

《1. Introduction and background》
1. Introduction and background
The concept of artificial intelligence was first proposed in 1956 [1]; since then, profound changes have taken place in the development of artificial intelligence based on information technology and an increased data scale [2]. These changes are particularly outstanding in certain fields, such as the mobile Internet, big data, supercomputing, sensor networks, and brain science. The Development Plan for a Next-Generation Artificial Intelligence [3], which was issued by the State Council of China in July 2017, describes artificial intelligence as moving into a new stage. The plan outlines how the new generation of artificial intelligence will be characterized by deep learning, cross-border fusion, human– machine collaboration, crowd intelligence, and autonomous intelligence. The foundation of these technologies is big-data-driven methodology [4]. Pan [2] has also described big data intelligence as the basic method and important development direction of the new generation of artificial intelligence.
Deep learning, which was developed by Hinton and Salakhutdinov [5], has become the key technology of big data intelligence [6] and has led to major breakthroughs, such as intelligent driving [7], smart cities [8], voice recognition [9], and information retrieval [10]. Compared with classical statistical machine-learning methodologies, deep learning, as the core of the big data intelligence method, has a relatively complex model structure. The size and quality of a dataset can significantly affect a deep-learning classifier. Large-scale annotated sample data are required in order to fully optimize the model parameters and obtain superior performance [11]. In other words, under the existing framework, the performance of a deep-learning model is determined by the scale and quality of the annotated data; this situation also influences the development of the new generation of artificial intelligence. Nevertheless, it is both difficult and expensive to obtain labeled sample data in many real-world applications. For example, a series of long-term and expensive experiments [12] is required to generate a training sample in biology, which can then be used to train the classifiers with high accuracy. In the field of computerized numerical control (CNC) machine tools, it takes decades to accumulate annotation datasets of a sufficient size, while data on certain specific cases of CNC are rare [13]. Meanwhile, the implementation of big data methods in CNC can be even more difficult in China, where CNC is still in the developmental stage. In strategic intelligence analysis, the labeling of samples requires close and seamless cooperation among outstanding experts from multiple fields [14–20]; thus, it is extremely expensive to obtain sufficiently sized datasets. In addition to the high cost, the data features are complicated and high dimensionality exists. In this situation, the dimensionality of the original feature space is approximately equal to or greater than the number of samples, which is known as ‘‘the small sample size problem” [21]. With a small sample size, deep learning is restricted to good generalization performance. Furthermore, the development of a new generation of artificial intelligence is limited because there are considerably more fields with a small sample size than fields with a big data environment [22–26].
In previous studies, several oversampling methods have been proposed in order to address the insufficiency of the data scale. The main advantage of these methods is that they are selfsufficient. In the early stage, the training set can be enlarged by duplicating the training examples of the minority class if the examples of different classes are imbalanced, or by creating a new dataset by adding artificial noises to the existing ones [27]. In 2002, Chawla et al. [28] proposed a classic oversampling method, called the synthetic minority oversampling technique (SMOTE), which involves the creation of a synthetic minority class dataset. On the basis of the SMOTE method, Han et al. [29] proposed two novel minority oversampling techniques, which consider neighboring instances and only the minority instances near the borderline, respectively. In 2008, He et al. [30] proposed the adaptive synthetic sampling approach, which utilizes a weighted distribution for minority class instances according to the level of difficulty in learning. The majority weighted minority oversampling technique was then proposed in 2014 by Barua et al. [31]. This method aims to generate useful synthetic minority class instances by identifying hard-to-learn minority class samples and assigning weights based on their Euclidian distance from the nearest majority class instance. It then generates synthetic instances using a clustering method. Many more methods have been developed to meet dataset demands. In 2015, Xie et al. [32] suggested a minority oversampling technique based on local densities in a low-dimensional space in order to address the problem of dimensionality that affected earlier methods; this technique involved mapping the trained sample into a low-dimensional space and assigning weights. In 2017, Douzas and Bacao [33] proposed a self-organizing map oversampling method, in which artificial data are used for certain classifiers. Most of the abovementioned methods focus on imbalance learning, in which better performance can be achieved by adding oversampling instances to the minority class dataset. However, datasets in many realms remain insufficient, rather than imbalanced, in every class.
