

《1 引言》
1 引言
在众多的聚类算法中, 一类基于熵
大量实验表明, MEC算法对例外点较敏感, 例外点的干扰常使学习得到的聚类中心严重偏离正确的聚类中心。现实中的数据集, 例外点是普遍存在的, 因此对MEC算法进行改进, 提高算法对例外点的抗干扰能力即鲁棒性能很有必要。同时, 大量事实表明, 数据集中的例外点暗含一些重要的信息, 这些重要信息对于科学研究和生产实践有着非凡意义。例如, 在地球南极的臭氧层漏洞被人类地面的观测者发现时, 地球卫星在数年前就已探测出这个漏洞的存在, 只是计算机程序在处理卫星数据时未能检测出暗含漏洞信息的例外点, 这使得人类对臭氧层漏洞未采取任何补救措施达9年之久。因此, 聚类算法对数据集进行聚类的同时如能有效地对例外点进行检测, 其意义重大。遗憾的是, 几乎所有的MEC算法都没有检测和标识例外点的能力。近年来, 如何利用聚类方法标识大量数据中的例外点受到了越来越多的关注, 业已提出了一些检测例外点的有效方法
针对提高MEC聚类算法对例外点干扰鲁棒性和有效检测例外点的需要, 笔者通过引入Vapnik´s ε-不敏感损失函数
《2 极大熵聚类算法MEC》
2 极大熵聚类算法MEC
在多种版本的极大熵聚类算法MEC中, 虽然描述各不相同, 但只是形式上的差别。这里仅介绍文献
对于样本集X={xixi∈Rd, i=1, 2, …, n}, 根据某种相似性度量, 它被聚类成c (2≤c<n) 个子类, 各类中心用矩阵V=[v1, v2, …, vc] vi∈Rd, i=1, 2, …, c表示;划分可用矩阵U=[uik]∈Rcn表示, 其中每一项满足
极大熵聚类算法MEC的目标函数定义为
这里‖·‖表示欧几里德距离, γ是非负常数。
对于目标函数J, 如下定理成立:
定理1 J (U, V) 取极小值的必要条件为
基于定理1, 可以把极大熵聚类算法MEC描述如下:
Step 1 固定c (2≤c<n) , 置精度级为εa, 迭代次数r=0, 初始化分割矩阵U (0) ;
Step 2 利用式 (3) 计算出V (r) ;
Step 3 利用式 (4) 和V (r) 更新U (r) 为U (r+1) ;
Step 4 若‖U (r+1) -U (r) ‖F ≤εa (亦可根据需要改置其他条件) , 则停止, 否则置r=r+1, 并返回Step 2。
