

《1 引言》
1 引言
由于语音信号易受到环境的影响, 语音识别技术的环境鲁棒性引起了广泛研究
由于通常语音信号特征提取都要进行正交化处理, 这会导致窄带噪声污染扩散, 此外, 识别对象以及噪声在不同频带上能量分布存在差异, 因此, 在噪声环境下, MLLR算法采用全带单一线性变换的形式进行参数优化估计, 过于简单, 不能充分反映信号本身特性以及环境间的关系。而基于独立感知理论提出的多子带框架利用了信号的频谱特征
分析可知, 识别对象和噪声频率特性的差异, 会对系统的识别性能产生很大的影响。Bregman等听觉实验表明, 人耳可以有选择地跟踪特定频率信号
《2 算法分析》
2 算法分析
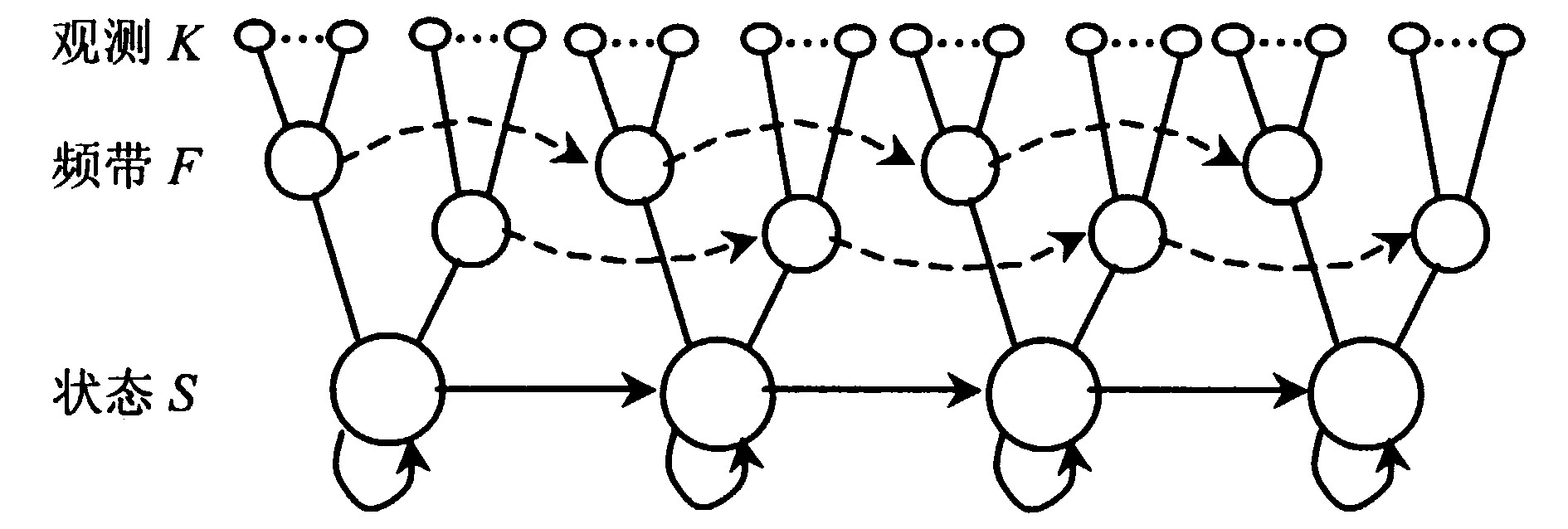
实验表明特定频带的信号受噪声污染严重, 会导致该频带识别性能的急剧恶化。在自动语音识别中, 为提高识别性能, 通常在提取语音参数时要进行正交化处理 (非正交的参数在纯净语音环境识别性能相对较差) , 这又会导致噪声污染的扩散, 使得整个识别系统性能恶化。人耳听觉实验表明, 人可以跟踪特定频带信号加以识别。为此对信号空间采用噪声污染假定方法来减少噪声污染影响。为保留频带间信号的相关性, 在信号空间进行信号合并, 同时在模型空间各频带语音信号采用帧同步分析。为此, 定义隐变量f表示互斥的频带合并策略。每个f排斥一种假定的噪声污染频带。f∈[1, …, 2L-1], 其中L表示子带个数。设多带语音识别系统中噪声环境下的观测序列为Y={yft, t∈[1, …, T], f∈[1, …, 2L-1]}, 相应的纯净语音为X={xft, t∈[1, …, T], f∈[1, …, 2L-1]}。语音信号模型采用连续密度隐Markov模型 (CDHMM) , 模型参数为Θ={{aij}, {kjf}{μjfk}, {Σjfk}}。由于采用帧同步分析, 即在HMM中各频带信号同步转移, 则多带模型中任一状态下信号观测概率密度为:
其中C=1/ (2L-1) 为常数, 以保证概率归一性。P (kt=k|st, ft) 为t时刻状态st频带ft下第k个高斯混合密度的观测概率, N (xft|μjfk, Σjfk) 为多维高斯概率密度函数。
分析式 (1) 可知, 如果噪声环境下直接采用式 (1) 进行同步概率估计, 由于状态转移的连乘关系, 会带来不同状态各频带概率估计交叉项。在纯净语音环境下, 各频带都能对语音进行较好的识别, 交叉项是在概率估计时对各频带取平均, 所以可以获得较好的识别性能, 同时利于模型的训练。但在噪声环境下, 交叉项的存在会扩展噪声的影响, 导致估计性能下降, 所以引入δ算子对似然估计修正, 限制受污染的频率信号的影响, 以此减少噪声影响的扩散, 如图1所示。
同时, 为减少环境不匹配带来的性能恶化, 假定Y与X间存在确定的映射关系, 设g:xft→yft, g (x) =Ax+b。假设环境变化仅对CDHMM观测概率的均值产生影响而其他参数保持不变, 则有
其中,
采用最大似然准则来估计参数П, 即
其中П对应线性变换参数集。
设{yft}在st=j, ft=f, kt=k时的高斯观测概率为
其中Wjfk=[bjfkAjfk]为状态j频带f混合高斯k对应的线性变换g的矩阵描述,
由于涉及隐变量, 用EM算法
其中Π为被估线性变换参数,
定义
