糊中心聚类》
2 优化计算与模糊中心聚类
在模式识别中, 假设输入矢量集X={X1, X2, …, Xp}⊂Rp×s, 每一个矢量有s个元素, 代表一个矢量的分量, 即 Xj={xj1, xj2, …, xjs}⊂Rs。
如果要将输入矢量集X={X1, X2, …, Xp}⊂Rp×s划分为c个类别。反过来说, 输入矢量集中p个矢量分别属于c个类别的隶属度可以列成下面的隶属函数矩阵
μ=⎡⎣⎢⎢μ11⋮μc1μ12⋮μc2⋯⋯μ1p⋮μcp⎤⎦⎥⎥ (1)
其中 μij (i=1, 2, …, c; j=1, 2, …, p) 表示第j个矢量Xj属于第i个类别的隶属度。显然, 每一列表达了第j个矢量Xj分别属于c个类别的隶属度, 它应该满足
∑i=1cμij=1‚j=1,2,⋯,p‚1≥μij≥0 (2)
模糊聚类的任务是根据输入矢量集X= {X1, X2, …, Xp}⊂Rp×s, 求出它们划分为c个类别的隶属函数矩阵, 或者把输入矢量集X映射为隶属函数矩阵μ={μij}⊂Rp×s。当求出了μ={μij}⊂Rp×s, 对第j个矢量Xj分别属于c个类别的隶属度矢量 μj= (μ1j, μ2j, …, μcj) 作极大运算, 如果要求硬划分, 则输出类别可用阶跃函数硬限幅输出, 就实现了模式分类。因此, 确定隶属函数形式具有重要意义。
定理1 模糊中心聚类方法, 当其聚类中心vi为模糊聚类中心价值函数的极小值时, 隶属函数可取
μij=1/∑k=1c(dij/dkj)2/(m−1)‚i=1,2,⋯,c,j=1,2,⋯,p。
证明 定义模糊聚类中心vi= (vi1, vi2, …, vis) ⊂Rs, vi (i=1, 2, …, c) 代表每一个聚类在输入空间中的中心矢量, 则第j个输入矢量Xj与第i个模糊聚类中心vi的距离定义为
dij=∥vi−Xj∥=[∑l=1s(vil−xjl)2]1/2‚i=1,2,⋯,c,j=1,2,⋯,p (3)dij≥0。
J(X‚μ,v)=∑i=1c∑j=1pμijmd2ij=∑i=1c∑j=1pμijm∥vi−Xj∥2 (4)
对于输入矢量集X={X1, X2, …, Xp}⊂Rp×s, 当存在下列约束条件时:
∑i=1cμij=1‚1≥μij≥0‚i=1,2,⋯,c,j=1,2,⋯,p (5)dij=∥vij−Xj∥‚dij≥0。
要求实函数J(X,μ,v)=∑i=1c∑j=1pμijmd2ij=∑i=1c∑j=1pμijm∥vi−Xj∥2的极小值, 构造一个Lagrange 函数:
L(X,μ,v‚λ)=J(X,μ,v)+∑j=1pλj(1−∑i=1cμij) (6)
式中 λ= (λ1, λ2, …, λp) T∈ R 是Lagrange乘数算子。
∂J(X,μ‚v)∂vi+∑j=1pλij∂∂vi(1−∑i=1cμij)=0 (7)
vi=∑j=1pμijmXj/∑j=1pμijm‚i=1,2,⋯,c (8)
∂J(X,μ,v)∂μij+∑j=1pλij∂∂μij(1−∑i=1cμij)=0 (9)
μij=(λ/md2ij)1/(m−1)‚i=1,2,⋯,c (10)
