

《1. 引言》
1. 引言
水土流失和突发洪水是印度北方邦南部地区面临的极端问题。由于土壤侵蚀,该流域的土壤不断退化,养分不断流失,进而限制了该地区的农业发展。在干旱和半干旱地区,短历时的强降雨和不可持续的土地利用方式加剧了侵蚀带来的土壤流失、土壤退化和养分减少问题。掌握土壤侵蚀和地表水排放的详细信息有利于流域管理人员更好地管理、保护土壤和水等自然资源,促进可持续发展。目前,利用降水、土地和土壤特征信息进行水文模拟的方法多种多样,其中包括水资源评估与规划(WEAP)模型、农业非点源污染(AGNPS)模型、区域非点源流域环境响应模拟(ANSWERS)模型、水土评价工具(SWAT)和水蚀预报模型(WEPP)。在这些方法中,SWAT是由美国农业部(USDA)农业研究局(ARS)开发的基于过程的水文模型[1]。此外研究者还开发了一些用于估计水文模拟参数的算法。
在众多水文模型中,SWAT模型被广泛用于径流和产沙模拟。该模型是一个具有空间基础的模型,可以进行连续时间序列的模拟,旨在帮助流域管理者预测土地利用管理活动对径流/土壤侵蚀和农业化学品流失的影响[2]。许多研究者将SWAT模型用于径流评估研究[3,4]、水质模拟[5,6]、流域和水文模拟[7–9]、产沙量模拟[10–13]以及易发生土壤侵蚀区域管理[1,14]。Psomas等[15]利用SWAT和WEAP模型制定了希腊的节水措施。
应用SWAT模型之前,需要利用径流、蒸散等变量的实测值和模拟值对影响SWAT模型结果的参数进行校准,以期实现合理的水文模拟。本模型中有26个径流参数、30多个土壤参数和41个水质参数,这些参数都可以被用于校准。研究者在对含参数的流域模型进行校准时需要特别考虑关于不确定性的问题[9]。Qiu和Wang[5]分别对1997—2002年和2003—2008年的新泽西州中部水文和水质评价进行了验证和校准。Vigiak等[16]对多瑙河流域的坡面侵蚀模型进行了校准和验证。
早期研究者应用确定性方法,如用试差法来进行校准、验证和不确定性分析。应用这类方法时,研究者必须不断调整参数,直到模拟值和实测值的偏差在可接受的范围之内。为提高校准效率及校准质量,研究者开发了许多用于校准、验证和不确定性分析的随机方法,包括序贯不确定性分析(SUFI-2)、并行求解(ParaSol)、粒子群优化算法(PSO)、普适似然不确定性估计(GLUE)、人工神经网络(ANN)和马尔可夫链蒙特卡罗模拟(MCMC)。
在应用随机方法对模型进行校准方面,Vilaysane等[17]使用SUFI-2算法来校准西得纳河流域的径流模拟值。Yesuf等[12]利用SUFI-2和SWAT-CUP算法对埃塞俄比亚的产沙量进行模拟研究,研究认为SUFI-2算法在优化模型运行时间的基础上执行了可操控性、一致性、认可度和脆弱性检查。Ercan等[18]使用云技术对SWAT模型进行校准。Talebizadeh等[19]使用ANN和SWAT模型进行泥沙负荷模拟和不确定性分析。Zhang等[20]使用遗传算法和贝叶斯模型平均法完成了模型的校准和验证。Tuo等[21]采用SUFI-2算法进行不确定性分析,评价了SWAT模型中的降水输入情况。Noori和Kalin[4]将ANN与SWAT和SWAT-CUP算法结合起来进行逐日径流预测。Salimi等[3]使用SUFI-2算法完成了径流模拟。Vigiak等[13]使用SUFI-2算法模拟了泥沙通量。Zhang[22]使用ANN和支持向量机(SVM)构建了类似SWAT的模型。由于很难确定出用于校准SWAT模型的最佳算法,因此我们在本研究中使用了GLUE、SUFI-2和ParaSol这3种算法用于校准-不确定性分析。
本研究利用SWAT2012模型进行水文模拟。校准时使用GLUE、SUFI-2和ParaSol这3种算法并对其进行比较,从而确定出最佳算法。将ArcSWAT界面与恒河流域进行关联,绘制和组织子流域以对径流、产沙量和蒸散量进行监测和模拟。该模型使用数字高程模型(DEM)、土地利用/土地覆被(LULC)图和土壤图作为流域划分及水文响应单元(HRU)分析的输入,使用了巴利亚、瓦拉纳西、巴特普尔和加齐普尔这4个气象站的1996—2015年的逐日气象数据。首先,本研究对流域进行划定,并将研究流域划分为子流域,确定河流数量并估计它们的流向;其次,建立流域中可用的出口点和水库信息,以准确地将流域划分为具有不同土地类型、土壤类型和海拔属性的HRU;然后,输入气象数据,运行SWAT模型以模拟每个HRU和子流域的径流、产沙量和蒸散量;接着,在获得2004—2009年间流域和子流域尺度的监测数据基础上,利用SUFI-2、GLUE和ParaSol算法对模型进行了校准,通过分析这些校准算法的结果、假设和局限性,基于5.2节所述的5类标准确定出最佳算法;最后,利用2009—2015年间的数据对校准后的模型进行了验证,获取了各水文参数的估计结果和校准结果,完成建模。
《2. 研究区》
2. 研究区
研究区是恒河流域的一部分,包括了印度北方邦的南部和东部地区。该流域的河流长度约为50km2,流域总面积为15621.612 km2。该地区位于东经82°1′52.439′′至83°55′10.63′′和北纬26°2′7.842′′至24°22′53.034′′之间。研究区覆盖的主要站点是瓦拉纳西、巴利亚、巴特普尔、加齐普尔、米尔扎普尔和查达里,研究区的干流位于瓦拉纳西区,该地区平均降雨量为941.2mm,最大降雨发生在7~9月,最小降雨发生在6月或10月,11月至次年5月的降雨可以忽略不计。该流域的主要土地利用是荒地和城镇用地,两种类型用地覆盖率超过50%。
《3. 数据》
3. 数据
高程数据、LULC数据、土壤数据和逐日气象数据是本模型建立的前提条件,高程数据采用航天飞机雷达测绘任务(SRTM)获取的分辨率为 90m×90m 的DEM,对LULC图采用Landsat-8卫星图像进行图像分类,输入的气象数据为1996—2015年间的日降雨量、温度、太阳辐射和气压等数据。表1给出了相关数据及其位置、时间和获取机构的详细信息。
《表1》
表1 建模原始数据

