

《1. Introduction》
1. Introduction
Recent decades have witnessed various developments in videography technology (e.g., from analog to digital, from single lens to multi-camera, and from megapixel-level to gigapixellevel). Even though the imaging resolution has significantly improved, the basic sensing and understanding pipeline remains unchanged; that is, the conventional videography system strictly follows a feedforward pathway by naively accumulating pixellevel information to increase the image resolution and progressively abstract global content. Therefore, the image quality of such videography methods is highly limited by the physical sampling resolution of the photography. Stitching cameras [1–3] and scanning strategies [4–8] can significantly boost the count of physically sampled pixels, especially for gigapixel videography. However, most such videography strategies simply fuse spatio–temporal photographic outputs, rather than taking advantage of the inherent instance-level representation with spatio–temporal consistency. This leads to high hardware complexity and tremendous data redundancy for the spatio-temporally dense sampling.
In contrast, a high-level human visual system uses past observations in service of the present or future, with a dual-pathway mechanism [9]. Specifically, it extracts and consolidates a memory engram, defined as the representation of a stable and semantic memory in the brain [9–12], and subsequently reactivates the associated engram through a feedback pathway for memory retrieval. In particular, upon engram formation [9–12], local detailed information is initially transmitted to the hippocampus. Then, recurrent associations between the hippocampal–cortical networks gradually strengthen and consolidate the cortical engram, and the global semantic information is extracted by the prefrontal cortex (PFC) [9,13]. The PFC then discriminates whether the incoming visual information corresponds to a previously stored cortical engram, and determines the subsequent procedure of consolidation or inhibition. Taken together, these dynamic and bidirectional information transfers realize efficient, robust, and adaptive visual perception and understanding.
Inspired by this, we propose a dual-pathway imaging mechanism denoted ‘‘engram-driven videography.” It starts by abstracting a holistic representation of a scene, which is bidirectionally associated with the local details, as driven by an instance-level engram. Analogically, the visual information is first captured by virtual eyes and pre-processed by the PFC module. The PFC module determines which information is already stored in the videographic memory. We call this the excitation–inhibition state, where the pixel-level details are dynamically consolidated or inhibited to strengthen the instance-level engram. Such a dynamic system mimics the human memory mechanism and can be programmed to maximize uncertainty, similar to the principle of entropy towards the equilibrium of the system [14,15]. Intuitively, to effectively maintain a dynamic videographic memory with a limited size, it is generally encouraged to increase the uncertainty of the memorized content by maximizing the entropy. Subsequently, in the association state, a constant-level engram is retrieved to synthesize the spatio-temporally consistent content for high-performance videography of future scenes. The schematic of engram-driven videography is shown in Fig. 1.
《Fig. 1》

Fig. 1. Schematic of engram-driven videography. It consists of an excitation–inhibition state, where the pixel-level details get dynamically consolidated or inhibited to strengthen the instance-level engram, and an association state, where the spatially and temporally consistent content get synthesized as driven by the engram for highperformance imaging of future scenes.
Experiments on both computer synthetic and real-world images/videos demonstrate that our engram-driven videography can significantly outperform traditional videographic approaches. It can generate high-quality instance-level results with only 5% high-resolution observations and 95% low-resolution observations. In addition, with the help of the associated engram, we can recover the high-resolution details of small instances. We believe that the engram-driven videography will open new directions for image/ video capturing, understanding, and storage, leading to nextgeneration visual sensation systems.
《2. Related work》
2. Related work
A large number of studies have considered human visual engrams, super-resolution algorithms, and high-resolution imaging systems. These are reviewed in the following subsections.
《2.1. Human visual engram》
2.1. Human visual engram
The human brain perceives and processes visual information at two levels [16]. At a low level, the cerebral visual cortex processes local visual features such as color, contrast, direction, and motion through feedforward hierarchical structure information. In the high-level visual processing, the engram is an indispensable component of the conscious experience. Object recognition, in particular, relies on the observer’s previous engram [16].