∑k=1cμkj=∑k=1c(λ/md2kj)1/(m−1)=λ1/(m−1)∑i=1c(1/md2kj)1/(m−1) (11)
由约束条件∑k=1cμkj=1, 可得
λ1/(m−1)=1/∑k=1c(1/md2kj)1/(m−1) (12)
μij=1/∑k=1c(dij/dkj)2/(m−1)‚i=1,2,⋯,c,j=1,2,⋯,p (13)
为了计算第j个矢量Xj分别属于c个类别的隶属度矢量μj= (μ1j, μ2j, …, μcj) , 需要计算第j个输入矢量Xj与第i个模糊聚类中心vi的距离dij=‖vi-Xj‖, 这就要求得到每一个聚类在输入空间中的模糊聚类中心vi, 而vi又是隶属度μij的函数。因此, 为了计算第j个矢量Xj分别属于c个类别的隶属度矢量μj, 必须推出模糊聚类中心vi的学习方法。
推论1 模糊中心聚类可由无导师在线学习实现, 其聚类中心vi=∑j=1pμijmXj/∑j=1pμijm可用递归计算公式 vi (n+1) =vi (n) + ηi (n+1) · (Xn+1-vi (n) ) , i=1, 2, …, c进行, 其中ηi(n+1)=μi,n+1m/∑j=1n+1μijm是第n+1输入矢量时, 递归计算过程中的一个动态常数。
证明 根据式 (8) , 设n (1≤n≤p) 输入矢量时的模糊聚类中心为
vi(n)=∑j=1nμijmXj/∑j=1nμijm‚i=1,2,⋯,c (14)
μij=1/∑k=1c(dij/dkj)2/(m−1)‚i=1,2,⋯,c,j=1,2,⋯,n (15)
dij=∥vi−Xj∥=[∑l=1s(vil−xjl)2]1/2 (16)
定义第n+1 (1≤n≤p) 输入矢量时的模糊聚类中心为
vi(n+1)=∑j=1n+1μijmXj/∑j=1n+1μijm‚i=1,2,⋯,c (17)
vi(n+1)=∑j=1n+1μijmXj/∑j=1n+1μijm=(∑j=1nμijmXj+μi,n+1mXn+1)/∑j=1n+1μijm (18)
vi(n+1)=(vi(n)∑j=1nμijm+μi,n+1mXn+1)/∑j=1n+1μijm=(vi(n)(∑j=1n+1μijm−μi,n+1m)+μi,n+1mXn+1)/∑j=1n+1μijm=(vi(n)∑j=1n+1μijm−vi(n)μin+1m+μi,n+1mXn+1)/∑j=1n+1μijm=vi(n)+μi,n+1m(Xn+1−vi(n))/∑j=1n+1μijm (19)
令第n+1输入矢量时, 递归计算过程中的一个动态常数为
ηi(n+1)=μi‚n+1m/∑j=1n+1μijm,i=1,2,⋯,c (20)
vi(n+1)=vi(n)+ηi(n+1)(Xn+1−vi(n)),i=1,2,⋯,c (21)
根据上述递归计算公式, 在线学习确定模糊聚类中心vi、隶属函数矩阵μ= {μij}的步骤如下:
Step 1 用 (0, 1) 之间的随机数初始化1, 2, …, c各个输入向量的隶属函数μ(1)(0)= (μ1i (0) , μ2i (0) , …, μij (0) ) , i=1, 2, …, c, 需要划分为多少个类别, 第一次就要初始化多少个向量, 并且这些向量不能相同, 还要注意到约束条件∑i=1cμi1(0)=1。令k=0, n=c。先计算一个模糊聚类中心:vi(k)(n)=∑j=1nμijm(k)Xk/∑j=1nμijm(k)‚i=1,2,⋯,c。
