

《1. 引言》
1. 引言
现代制造的特点是高价值、低产量和高客制化,并且要求零缺陷的生产管理,以最大限度地减少废料、提高产品质量和生产率。然而,意外的异常(如加工工具破损、机器主轴故障或严重的工具磨损)可能阻碍我们对于零缺陷目标的追求。因此,开发有效的诊断系统以便有效地检测加工过程中的意外异常至关重要,这使得我们可以对设备进行适当的调整以解决异常[1,2]。为满足这一需求,欧盟委员会在制造业中推动“零缺陷制造”这一概念。因此,为了确定解决方案,委员会亦资助了一批研究项目[如智能故障纠正和自优化制造系统(IFaCOM)项目等]。而从工业角度来看,人们已经开发出一些诊断系统并将其部署在工厂中。此类系统中所采用的一种较流行的策略是通过将关键性能指标(KPI)与由经验丰富的工程师所预设的静态阈值进行比较来识别异常。然而,加工过程通常在不同的工作条件下进行,这导致加工过程中高动态的特性。因此,基于预设静态阈值的诊断系统无法有效地解决动态的问题。
近年来,智能传感器和安全物理系统(CPS)越来越多地被集成到工厂中,以监控加工设备及工装的动态条件。因此,数据驱动诊断系统的相关研究也已得到了积极的推进[3–5]。在此类系统中,人们利用智能与深度学习算法,通过时域、频域或时域/频域比来从大数据流中挖掘分析其中的异常[6,7]。为了在工业中更加有效地应用此类数据驱动系统,我们有必要进行进一步的研究以提高数据处理和分析过程中的系统性能。
本文提出了一种全新的用于计算机数控(CNC)加工过程的数据驱动诊断系统。基于该系统,我们可以实现对于加工过程的连续监控和数据收集。随后通过对监控数据的分析以动态检测机器和工装中的异常。该系统的创新特性如下:
(1)对于所监测的数据设计了去噪、标准化以及校对机制,有助于进行异常分析。
(2)定义了一组关键特征来表示所监视数据最重要的方面。我们将其与阈值进行比较以识别异常。同时,系统采用果蝇优化(FFO)算法对阈值进行优化,以实现对动态加工过程更准确的诊断。
(3)已通过工业应用实例验证了该系统在实际加工过程中的有效性。
《2. 文献综述》
2. 文献综述
过去,基于物理实体和模型的诊断方法是主流方法。而近年来,随着智能传感器、数据分析和深度学习技术的快速进步,人们开发了数据驱动算法以提高诊断的有效性及性能[如玻尔兹曼机(Boltzmann machines)、支持向量机(SVM)、卷积神经网络(CNN)等]。Hu等[8]开发了一种将深度玻尔兹曼机算法与多粒度级联森林算法相结合的工业设备故障挖掘方法。Tian等[9]设计改进了一种支持向量机(SVM)来诊断钢铁厂的故障,他们通过递归特征消除(RFE)算法来减少数据维数,以达到加快计算速度的目的。