In order to address the small sample size problem, a few traditional approaches other than SMOTE have also been raised. In 1995, Bishop [34] proposed that training with noise could lead to a good result; this concept is equivalent to Tikhonov regulation. In 2004, the neural-ensemble-based C4.5, a decision tree method, was introduced by Zhou and Jiang [35]; this method first trains a neural network, and then employs it to generate a new training set. A virtual sample generation method based on an internalized kernel density estimate was introduced by Li and Lin [36] in 2006; this method involves determining the probability density function of the samples, which is then used to generate training samples. In 2009, Li and Fang [37] again proposed a non-linear virtual sample generation technique using group discovery and parametric equations of the hypersphere. Nevertheless, these methods are unable to make use of the inherent features of the samples, resulting in a limitation of the training models.
In recent years, with the rapid development of the new generation of artificial intelligence and big data, the use of a generative adversarial network (GAN) based on a deep neural network (DNN) has provided opportunities to create new approaches to solve the data problem. It has also made the application of deep learning possible in the case of a small sample size. A GAN is a powerful type of generative model [38] that was introduced in 2014 by Goodfellow et al. [39]; it can be utilized to generate synthetic samples with the same distribution as the real data in order to solve the insufficiency problem of annotated data [40]. A GAN consists of two deep architecture functions for the generator and the discriminator, which can simultaneously learn from the trained data in an adversarial fashion [41]. In the learning process, the generator captures the potential distribution of the real data and generates synthetic samples, while the discriminator discriminates between the real samples and the synthetic samples as accurately as possible.
Recent work has shown that a GAN can successfully be applied to image generation, language processing, and supervised learning with insufficient training data. From the perspective of image generation, Santana and Hotz [42] proposed an approach to generate images with the same distribution as real driving scenarios. Gou et al. [43] utilized a GAN to learn from both real and synthetic images in order to improve the accuracy of eye detection. From the perspective of language processing, Li et al. [44] utilized a GAN to capture the relevance of dialog and to generate corresponding synthetic text, while Pascual et al. [45] proposed a speechenhancement framework based on a GAN. These studies demonstrate that the synthetic samples generated by a GAN conform to the distribution of the original samples. Moreover, the success of GANs in various fields indicates that this generative model is independent of precise domain knowledge, which is propitious for the application of this approach in other fields. From the perspective of supervised learning with insufficient training data, most of the existing studies deal with the problem of class imbalance, and a GAN is often used as an oversampling method. Fiore et al. [46] utilized a GAN to generate synthetic illicit transaction records, and merged these synthetic records into an augmented training set to improve the effectiveness of credit card fraud detection. Douzas and Bacao [47] utilized a GAN to generate synthetic samples for the minority class of various imbalanced datasets; the results showed that the GAN performs better than the other oversampling methods. These studies demonstrate that data augmentation with a GAN is more effective than traditional oversampling methods in improving the quality of data. Furthermore, most standard augmentation methods have been integrated into Augmentor, a well-accepted data augmentation tool with a high-level application programming interface (API) [48]. Despite the remarkable success of GANs in balancing datasets, their application in multi-classification with a small sample size has, surprisingly, not yet been studied, to the best of our knowledge. Enlargement of the data scale by means of data augmentation makes it possible to improve the performance of supervised machine-learning based on DNNs in various fields. To sum up, a GAN provides an opportunity to solve the problem posed by a small sample size and thus improve multi-classification.
To solve the multi-classification problems posed by a small sample size, we propose an approach that combines a GAN with a DNN. In this research, the original samples were first divided into a training set and a test set. The GAN method was utilized as data augmentation in order to generate synthetic sample data to enlarge the training set scale of cancer staging in biology, and to satisfy the conditions of DNN model training. Next, the DNN method was trained with the synthetic samples and tested using the test set. Finally, the effectiveness of the approach for multiclassification with a small sample size was validated by comparing several indicators with a combination of the classical supervised machine-learning approaches—DNN, SMOTE, and GAN. The approach proposed in this paper is an attempt to transform the classical statistical machine-learning classification method based on original samples into a deep-learning classification method based on data augmentation. Furthermore, this research is conducive to exploring the potential of the application range and reliability of the new generation of artificial intelligence, as represented by deep learning. This is the first attempt to utilize an approach combining GAN with DNN to improve the effectiveness of multi-classification for cancer staging.
