


《1 引言》
1 引言
如何从现有的知识库中进一步的发现出更多的深层次的知识, 即KDK, 在国内外基本上无人涉足。从知识库中发现规则对于知识工程和机器学习都是一个重要的问题, 因为它的成功将直接作用于知识获取和大型知识库的构建, 并且发现规则对于发现大型和通常意义下的知识库可以产生怎样的机器学习程序是很有用的。
知识库中的知识发现 (KDK) 与数据库中的知识发现 (KDD) 有所不同, 主要表现在:a. 发现的基础不同, KDK针对的对象是知识库, 一个真实的知识库一般包含事实库和规则库, 它们的结构与数据库有着明显的区别;b. 采用的手段不同, 知识库中包含着显性的关系, 如何针对关系得出更高层次的知识, 将采用与数据挖掘完全不同的方法。
《2 关于KDK的描述》
2 关于KDK的描述
目前在国际和国内都没有明确提出过KDK这个概念, 更没有人对它进行详尽的定义。在这里, 将通过分析最终采用描述性的方法界定所研究的KDK的范围。
总括而论, 演绎逻辑系统 (包括经典的和非标准的) 已在计算机科学技术中占有重要的地位。机器学习、归纳学习与不确定性推理至今仍主要是以演绎逻辑系统作为工具。由于计算机本身是演绎化的产物, 而发现的核心是归纳, 因此, 唯一要做的是归纳的演绎化或演绎的归纳化。可以看出, 发现本身既离不开归纳也离不开演绎。
首先, KDK的目的是为了在真实的大型知识库中发现新的知识。这种发现过程借用KDD的语言来说是非平凡的。意即这种发现过程的核心将是归纳, 而演绎将作为辅助手段;该过程不同于传统的演绎, 它有可能是不保真的。
其次, KDK能够发现深层次的知识。具体而言就是在已有属性与关系的基础上进一步发现其上的关系, 从逻辑的角度上说就是发现谓词间的关系或函词间的关系。
第三, 由于知识本身所可能具有的一些属性, 如不确定性、非单调性、不完全性等, 就决定了KDK过程的进行也将是一个复杂的、多方法、多途径的过程。它与知识库的组织、用户对最终寻求的知识类型都紧密相关, 采用的推理手段可能涉及很多不同的逻辑领域。
最后, KDK发现的知识应该是新颖的、有效的、潜在有用的、用户可理解的, 这与KDD的要求相同。
从以上界定性的描述可以看出:KDK究其本质应是一种机器学习过程
笔者将以归纳逻辑的研究为基础, 探讨KDK结构模型的构建, 在其构建中, 逻辑的参与将主要作用在知识库的语义构造和归纳假设的证实过程。
《3 基于事实的KDK建模与挖掘算法》
3 基于事实的KDK建模与挖掘算法
《3.1基于属性的知识库建库》
3.1基于属性的知识库建库
在KDK系统中, 选用了基于属性的知识表示方法, 其最终形式为产生式规则, 这主要是基于以下几点考虑:
1) 下一步的工作中, 将把KDK的结果与数据库和KDD过程相连接, 这就要求必须为知识库和数据库的协调留下接口;而基于属性的建库方式使得知识库与数据库在结构上相似, 便于协调。
2) 基于属性的建库方式可以有效的借用数据库的现有功能, 便于存储大容量的知识, 解决目前知识库容量小的问题。
4) 产生式规则的知识表示方法具有模块化、清晰、便于理解等优点, 尤其重要的是它提供的是一种粗框架的表示, 可以在产生式内部结合基于属性的具体表示方法。
定义1 在相关于论域X的知识库中, 称 “一个属性词+一个属性程度词”这样形式表示的知识结点为知识素结点。
定义2 相应于论域X的知识结点, 是指如下形式的合式公式:
其中 ai为某一知识素结点, θi∈ J, i = 0, 1, …, m。这里J是由符号“∧”, “∨”, “not”, “ (” 和 “) ”等5个符号及其任意组合以及NOP (空) 而形成的集合;但θi在其中取值要使该公式有意义;只有θ0和θm可以取空。显然, 知识素结点是知识结点的一种特殊形式。
《3.2基于卡尔纳普归纳逻辑的KDK建模》
3.2基于卡尔纳普归纳逻辑的KDK建模
根据对概率的不同解释及其度量的不同处理, 现代归纳逻辑分为贝叶斯派和非贝叶斯派。在贝叶斯派中又可分为逻辑贝叶斯派和主观贝叶斯派。其中较有代表性的有凯恩斯的概率逻辑、卡尔纳普的归纳逻辑、柯恩的归纳支持逻辑、勃克斯的因果陈述句逻辑等。在我们的研究中, 选择了卡尔纳普归纳逻辑作为理论基础。该理论基础将主要作用于知识库的语义构造和KDK的假设评价中。
《3.2.1 知识库的语义构造》
3.2.1 知识库的语义构造
定义3 用以完全描述给定知识库的某给定个体域的一切可能状态的语句集称为一个状态描述。
定理1 知识库中的任一知识结点都能写成若干个状态描述的析取式。 (证明略)
《3.2.2 KDK的模型构建》
3.2.2 KDK的模型构建
定义4 m是关于某状态描述的正则测度函数, 当且仅当m满足以下条件:
1) 对于知识库中的每一个状态描述, m值为正实数;
2) 知识库中某给定个体域的所有状态描述的m值之和为1。
定理2 设m是知识库中某一状态描述的正则测度函数, 则每一个状态描述的m∈[0, 1]。 (证明略)
定义5 m是知识库中关于某状态描述的正则测度函数, 扩展m为知识库中关于知识结点的正则测度函数M:
1) 对于任何在知识库中不成立的知识结点j, M (j) = 0;
2) 对于任何在知识库中非不成立的知识结点j, M (j) = 知识结点中所有状态描述的m值之和。
定义6 若m是知识库中的关于知识结点的正则测度函数, c为知识库中知识结点的二元函数, 且c (h, e) =M (h, e) /M (e) , 则称c为知识库中的正则确证函数。
正则确证度表示了知识结点h和e共同成立的可能世界的个数与e成立的可能世界的个数的比值。它代表了知识结点间的逻辑关系, 根据卡尔纳普的逻辑体系, 尽管h和e本身是涉及到事实经验的, 但只要有了适当的确证度理论, 就可以抛弃事实根据, 只凭语义和语形分析得出确证度。
定义7 KDK过程模型为一个四元组 M = 〈W, R, m, c〉, 其中:
1) W为知识结点集, 可理解为可能世界集;
2) R⊆W×W, 可理解为认知通达关系;
3) M*为知识库中的正则测度函数, M*=Ms/Mt, Ms为特定知识结点状态描述的正则测度函数, Mt为全部知识结点状态描述的正则测度函数;
4) c为知识库中的正则确证函数。
说明:以上模型是针对KDK的归纳过程而建, KDK的目的是针对已知的两个知识结点, 通过知识库的归纳得出两个或更多知识结点之间的关系, 即上述模型中的R (认知通达关系) 。在这个模型中, 定义了知识库中的正则测度函数和知识库中的正则确证函数, 对关系R进行了量化的表示。据此量化值可知对于归纳结果的可信任程度。
《3.2.3 对于利用卡尔纳普归纳逻辑构建KDK结构模型的几点说明》
3.2.3 对于利用卡尔纳普归纳逻辑构建KDK结构模型的几点说明
卡尔纳普归纳逻辑