其中‖·‖F表示Frobenius范数。上述极大熵聚类算法MEC的一个缺陷是对数据集中的例外点较敏感, 这极大地影响了极大熵聚类算法MEC的性能, 同时, 该算法也不具备检测例外点的能力。针对此问题, 笔者提出新的聚类算法——鲁棒极大熵聚类算法RMEC (robust maximum entropy clustering) 。
《3 算法RMEC》
3 算法RMEC
《3.1改进的目标函数》
3.1改进的目标函数
算法MEC中用二次方损失函数
Vapnik´s ε-不敏感损失函数可表示为
其中ε≥0表示不敏感性参数, 当ε=0时, Vapnik´s ε-不敏感损失函数变为绝对误差损失函数。
为了使新的算法能对数据集中的例外点进行有效的检测, 新的目标函数同时引入了权重因子
利用Vapnik’s ε- 不敏感损失函数代替二次损失函数, 同时引入权重因子和不敏感参数惩罚项, 可以重新构造目标函数为
其中
q是一个由用户定义的指数常数。εi= (εi1, εi2, …, εid) 为第 i类的不敏感参数矢量。式 (8) 定义的好处在于有很好的抗例外点干扰能力, 文献
1) 新的目标函数可以保证J的前两项最小的同时使得不敏感参数惩罚项尽可能的小。通过调整γ可以灵活地根据需要确定不敏感参数惩罚项的影响。
2) 引入不敏感参数惩罚项能使推导出的新算法自动调节不敏感性参数, 不再需要人为地确定不敏感性参数, 这就避免了不敏感性参数选取的随意性 (见定理2证明) 。
3) 总的来说, 例外点远离数据集中的任何一类。RMEC算法赋予例外点一个较大的权重因子wk (一个较小的值1wkq) , 新构造的目标函数中权重因子的引入, 使得RMEC算法能根据学习后得到的权重因子数值检测出数据集中的例外点xk (wk >w0) , w0为阈值, 一般由专家给出。参数q在聚类处理中扮演重要的角色, q足够大时, 每个数据点的权重因子趋近于Wn, 也就是所有的数据有相同的权重因子, 当q趋近于0时, 权重系数的影响将达到最大。
《3.2算法RMEC的推导及证明》
3.2算法RMEC的推导及证明
为了得到RMEC算法, 首先证明下面的定理:
定理2 目标函数式 (7) 取极小值的必要条件是
《图1》
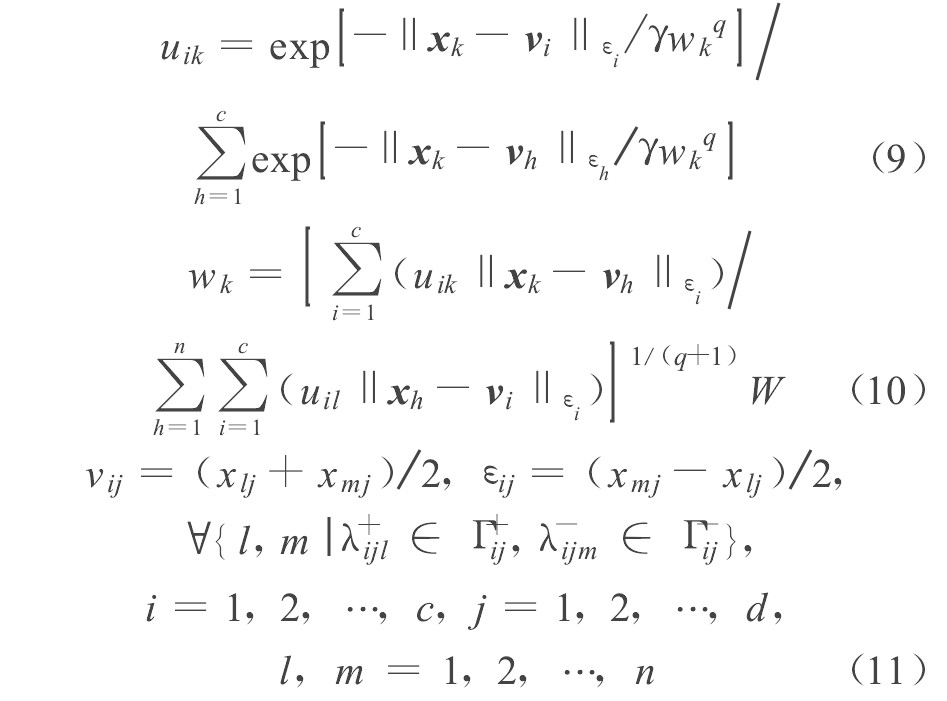
式中:
证明 如果w, ε, V一定, 求目标函数式 (7) 的极小值可以表述为求式 (14) 的极小值。
式 (14) 在约束条件式 (1) 下的拉格朗日函数为
λk是拉格朗日乘子。式 (15) 取极值时, 拉格朗日函数梯度为0, 得到