Zheng等[10]提出了通过复合多尺度模糊熵(CMFE)与集成支持向量机(ESVM)来提取非线性特征并对滚动轴承故障进行分类。然而,所使用的数据之中掺杂了其他冗余的、不相关的特征,这可能大大降低真实的检测率并增加计算时间。Wu和Zhao [11]提出了一种深度卷积神经网络(CNN)模型来检测化学过程的缺陷。然而,深度CNN往往需要较长的计算时间。Madhusudana等[12]开发了一种决策树方法(J48算法)来检测面铣刀的故障情况。通过该方法,人们可利用离散小波变换(DWT)方法从声信号中提取一组离散小波特征。而这项研究的局限在于决策树结构及其阈值难以被定义。Lu等[13]提出了一种双约化核极限学习机方法来诊断航空发动机故障。Wen等[14]提出了一种基于LeNet-5的新CNN;并对该CNN进行了电机轴承测试以及自吸式离心泵和轴向柱塞液压泵故障检测,其精度在99.481%~100%之间。此外,Wen等[15]还提出了一种基于稀疏自动编码器的新型深度迁移学习模型,并将其应用于电机轴承故障检测,其检测精度达到了99.82%。Wen等[16]还提出了一种新的分层卷积神经网络(HCNN),其精度在96.1%~99.82%之间。表1总结了上述研究工作。
《表1》
表1 综述研究方法总结
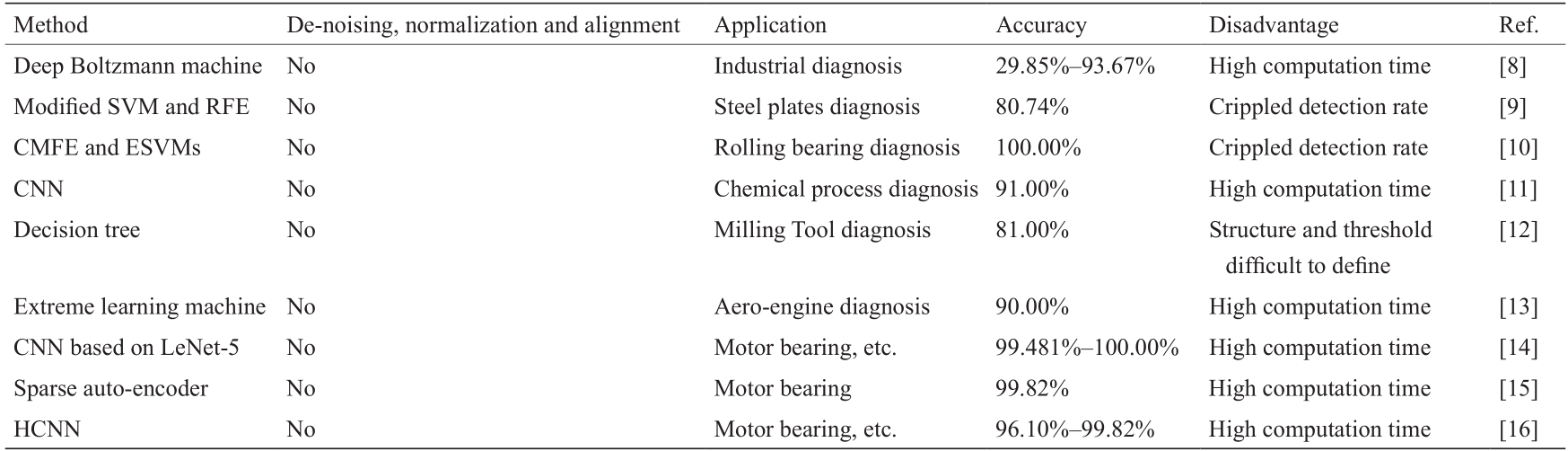
根据García等[17]以及Pan和Yang [18]的调研,在进一步提高数据驱动算法的效率方面存在以下研究空白:
(1)我们有必要为检测数据设计合理的预处理技术,以确保最佳的诊断准确性及诊断效率。
(2)深度学习算法通常需要很长的训练时间才能达到高精度。获取足够的错误数据模式用于算法训练也是困难和昂贵的。
(3)对不同故障进行分类的阈值通常由经验丰富的工程师预先设定。这对于现代生产中日益动态化的环境而言并非最佳解决方案。
《3. 系统结构》
3. 系统结构
计算机数控(CNC)机床中控制电机的功率数据可以反映出机床与工装的工作条件[19,20]。此外,与振动传感器或声学传感器[21,22]相比,功率传感器在实际应用中更具成本效益。因此,在本系统之中,我们选用由安装在计算机数控(CNC)设备上的无线传感器网络(WSN)作为数据来源,以此收集功率数据以支持生产设备和工装的异常诊断[5]。系统结构如图1所示。其功能说明如下:
《图1》

图1. 数控加工过程的系统框架。
(1)数据存储库:我们配备并部署了一个大型数据基础设施,在生产过程中用于收集、存储及可视化实时监控数据[5]。