1) KDK系统的知识库采用了基于属性的知识表示方法, 而基于卡尔纳普的知识评价方法也是基于属性的。因此, 在形式上类似。
2) 现代逻辑界普遍认为卡尔纳普归纳逻辑因为暗示了归纳问题的一种先验主义的解决方式, 因此是一种证明的逻辑, 而不是一种发现的逻辑。在KDK过程中, 要借鉴卡尔纳普逻辑的主要原因是用于假设规则的评价, 因此是一种较适当的方法。
3) 卡尔纳普逻辑作为一种严密的数理逻辑有它的缺陷, 主要在于它在处理无限世界中的问题时, 它不能给出所有的状态描述。而应用于计算机实现时, 因为计算机处理的只能是有穷世界, 卡尔纳普的障碍不会影响KDK系统的实现。
4) 卡尔纳普在处理正则测度函数时使用了平权的方法, 这也是逻辑界争论的焦点, 因为他不能给与平权制一个合理的解释。在KDK实现时, 因为处理的是有穷世界, 可以给不同的状态描述以不同的权重。这个权重可以用主客观相结合的方法给定, 即首先由多专家参与共同给出加权均值, 再通过扫描数据库用统计方法计算出权重, 最后将两者结合。结合的方法可采用αA1+ (1-α) A2的公式, 此公式中A1表示主观性因子, A2表示客观性因子, α为主观性权值。这样就可以极大地减少个人的主观因素的影响。
《3.3利用KDK模型从事实库中发现规则》
3.3利用KDK模型从事实库中发现规则
图1给出了基于卡尔纳普归纳逻辑的KDK算法流程图。
《4 基于规则的KDK建模与挖掘算法》
4 基于规则的KDK建模与挖掘算法
《4.1归纳假设的产生》
4.1归纳假设的产生
《4.1.1 广义概念格的定义与基本性质》
4.1.1 广义概念格的定义与基本性质
定义8 若有形式背景K = (U, D, R, S) , 其中U是规则集合, D是规则特征属性的集合, R是U与D之间的一个二元关系, 即R⊆U×D, S是规则支持度、可信度、综合指标的集合。则在此形式背景下, 存在偏序集合与之相对应, 并且这个偏序集合产生唯一的格结构, 称为K一格结构。
这里, 规则集合U可仅以规则序列号的集合来表示。规则特征属性集合D就是知识素结点的集合。R是此规则所具有的特征属性, 或说是该规则的条件和决策属性的包含。
定义9 当且仅当三元组 (X, Y, S) 满足性质:
时, 称三元组 (X, Y, S) 关于R是完备的, 且有f (Φ) =D, g (Φ) =U。
定义10 由定义8和定义9所诱导的格L称为广义概念格。
定理3 所有广义概念格中的结点都是最大扩展序偶。 (证明略)
定理4 这种最大扩展是偏序集中的一种闭包。对于偏序集 (U, = ) 中的闭包, 有h:U→U, 性质如下:
1) ∀x ∀y (x = y ⇒ h (x) = h (y) ) ;
2) ∀x (h (x) = x) ;
3) ∀x (h (h (x) ) = h (x) ) ,
h (x) 称为x的h闭包。 若x = h (x) , 则称x是h近似。 (证明略)
定理5 设广义概念格节点C1 (X1, Y1, S1) 和C2 (X2, Y2, S2) , 若Y1≤Y2⇔X2⊆X1, 则有C1≤C2 ⇔X2⊆X1。 (证明略)
《4.1.2 产生式规则的数据库表示》
4.1.2 产生式规则的数据库表示
若有产生式规则知识 (包括领域知识或者KDD挖掘结果知识)
X1∧X2∧…∧Xn⇒Y1∧Y2∧…∧Ym (sup, conf) , 则可视为一个五元组 (序号, 条件, 结果, 支持度, 可信度) , 其中Xn, Ym为语言变量, 表示若有条件X1, X2, …, Xn发生, 则有决策属性Y1∧Y2∧…∧Ym 成立, 规则支持度为sup, 可信度为conf。其表表示形式如表1所示。