Step 2 令n=n +1, 计算第n个输入矢量的隶属函数:
μij(k)=1/∑k=1c(dij(k)/dkj(k))2/(m−1)‚
其中dij=∥vi−Xj∥=[∑l=1s(vil−xjl)2]1/2‚i=1,2,⋯,c,j=1,2,⋯,n。
Step 3 计算ηi(k)(n+1)=μi‚n+12(k)(n)/∑j=1n+1μij2(k)(n),
v(k)(n+1)=vi(k)(n)+ηi(k)(n+1)⋅(Xn+1−vi(k)(n)),i=1,2,⋯,c。
Step 4 根据v (k) (n) , 计算n个输入矢量的隶属函数:
μij(k)(n+1)=1/∑k=1c(dij(k)/dkj(k))2/(m−1)‚
其中dij=∥vi−Xj∥=[∑l=1s(vil−xjl)2]1/2‚i=1,2,⋯,c,j=1,2,⋯,n。
Step 5 当n=p时, 计算隶属度函数矩阵 |μ (k+1) (n) -μ (k) (n) | 是否小于ε, ε是一个预定的小的正实数误差值。如果小于ε, 计算停止, 得到要求的模糊聚类中心vi和隶属函数矩阵μ={μij};如果大于ε, 令k=k+1, 并令vi (k) (n) =vi (k+1) (0) 转到Step 2。
《3 模糊中心聚类仿真结果》
3 模糊中心聚类仿真结果
模糊中心聚类通过计算每个输入矢量与中心的距离来完成的。
用IRIS
[12] 数据作为算法的验证数据, 因为IRIS数据是国际公认的比较无监督分类 (聚类) 方法效果好坏的典型数据。它包含了150个4维的样本点, 聚类类别数c=3, 每一类各50个样本点, 第一类序号为1—50, 第二类序号为51—100, 第三类序号为101—150。
实验中, 给定了迭代次数上限Tmax, 如果2次迭代隶属函数矩阵的数值之差小于给定的误差ε, 将视为收敛并终止迭代。初始中心点是在样本集合范围内随机选取, 并要求不同。当c=3, m=2, Tmax=20, ε=10-6时, 得到模糊中心聚类递推学习方法的聚类结果为第一类正确分类。第二类的58, 59分到第一类, 55, 56, 59, 64, 65, 69, 71, 73, 74, 77, 78, 79, 84, 87, 88, 90, 91, 92分到第三类。第三类正确分类, 总共错分了20个数, 错分率为13.3 %。图1为目标函数值随迭代次数变化的曲线, 由图1可见, 当迭代次数超过一定值, 目标函数J (X, μ, v) 接近极小值。图2为数据分类的结果, ‘*’, ‘。' 和‘×' 分别代表3类数, 图2中只画出每个数据Xi={X1, X2, X3, X4} (i=1, 2, …, 150) 的3维向量X1, X2, X3。
《图1》

图1 目标函数值随迭代次数变化的曲线 Fig.1 A change curve of clustering objective function
《图2》