(2)数据预处理:考虑到监控数据的准确性,我们设计了数据预处理机制。这些机制包括:①根据各个加工过程将数据划分为时间序列数据集;②利用高斯核模型[23,24]对来自监测数据源的波动信息进行去噪,以便进一步处理;③对数据进行标准化以确保监测数据的规模适合分析;④基于协方差交叉算法[5]进行数据校对,以标准和预设的参考模式重新调整功率数据,以便进行异常识别。
(3)特征表示与异常识别:预设一组关键特征用于生产过程中的异常分析与诊断。关键特征的阈值则通过与实时数据比较用于异常识别。该系统对过程中产生的新异常保持开放,并在加工过程中动态更新。
(4)阈值优化:我们设计了一种优化算法,以历史监测的数据为基础确定优化的阈值。
《4. 监控数据预处理》
4. 监控数据预处理
《4.1. 监控数据分区处理》
4.1. 监控数据分区处理
在加工过程中获得的监测功率数据将用于故障诊断。功率的计算公式如下:
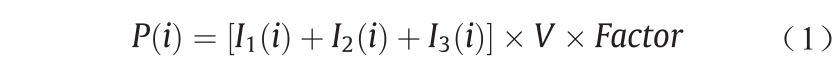
式中, 为沿时间轴(x轴)的功率数据的第i 个点;
为沿时间轴(x轴)的功率数据的第i 个点; 代表三相电流;V\为电源的电压;Factor为电源的质量系数。对加工过程中采集到的所有功率数据进行分析是耗时且无效的。为便于分析,我们首先根据机器特定的功率水平对监控数据进行分区,以表示加工过程的各道工序。然后对已分区的监视数据应用下述步骤以便于进一步分析。
代表三相电流;V\为电源的电压;Factor为电源的质量系数。对加工过程中采集到的所有功率数据进行分析是耗时且无效的。为便于分析,我们首先根据机器特定的功率水平对监控数据进行分区,以表示加工过程的各道工序。然后对已分区的监视数据应用下述步骤以便于进一步分析。
《4.2. 监控数据的降噪及平滑处理》
4.2. 监控数据的降噪及平滑处理
通常而言,由于信号中的噪声干扰,监控的功率数据往往存在一定波动。为有效提取关键特征,必须对所监视的数据进行去噪与平滑处理。在本研究当中,我们设计了一种基于高斯核的模型用于数据降噪处理。Feng等[23]以及Rimpault等[24]的研究已经证明了高斯核的鲁棒性。在此处,我们通过高斯核卷积计算来平滑处理所监测数据。在第i点处去噪及平滑处理后的功率数据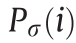 计算如下:
计算如下:

式中,n 为P(功率数据)中的总点数;xj 为沿x 轴(时间)的P 中的第j 个点;而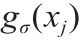 则为内核宽度为σ 的第j 个点的高斯核。