《4. 方法》
4. 方法
《4.1.水土评价工具(SWAT)》
4.1.水土评价工具(SWAT)
本研究利用SWAT2012进行水文模拟,同时使用ArcGIS10软件及其扩展ArcSWAT,流域被分成多个子流域,然后又进一步被划分为不同的HRU。每个HRU包含了不同的土壤特征、海拔和LULC信息。水收支平衡是HRU划分的主要动力,HRU是水文参数估计的最小单元。水文模拟过程被分为两个阶段:①在陆地阶段,SWAT模拟河流的集水区负荷、残留和来自每个HRU的补充,然后将它们分配到各个子流域;②在河道演算阶段,对每个子流域的负荷进行演算、分配,以获得流域河网的整体负荷。
作为SWAT的一部分,单独的植物改良模型被用于获得特别的土地覆盖类型。这个改良模型被用于评价根系区水和营养物的移动、蒸腾和生物量的产量。每次模拟都可以重新进行植物的种植、收获、培养、补充和农药使用[23]。一旦每个子流域水平下的HRU数据被确定,径流、泥沙、营养物质和杀虫剂就会通过河道、池塘、水库和湿地流向流域出口。
Neitsch等[24]编制了2009年版本的SWAT理论手册用于参考,方便读者了解更多有关SWAT建模的知识。
《4.2.序贯不确定性分析(SUFI-2)》
4.2.序贯不确定性分析(SUFI-2)
SUFI-2是评价不确定性最常用的随机算法。在这个算法中,参数不确定性对所有不确定性因素的解释度由P因子来评价。该参数表示95%预测不确定性(也称为95PPU)包含观测数据的百分比。评价校准质量的另一个参数是R因子,它是95PPU的平均厚度除以观测值的标准偏差。理想情况下,P因子取值介于0~100%,R因子介于0~∞。理论上P因子为1且R因子为0代表实测值和模拟值完全吻合。在这项研究中,使用SWAT-CUP软件对SWAT2012模拟值进行自动校准。利用SUFI-2算法,结合模拟值和实测值,可以实现不确定性分析和校准。
SUFI-2算法描述如下:
步骤1:定义目标函数(gi)。其次确定被优化的关键物理参数的取值范围(θj)。
步骤2:对参数进行敏感性分析。然后,进行第一轮拉丁超立方抽样,抽样过程考虑参数的初始不确定性范围。
步骤3:进行下一轮拉丁超立方抽样,计算对应目标函数值。敏感性矩阵Jij和参数方差C由下式计算:
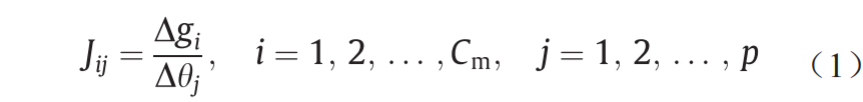
式中,Cm是灵敏性矩阵中的行数;p是估计的参数个数。

式中,Sg2为模型运行得到的目标函数值的方差。
步骤4:计算P因子和R因子后,计算95PPU值。
《4.3.普适似然不确定性分析(GLUE)》
4.3.普适似然不确定性分析(GLUE)
GLUE算法被应用于参数模型的校准,在参数估计时考虑了参数集的非唯一性。GLUE算法简单易行,该算法假定:在大量参数构成的模型中,可以优化的参数集往往不唯一。在GLUE算法中,参数的所有不确定性来源都被考虑进参数不确定性中。与参数集有关的概率估计反映了所有的误差来源以及参数估计的共同影响对模型效果的影响。GLUE分析包括以下3个阶段。
(1)对“广义似然测量”L(ϕ)进行定义,进而在众多参数集中进行随机抽样;通过将计算的似然值和定义的似然阈值进行对比,把每一个参数集划分为“行为集”或“非行为集”。
(2)通过下式获取每个行为集参数“似然权重”Wi:
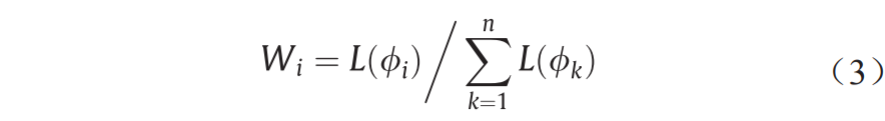
式中,n表示行为集参数的个数。
(3)将精度不确定性描述为参数加权累计分布的预测分位数。GLUE算法最常用的似然度量标准为纳什效率系数(NSE)。
《4.4.并行求解(ParaSol)》
4.4.并行求解(ParaSol)
ParaSol是对全局优化算法SCE-UA的改进。其目标是利用优化期间执行的模拟来推导预测不确定性。由于SCE-UA进行的累积模拟非常重要,因此计算在整个参数空间上进行,重点放在参数的理想/最优布局上。
ParaSol算法求解步骤如下:
(1)优化SCE-UA应用(将SCE-UA计算的任意性扩大到整个参数空间范围)之后,通过类似于GLUE算法设定阈值的方式,划分“优”和“劣”参数集。
(2)对每个“优”参数集赋予相似的权重以体现精度不确定性,目标函数为残差平方和(SSQ)最小:

式中,n是测量变量yi,M(ϕ)的个数;yi,S是模拟变量。
在Abastpour[25]编写的SWAT-CUP用户手册中可以找到对SWAT-CUP、SUFI-2、GLUE和ParaSol算法的简要描述,Arnold等[26]给出了SWAT模型的使用、校准和验证方法。
《4.5.数据预处理》
4.5.数据预处理
SWAT建模所需的输入数据是DEM、LULC图、土壤图和气象数据。首先,对表1中从不同机构获取的原始数据进行预处理。利用ArcGIS10的镶嵌工具对从美国地质调查局(USGS)下载的不同DEM进行镶嵌。在镶嵌工具中,将多个图像合并为一个单元。为获取LULC图,对卫星图像进行处理。本研究使用ERDAS工具进行图像分类。所有的卫星图像都包含电磁波谱中的多个波段,所有的波段合在一起形成一个图像,但是这样只提供了光谱信息。将光谱信息转换成LULC图或任何其他特定的信息都需要进行图像分类。基于光谱曲线或像元光谱,可以实现图像的分类。根据信息分类,像素可以表示水域、林地或城镇用地。基于光谱曲线或像素的光谱,分类是可行的。目前有两种自动图像分类技术:监督分类和非监督分类。在监督分类中,研究人员或专业图像解译人员操作软件,将感兴趣的土地覆盖类别进行定义,然后该软件将自动使用该数据集来创建光谱类别;在非监督分类中,操作人员只确定分类图像所需的类别数量,在没有专业知识的情况下用该方法对图像进行分类。本研究通过对光学卫星图像进行监督分类,提取了该区域的LULC图(图1)。使用目视判读将土地利用分为6类:水域(WATR)、林地(FRSD)、城镇用地(URBN)、山地(RNGE)、农耕地(AGRL)和荒地(BARR);每种分类使用约150个训练数据集。监督分类采用最大似然法。流域的大部分土地利用类型为城镇用地或荒地。
《图1》
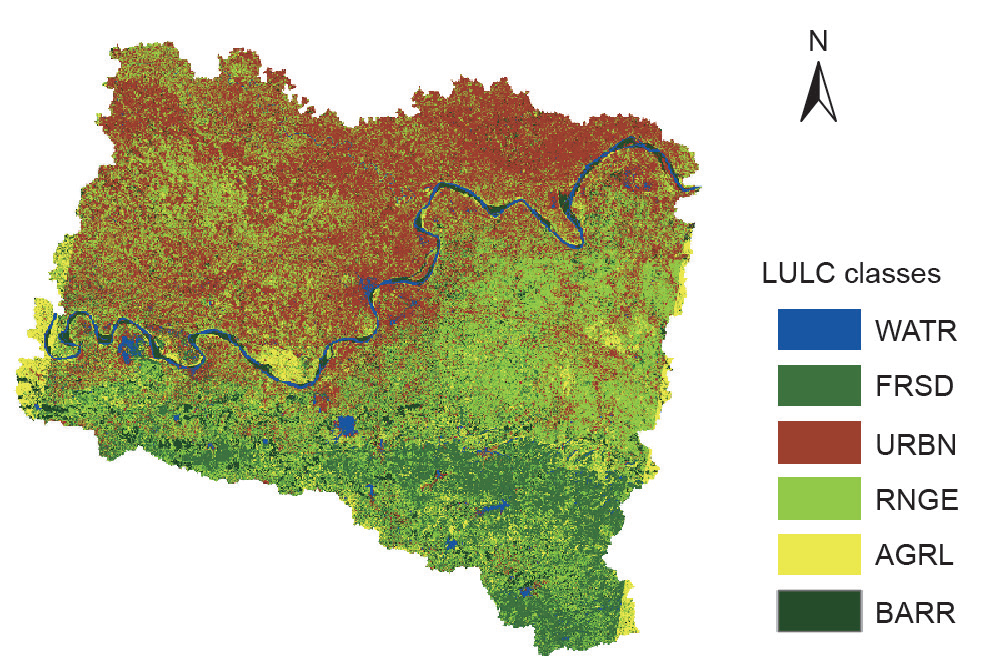
图1. 研究区域的LULC图。
为构建如图2所示的土壤分类图,使用国家土壤测量局提供的数据和土地利用规划局(NBSS & LUP)的数据,及实验室测试数据对土壤数据进行收集。土壤被分成5层。构建描述每个土壤分类的用户土壤数据库以便用于HRU分析(表2)。使用印度气象部(IMD)的数据创建气象数据库,经度、纬度、降雨量、温度和太阳辐射数据在单独的文本文件中给出。
《图2》
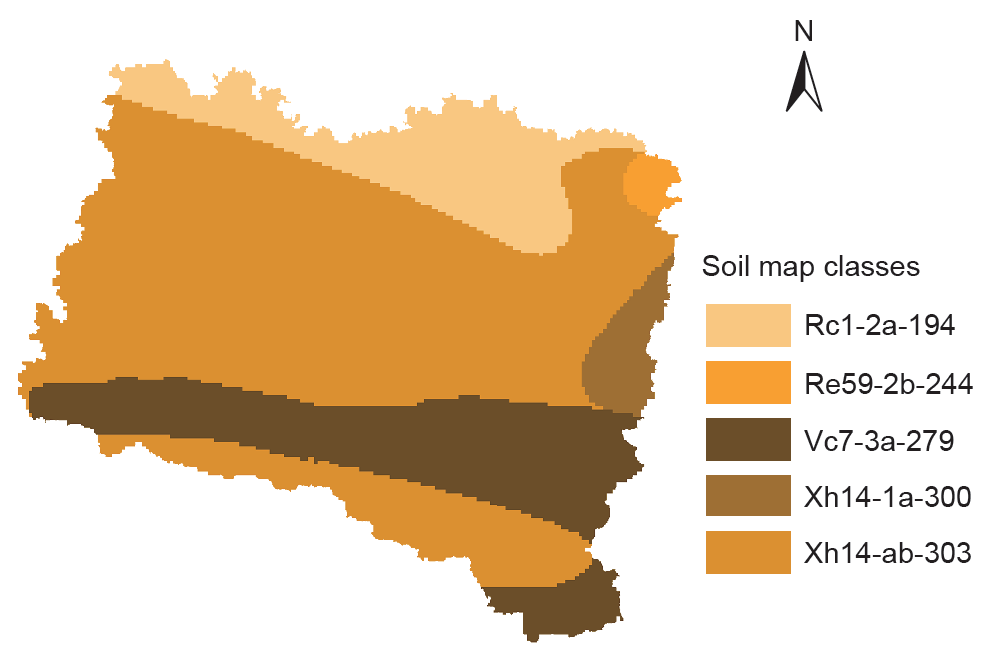
图2. 土壤分类图。
《表2》
表2 土壤类型表