The term engram was coined by Semon more than 100 years ago, and refers to the representation of a more stable memory [9–12]. The prevailing view is that an engram in the brain may change with time [9–12]. Specifically, visual information is initially encoded in parallel in hippocampal–cortical engrams, and the recurrent associations between the hippocampal–cortical networks gradually strengthen the cortical engram for memory consolidation. Finally, the PFC abstracts the global semantic information from the pre-existing cortical engram, and then discriminates whether the incoming visual information corresponds to a previously stored cortical engram for the subsequent decision procedure of consolidation or inhibition [13]. In information theory, Shannon entropy measures the amount of information held in data; the proposed memory entropy is named based on reference to this idea. In particular, in our system, the memory entropy encodes the uncertainty of the instance-level visual information in the engram. Memory entropy can be regarded as an extension of Shannon entropy in the field of imaging and memory, as we do not calculate the entropy directly. Instead, we use the distance between the feature vectors to represent the relative entropy change.
《2.2. Super-resolution algorithms》
2.2. Super-resolution algorithms
Image/video super resolution approaches aim to recover highresolution details from low-resolution inputs. The most common super-resolution method is single image super-resolution (SISR). Early works only used low-level priors such as sparsity [17–20] or exemplar patches [21,22], whereas the deep neural network has shown great performance. Kim et al. [23] first proposed a threelayer neural network for single-image super-resolution, and further improved it by using a 20-layer deep neural network [23], recursive structures [24,25], and a dense structure [26]. However, the mean squared error losses from these methods usually led to over-smooth results with no details. Thus, perceptual losses were introduced into image/video super-resolution. Johnson et al. [27] first proposed perceptual losses for real-time style transfer and super-resolution by combining conventional pixel-wise losses and Visual Geometry Group (VGG)-like feature spaces losses. Ledig et al. [28] presented super resolution generative adversarial network (SRGAN), a generative adversarial network for photorealistic 4× natural images at super-resolution.
The performance of SISR is limited, especially under a large resolution gap (> 8×), because the high-frequency details are lost during down-sampling and are unrecoverable under general priors. Therefore, reference-based super-resolution (RefSR) has been proposed. Boominathan et al. [29] adopted a digital single-lens reflex (DSLR) camera image as a reference, and presented a patch-matching-based method for super-resolved low-resolution light field images. Wu et al. [30] improved the algorithm by proposing a better patch-matching algorithm combined with dictionary-learning-based reconstruction. Wang et al. [31] iterated the patch-matching step to enrich the patch database and improve the reconstruction quality. Zhang et al. [32] presented the superresolution neural texture transfer (SRNTT) to conduct multilevel patch matching in the neural space. The methods mentioned above only used the information of local patches. This often led to poor super-resolution results under real data from hybrid camera systems, owing to the easily failed patch matching. Therefore, Tan et al. [33] and Zheng et al. [34] proposed CrossNet and CrossNet++, an end-to-end neural network containing a novel two-stage cross-scale warping module to build the correspondence between the input and reference. Compared with patch-based approaches, the warping approach can find more reliable correspondences for the entire image when the input and reference images are close.
《2.3. High-resolution imaging systems》
2.3. High-resolution imaging systems
In addition to super-resolution algorithms, researchers have developed powerful imaging systems to increase the resolution. Kopf et al. [35] designed a motor-controlled camera mount for static gigapixel image capture. Brady et al. [3] built the world’s first gigapixel camera ‘‘AWARE2” with a spherical objective lens and 98 micro-optics; it produced a 0.96 gigapixel image in a single shot. The objective lenses were carefully designed and manufactured to minimize aberrations [36,37]. In contrast, Cossairt et al. [38] used a simple optical design and post-capture deconvolution stage to increase the resolution. Owing to the large computational complexity caused by the extremely high resolution, AWARE2 can only capture three frames per minute. A similar idea has also been employed in microscope design for gigapixel-level whole-mouse brain imaging [39]. To reduce the computational complexity, Yuan et al. [40] proposed multiscale gigapixel videography, which dramatically reduced the bandwidth requirement and was capable of handling an 8× resolution gap. Zhang et al. [1] extended this idea to three dimensional (3D) videography for virtual reality (VR) applications. However, even with such a strategy, a large number of cameras is still required. The spatial redundancy is reduced, whereas the temporal redundancy still exists.