由式 (16) 得出
由式 (17) 得出
由式 (18) 和式 (19) 可得
式 (19) 和式 (20) 两边分别相除得
于是式 (9) 得证。
参照式 (9) 的证明方法, 可得式 (10) 的证明结果。
如果w, U一定, 求目标函数式 (7) 的极小值可以表述为求式 (21) 的极小值。
式 (21) 取极小等价于式 (22) 取极小。
一般来说, 不是所有的样本数据分量xkj, k=1, 2, …, n, j=1, 2, …, d 都满足不等式
如果引入松弛变量ξ+ijk, ξ-ijk≥0, 对于所有的样本数据分量xkj可满足下面的不等式
于是式 (22) 可表示为
其中约束条件为式 (24) 和ξ+ijk, ξ-ijk≥0。对含有上述约束条件的式 (25) 的拉格朗日函数为
式中λ+ijk, λ-ijk, μ+ijk, μ-ijk, βij≥0是拉格朗日乘子。问题求解的目标是拉格朗日函数式 (26) 相对于vij, ξ+ijk, ξ-ijk, εij 取最小, 同时相对于拉格朗日乘子变量取最大。拉格朗日函数式 (26) 相对于vij, ξ+ijk, ξ-ijk, εij最小时, 满足条件
λ+ijk, λ-ijk, μ+ijk, μ-ijk, βij≥0和式 (27) 至式 (30) 表明λ+ijk, λ-ijk∈[0, uik
由经典的拉格朗日对偶理论知,
即为求解问题的所谓Wolfe对偶表达。令
式 (32) 可分解为式 (34) 的优化问题:
亦即
按照优化理论的Kuhn-Tucker定理, 在鞍点, 对偶变量与约束的乘积为零, 即
又由式 (28) 和式 (29) 可得
结合式 (36) 和式 (37) , 进行如下推理:
当λ+ijk, λ-ijk∈ (0, uik/wkq) 时, 由式 (37) 可知μ+ijk, μ-ijk∈ (0, uik/wkq) , 由式 (36) 中可知此时ξ+ijk=0, ξ-ijk=0并可得到
即
这样, 可以根据任意样本分量xlj, xmj, 当λ+ijl, λ+ijm∈ (0, uikwkq) 时, 由式 (39) 确定聚类中心分量vij和不敏感性参数εij的值。 从而式 (11) 至式 (13) 式得证。
基于定理2, 可以得到RMEC算法:
Step 1 固定c (2≤c<n) , 置精度级为εa, 迭代次数r=0, 初始化分割矩阵U (0) 和权重因子向量w (0) ;