Table 1 Producing pattern rule knowledge
《表1》
ID | X1 | X2 | X3 | X4 | Y1 | … | sup | conf |
1 | 2 | 3 | 4 | 3 | 1 | … | 1 | 1 |
2 | 4 | 4 | 2 | 1 | 5 | … | 2 | 2 |
︙ | ︙ | ︙ | ︙ | ︙ | ︙ | ︙ | ︙ |
《4.1.3 产生式规则的广义概念格表示》
4.1.3 产生式规则的广义概念格表示
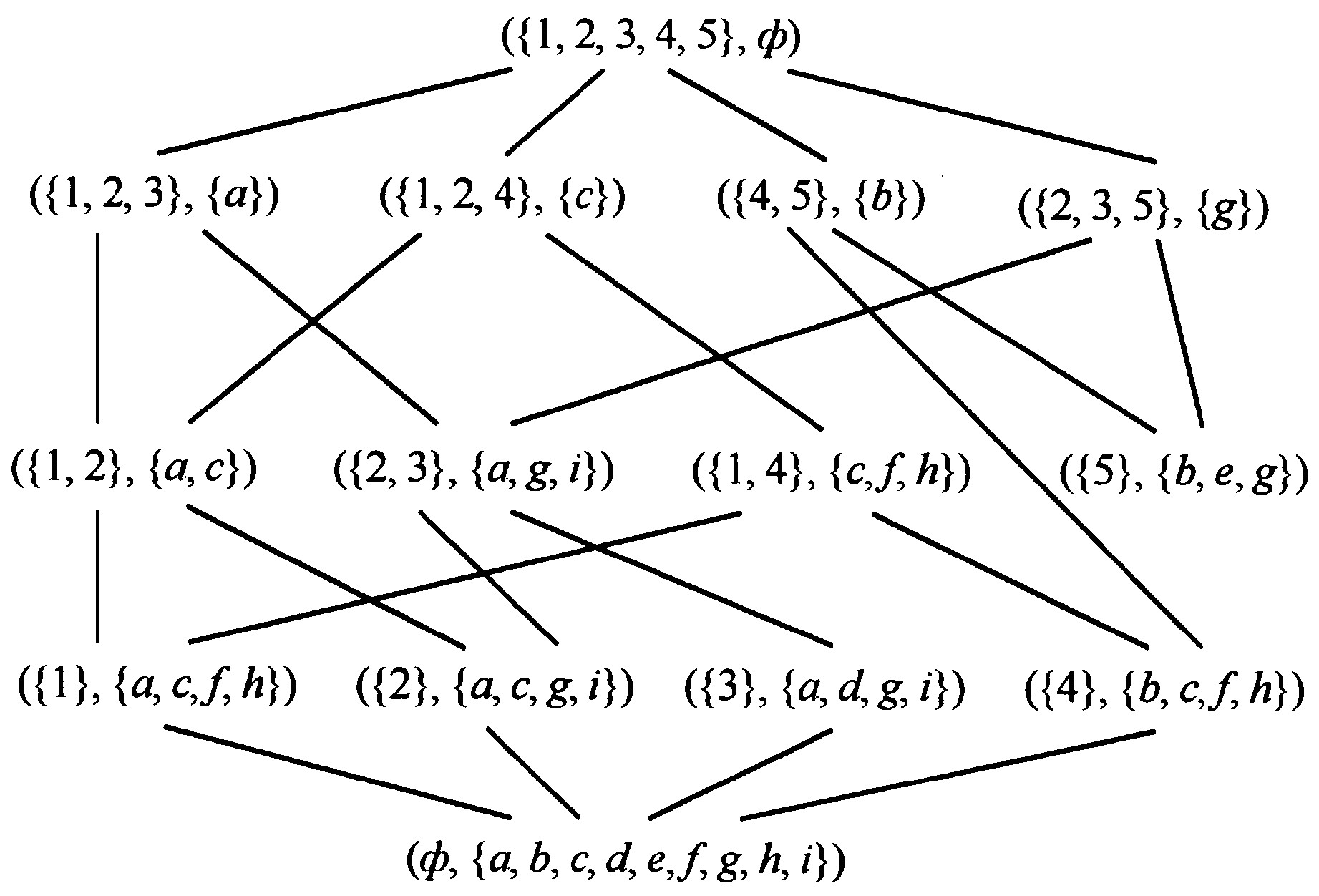
由广义概念格定义, 可构造匹配的形式背景 (U, D, R, S) , 如表2所示:U = {1, 2, …}为规则序号, D = {a1, a2, a3, a4, a5, b1, b2, …}为知识素结点的集合, R为每条规则的条件知识素结点和决策知识素节点, S为此条规则的支持度。可以此形式背景得到相应的广义概念格, 图2为其所对应的广义概念格的哈斯图。
Table 2 The pattern background of producing pattern rule
《表2》
R | a | b | c | d | e | … | sup |
1 | 2 | 3 | 4 | 3 | 1 | … | s1 |
2 | 4 | 4 | 2 | 1 | 5 | … | s2 |
3 | 1 | 0 | 0 | 1 | 0 | … | s3 |
4 | 0 | 1 | 1 | 0 | 0 | … | s4 |
5 | 0 | 1 | 0 | 0 | 1 | … | s5 |
︙ | ︙ | ︙ | ︙ | ︙ | ︙ | ︙ |
《4.1.4 广义概念格结构产生式规则的批量式生成》
4.1.4 广义概念格结构产生式规则的批量式生成
在基于广义概念格的生成算法中 (算法从略) , 建立边 (结点间联系) 过程和通常的算法区别不大, 但增加了支持度信息, 并实时得到可信度信息;只有满足规则支持度和可信度要求的结点才会被加入格中。为加快后续规则知识的发现过程, 增加队列First A, 记录知识素结点的首次出现。
此外, 还提出广义概念格的快速增量式更新算法 (算法从略) , 其思路是对索引树结点进行分类, 从而设计出一种基于树的快速增量式广义概念格 (产生式规则) 的生成算法。
《4.2基于科恩归纳逻辑的归纳假设评价体系》
4.2基于科恩归纳逻辑的归纳假设评价体系
由4.1节给出的方法和归纳学习的方法都可以得到归纳假设。而这两种规则的获取方法从本质上来说都是一种归纳, 而归纳是一个不保真的过程, 因此对此归纳假设的评价是一个非常必要和十分困难的任务
《4.2.1 归纳假设概率的确定》
4.2.1 归纳假设概率的确定
规则1 若假设与事实相符合, 则它是正确的。
规则2 若假设没有反例, 则它是正确的。
规则3 假设的正确性程度由其所有的相关变量的变化范围内无反例区域的大小决定。
下面直接确定归纳假设概率Pi值。
定义11 相关变量v是假设H的相关变量, 如果v的变化可能改变H的值。
定义12 一个相关变量是以某一属性 (有限个) 不同值为定义域的变量。这些值就称为它的变素。其中有且仅有一个是默认变素。