则为内核宽度为σ 的第j 个点的高斯核。
上述过程的一个示例如图2所示。
《图2》

图2. 监控数据的数据分区与去噪示例。(a)在一天内(2016年5月31日)获得的功率数据;(b)分区与去噪后两个分区进程的功率模式(红色)。
《4.3. 监控数据的标准化》
4.3. 监控数据的标准化
为确保数据具有恰当的比例,我们对监测数据进行标准化,以便从数据之中提取关键特征(例如,在第5节中描述的峰值在没有标准化的情况下极高):
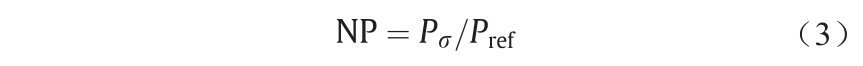
式中,NP为标准化的功率数据;Pσ 为原始功率数据;Pref 为机器设备的参考功率数据。
《4.4. 监控数据校对》
4.4. 监控数据校对
在实际的制造条件下,当加工部件时,分区监控数据可能存在时间延迟或偏差,这将会导致与标准模式(即在正常工作条件下加工相同部件时的功率模式)的不一致。我们将监测数据与参考标准( )进行协方差交叉运算以识别时间延迟[5]。
)进行协方差交叉运算以识别时间延迟[5]。
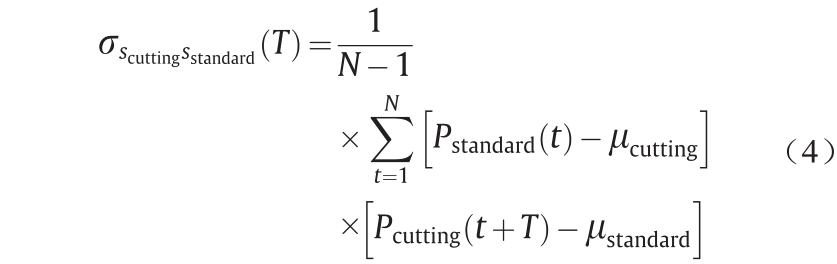
式中,Pstandard 和Pcutting 分别为参考标准和分区监控数据;μstandard 和μcutting 为时间序列的均值;N 为两个数据集当中较小的数;而t 和T 分别为时间偏差与标准时间。时间延迟可以通过以下公式计算:

当Xcoef 取最大值时,时间延迟可计算如下:

因此,经校准的监控数据为:

将监测数据与故障参考Pfault (即在异常条件下加工相同部件时的功率模式)进行校准时,亦是相同的步骤。只需将上述公式中的Pstandard 换为Pfault 。
《5. 异常检测过程》
5. 异常检测过程
在加工过程中,我们将定义一些关键特征用以表示预处理的监测数据与参考标准(即在正常工作条件下加工相同部件的数据模式)间的差异。在良好的工作条件下,我们在部件加工的过程收集数据以形成参考标准。如图3所示的诊断程序包括以下步骤:
《图3》
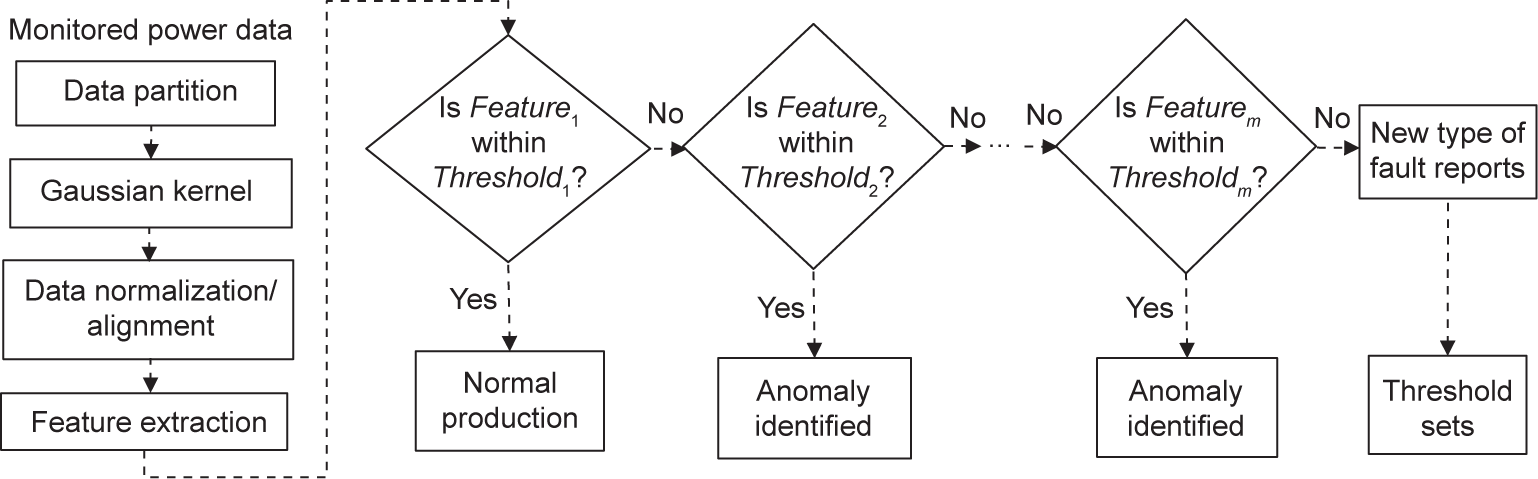
图3. 异常诊断过程。
(1)关键特征是基于数据的绝对平均值、峰值以及峰值因子矩阵来表示的。相关定义详见表2。在表2当中,Featurem 是根据每条经预处理的监测数据及其标准参考值计算而得的。Feature2 ~ Featurem 是根据每条经预处理的监测数据及其故障参考值计算而得的(其中,m 的含义是异常类型)。
《表2》
表2 标准参考、错误参考和监控数据的特征和阈值的定义[25]