《4.6.SWAT建模》
4.6.SWAT建模
流域指在单一形态分界线内的集水区和排水渠,它是一个天然的水文单元,被自然边界覆盖,其特征是具有相似的物理特征、地表拓扑结构和气候条件。流域划定意味着在地图上绘制线条来表示流域的限制。通常利用来自DEM或等值线图的数据来对流域进行划定。
流域划分是SWAT建模的第一步。在这一步中使用DEM作为输入,依据流域的坡度生成河流和出口点。依据研究人员选择的出口点对流域进行划分。用户还可以提供与水库、定义的河流相关的数据作为输入。本研究将流域划分为46个子流域。图3显示了划定的流域、河流和研究区的监测点。建模的第二步是HRU分析。在HRU分析中,流域分为具有不同土地类型、土壤类型和海拔属性的单元。在这一步中,利用研究区的土壤图、用户土壤表、LULC图和坡度图(图4),将所有子流域共划分为760个HRU。在第三步中,气象数据被输入模型。最后,运行SWAT模型以产生1996—2015年间每个子流域和HRU的径流、蒸散量和产沙量。
《图3》

图3. 研究区域的流域划分图。
《图4》

图4. 研究区域坡度图。
《4.7.校准和验证》
4.7.校准和验证
如前所述,校准是利用径流量、蒸散量等输出变量实测值和模拟值的偏差对影响SWAT模型结果的参数进行修正。验证是将SWAT输出的模拟值与实测值进行比较,而不修改参数的值。实现合理的水文模拟需要进行校准。有34个径流和土壤侵蚀参数可用于校准。表3描述了本研究中用于校准的参数及其取值范围。在这一步中,SWAT-CUP作为SWAT和校准算法之间的接口,来执行水文模拟输出的不确定性分析、校准和验证。SWAT模型的TxtInOut文件夹被导入SWAT-CUP软件中进行输入。1996—2015年间瓦拉纳西小流域地表水排放的实测值使用声学多普勒流量剖面仪(ACDP)进行测定。这些数据用于对比校准。SWAT-CUP模型的输入文件根据需要进行了更新。图5以流程图的形式显示了详细的校准过程。
《表3》
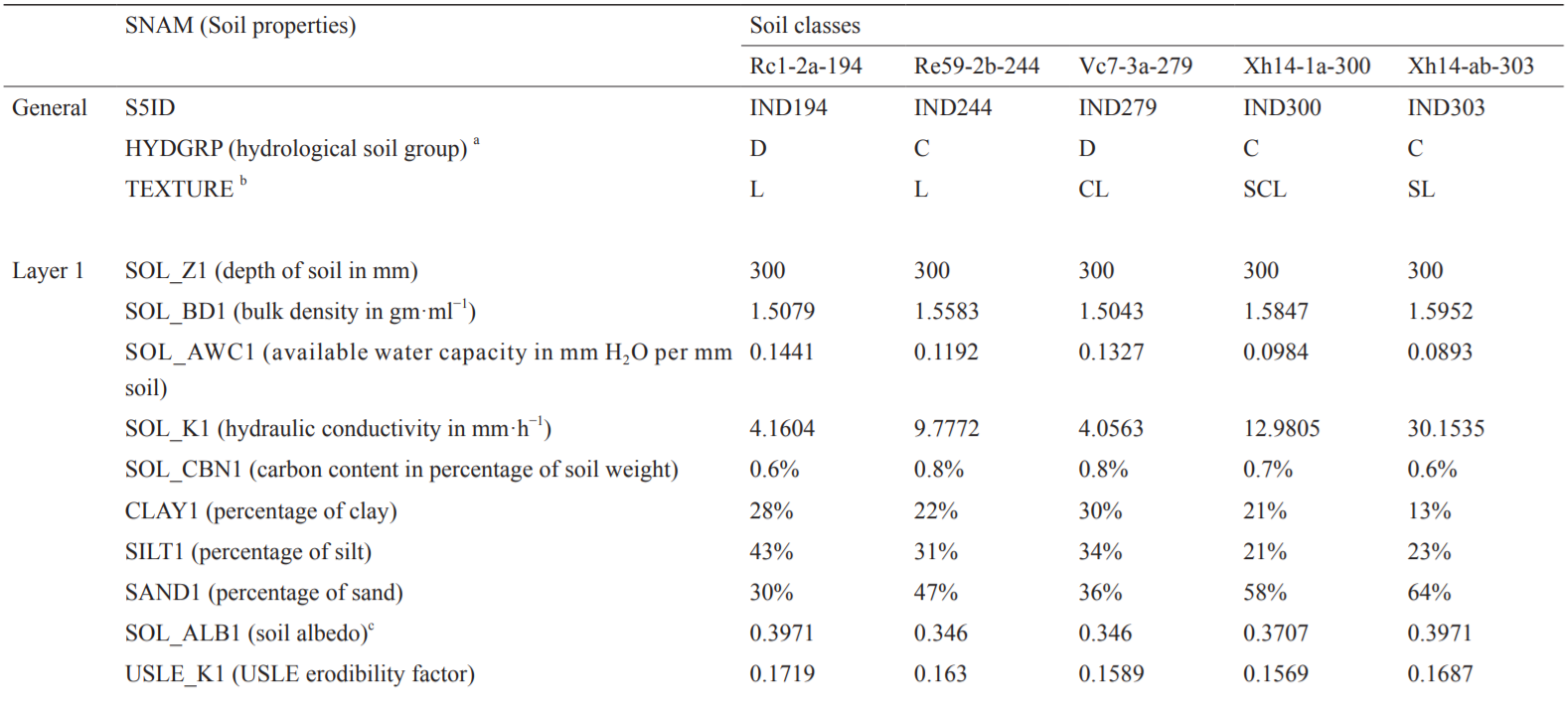
表3 用于校准的参数和参数取值范围
《图5》