其中cf为与频带有关的系数。
设不同频带采用不同的线性变换, 通过上述分析可以看到δ算子的引入, 对各频带线性变换参数可以进行单独估计。根据EM算法, 考虑到实际应用中可能自适应数据较少, 同频带高斯可采用相同的线性变换, 设采用相同线性变换的高斯集合为Uz, z=1, …, Z。令
得
由式 (10) 两侧相等, 通过求解一系列线性方程组可得到{Wf, ∀f}, 根据EM算法, 通过迭代, 可获取参数优化解。
《3 识别实验》
3 识别实验
识别实验是汉语普通话非特定人语音识别。为便于与LMMLLR算法比较, 采用相同的实验环境, 语音库由19个男性和11个女性近麦克风录制, 采样率8000, 8 b量化, 语料为0~9。语音参数使用MFCC
实验表明, 对于宽带噪声 (表1) , 特别是低
表1 white噪声下S算法, MLLR, LMMLLR, SMMLLR误识率 Table 1 Error-rate of S algorithm, MLLR, LMMLLR, SMMLLR in white noise
《表1》
| SNR /dB |
自适应 数据数 |
误识率/% | |||
| S算法 | MLLR | LMMLLR | SMMLLR | ||
| 0 | 5 | 74.7 | 53.7 | 46.3 | 47.6 |
| 10 | 74.7 | 51.0 | 37.0 | 42.3 | |
| 5 | 5 | 44.0 | 44.3 | 33.0 | 31.0 |
| 10 | 44.0 | 43.3 | 28.3 | 25.7 | |
| 10 | 5 | 34.6 | 40.3 | 24.3 | 21.0 |
| 10 | 34.6 | 36.7 | 22.0 | 19.6 | |
表2 babble噪声下S算法, MLLR, LMMLLR, SMMLLR误识率 Table 2 Error-rate of S algorithm, MLLR, LMLLR, SMMLLR in babble noise
《表2》
| SNR /dB |
自适应 数据数 |
误识率/% | |||
| S算法 | MLLR | LMMLLR | SMMLLR | ||
| 0 | 5 | 47.3 | 49.0 | 32.7 | 33.3 |
| 10 | 47.3 | 43.3 | 31.3 | 29.6 | |
| 5 | 5 | 40.3 | 45.3 | 26.0 | 28.0 |
| 10 | 40.3 | 33.7 | 24.3 | 24.6 | |
| 10 | 5 | 29.0 | 34.7 | 17.3 | 18.3 |
| 10 | 29.0 | 28.7 | 16.7 | 16.0 | |
表3 destroyerengine噪声下S算法, MLLR, LMMLLR, SMMLLR误识率 Table 3 Error-rate of S algorithm, MLLR, LMMLLR, SMMLLR in destroyerengine noise
《表3》
| SNR /dB |
自适应 数据数 |
误识率/% | |||
| S算法 | MLLR | LMMLLR | SMMLLR | ||
| 0 | 5 | 49.0 | 58.3 | 44.0 | 45.6 |
