


《1 引言》
1 引言
人脸识别是当前图像工程领域的四大研究热点之一
不同方法抽取的特征反映了模式对象在不同标准下的分类能力。在一种特征空间很难区分出来的样本, 可能在另一特征空间里可以很容易地分开。因此, 将不同方法抽取的特征有机地结合在一起, 就可能得到更好的分类性能。以前的特征抽取方法是一维的或是二维的, 还未见组合这两类特征的融合方法。笔者用一维和二维方法抽取两组特征, 用并行方法将两组特征组合成复向量, 用复主分量分析 (CPCA) 提取融合特征
《2 两种特征抽取方法》
2 两种特征抽取方法
两种特征抽取方法:一种是传统的将图像转换成一维向量, 然后用PCA, LDA或Fisherfaces等方法抽取出一组特征;另一种方法是将图像看成一个矩阵, 直接进行投影分析, 抽取出特征向量。
《2.1Fisher线性鉴别分析 (LDA)》
2.1Fisher线性鉴别分析 (LDA)
设向量样本集{X}, 所属类别分别为ωI, ω2, …, ωC, 总类别数为C。LDA
其中类间散度矩阵Sb、类内散度矩阵Sw和总体散度矩阵St分别为
mi为类别ωi的均值, P (ωi) 为其先验概率, m0为样本总体均值。求解准则函数式 (1) 的d个最佳投影轴等同于求解广义特征方程
的d个最大本征值的本征向量φ1, φ2, …, φd。
特征抽取Y为
讨论Sw奇异情况下求解最优投影轴的文章很多, 如Fisherfaces方法
采用扩大样本集和对图像降维方法也可使类内散布矩阵为非奇异阵。
《2.2二维特征抽取方法2DPCA》
2.2二维特征抽取方法2DPCA
二维主分量分析 (2DPCA)
其中P (ωi) 为第i类模式的先验概率, 一般取P (ωi) =ni/N。
2DPCA也可以取Gb的最大的d个本征值对应的标准正交的本征向量为最优投影轴进行投影, 抽取特征, 一般可取得比用总体散度矩阵更好的识别率。同时, Gt的计算与训练样本的总数N有关, 而Gb的计算与类别数C有关, Gb的计算量比Gt小。
特征抽取方法:
设最优图像投影轴为X1, …, Xd, 令
《3 两组特征的融合策略》
3 两组特征的融合策略
设同一个样本的用2种方法抽取出的特征向量分别为α和β, 用复向量γ=α+iθβ (θ>0, 为加权系数) 来表示并行组合后的特征。若2组特征α与β的维数不等, 低维的特征向量用零补足。例如, α= (a1, a2, a3) T, β= (b1, b2) T, 则γ= (a1+ib1, a2+ib2, a3+i0) T表示组合后的特征向量。二维方法抽取的特征Y与一维方法抽取出的特征一起组合时, 先将Y拉直成一个向量, 再进行相应的组合。
两组特征之间的值可能相差很大, 组合前应进行预处理。将特征样本α与β分别进行标准化处理:Y= (X-μ) /σ, 其中, X为n 维特征样本, μ为训练样本的均值向量,
简单地取θ=1, 要取其最佳是比较困难的。一般考虑两点, 一是用单个特征α或β的分类能力, 即取θ=β 或θ=α;二是α与β的维数不等时, 令δ表示特征α与β的维数之比, 则可根据δ是否大于1在区间 (δ, δ2) 内或在 (δ2, δ) 内选取θ。组合后的特征如果直接用于分类, 并不能提高识别率, 有时识别率还会降低。组合后的特征应当在复向量空间中再提取一次特征, 才能起到提高识别率的效果。复向量空间是定义了内积的复向量空间, 其内积和范数定义如下:
式中的H为共轭转置符号。
复特征融合:
在复空间中样本仍然用X表示, m0表示总体均值, mi 表示第i类训练样本的均值, 计算类间散度矩阵、类内散度矩阵和总体散度矩阵:
由定义可知, Sw, Sb, St均为Hermite矩阵, 且非负定。由于是第二次特征抽取, 所以一般Sw, St均为正定矩阵。用复主分量分析 (CPCA)
《4 FERET人脸库上的实验与分析》
4 FERET人脸库上的实验与分析
实验是在较大的FERET人脸库
将图像用邻域均值的方法进行压缩, 使其分别成为40×40及20×20的图像。这样对20×20的人脸图像进行识别就不是高维小样本问题, 本征值本征向量的计算不需要用奇异值分解定理。LDA的计算中所遇到的矩阵是400阶的, 不随样本数的增加而增加矩阵的阶数。这种降维的方法为处理几百上千人的大型的人脸识别提供了计算上的可能。许多实验表明, 将人脸图像降低到合适的分辨率后, 不但会提高运算速度, 也会取得较高的识别率。为了消除光照强弱对识别的影响, 对每幅降维后的图像作直方图均衡化处理。图2是压缩到40×40及20×20的分辨率, 并进行直方图均化前后的图像对比。可以看出降维后的图像用于分类仍然是合适的。直方图均化后的图像光照变化的影响明显减小。
《图2》

图2 40×40与20×20分辨率图像及进行直方图均衡化后的比较
Fig.2 The FERET images with resolution 40×40 and 20×20, and compared with its after histogram equalization
1至7之间的整数分别对应图像文件含有标识符ba, bd, be, bf, bg, bj, bk的样本。在实验中, 用随机程序产生1至7的排列, 前3个数字对应的3幅图像作为训练样本, 后4个数字对应测试样本。这样原始训练样本有200×3=600个, 测试样本的总数为200×4=800个。
人脸都是基本对称的, 每人只用3幅图像进行训练, 显得训练样本不足。特别是考虑到姿态的变化, 如果未包含某一方向的训练样本, 抽取出特征后进行特征比对匹配时会产生出许多错误的分类。例如, 只用向右旋转人脸图像训练, 而用向左旋转后的图像测试, 会增加出错的概率。通过增加镜像图像作为训练样本, 对提高有姿态变化的人脸识别效果显著。所以, 将每人的3个训练样本作镜像变换, 产生出3个镜像样本, 与原有的3个训练样本一起进行训练, 构成扩大的训练样本集。图像A的镜像=AM, M是一个与A的列数相同的方矩阵, 且反对角线上的元素为1其余元素都为零。这样共有1 200个训练样本。
首先用二维投影计算矩阵Gt, 取6个最佳投影轴, 提取120个特征, 作为第一组特征α1。利用α1直接进行识别分类的方法, 称其为2DPCAGt。用LDA也抽取120个特征, 作为第二组特征β。加权系数取θ=1.0, 组合为α1+iβ。在复向量空间中取28个主分量, 作10次实验, 结果见表1至表4中融合方法1。再用二维投影计算矩阵Gb, 取6个最佳投影轴, 提取120个特征, 作为第一组特征α2。利用α2直接进行识别的方法称为2DPCAGb。α2与β组合为α2+iβ, 在复向量空间中由类间散布矩阵作为产生矩阵抽取28个主分量, 作10次实验, 识别结果见表1至表4中融合方法2。实验中采用最近邻分类器。
Table 1 The recognition rates (%) at the FERET database under 20×20 resolution
《表1》
训练 样本 |
2DPCAGt | LDA | 融合 方法1 |
2DPCAGb | 融合 方法2 |