定义13 检验特征函数Vari (H (x) ) , 为标记归纳假设H (x) 经受检验状况的函数。
Vari (H (x) ) = 1表示H (x) 通过某一检验。Vari (H (x) ) = -1表示H (x) 未能通过某一检验。Vari (H (x) ) = 0表示不能判断H (x) 能否通过某一检验。
规则4 □H (x) ∧Vari
若H (x) 通过由增加一个相关变量构成的检验ti+1, 则它的PI值加1。 这条规则是确定PI的主要规则, 称为主规则, 其余规则称为从规则。
规则5 □H (x) ∧Vari
若H (x) 通过ti, 但无法判断它是否通过ti+1, 则有 □H (x) 。
规则6 □H (x) ∧Vari
若H (x) 通过ti, 但未能通过检验ti+1, 则有□iH (x) 。
H (x) 是否能经受住某一次的检验, 无法作出直接的回答, 此时系统将从已知条件和H (x) 出发, 进行演绎推理, 以确定Vari (H (x) ) 的值。
在归纳评价时, 按相关变量及其检验序列, 采用演绎和归纳交替的办法。首先给出归纳假设作为从目标, 从目标出发构造演绎的与/或树。若演绎成功, 则返回成功的可信度;若演绎不成功而又可选取主规则, 则开始进行归纳, 根据归纳结果返回相应的PI值, 并将此值赋给相应的与/或树。然后, 利用返回的PI值, 通过计算将结果返回给根目标, 从而得出目标成立的PI值。最后若无规则可用, 则采用直接提问的方式使评价进行下去。
定义14 相关域函项r是一个从假设集到相关变量的有穷序列集的映射。r[H]= (v1, v2, …, vn) 指已知H的全部相关变量为v1, v2, …, vn。
定义15 归纳度量函项m是一个从相关变量的有穷序列集到U{-1, 0, 1}n的映射。
若设归纳假设H有全称条件形式r[H] = (v1, v2, …, vn) , 并有domain (vi) = (v
《4.2.2 归纳假设的评价算法》
4.2.2 归纳假设的评价算法
1) 给出归纳假设H;
2) 确定可能证伪的所有可能的因子即相关变量, 记为相关变量集合V;
3) 确定相关域函项r;
4) 确定归纳度量函项m;
5) 检验控制所有N个变量, 使其所有可能的组合逐个出现;
6) 计算归纳概率PI。
将此算法应用于基于广义概念格所发现的假设归纳规则, 在给定最小归纳概率阈值后, 经验证得到的规则数目减少一半, 而正确率大大提高了。从而验证了基于规则的KDK模型构建与基于科恩归纳逻辑 (做了改进) 的归纳假设评价算法的有效性。
《5 结语》
5 结语
1) 在cyc数据库中对文献
为验证所提出的新的KDK算法的有效性, 同样选取了cyc知识库。从Person集合中, 同样得到了146个假设。经过正则确证度函数的评估后, 证实了137个假设, 正确率提高到93 %。
2) 对于基于规则的KDK算法 (包括归纳评价算法) , 也得到了类似的有效性的实验验证结论。
3) 对于基于模式KDK算法 (包括归纳评价算法) , 将做为下一阶段重点研究对象。在下一步的工作中, 还将考虑数据库及KDD参与KDK挖掘过程, 即探索知识发现系统内在机理中的第二个机制——双基融合机制。











 京公网安备 11010502051620号
京公网安备 11010502051620号