《2. Methodology》
2. Methodology
《2.1. Workflow of the study》
2.1. Workflow of the study
To solve the supervised learning problem posed by a small sample size and extend the scope of application of deep learning, this paper proposes an approach combining a GAN with a DNN classifier for multi-classification. This approach can be outlined as follows (Fig. 1):
《Fig. 1》
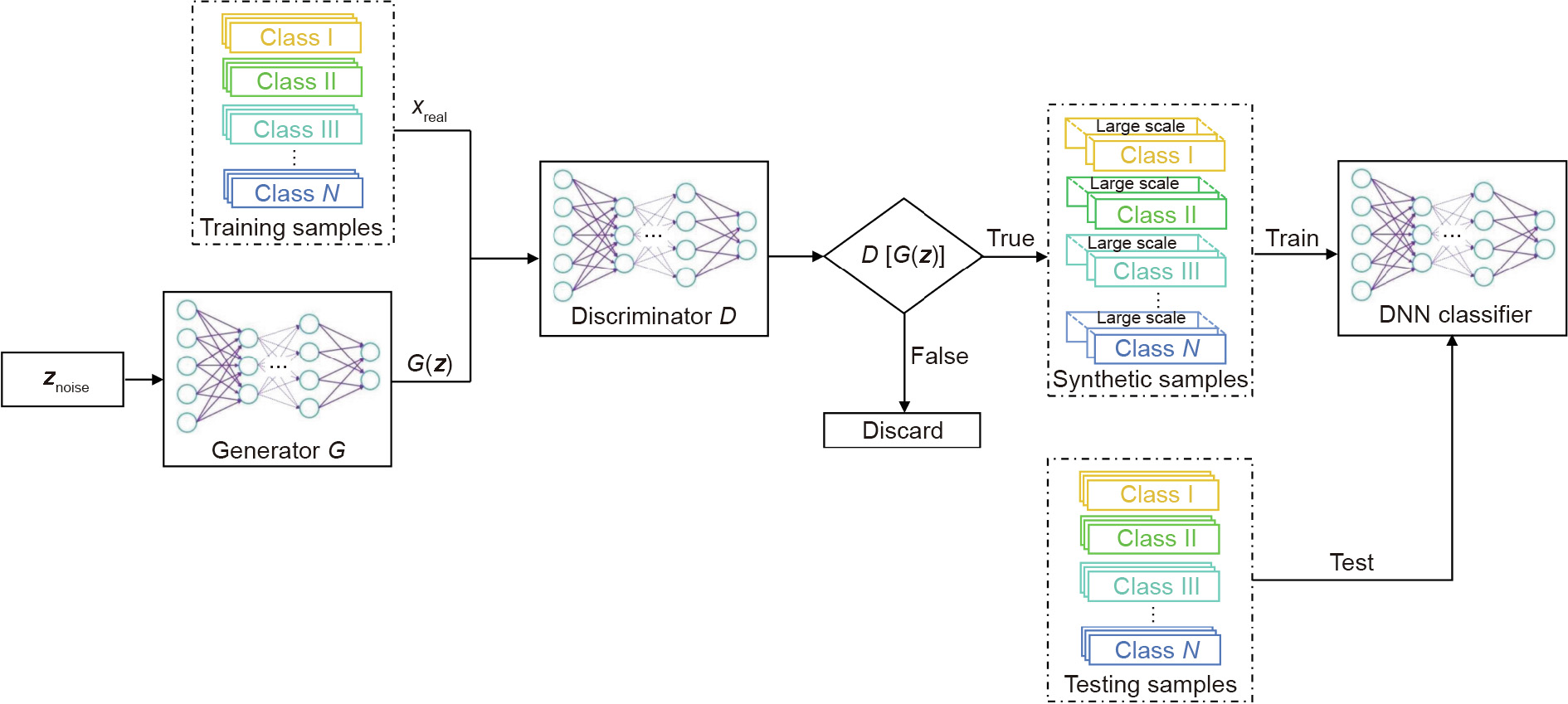
Fig. 1. Workflow of the small sample size multi-classification approach.