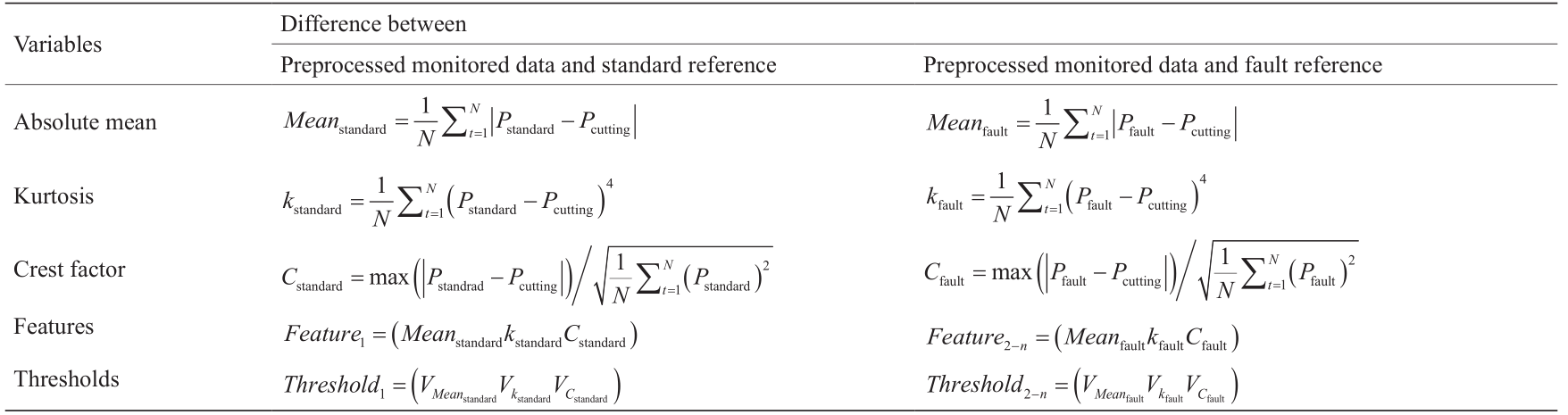
(2)定义了一系列的阈值。我们设立Threshold1 ,通过比较Feature1 和Threshold 1 就可以确定情况为正常或异常。我们设立Threshold2 ~ Thresholdm ,可分别通过比较Feature2 ~ Featurem 和Threshold2 ~ Thresholdm 来对异常类型进行分类。如果不存在现有的异常类型进行匹配,系统则会将新的异常类型更新到数据库当中。
(3)基于最新的历史数据,通过FFO算法周期性地优化上述阈值。
在本研究当中,我们根据下述规则定义异常的工作环境[5]。
• 刀具等工具磨损:功率范围明显垂直移动,但在设备空转阶段的功率范围保持不变。
• 刀具等工具破损:功率先是增加到峰值,随后又回到切割空气的功率范围。
• 主轴故障:在加工过程与设备空转阶段均突然出现功率峰值,同时功率范围增大。
根据上述规则与历史数据,我们可以对上述异常条件下的三个阈值做出定义:判断刀具等工具磨损的Threshold2 ,判断刀具等工具破损的Threshold3 和判断主轴故障的Threshold4 。确定最佳阈值的过程将在下一节中介绍。
《6. 阈值优化》
6. 阈值优化
正如我们之前的研究中[5]所讨论的那样,整体检测准确度可以由四个因素决定:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。TP 表示异常情况被正确识别为异常;FP表示正常情况被错误识别为异常;TN 表示正常情况被正确识别为正常;而FN 表示异常情况被错误识别为正常。基于上述四要素,我们引入Precision, Recall 和F 来评估整体检测精度[26]:

式中,Precision为正确识别的异常条件与所有参与识别的异常条件的比例;Recall为正确识别的异常情况与所有实际异常情况的比例;F 为检测的总体准确性。F 得分越高(即越接近1),表明检测的整体准确度越高。
TP, FP, TN 和FN 受四个阈值(即Threshold 1 , Threshold 2 , Threshold 3 , Threshold4 )的影响。因此,阈值的选择会影响最终的F 分数。
在本研究中,阈值通过历史监测数据使用FFO算法而非依赖于专家的经验进行优化。FFO能够避免局部最优,并且具有比其他一些主流优化算法更优异的性能[27,28]。在该算法当中,我们对群体中心进行初始化以进行搜索(在本研究中,每个中心被模型化为四个阈值的向量,即Threshold 1 ~ Threshold4),随后围绕着每一个群体中心,将生成所谓的“果蝇”随机解决方案,我们利用基于气味与视觉的策略分别对最优化程度和群体中心的选择进行计算(详见步骤3和步骤4)。最终计算迭代以达到优化目的。