Our new engram imaging system considers both spatial and temporal redundancies. The history inputs are encoded and buffered in ‘‘memory” as references, and are used to super-resolve further inputs.
《3. Method》
3. Method
In this paper, we propose engram-driven videography, including a feedforward pathway for consolidating the interesting information of a scene, and a feedback pathway for associating the engram for future content inference and synthesis. Our main contribution lies in a high-level neuromorphic imaging system consisting of the functional modules for an engram neural circle [9,10,12]. As shown in Figs. 2 and 3, our imaging system consists of three main modules: an instance-level observation module, instance-level engram module, and engram processing unit (EPU), corresponding to the hippocampus, cortical memory, and PFC in the human brain, respectively. The former two are responsible for low-level and high-level information representation, whereas the latter is responsible for information abstraction and control.
In the feedforward pathway (Fig. 2), an entropy equilibrium policy is proposed for consolidating the valid information from the low-level observations to the engram and inhibiting meaningless information. In the feedback path (Fig. 3), the pre-generated engram is associated with new observations and used to synthesize high-quality future content.
《Fig. 2》

Fig. 2. Feedforward pathway for engram generation. The large-scale scene is captured by virtual eyes, and is pre-processed and saved in instance-level observations first. After that, the EPU abstracts the low-level information and consolidates it to an instance-level engram (excitation state) or inhibits it (inhibition state), based on the entropy equilibrium model.
《Fig. 3》
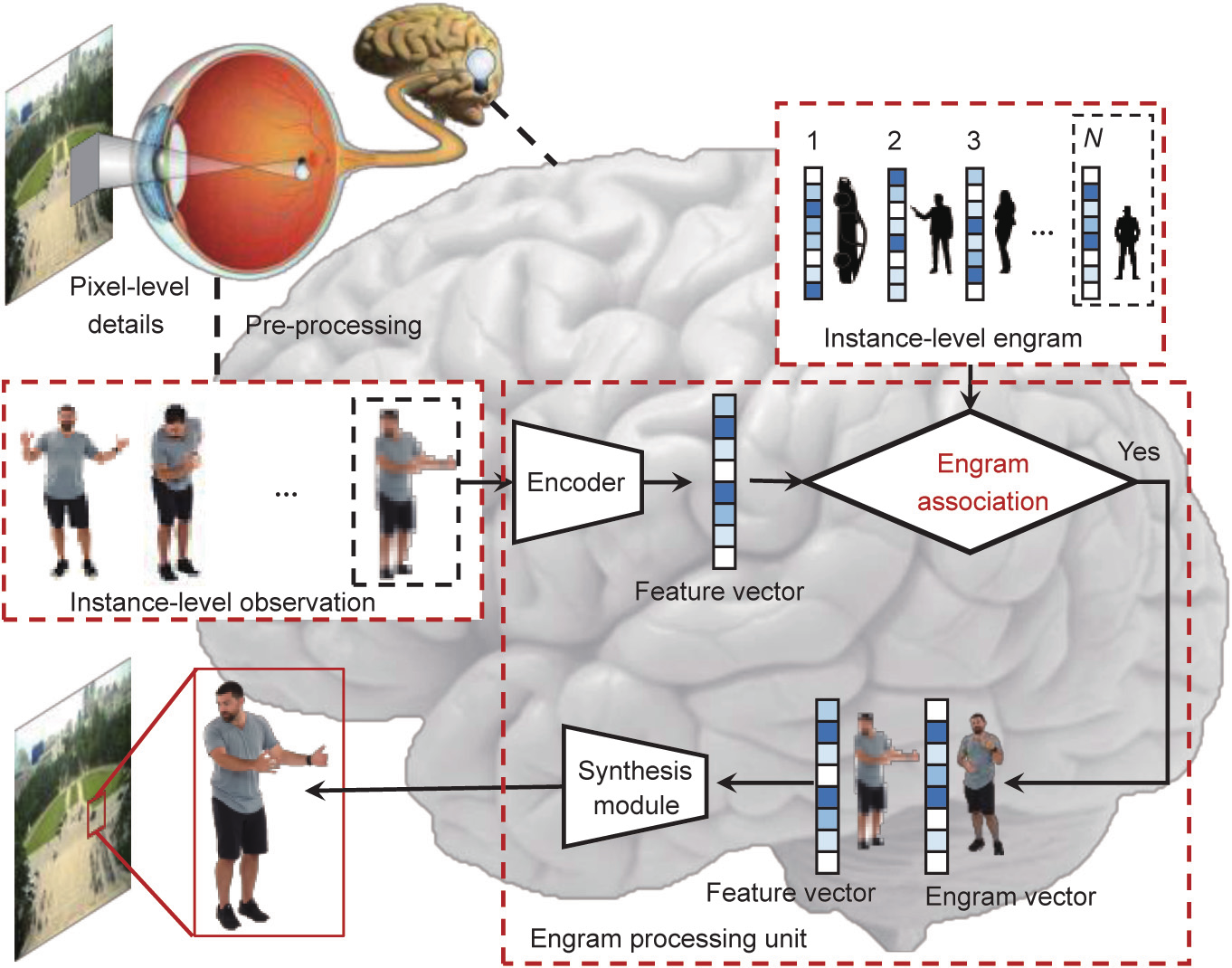
Fig. 3. Feedback pathway for engram-driven videography synthesis. An engram association module is used to match the feature vector between the observation and engram. These two vectors are then concatenated, and are input to the synthesis module.
《3.1. Videographic memory entropy》
3.1. Videographic memory entropy