(1) Divide the original samples into a training set and a test set. Use the training set to train the GAN and tune its hyperparameters.
(2) Use the trained generator of the GAN to generate synthetic samples, and use the discriminator to filter these samples.
(3) Use the synthetic samples to train the DNN classifier, and use the test set to test the DNN classifier.
《2.2. Generative adversarial network》
2.2. Generative adversarial network
The Wasserstein generative adversarial network (WGAN) [49] was used to generate the synthetic samples in this study, as the training process of the original GAN was a minimax game, and the optimization goal was to reach the Nash equilibrium [40], which posed the vanishing gradient problem [50]. Compared with the original GAN, WGAN uses the Wasserstein distance instead of the Jensen–Shannon (JS) divergence to evaluate the distribution distance between the real samples and the generated samples [51]. Using the Wasserstein distance, the training process of WGAN was more stable and faster than that of the original GAN [52].
In the proposed approach, the process of generating synthetic samples using WGAN consisted of two stages. First, the generator began to generate the original synthetic samples when the loss functions of the generator and the discriminator converged after being trained tens of thousands of times. Second, according to the GAN’s concept of the adversary [53], the generator attempted to generate synthetic samples that could fool the discriminator, while the discriminator attempted to discriminate between the real samples and the synthetic samples. In other words, when a synthetic sample was identified as real by the discriminator, that synthetic sample fooled the discriminator. The original synthetic samples that fooled the discriminator were taken as the final synthetic samples.
《2.3. Deep neural network》
2.3. Deep neural network
This study used a DNN, which is a deep architecture classifier based on deep learning, as a classifier. A DNN classifier can utilize several models of computation to learn representations of data with multiple layers of abstraction; the models are composed of multiple processing layers. The DNN classifier was trained with a large number of synthetic samples generated by WGAN in order to avoid overfitting. In the proposed approach, the DNN classifier was tested with the test set, which could inspect the generalization performance of the classifier. To test the performance of the DNN classifier, we used three multi-classification metrics based on a confusion matrix (Fig. 2): accuracy, the F-measure, and the G-mean. Accuracy denoted the proportion of predictions that were correct, the F-measure represented the harmonic mean of precision and recall [54], and the G-mean indicated the geometric mean of recall [55]. Accuracy, F-measure, and G-mean are defined in Eqs. (1–3).
《Fig. 2》

Fig. 2. Diagram of the multi-classification confusion matrix.

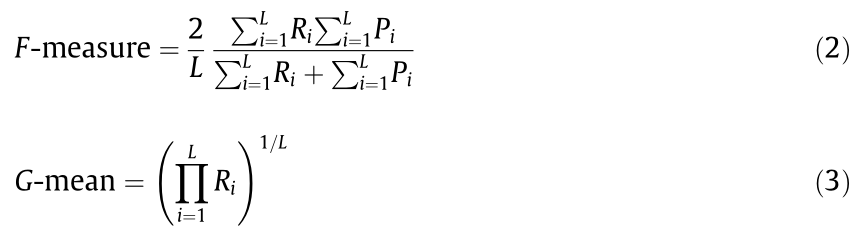
In these equations, L represents the class number; nii and nij denote the number of class Ci samples that are correctly predicted as class Ci and incorrectly predicted as class Cj, respectively; and Ri and Pi indicate the recall and the precision of class Ci, respectively, which are defined as follows:

《3. Empirical analysis and discussion》
3. Empirical analysis and discussion
Due to the need to protect patient privacy, pathological data are expensive to acquire and the corresponding data annotation is difficult. As a result, pathological studies often encounter the problem of a small sample size. Therefore, the application of data augmentation in the field of pathology is typical. Hepatocellular carcinoma (HCC) is a common malignancy with five-year relative survival rates of less than 15% [56,57]. The five-year relative survival rates of HCC can be improved effectively by early treatment. Nevertheless, research on the identification of early-stage HCC is limited by the lack of samples with staging information. Glycosylation is one of the most widespread post-translational modifications, and plays crucial roles in various biological processes [58–60]. Numerous cancer-related processes, including oncogenic transformation [59,61], tumor progression [62], and antitumor immunity [63], are associated with the aberrant glycosylation of proteins. Furthermore, various tumor markers are glycoproteins with alterations in serum glycomics [64–67]. Therefore, glycosylation data are an effective means for the prediction of cancer staging. In this section, we discuss the use of WGAN combined with a DNN to identify the stage of HCC, which is significant for the diagnosis and treatment of HCC.