2, 7, 4 1, 2, 6 1, 2, 7 3, 4, 7 3, 6, 4 1, 3, 2 2, 7, 6 1, 3, 4 5, 1, 4 4, 5, 6 |
73.25 56.88 66.13 77.38 68.38 52.25 58.13 70.38 53.25 50.13 |
70.75 65.63 64.75 64.63 66.25 68.63 62.13 65.00 70.38 68.25 |
84.13 75.75 81.75 79.50 76.00 72.75 73.63 73.25 71.88 72.38 |
75.25 63.13 69.75 77.88 71.38 64.25 62.50 70.00 64.63 60.38 |
86.88 76.38 81.00 81.63 79.38 75.50 76.00 77.00 72.25 71.25 |
平均 |
62.62 | 66.64 | 76.10 | 67.92 | 77.73 |
复主分量分析取多少主分量d对识别率有一定影响, 但在一个相对大的区间内变化不大, 方差很小, 所以该方法具有很好的稳定性。对d取20至70之间, 用上面的10次抽取的样本进行了计算, 10次的平均识别率稳定在75.6%至77.8%之间。随机取3个训练样本的5次实验针对d取20至70之间的不同值, 其识别率曲线图见图3, 曲线基本平稳。
Table 2 The recognition rates (%) at the FERET database under 40×40 resolution
《表2》
训练 样本 |
2DPCAGt | EFM | 融合 方法1 |
2DPCAGb | 融合 方法2 |
2, 7, 4 1, 2, 6 1, 2, 7 3, 4, 7 3, 6, 4 1, 3, 2 2, 7, 6 1, 3, 4 5, 1, 4 4, 5, 6 |
73.50 58.13 69.25 77.25 68.75 55.00 59.63 71.50 57.25 53.00 |
62.88 58.75 54.38 61.63 62.13 67.75 53.13 63.25 70.38 65.13 |
88.00 77.88 80.75 85.13 80.50 79.00 79.00 78.25 74.63 73.63 |
78.38 64.88 70.88 81.63 74.13 66.00 63.63 72.88 66.75 62.50 |
88.00 76.13 81.38 84.75 80.63 78.75 76.88 78.00 73.00 72.88 |
平均 |
64.33 | 61.94 | 79.68 | 70.17 | 79.04 |
表3 80×80分辨率的FERET人脸库 (未进行光照标准化) 上的实验结果
Table 3 The recognition rates (%) at the FERET database under 80×80 resolution
《表3》
训练 样本 |
2DPCAGt | EFM | 融合 方法1 |
2DPCAGb | 融合 方法2 |
2, 7, 4 1, 2, 6 1, 2, 7 3, 4, 7 3, 6, 4 1, 3, 2 2, 7, 6 1, 3, 4 5, 1, 4 4, 5, 6 |
79.38 54.38 72.38 81.00 65.50 53.88 70.13 66.50 52.75 51.00 |
58.75 54.38 49.50 55.00 55.13 60.25 49.88 56.50 58.13 58.38 |