Similar to the Universe, our brains might be programmed to maximize disorder (similar to the principle of entropy), and our memory mechanism could simply be a side effect. Accordingly, we used entropy to quantify the functioning of the photographic memory in the human brain (i.e., to characterize the degree of the underlying uncertainty of the instance-level engram). Entropy is a term used to describe the progression of a system from order to disorder (i.e., random variables with small entropies have a high level of predictability, and hence a low level of uncertainty) [41].
The visual observations abstracted into the engram are defined as a continuous-valued random vector 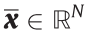 in an N-dimensional feature space with a probability density function
in an N-dimensional feature space with a probability density function  . The photographic memory entropy
. The photographic memory entropy 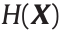 is defined as follows, and is used to measure the degree of uncertainty that the information content
is defined as follows, and is used to measure the degree of uncertainty that the information content 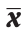 comprises. Storing redundant observations in the engram should be avoided, because the visual system is highly robust to predicting one sample from a similar one.
comprises. Storing redundant observations in the engram should be avoided, because the visual system is highly robust to predicting one sample from a similar one.

where E is the expected value operator.
The next question is how to measure the prediction confidence for the neighboring regions in the feature space. Intuitively, when two samples 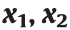 get closer in the feature space, it is more reasonable to represent one sample using the other. Therefore, we use a multivariate Gaussian
get closer in the feature space, it is more reasonable to represent one sample using the other. Therefore, we use a multivariate Gaussian  with a mean vector
with a mean vector 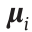 and covariance matrix
and covariance matrix 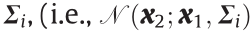 to represent the prediction confidence of
to represent the prediction confidence of  using
using  . For the case where the memory contains multiple visual observations,
. For the case where the memory contains multiple visual observations, 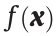 can be defined as follows:
can be defined as follows:

where 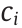 is non-negative weighting coefficients, with
is non-negative weighting coefficients, with  .