《3.1. Data collection》
3.1. Data collection
In this study, serum samples donated by Tongji Hospital (Tongji Medical College, Huazhong University of Science and Technology) were used as the experimental data. N-glycans, which are features of data augmentation, were first released from the human serum samples by means of PNGase F prior to a solid-phase permethylation protocol [68]. Next, the mass spectrometry (MS) peak distribution and its relative intensities of permethylated N-glycans (Fig. 3) were detected using 4800 Plus MALDI (AB SCIEX, Concord, Canada). The obtained MS data were processed further using Data Explorer 4.5, and .txt files listing the m/z values and MS intensities were generated (from ASCII Spectrum). The stages of cancer were divided according to the tumor node metastasis (TNM). Through the abovementioned biological processes, 60 HCC cases (TNM stage I, 21 cases; TNM stage II, 24 cases; and TNM stage III, 15 cases) were obtained, each containing 42 features, and 18 healthy samples served as the control group. Each sample was represented as a 42 dimensional feature vector, according to its peak distribution order and relative intensity, as shown in Fig. 3. The HCC cases were divided into a training set (60%) and a test set (40%), as shown in Table 1.
《Fig. 3》

Fig. 3. N-glycan spectra of the HCC sample using MALDI mass spectrometry.
《Table 1》
Table 1 Overview of the dataset used in this paper.

《3.2. Result analysis》
3.2. Result analysis
According to the proposed approach, we first used TNM stage I, TNM stage II, TNM stage III, and the control group’s training set to train WGAN, and then used the trained WGAN to generate the corresponding synthetic samples. The hyperparameters for the GAN were determined through a series of experiments. The generator had one hidden layer containing 32 rectified linear units (ReLUs), and 42 sigmoid units were used as the output layer. The dimension of the noise vector z was set to 15. The discriminator also had one hidden layer, which contained 64 ReLUs; one unit without the activation function was used as the output layer. The hyperparameters of WGAN for each class’ training sample were the same. The WGAN’s development environment was TensorFlow1.1 and it was trained through the graphics processing unit (GPU). The WGAN training process contained 300 000 iterations. In each iteration of the WGAN training, the discriminator first iterated 100 times, and then the generator iterated one time.
After the generation of the synthetic samples of the HCC cases, these samples were used to train the DNN classifier. The DNN classifier, which was a multi-layer perceptron (MLP), was then validated with the HCC test set. After a series of experiments on the DNN, the hyperparameters were determined. The dimension of the classifier’s input was 42, which was equal to the number of features in the HCC samples. The classifier had three hidden layers, each containing 32 ReLUs; the softmax function was used as the output layer and cross-entropy was used as the loss function. TensorFlow1.1 and GPU were used to train the DNN classifier as well, and the number of iterations was set to 3000.
To evaluate the effect of the synthetic training sample size on the performance of the DNN classifier, we used a different number of synthetic samples to train the DNN classifier, and then used real samples to test for the three indicators of accuracy, F-measure, and G-mean. From 20 synthetic training samples of each class, more than 20 synthetic samples were generated each time to train the DNN classifier. In the case of more than 100 synthetic training samples, more than 100 synthetic samples were generated each time to train the DNN classifier. The changes in the accuracy, F-measure, and G-mean are shown in Fig. 4.