图 5. 校准流程图。
《4.8.校准算法对比标准》
4.8.校准算法对比标准
在对校准方法进行对比时,存在以下问题:
(1)大多数算法在理论上各有不同,研究者必须主观确定考虑先验参数分布函数及目标函数。考虑到模型的水文应用,在本研究中我们对每种算法的目标函数进行了确定,这导致了各种算法的目标函数有所不同。在结果讨论时,我们指出了校准差异是由特定算法的理论定义/目标函数的选择所引起。
(2)每一种算法都有各自的基本概念和目标函数,这影响了算法之间的比较。为解决这个问题,我们计算了每种算法包含的函数值以便合理比较。同样,我们对计算性能进行了度量,对概念标准进行了评估,以便更好地对不同算法进行比较。
(3)每种算法都会产生不同的结果。为解决这个问题,我们考虑了所有可能标准下的算法结果,然后对结果进行总结归纳,以便读者得出自己的结论。
(4)比较的结果取决于应用。为解决这个问题,我们将每种应用情景下的结果与整体结果做了区分。
以下是用于比较3种(SUFI-2、GLUE和ParaSol)校准算法的5个标准:校准过程中各种校准算法都包含多个参数。对于每种算法,这些参数的最佳估计和不确定性范围不同,所以第一次比较基于参数最佳估计和每种算法的参数最小、最大不确定性范围以及参数相关性;不同校准算法的目标函数有所不同,因此第二次比较是基于NSE、R2和其他目标函数值;第三次比较基于R因子值(带宽的平均宽度除以相应测量变量的标准偏差)以及P因子(95PPU包含观测数据的百分比);第四次比较是基于使用概念、可测试性和统计假设的满足程度;最后的比较是基于实现的难度。