优化目标是确定使得分数F可以取到最大的最佳阈值,我们取向量:

优化过程如下所述(步骤2和6中提供了对典型FFO算法的改进方案):
步骤1 设最大迭代次数为Tmax ,群体中心的种群大小为v,每个群体中心周围的果蝇数量为k。
步骤2 根据以下公式在每个群体中心周围随机生成果蝇:

式中,Vectorcenter 和Vectorsub 分别为每个群体中心以及该群体中心周围的果蝇子群的向量;α为确定果蝇在每个群体中心周围搜索边界大小的决定变量;而rand 代表一个随机数。
步骤3 进行基于气味的搜索以计算每个果蝇对应的气味浓度(即最优化程度)。
步骤4 进行基于视觉的搜索,用具有相对最优效果的子群中的果蝇代替原来的群体中心,并指导子群进一步进行搜索。
步骤5 在典型的FFO算法中,搜索距离总是恒定的,所以当果蝇接近最终的最优结果时,搜索往往难以收敛。因此为了改进算法,当优化结果在五次迭代后仍没有得到进一步改善时,我们将缩短搜索距离。(这提高了收敛速度,因为当果蝇群体接近解决方案时,可以更容易地靠近该解决方案[29]。)
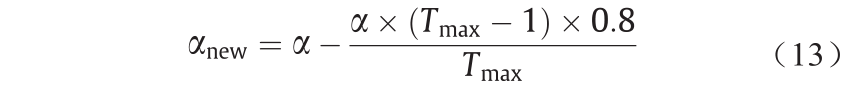
式中,αnew 为接近最佳结果时所缩短的搜索距离。
步骤6 重复上述步骤,直到达到收敛的解或最大迭代次数Tmax 。
《7. 案例研究》
7. 案例研究
在“欧盟智能及云端流量建构项目”(EU Smarter and Cloudflow projects)的赞助下,我们在英国一家公司的车间内开发和部署了一个无线传感器网络。该公司专门从事汽车、航空航天以及模具应用的高精度加工。在本实践研究当中,我们对五轴铣床MX520进行了监控。6个月以来,我们收集到了超过10 GB的功率数据并将其储存在本地数据库当中。随后,基于开源平台Hadoop,我们开发了一个大型数据处理基础设施,用于管理海量数据并加速数据处理。
生产线的一部分如图4所示。三台电流传感器(每相一个)夹在数控机床的主电源上,每个传感器的数据搜集速率为每秒一个样本;随后,每秒产生的样本将通过工厂车间里的Wi-Fi传输到Hadoop的数据服务器。此后我们会根据三相电流、220 V电压和0.82的电源质量系数计算功率。
《图4》

图4. CNC加工过程。(a)机加工零件;(b)功率测量;(c)马扎克机床及其加工工艺。