《Fig. 4》
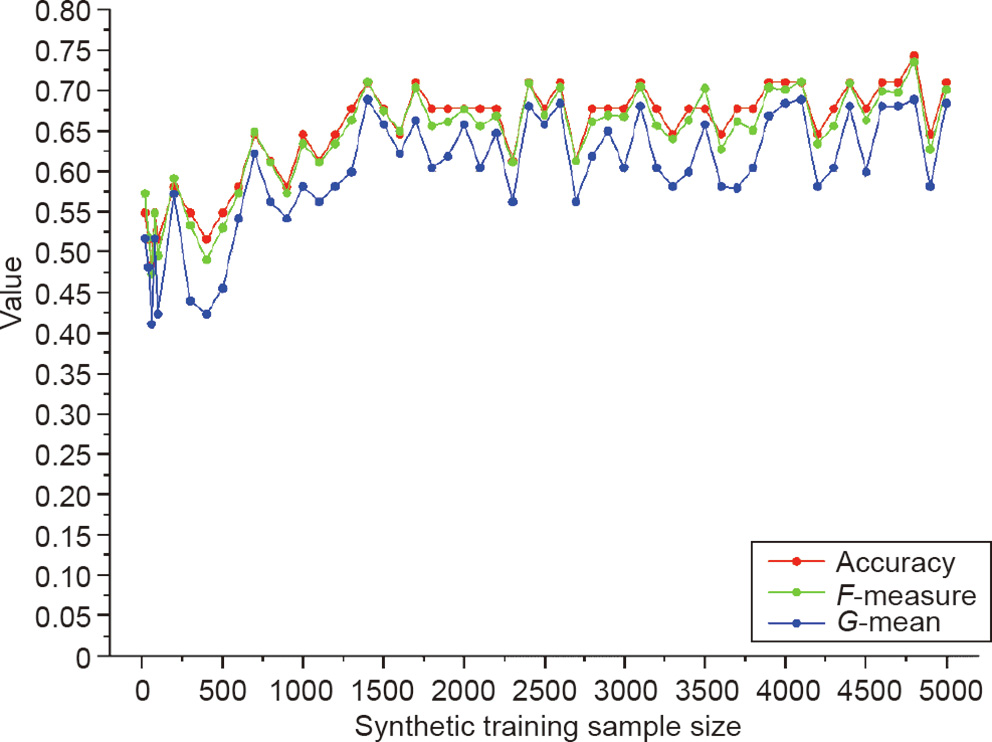
Fig. 4. DNN classifier performance with increase in synthetic training sample size.
With an increase in the synthetic training sample size, the accuracy gradually increased. With 100 synthetic training samples, the accuracy reached 51.61%. When the synthetic training sample size was 1000, the accuracy was greater than 0.6 (64.52%), and when the synthetic training sample size reached 2000, the accuracy was 67.74%. However, after this, increasing the synthetic training sample size did not lead to an improvement in accuracy, and the accuracy continued to fluctuate around 67%. When the synthetic training sample size reached 4000, the accuracy remained stable at approximately 70%. In addition, when the synthetic training sample size was increased, the tendency of the F-measure was basically consistent with that of the accuracy, which showed that the prediction accuracy of each class’ real samples was consistent with the overall situation. Furthermore, each stage of HCC could be predicted effectively, and the misdiagnosis rate was very low. With an increase in the number of synthetic samples, the G-mean remained slightly lower than the accuracy but was consistent overall. This finding indicated that the misdiagnosis rate remained low. According to the accuracy, F-measure, and G-mean values, when the synthetic training sample size was 4000, an effective DNN classifier for the identification of the HCC stage in a small sample size could be obtained.