Step 2 利用式 (11) 计算出V (r) ;
Step 3 利用式 (9) (10) 和V (r) 更新U (r) , w (r) 为U (r+1) 和w (r+1) ;
Step 4 若‖U (r+1) -U (r) ‖F ≤ εa (亦可根据需要改置其他条件) , 则停止, 否则置r = r + 1, 并返回Step 2。
对于RMEC算法中的α≥0, 当α= 0时, 有式 (13) 可以得出λ+ijk, λ-ijk=0此时由式 (11) 和式 (12) 可知vij, εij得不到更新, 故仅当α>0时RMEC算法才能有效地执行。
《4 仿真实验及实验分析》
4 仿真实验及实验分析
为了考察RMEC算法的性能, 做了大量的仿真实验。实验从3个不同的方面对RMEC算法的性能进行考察。
实验1 此例说明可以用权重因子来标识数据集中的例外点。图1a是含有例外点的数据集, 图1b显示了γ= 0.05, q=0.9, W=200, w (0) =32时, RMEC聚类算法的聚类效果。图1b中示出了数据点的等势线, 等势线上的各点具有相同的权重因子。根据专家提供的权重因子阈值w0, 就可以标识数据集中的例外点, 即那些权重因子大于w0的数据点。图1b中* 点为被检测出的例外点 (wk>w0) 。
《图2》
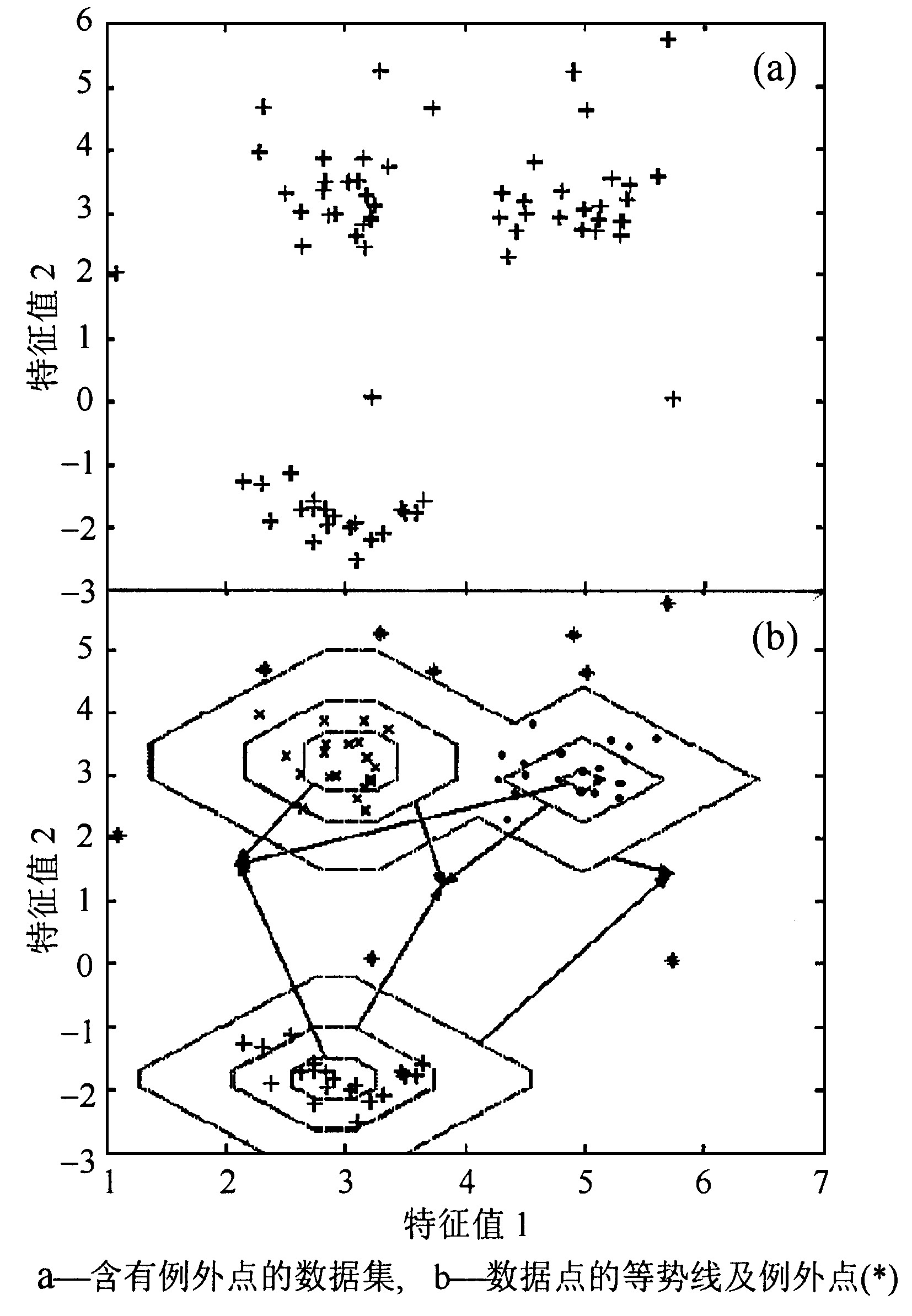
Fig.1 The clustering result of algorithm RMEC and the labeled outliers (*)
实验2 为了比较RMEC算法和MEC算法
《图3》
![图2 例外点个数分别为0~8时, MEC算法[5]和RMEC算法 (α = 5) 聚类结果](/views/uploadfiles/download/GCKX200409007_114.jpg)
图2 例外点个数分别为0~8时, MEC算法
Fig.2 The clustering results of MEC
如果真正的聚类中心用矩阵V1表示, 存在例外点时算法执行得到的聚类中心用矩阵V2表示, 则可用Frobenius范数ΔV=‖V1-V2‖F 表示受例外点影响聚类中心的偏移量。ΔV越小, 表示算法的抗例外点干扰能力越强。表1示出了RMEC算法取不同参数值α时类中心的偏移量和MEC算法