89.00 68.75 82.25 84.00 68.88 70.25 80.88 68.88 69.12 69.25 |
84.50 62.00 79.50 83.50 65.75 64.63 75.75 65.88 59.00 57.88 |
91.38 68.00 84.13 86.88 71.13 71.63 82.88 69.12 67.38 67.88 |
平均 |
64.69 | 55.59 | 75.13 | 69.84 | 76.04 |
图像分辨率为40×40或80×80时, 一维的类内散度矩阵是奇异的, 用LDA前要先用PCA降维。这是和表1中不同的地方。使用增强Fisher线性鉴别法
表4 40×40分辨率FERET人脸库上的10次实验的平均结果
Table 4 The ten times average recognition rates (%) at the FERET database under 40×40 resolution
《表4》
图像 分辨率 |
2DPCAGt | EFM | 融合 方法1 |
2DPCAGb | 融合 方法2 |
40×40 |
64.33 (65.49) |
61.94 (39.85) |
79.68 (67.49) |
70.17 (63.97) |
79.04 (66.09) |
注:括号中的数是不加入3个镜像样本的识别率, 括号外为加入镜像样本后的识别率。
《图3》
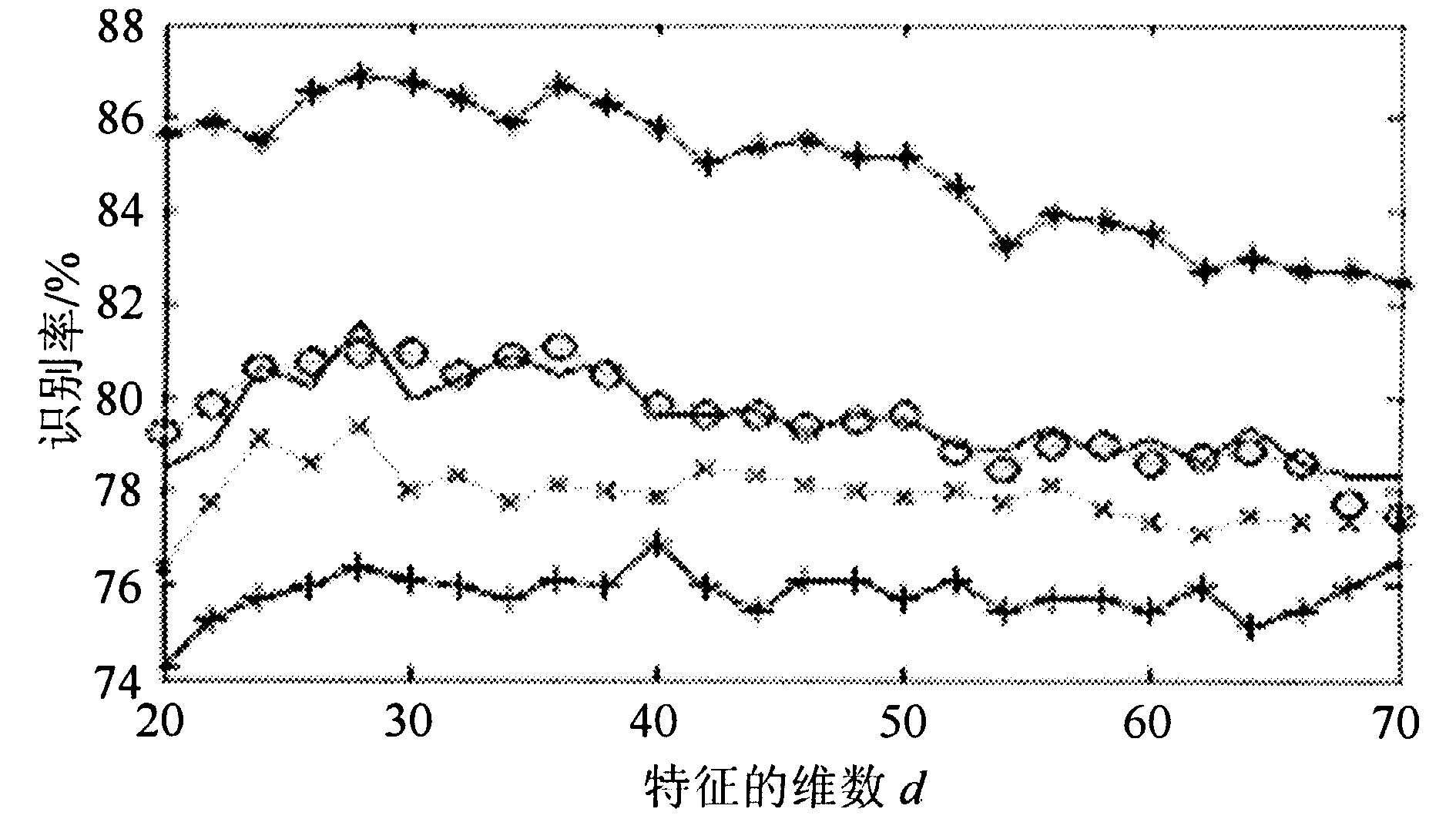
Fig.3 Five CPCA Recognition Rates curves with different feature numbers
从3个实验的数据对比可见, 二维算法就单个识别率而言取类间散度最大的2DPCAGb好于以总体散度最大的2DPCAGt, 但是融合后的效果都有很大提高, 且基本相当。这说明2DPCA与一维LDA的特征之间有互补性, 融合后都能提高识别率。三种不同分辨率的实验表明, 在40×40的分辨率下, 取得的识别率最高, 这说明合适的图像分辨率对识别率也有影响。
一个自然的想法是二维算法是否可用二维线性鉴别分析 (2DLDA) 与一维LDA进行融合。经过实验发现, 2DLDA在这个200人的人脸库上的识别率很低, 只有40%左右, 这说明2DLDA的识别性能不一定好于2DPCA。2DLDA与LDA融合后的识别率反而低于LDA本身的识别率。这说明LDA推广到2DLDA后, 随样本类别数的增多它的识别率下降的恨快, 它的鉴别能力和适用场合有待进一步研究。不加入镜像样本也进行了实验, 结果见表4, 括号中为不加入镜像样本的数据。EFM提高识别率22.09%, 两种融合方法分别提高12.19%和12.95%, 加入镜像样本是有效的。
《5 结论》
5 结论
提出一种将基于向量提取的特征与基于二维的图像投影提取的特征相融合的特征抽取方法, 一方面提高了识别性能, 另一方面减少了所需抽取的特征数量。在FERET人脸库上用3种不同的分辨率所做的实验, 验证了该方法的有效性。该方法虽然是在人脸库上进行, 但其应用不仅仅限于人脸识别, 对其他类似的图像分类也有实际的应用价值。所使用的对图像降维和加镜像样本的方法, 有助于提高其他人脸识别算法的识别率。此外, 所用的算法计算量小, 特别是2DPCA不随样本数的增加而增加计算量, 为实际中处理大样本集的人脸识别问题提供了参考。











 京公网安备 11010502051620号
京公网安备 11010502051620号