In particular, when the number of synthetic samples generated by WGAN was 4000, the test accuracy of the real samples was 70.97% (of the 31 original samples, 22 were predicted correctly), the F-measure was 70.07%, and the G-mean was 68.39%. Table 2 presents the DNN prediction results for all of the stages. All of the healthy samples in the control group were correctly predicted. Of the eight TNM stage I test samples, five samples were correctly predicted, two were predicted to be TNM stage II, and one was predicted to be stage III. Of the ten TNM stage II test samples, seven samples were predicted correctly; two were predicted to be healthy, indicating a risk of misdiagnosis; and one was predicted to be TNM stage III. Of the six TNM stage III real cases, only three were correctly predicted; the rest were predicted to be TNM stage I, for an accuracy of only 50%. This decreased the overall DNN model performance. Therefore, the number of original TNM stage III samples should be increased in a future study, in order to improve the specificity of the DNN model for TNM stage III. TNM stages I and II have similar clinical features and can be classified into a single category called ‘‘early-stage cancer.” Thus, according to the results of the early-stage HCC (TNM stages I and II) identification, the accuracy of the proposed method reached 77.78%. This level of accuracy has great significance for the early identification and treatment of HCC, because a current study [69] has found that early treatment significantly increases the survival rate of patients with HCC. A recent study by Holzinger et al. [70] indicates that digital pathology will dramatically change medical workflows if pathologists are augmented by machine-learning methods. Thus, our integrated approach with accurate prediction holds potential to promote further research into the pathogenesis of HCC.
《Table 2 》
Table 2 Confusion matrix of HCC stage identification

《3.3. Evaluation of WGAN combined with a DNN》
3.3. Evaluation of WGAN combined with a DNN
To test the effectiveness of the proposed approach in classifying the TNM stage of HCC with a limited number of samples, a classical statistical machine-learning classifier and a data oversampling method were used for a comparison. A random forest (RF) is an ensemble learning method with higher accuracy and a better generalization capability than other machine-learning models [71], while a naïve Bayes (NB) classifier has a simple principle and a stable classification performance [72]. These two algorithms were chosen as the representatives of classical statistical machinelearning classifiers. The deep-learning method cannot be applied effectively if there is a limited number of real samples of HCC due to the lack of sufficient data on HCC; however, the classical statistical machine-learning method has a relatively low demand for datasets, so this method can be used. In the classical statistical machine-learning experiments with original samples, the classifiers were trained using the training set and then tested with the test set. In the oversampling experiments, SMOTE was adapted to generate the oversampling samples by using the oversampling HCC training set of all of the stages. The RF, NB, and DNN classifiers were then trained with the oversampling samples. Next, the trained classifiers were validated with the HCC test set. In the proposed framework based on WGAN, a large number of synthetic samples generated by WGAN were used to train the RF, NB, and DNN classifiers. The classifiers were then validated using real samples.
As shown in Table 3, the RF and NB models trained with the training set and tested with the test set resulted in the relatively low accuracies of 54.84% and 32.26%, F-measure values of 56.73% and 12.20%, and G-mean values of 45.50% and 0, respectively. The NB indexes were considerably lower than those of the RF, which indicated that the NB was more sensitive than the RF in the case of the considered dataset. These results indicate that the misdiagnosis rate was high and that a number of HCC cases were not discriminated. Thus, given a limited training set, classical machine-learning models cannot be effectively trained.
《Table 3》
Table 3 Performance of different classification strategies.
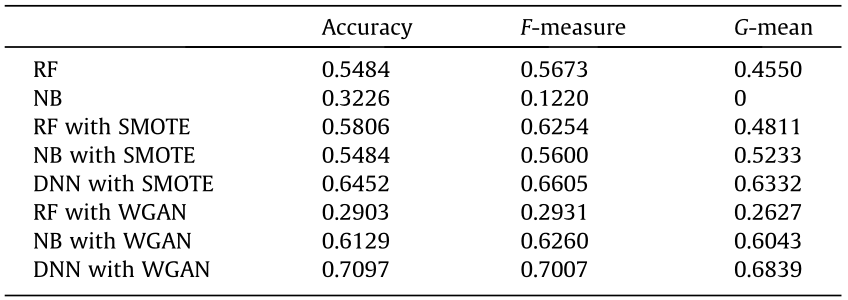
In comparison, the RF and NB models trained with 4000 oversampling samples generated by SMOTE performed better in terms of all the indexes. These results indicate that SMOTE improved the classical machine-learning model performance and reduced the misdiagnosis rate to a certain extent. The DNN model trained with 4000 oversampling samples generated by SMOTE showed significant improvement in all of the indexes: The accuracy increased to 64.52%, the F-measure increased to 66.05%, and the G-mean increased to 63.32%. These results show that the deep-learning model resulted in better performance than the classical machinelearning model.