在本案例研究中,FFO算法旨在根据历史数据确定可以使F取得最高分数的最佳阈值。表3显示了此优化过程的基准测试结果。Threshold 1 的优化阈值为(0.192, 0.032, 0.287),代表刀具等生产工具磨损的阈值Threshold 2 为(0.632, 0.410, 0.652),代表刀具等生产工具破损的阈值Threshold 3 为(3.698, 75.363, 10.737),代表主轴故障的阈值Threshold 4 为(2.412, 1.081, 0.921)。FFO算法可以在23次迭代中实现最优结果,与其他基准算法相比,收敛速度最快。同时,它可以使F的得分取值为1,这意味着优化的阈值可以基于历史数据实现100%的真实检测率。下文将介绍一些异常检测和识别的示例。
《表3》
表3 优化算法的比较

GA: genetic algorithms; SA: simulated annealing.
《7.1. 正常生产》
7.1. 正常生产
图5显示了用于异常检测的监测数据的分析过程。所取的关键特征Feature 1 为(0.147, 0.004, 0.113),小于Threshold 1 (0.192,0.032,0.287)(特征和阈值的定义见表2)。因此,它可以被归类为正常生产。
《图5》
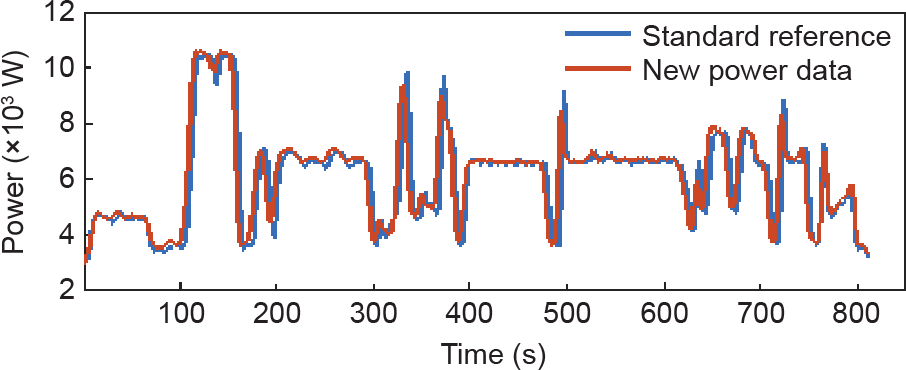
图5. 监测数据表明生产条件正常。
《7.2. 异常情况——刀具等生产工具磨损》
7.2. 异常情况——刀具等生产工具磨损
对于图6 (a)中所示的监测数据,其Feature1 为(0.206, 0.042, 0.295),高于阈值Threshold1 (0.192,0.032,0.287)。因此,此生产过程被归类为存在异常。随后,我们对其进行异常诊断[图6(b)]。Feature2 为(0.171, 0.058, 0.250),小于Threshold 2 (0.632, 0.410, 0.652)。因此,该生产异常可以被分类为工具磨损。
《图6》
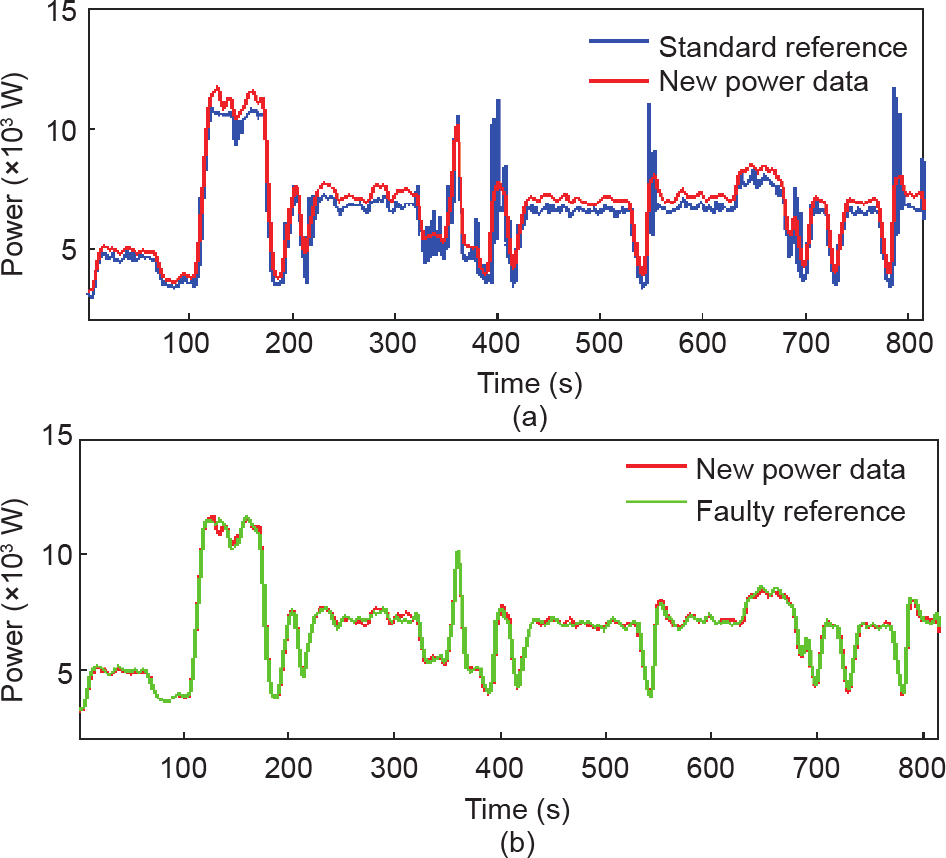
图6. 刀具等生产工具磨损检测。(a)故障识别;(b)故障分类。
《7.3. 异常情况——刀具等生产工具破损》
7.3. 异常情况——刀具等生产工具破损
对于图7(a)所示的监测数据,Feature 1 为(0.460, 41.532, 2.303),高于Threshold 1 (0.192, 0.032, 0.287)。因此,此生产过程被归类为存在异常。随后,我们对其进行异常诊断[图7 (b)]。Feature3 为(1.039, 61.512, 1.744),小于阈值Threshold3 (3.698, 75.363, 10.737)。因此,该生产异常可以被分类为工具破损。