.
Similar to the human working memory, which maintains a limited amount of information, the proposed photographic memory also has a limited capacity, so that it can be quickly accessed to serve the needs of ongoing videography tasks. Accordingly, we propose an engram update mechanism for stimulating the progression of the system from order to disorder. Specifically, it is programmed to maximize the information content; simultaneously, the entropy of our videography system can only increase.
Here we define two states, the memory state  and instantaneous state
and instantaneous state 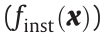 , as follows:
, as follows:
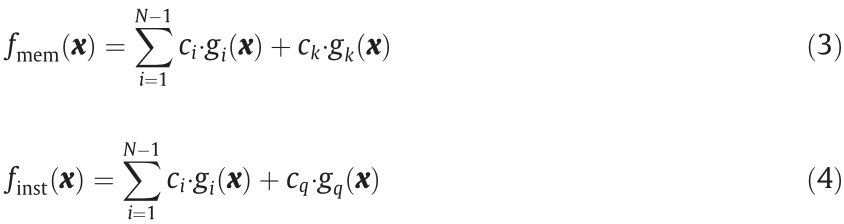
where the kth sample is the most redundant in the memory, and the qth sample represents an incoming query sample.
Intuitively, after the query sample replaces the most useless one in the size-limited memory, and if the system entropy increases (i.e., Hmem(X) < Hinst(X) , where Hmem(X) is the videographic memory entropy and Hinst(X) is the videographic instantaneous entropy), the engram update mechanism tends to encourage such an update. In contrast, if the newly observed information decreases the system entropy (i.e., Hmem(X) ≥Hinst(X) ), such a process will be inhibited.
The key idea for the engram update mechanism is to retain the information that increases the entropy of the photographic memory system. For the implementation, the critical part is in evaluating the entropy to guide the engram update strategy. Even though the entropy of an N-dimensional Gaussian has a simple closedform expression, the entropy generally cannot be calculated in the closed form for Gaussian mixtures, owing to the logarithm of the sum of exponential functions. Following the approximation method [52], the bounds of the mixture entropy are as follows:

here,  and
and  are defined on Chernoff α-divergence and Kullback–Leibler (KL)-divergence, respectively, which decrease together with the distance
are defined on Chernoff α-divergence and Kullback–Leibler (KL)-divergence, respectively, which decrease together with the distance 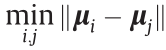 . We can conclude that it is highly likely that the entropy H(X) is proportional to its bounds (i.e., and ).
. We can conclude that it is highly likely that the entropy H(X) is proportional to its bounds (i.e., and ).
Therefore, to maintain the equilibrium of the system, we evaluate the Hinst(X) for each observation, and compare it with Hmem(X) . Eventually, the pixel-level details are dynamically consolidated or inhibited, so as to strengthen the instance-level engram in the excitation–inhibition state.
《3.2. Feedforward pathway》
3.2. Feedforward pathway
Fig. 2 illustrates the feedforward pathway for the engram generation. The pixel-level details are first captured by a virtual eye (camera) from a large-scale scene, and are pre-processed and saved as instance-level observations (hippocampus in the human brain), including foreground dynamic objects and interesting backgrounds. Here, faster region-based convolutional neural network (R-CNN) [42] and mask R-CNN [43] are used for bounding box detection and segmentation, respectively. Subsequently, the high-level semantic information is extracted from these low-level observations using the encoder. We compute the feature vector using five convolutional layers, each with 64 filters of size 5 × 5. The strides are set to one for the first two layers and two for the following three layers, leading to coarse-to-fine multiscale feature maps. The feature vector is then computed by concatenating the feature maps. Subsequently, an entropy equilibrium policy is used to decide whether to consolidate the information to the engram or to inhibit it.