图2 c=3时IRIS数据的分类结果 Fig.2 The results of fuzzy central clustering of IRIS data (c =3)
《4 模糊中心聚类模式识别神经网络》
4 模糊中心聚类模式识别神经网络
提出的模糊中心聚类方法易于网络结构实现, 网络便于并行计算实施。在该网络的输出端加上一个正反馈硬划分结构, 就构成一个模糊中心聚类模式识别神经网络。其结构示意图见图3。
《图3》
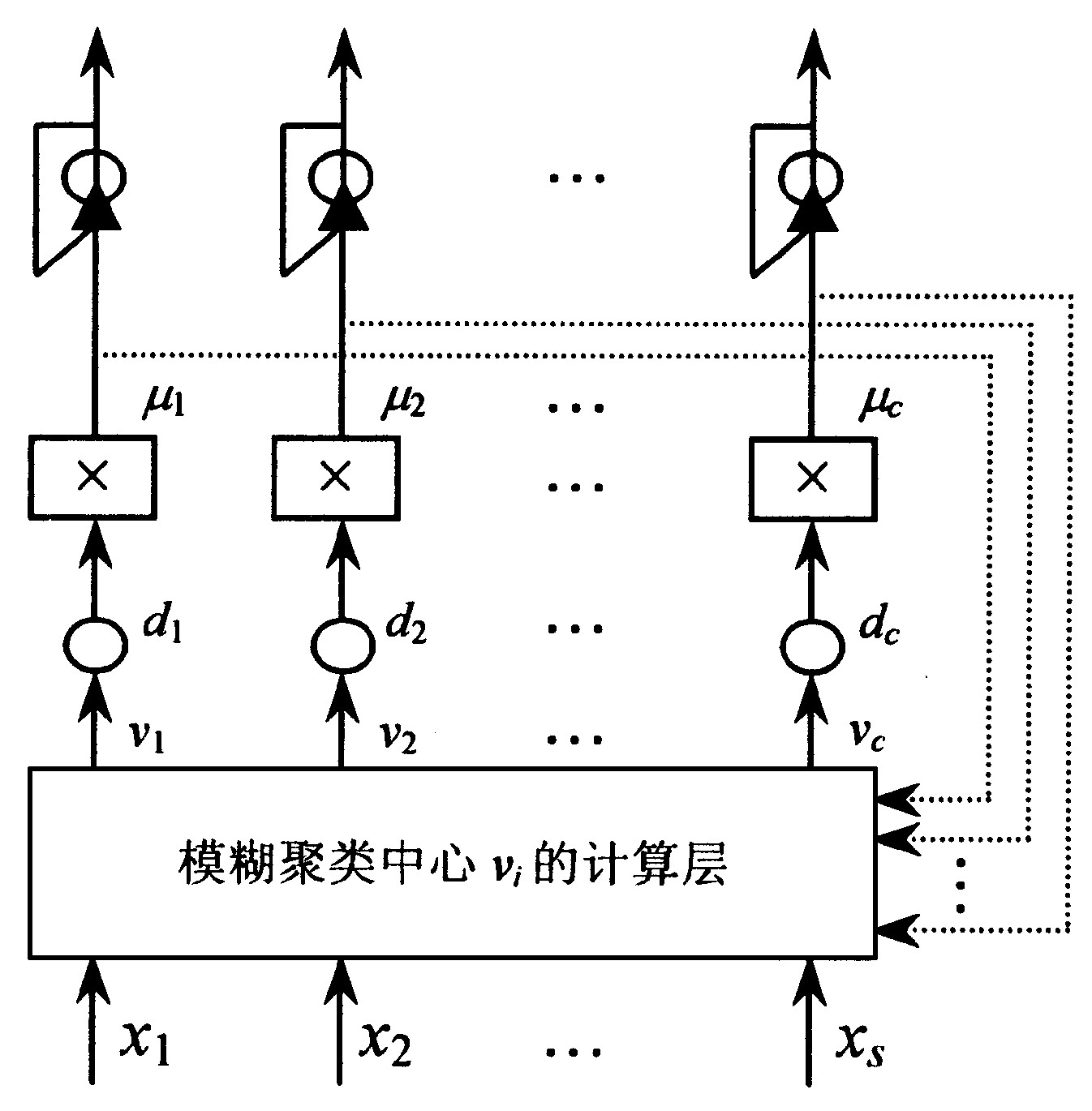
图3 模糊中心聚类模式识别神经网络实现 Fig.3 The model of fuzzy central clustering neural network
该网络的最后一层就是为实现模式分类为硬划分而设计的一个正反馈硬划分结构, 它把第j个输入矢量Xj={xj1, xj2, …, xjs} 通过网络后产生的输出隶属函数矢量, 又全部通过正反馈到该层的输入端, 最后μj= (μ1j, μ2j, …, μcj) 中的最大者通过硬限幅输出为1, 其他的输出为0。如果系统要求模式分类的软划分结果, 可以省去网络的最后一层。
网络的第三层是输出隶属函数矢量μj= (μ1j, μ2j, …, μcj) 层, 它把第二层的输出距离dij=∥vi−Xj∥=[∑l=1s(vil−xjl)2]1/2, 通过乘法器、求和器以及倒数运算, 得到隶属函数:μij=1/∑k=1c(dij/dkj)2/(m−1)。
网络第二层是距离函数计算层, 它将输入矢量Xj与每一个模糊聚类中心vi= (vi1, vi2, …, vis) , i=1, 2, …, c, 分别计算第j个输入矢量Xj与第i个模糊聚类中心vi的距离。
网络第一层是模糊聚类中心vi的计算层, 它需要一组乘法器和累加存储器完成计算∑j=1nμijm的任务, 一组相乘法和累加存储器完成计算∑j=1nμijmXj的任务, 最后输出模糊聚类中心vi=∑j=1nμijmXj/∑j=1nμijm。
利用上节推出的无导师在线递推学习确定模糊聚类中心vi, 隶属函数矩阵μ= {μij}。训练过程结束后, 取消网络中输出隶属度μ= {μij}到输入层用来确定模糊聚类中心vi的反馈。
《5 结语》
5 结语
从优化计算的角度研究了模式识别中广泛应用的模糊中心聚类问题, 首先把计算每一个输入矢量与中心的距离来实现聚类作为一个约束情况下的非线性规划问题, 证明了模糊中心聚类方法, 取一个适当的隶属函数μij=1/∑k=1c(dij/dkj)2/(m−1)‚i=1,2,⋯,c; j=1, 2, …, p, 其聚类中心vi为模糊聚类中心价值函数的极小值, 推导出基于模糊中心聚类的模式识别的无导师递推学习方法, 然后从递推计算的角度, 给出了无导师的递推学习方法来修改模糊聚类中心和隶属函数的实现步骤, 基于模糊中心聚类的模式识别的仿真结果, 证实了所提出的理论。最后提出了一种基于模糊中心聚类学习的神经网络来实现并行数据处理和模式分类, 该网络不仅具有学习速度快, 全局稳定, 而且还能完成模式识别中的硬划分和模糊划分。












 京公网安备 11010502051620号
京公网安备 11010502051620号