《图7》
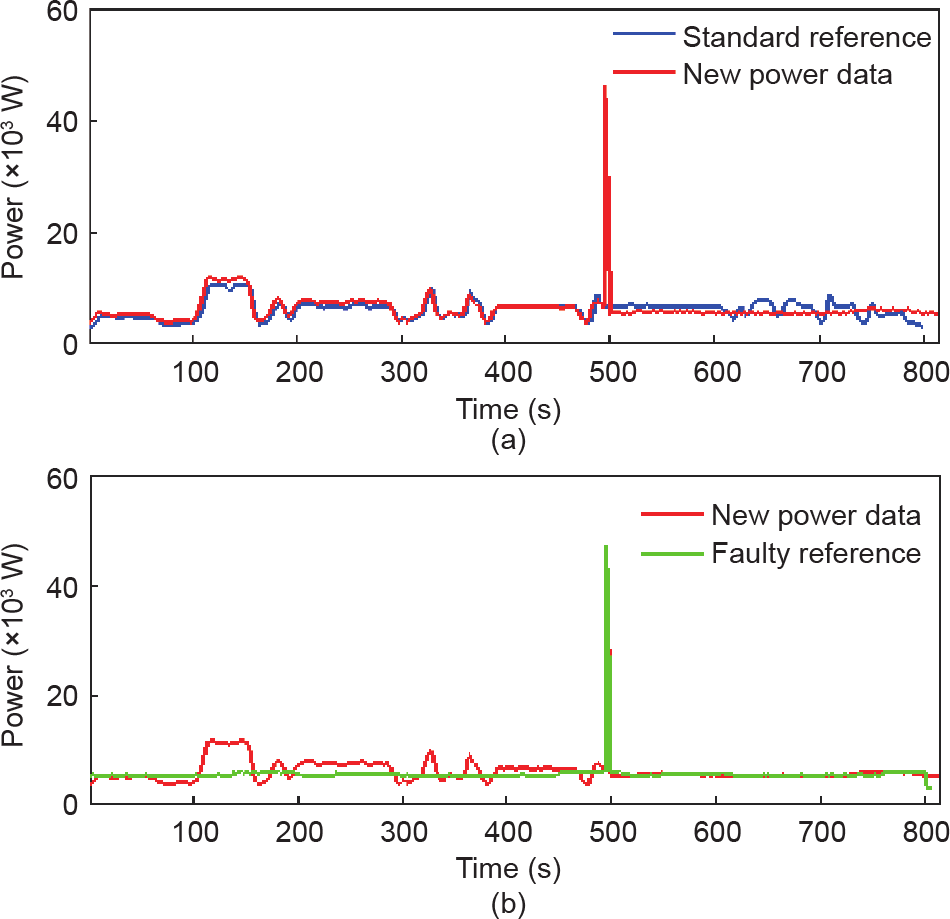
图7. 刀具等生产工具破损检测。(a)故障识别;(b)故障分类。
《7.4. 新的异常情况——设备长时间空转》
7.4. 新的异常情况——设备长时间空转
图8显示了用于异常检测的监测数据的分析过程。Feature1 为(0.492, 0.441, 0.379),高于Threshold1 (0.192, 0.032, 0.287)。因此,此生产过程存在异常。但是,数据库中没有类似于此数据模型的故障参照。因此,该情况下产生的数据被报告给了车间工程师。最终发现设备意外地一直在空转。随后,该数据模型被保存至数据库以更新故障参照。
《图8》

图8. 新的异常数据检测。
《8. 总结》
8. 总结
在本研究中,我们开发了数据驱动的异常情况分析方法。该系统在某机加工企业进行了实际加工条件下的验证。本研究的创新点如下:
(1)开发了预处理机制,包括去噪、数据标准化和校准,解决了监控数据的准确性问题。
(2)设计了FFO算法来识别最佳异常阈值,以便在动态加工过程中实现更准确的检测。今后,我们将进行进一步的调查,以提升该系统的可靠性,调查将包括以下内容:①我们将测试不同的数据采样率,以找到最佳的系统精度和效率。此外,我们将尝试通过使用数据融合来增强预测结果,并考虑不同的数据源(如振动、力数据等)。②我们将考虑设计高效的深度学习算法以及有效的计算架构[如用于递归神经网络(RNN)、长短期记忆递归神经网络(LSTM RNN)等的迁移学习算法和边缘计算架构],以进一步提高系统性能。
《Acknowledgement》
Acknowledgement
The authors acknowledge the funding from the EU Smarter project (PEOPLE-2013-IAPP-610675).
《Compliance with ethics guidelines》
Compliance with ethics guidelines
Y.C. Liang, S. Wang, W.D. Li, and X. Lu declare that they have no conflict of interest or financial conflicts to disclose.











 京公网安备 11010502051620号
京公网安备 11010502051620号