从表1可以看出, MEC算法聚类结果受例外点影响很大, 随着例外点数目的增加, 偏移量ΔV越来越大。从表1可以看出α≥3时, RMEC算法受例外点影响则较小, ΔV在例外点数目为0~8的范围内基本稳定, 并且RMEC算法能得到较合理的聚类中心, 但α≤2 时RMEC算法聚类中心稳定点已不合理, 如图3a所示。试验结果表明, α取较大值时RMEC算法能得到较理想的聚类效果, 如图3b至图3d所示。当例外点数目很少时, MEC算法得到的聚类中心偏移量ΔV较RMEC算法得到的聚类中心偏移量ΔV小, 但随着例外点数目增加时, 选取合适参数α, RMEC算法聚类效果明显优于MEC算法聚类效果。
对于MEC算法
表1 RMEC算法和文献中的MEC
Table 1 The performance comparison between MEC
《表1》
例外点数目 | RMEC算法 ΔV | MEC算法 ΔV | ||||||
α = 0.1 | α = 0.5 | α = 1 | α = 2 | α = 3 | α = 10 | α = 100 | ||
0 | 4.375 6 | 4.366 4 | 0.881 1 | 0.195 6 | 0.195 6 | 0.195 6 | 0.195 6 | 0.056 7 |
1 | 4.385 8 | 4.360 6 | 1.919 2 | 0.304 9 | 0.285 2 | 0.285 2 | 0.285 2 | 0.209 1 |
2 | 4.353 7 | 4.355 9 | 1.814 9 | 0.226 6 | 0.285 6 | 0.285 6 | 0.285 6 | 0.295 6 |
3 | 4.432 3 | 4.353 5 | 4.891 1 | 0.260 2 | 0.301 6 | 0.301 6 | 0.301 6 | 0.400 3 |
4 | 4.432 3 | 3.954 0 | 4.859 4 | 0.248 2 | 0.301 9 | 0.317 8 | 0.317 8 | 0.518 2 |
5 | 4.432 3 | 2.645 2 | 2.417 9 | 0.254 1 | 0.301 9 | 0.301 9 | 0.301 9 | 0.645 8 |
6 | 4.432 3 | 2.831 2 | 0.515 6 | 3.482 0 | 0.304 1 | 0.304 1 | 0.304 1 | 0.779 9 |