The RF and NB models trained with 4000 synthetic samples generated by WGAN exhibited different performance changes. The RF model had worse indexes than the model trained with the oversampling samples, while the NB model’s indexes increased considerably. These results imply that with the synthetic samples generated by WGAN, the classical machine-learning models did not provide good results. In the proposed framework, the deeplearning model DNN with synthetic samples from WGAN performed best among all the considered classifiers. Compared with the oversampling samples generated by SMOTE, this method further increased the accuracy from 64.52% to 70.97%, the Fmeasure value from 66.05% to 70.07%, and the G-mean value from 63.32% to 68.39%, which demonstrates that WGAN with a DNN effectively solved the HCC stage recognition problem. Above all, these findings indicate that the deep-learning method can successfully be applied to a multi-classification problem with a limited number of samples.
《3.4. Discussion》
3.4. Discussion
According to the experimental results given above, WGAN combined with a DNN can be applied to the identification of HCC stages, and results in excellent performance compared with traditional methods. This finding is of significance to cancer research. Research into most cancers is hindered by the small sample size problem; samples with accurate staging information are particularly rare. This problem has led to slow progress in the early diagnosis and treatment of cancers; furthermore, it affects the exploration of the pathogenesis of cancer. Our data augmentation method based on WGAN may well provide a solution for these issues. The proposed approach was designed not only to solve the problem of HCC staging, but also to solve the small sample size problem using supervised learning. Therefore, cancer-staging data based on serum samples were selected, as such data result in unsatisfactory performance with traditional statistical machine learning due to the small sample size problem. The proposed framework does not rely on a precise domain knowledge of cancer, due to the characteristics of deep learning. Therefore, the proposed method has a low barrier to successful application in other biological research domains, and may even be applied in more farranging fields once the performance has been optimized. Furthermore, the combination of WGAN with a DNN holds enormous potential for bringing domains that lack samples into the intelligence era [26,73–75].
《4. Conclusion》
4. Conclusion
In this paper, a WGAN approach combined with a DNN was presented for cancer stage identification on the basis of a small sample size. Using the indicators of precision, F-measure, and G-mean, we demonstrated that in comparison with classical machine-learning methods and oversampling methods, the proposed approach substantially improved the classification effectiveness with an increase in the number of synthetic samples. Early recognition of cancer is particularly significant for the diagnosis and treatment of cancer. Because the feature selection did not rely on precise domain knowledge from experts, the proposed supervised deeplearning approach based on a small sample size holds potential to provide effective solutions to other problems involving a small sample size in various fields. Thus, this approach could easily be used to promote intelligent development in other fields. This new approach strongly promotes the new stage of artificial intelligence. In future, the proposed approach will be applied to more datasets from various fields in order to continuously improve our research [76,78].
《Acknowledgements》
Acknowledgements
This work was supported by the National Natural Science Foundation of China (91646102, L1724034, L16240452, L1524015, and 20905027), the MOE (Ministry of Education in China) Project of Humanities and Social Sciences (16JDGC011), the Chinese Academy of Engineering’s China Knowledge Center for Engineering Sciences and Technology Project (CKCEST-2018-1-13), the UK– China Industry Academia Partnership Programme (UK-CIAPP \260), Volvo-Supported Green Economy and Sustainable Development at Tsinghua University (20153000181), and the Tsinghua Initiative Research Project (2016THZW).
《Compliance with ethics guidelines》
Compliance with ethics guidelines
Yufei Liu, Yuan Zhou, Xin Liu, Fang Dong, Chang Wang, and Zihong Wang declare that they have no conflict of interest or financial conflicts to disclose.











 京公网安备 11010502051620号
京公网安备 11010502051620号