《5. 结果》
5. 结果
《5.1.SWAT输出》
5.1.SWAT输出
SWAT将流域划分为46个子流域和760个HRU,以实现简单而准确的模拟。结果显示,该流域年平均降水量估计值为941.24mm,降雪量为0mm,融雪量为0m,地表径流量(SURQ)为358.56mm,侧向流量为1.39mm,浅层地下水流量、深层地下水流量分别为138.69mm和8.53mm。总含水层补给量平均值为180.65mm,流域总水量为507.17mm,蒸散量为411.7mm。SWAT输出的径流和蒸散量的图形表示如图6所示。从结果中可以看出,有平均超过45%的降水在径流和蒸散中丧失。表4给出了流域所有变量的月平均值,包括降雨量、降雪量、地表径流量、径流量、产水量和蒸散量。估计平均每年有52.11d的用水压力和10.54d的温度压力。
《表4》
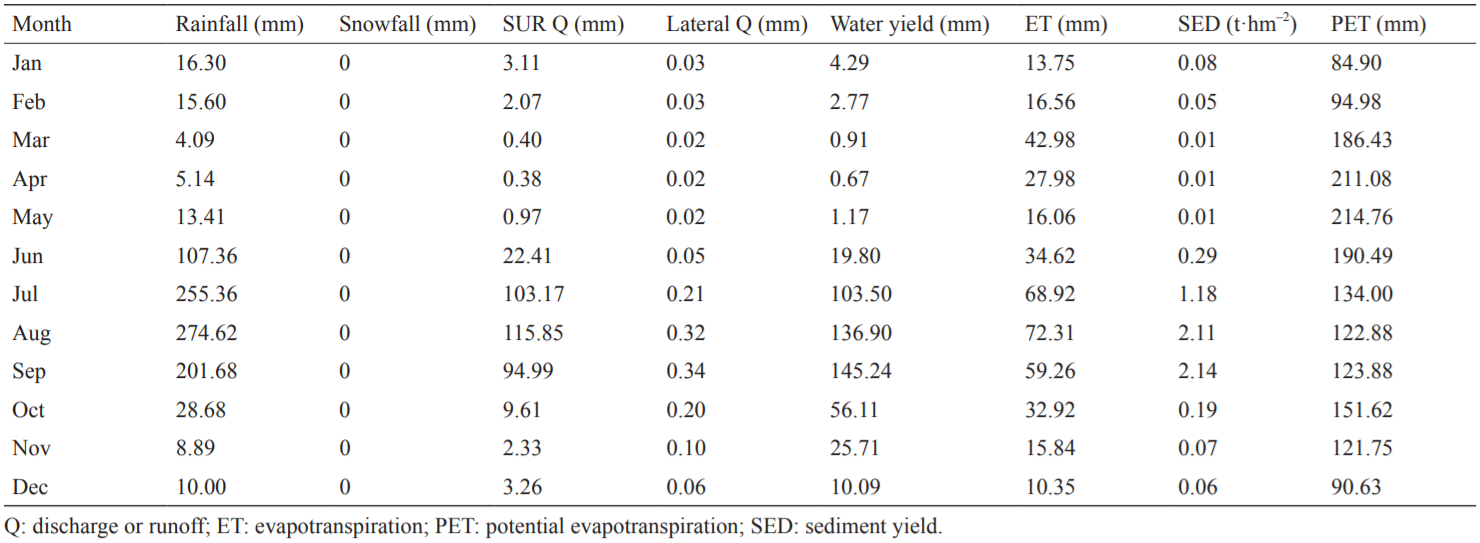
表4 流域参数的月平均值
《图6》
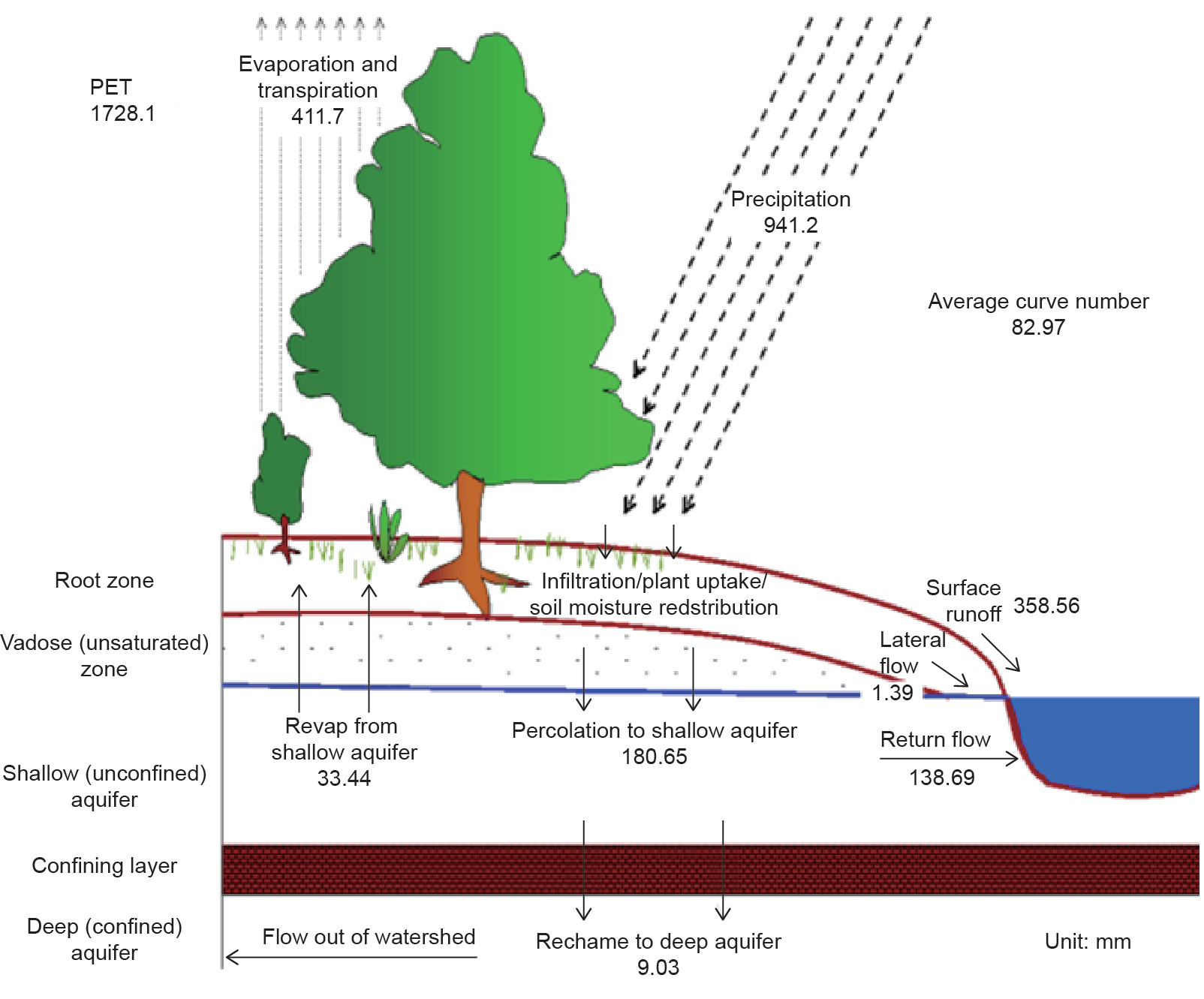
图6. SWAT输出结果图示。
在流域影像分类过程中,根据土地利用情况将流域划分为6类,流域大部分用地为城镇用地或荒地。表5给出了各种土地利用类型下参数的年平均值。结果表明:城镇用地的地表径流量可能过大,小于22%的水量是基流量;农耕地的地表径流可能过多;荒地的产沙量过高;超过一半的降雨流失,地表径流量最高,低于22%的水流是基流。
《表5》
表5 各种土地类型参数的年平均值