(1) Virtual eye. Although the human eye has approximately 0.576 gigapixels, it only has very high resolution in the center of the field of view (FoV) [44,45], and uses saccadic movements to generate an all-clear wide-FoV image in the brain, leading to highly efficient information capturing and integration. Thus, we designed a hybrid camera system to mimic it: A global camera with wideFoV captures low-resolution whole scenes, whereas several local cameras with long-focus lens tracks are used to capture interesting details.
(2) Entropy equilibrium. To reach the videographic memory equilibrium, the state with the maximum entropy, we can directly maximize the minimal pairwise distance , which is approximately proportional to both the Hmem(X) andHinst(X) . As depicted in Fig. 2, the feature vectors  are produced by the encoder and transmitted to the videographic memory to update the instance-level engram. Intuitively, if a query sample
are produced by the encoder and transmitted to the videographic memory to update the instance-level engram. Intuitively, if a query sample 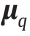 can increase the videographic memory entropy (i.e., Hmem(X) < Hinst(X) ), the engram update mechanism tends to encourage such an update. In contrast, if the newly observed information decreases the system entropy, i.e., Hmem(X) ≥ Hinst(X) , such a process will be inhibited. Notably, we do not need to calculate the entropy. Instead, as described in the previous section, the minimal pairwise distance can reflect the relative changes in the entropy. In our experiment, we used the perceptual embeddings as feature vectors (i.e., ).
can increase the videographic memory entropy (i.e., Hmem(X) < Hinst(X) ), the engram update mechanism tends to encourage such an update. In contrast, if the newly observed information decreases the system entropy, i.e., Hmem(X) ≥ Hinst(X) , such a process will be inhibited. Notably, we do not need to calculate the entropy. Instead, as described in the previous section, the minimal pairwise distance can reflect the relative changes in the entropy. In our experiment, we used the perceptual embeddings as feature vectors (i.e., ).
《3.3. Feedback pathway》
3.3. Feedback pathway
After generating the engram, we used a designed feedback pathway for the engram-driven videography synthesis (Fig. 3). In this approach, the pixel-level details are captured and preprocessed to instance-level observations. In contrast to the feedforward pathway focused on engram generation, the instance-level engram helps synthesize high-resolution images from lowquality instance-level observations. Technically, an engram association module is trained to retrieve the best-matched feature vector from the engram (denoted the ‘‘engram vector”). Finally, we concatenate the two feature vectors and use a synthesis module to generate high-resolution images [33,34].
(1) Engram association. The purpose of engram association is to find the engram vector for generating the best high-resolution image. This means that the selected engram vector should be close to the feature vector of the observation. Although there are already a large number of loss functions both in the low-level pixel domain and high-level semantic domain [27], none of them can handle a large resolution/quality gap. Thus, we implement the engram association module using our new pairwise loss function, as shown in Fig. 4(a). The feature vector of the observation is generated by the encoder, whereas the engram vector is extracted from the high-level engram directly. A perceptual loss is then used to estimate the similarity score. This step is applied to all of the engram–input pairs to select the best engram vector.
As it is very difficult to obtain the ground truth of a similarity score, we adopt the pairwise ranking loss to train the network [46]. During the generation of the training data, we examine all of the observation–engram pairs and use the peak signal-to-noise ratio (PSNR) of the synthesized image to rank all of the engram vectors. With this ranking, we train the network by comparing two observations–engram pairs using the pairwise ranking loss.
(2) Synthesis module. As illustrated in Fig. 4(b), we recover the high-quality image using a synthesis module. A warping module is used to build a dense correspondence between the feature vector and engram vector. We modify the FlowNet structure to support multichannel feature maps [47,48]. Finally, we concatenate the two vectors and use a decoder to generate the final highresolution image. The decoder consists of one deconvolutional layer with 64 filters (size 4 × 4, stride 2). The loss function L is defined between the decoder output and ground truth, as follows:

where 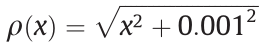 is the Charbonnier penalty function [49]; Igt denotes the ground truth; and IH represents the decoder output.
is the Charbonnier penalty function [49]; Igt denotes the ground truth; and IH represents the decoder output.