| 10 | 49.0 | 50.7 | 39.0 | 38.6 | |
| 5 | 5 | 40.0 | 40.3 | 26.0 | 27.0 |
| 10 | 40.0 | 36.3 | 23.7 | 23.6 | |
| 10 | 5 | 27.7 | 38.0 | 19.7 | 21.0 |
| 10 | 27.7 | 35.7 | 15.7 | 15.4 | |
信噪比环境下, 由于不满足S算法所需的信号存在不受噪声影响的频带假设, S算法的性能较差。而SMMLLR算法, 由于在最大似然估计的同时, 采用同步多带模型和噪声污染假定, 不仅不需要对信号做存在不受噪声污染的频带假设, 而且克服了S算法子带分析中不同频带间信号相关性丢失的缺陷, 因此SMMLLR不仅对于宽带噪声环境, 而且对于能量相对集中在某些频带的噪声环境下都明显地降低了误识率。如在5自适应数据、white, babble和destroyerengine 5 dB环境下, SMMLLR相对于S算法, 误识率分别下降29.5%, 30.5%和32.5%。
由于SMMLLR通过隐变量使用噪声污染假定引入信息冗余, 较好地捕捉了信号及噪声的频域特性, 并根据信号的频谱特征进行最大似然补偿, 而且同步特性又弥补了分频带导致的相关性丢失的缺陷, 因此, SMMLLR比MLLR全带统一线性假设更好地补偿了噪声环境的恶化影响, 所以SMMLLR性能上明显优于MLLR算法。如在white, babble, destroyerengine噪声0 dB环境、10自适应数据下, SMMLLR相对于MLLR, 误识率分别下降17.1%, 31.6%, 23.9%。
LMMLLR算法中各频带信号处理是独立的, 对信号处理来说较为简便。而SMMLLR算法中各频带信号处理利用了同步相关感知, 有利于模型的简化, 并且与全带分析是一致的。在不同的环境下, 两种算法性能各有优势, 这说明, 人耳为了易于理解, 总是有选择地跟踪特定频率的信号, 独立与同步是交织进行的, 这与人耳直接测试的感知效果是匹配的, 这进一步表明, 对SMMLLR和LMMLLR的研究是有效的。
需要指出:S算法需要计算L个HMM, 此外还需要建立2L-1个神经网络, 并对其进行训练和计算;LMMLLR采用独立处理方式, 不需要建立2L-1个神经网络, 需建立2L-1个HMM;而SMMLLR采用多带同步模型, 只需计算1个HMM。这说明SMMLLR算法简化了模型。
《4 结论》
4 结论
人类听觉可以从带限信号中抽取音素信息。子带分离模型的一个重要缺陷是频带间相关信息的丢失。SMMLLR算法根据听觉感知特性, 采用同步模型和噪声污染假定引入带间相关, 一定程度上克服了子带分析所要求的独立感知假设导致的带间相关性丢失, 在较少数据下就可获得较高的识别率, 而且同步模型大大减少了模型数。同时, 由于引入多带信息冗余, 根据信号频谱特性进行模型补偿, 一定程度上克服了MLLR算法全频带线性假设对环境间依存性描述不足的弱点, 从而有效地改善了识别性能。人耳对不同频率的信号处理并不是绝对的独立处理, 也不是绝对的同步处理, 感知总是根据信号的特点变化, 因此, 从听觉实验入手将进一步研究特定频率信号的感知, 改进现有识别方法。











 京公网安备 11010502051620号
京公网安备 11010502051620号