该区域的泥沙损失取决于许多因素。SWAT模型中对泥沙量的高估主要是由生物量生产不足造成的,这通常发生在特定的土地利用类型中。SWAT模型也会调整泥沙以考虑河内泥沙、河岸与河道的侵蚀。通常,很少有实测数据来区分旱地泥沙和河流泥沙交换。河流可能是泥沙的源或汇。河道底泥改性受物理河道特征(坡度、宽度、深度、渠道覆盖和底质特征)以及泥沙含量、来自上游的流量影响。因此,预计至少有一个HRU的最大产沙量高于50t·hm–2。最大产沙量来自于HRU#473,子流域#36,该单元土地利用类型为荒地,土壤类型为Vc7-3a-2型。估计该流域的总泥沙负荷为6.198t·hm–2。
图7显示了SWAT模型输出的产沙量。可以看出,平均陆地产沙量为6.2Mg·hm–2,最高陆地产沙量为827.43Mg·hm–2。
《图7》

图7. SWAT 模型输出的产沙量。
《5.2.输出对比》
5.2.输出对比
表6显示了校准算法的对比结果。根据如下5个类别标准进行了对比分析。
《表6》
表6 基于4.8节的标准对校准算法进行对比


第一类:根据第一类标准对算法进行对比分析发现,GLUE算法优于SUFI-2和ParaSol算法,因为GLUE算法的不确定性最广泛。因此,SUFI-2和ParaSol算法考虑的大部分不确定性都在GLUE中有所考虑。在这个类别中,SUFI-2算法是第二优算法。
第二类:根据第二类标准对算法进行对比分析发现,ParaSol是基于全局优化算法,因此该算法获得了最高的目标函数值,即模型效率系数NSE值最高。结果如表6数值所示,从表6可知:SUFI-2和GLUE算法具有相似的结果值,因此这两种算法排名相同。
第三类:根据第三类标准对算法进行对比分析发现,SUFI-2比GLUE算法得出的结果更好;而ParaSol算法的预测不确定性带窄,因此得出的结果比其他两种算法差。
第四类:根据第四类标准对算法进行对比分析发现,SUFI-2和GLUE算法考虑了不确定性的所有来源,而ParaSol算法仅考虑参数的不确定性而忽略了其他的不确定性来源。在概念上,SUFI-2比GLUE、ParaSol算法更好,因为它提供了最好的校准结果。
第五类:根据第五类标准对算法进行对比分析发现,GLUE算法最容易实现,因此最优。
通过本节的比较和描述,我们得知SUFI-2和GLUE算法的性能非常相似。然而,通过观察95PPU图(图8和图9),我们认为SUFI-2比GLUE算法更好,因为前者结果更好并且该算法更好地考虑了不确定性。SUFI-2算法可以使用最少的参数运行,而GLUE算法需要大量的模拟计算且不能提供比SUFI-2更好的结果;由于GLUE算法需要进行随机抽样,因此需要更长的计算时长。因此,SUFI-2被认为是本研究的最佳校准算法,并且在接下来的研究中我们使用SUFI-2算法对模型的产沙量进行校准、验证,基于此对模型进行进一步分析。
《图8》