7 | 4.432 3 | 2.633 6 | 0.802 6 | 1.506 2 | 0.319 8 | 0.319 8 | 0.319 8 | 0.918 5 |
8 | 4.432 3 | 2.653 2 | 2.647 1 | 0.275 4 | 0.319 8 | 0.319 8 | 0.319 8 | 17.471 |
《图4》
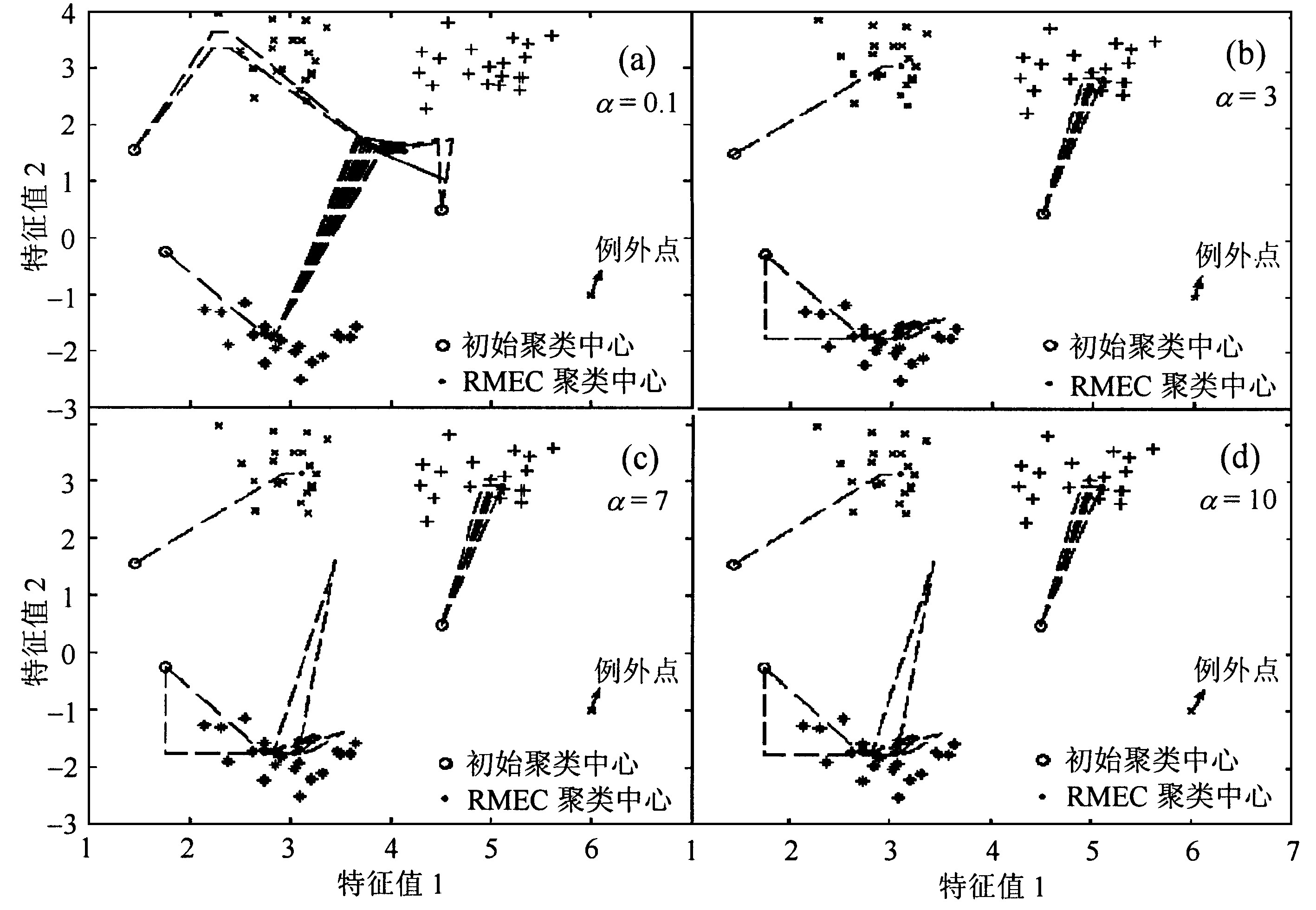
图3 例外点个数分别为1~8, α= 0.1, 3, 7, 10时RMEC算法的聚类效果
Fig.3 The clustering results of RMEC algorithm with different α (α=0.1, 3, 7, 10)
实验3 图4a是中国的一个城市的卫星灰度图像, 通过RMEC聚类算法可对其进行分割并检测图像中的例外点信息, 即乌云。其过程如下:第一步, 以图像像素点的灰度值为特征向量构造数据集;第二步, 令γ = 5, q = 2, W = 200, α = 3, w (0) =11, 用RMEC算法对数据集进行聚类, 以聚类结果对图像进行分割的效果如图4b所示;第三步, 利用聚类后得到的各数据的权重因子检测例外点, 图4c示出了RMEC聚类算法检测出的例外点在图4a中的分布, 这些例外点表示图像中存在的乌云信息。
从实验3可以看出, RMEC算法在图像处理中也能得到很好的应用。可以预测, RMEC算法亦可以应用于医学图像分析, 数据挖掘等领域。
《图5》

图4 卫星图像的RMEC算法分割结果及检测出的例外点信息 (乌云) Fig.4 The result of RMEC algorithm on the satellite image segmentation and the labeled outlier information (clouds)
《5 结语》
5 结语
针对极大熵聚类算法MEC对例外点较敏感和不具备检测例外点能力的缺陷, 提出了一种改进的极大熵聚类算法RMEC。RMEC算法不但较传统的MEC算法对例外点有更好的鲁棒性, 而且还能利用学习后的权重因子检测出数据集中存在的例外点, 根据检测出的例外点, 可以发现一些重要的信息。下一步工作, 将对RMEC算法做更深入的研究, 以期进一步有效地应用于图像处理, 数据挖掘, 建模等领域。











 京公网安备 11010502051620号
京公网安备 11010502051620号