图8. 使用GLUE算法进行校准后的模拟值和实测值的对比图。
《图9》

图9. 使用SUFI-2算法进行校准后的模拟值和实测值的对比图。
《5.3.SUFI-2输出》
5.3.SUFI-2输出
本研究使用表3中给出的敏感参数对模型进行校准。以月为模拟步长,确定出5个参数作为本流域模型中的最敏感参数。这些参数分别是主河道水力传导率(CH_K2)、通过水土流失方程(USLE)、USLE方程水土保持因子(USLE_P)、主河道的曼宁系数值(CH_N2)、地表径流滞后时间(SURLAG)以及土壤有效含水量(SOL_AWC)。校准过程中阈值设置为0.500000。2000—2004年作为预热期,2004—2009年作为校准期,2009—2015年作为验证期。由SUFI-2方法完成的校准和验证结果如图9和图10所示。其中,图9显示了流量模拟值和实测值的对比,图10显示了校准后产沙模拟值和实测值的对比。在#27的同一出口点对模拟结果进行了对比。
《图10》
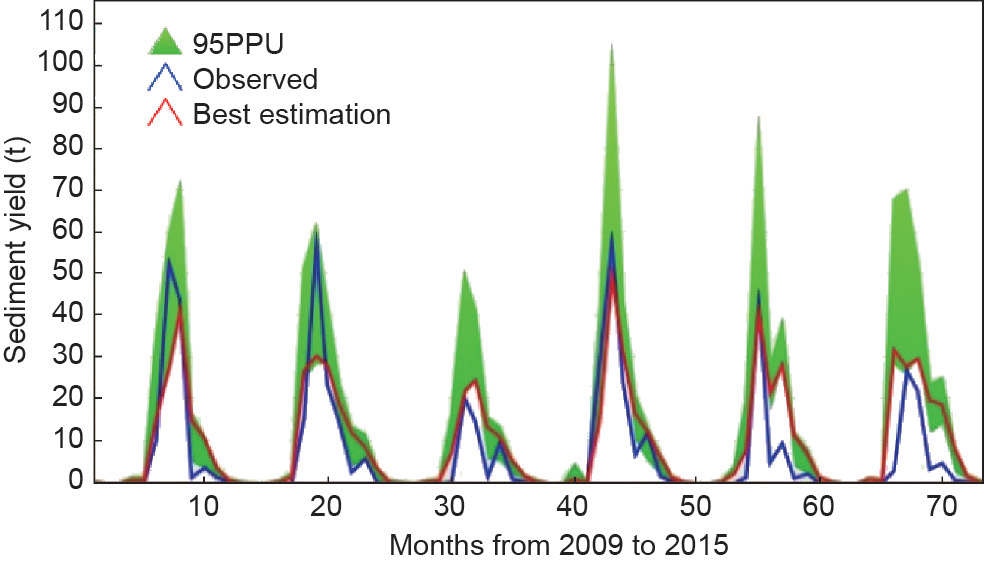
图10. 产沙量模拟值与实测值对比(mm)。
表7列出了研究流域不同目标函数下的模拟月产沙量的得分系数。表6中记录了研究区不同目标函数下模拟的逐月产沙量的评估系数。P因子值或95PPU包含观测数据的百分比为0.69。R因子值为0.763。结果表明,SUFI-2观测到的产沙量所占比例较低。相应地,R2=0.78,NSE=0.76,百分比偏差(PBIAS)=2.4×102,观测标准偏差比(RSR)=0.49,表明拟合优度不强,但在合理的变化范围内。结果表明SWAT模型可以很好地模拟该流域的水文特征。因此,该模型可进一步被用于流域内的水文研究。同样,SWAT模型可以用于前期流域水文分析。
《表7》
表7 目标函数值

《6. 结论》
6. 结论
本研究应用SWAT模型对恒河流域进行了水文模拟。利用1996—2015年间的逐日气象资料,取得了较显著的成果。将2000—2004年作为模型预热期,将2004—2009年为模型校准期,将2009—2015年作为模型验证期。使用GLUE、SUFI-2和ParaSol3种算法进行模型校准,根据校准结果对这3种算法进行比较。结果表明,在3种校准算法中,由于SUFI-2算法较好地考虑了不确定性,并且在校准过程中需要计算的参数最少,因此被确定为最佳算法。此外,SUFI-2算法的主要不足包括:①如果不能充分认识参数对径流和土壤侵蚀的影响,用户运行SUFI-2算法会有困难;②SUFI-2算法没有考虑参数相关性,这会影响SUFI-2算法的性能。
使用SUFI-2算法对模型进行校准和验证获得了月模拟结果,校准期的R2=0.78,NSE=0.76;验证期的R2=0.71和NSE=0.76。SWAT对子流域划分和HRU定义阈值的影响检验表明,径流对HRU定义阈值比对子流域划分更敏感。该流域有760个HRU。95PPU部分与校准期实测信息和验证期实测信息非常吻合。使用SUFI-2计算得到的P因子和R因子表明了模拟结果较好,可以对超过75%的实测数据进行合理估计,因此SUFI-2被认为是一种可行的算法。尽管具有不确定性,但是运行构建的SWAT模型获取的大量结果(以月为步长)有助于开展该流域的水资源管理工作。
《Acknowledgements》
Acknowledgements
We would like to thank the Indian Meteorological Department (IMD) in Pune India for providing the daily meteorological data, and the National Bureau of Soil Survey and Land Utilization Planning in Nagpur India for providing the soil data.
《Compliance with ethics guidelines 》
Compliance with ethics guidelines
NikitaShivhare,PrabhatKumarSinghDikshit,andShyamBihari Dwivedi declare that they have no conflict of interest or financial conflicts to disclose.











 京公网安备 11010502051620号
京公网安备 11010502051620号