《4. Experiment》
4. Experiment
We verified our engram imaging system on both computer synthetic data and real-world data, and showed evident improvements for both compared to conventional imaging systems. We also conducted ablation studies to demonstrate the effectiveness of each module in our neural network.
《Fig. 4》
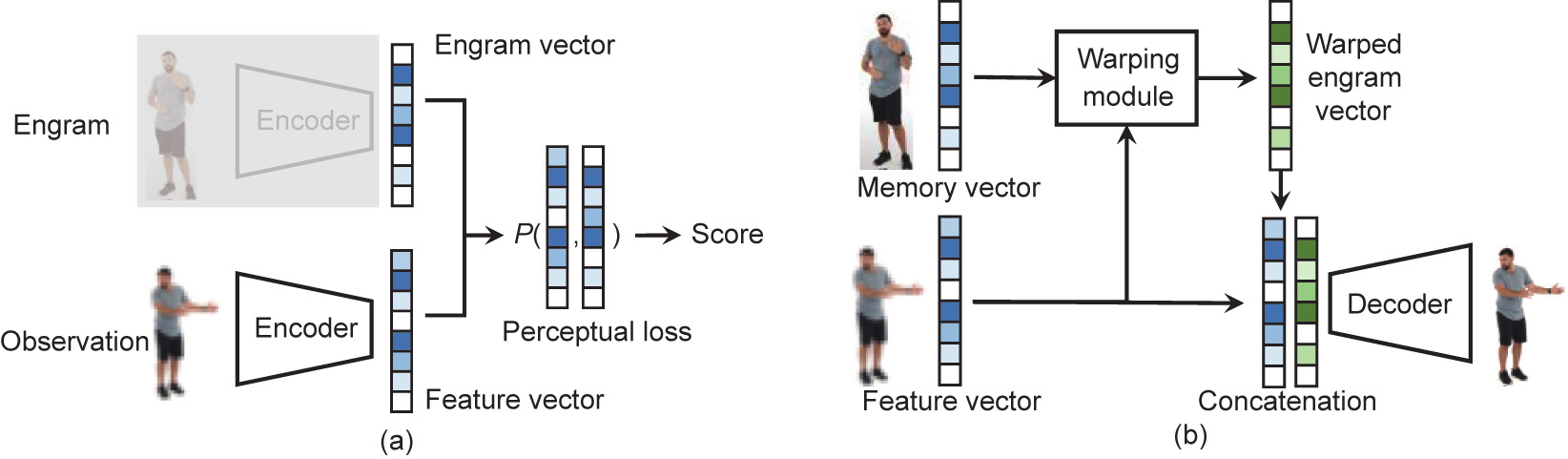
Fig. 4. Network structure of two sub-modules in the feedback pathway. (a) Association module for engram extraction; (b) synthesis module. P: perceptual loss.
《4.1. Data preparation》
4.1. Data preparation
To better verify the effectiveness of our engram imaging system, we used the Unreal Engine to render synthetic data for the simulation verification. We also rendered virtual human models on the scene using predefined paths; these were used as the simulated interesting instances of the synthetic video. The main camera was set to a 90-degree FoV with 8192 × 8192 30-fps resolution. The high-resolution videos were first rendered as a ground truth, and then were down-sampled as a low-resolution wide-FoV video. We also cropped a high-resolution small block from the ground truth as a high-resolution small-FoV video (mimicking the center of the human eye).
In addition to computer synthetic data, we tested our system on real captured videos. The real-world data were generated using the gigapixel video dataset PANDA [50]. As PANDA covers a wide-FoV with an extremely high resolution, we cropped a small moving block located on interesting regions or objects as a highresolution small-FoV video, and down-sampled the entire video as a low-resolution wide-FoV video.
《4.2. Comparison with conventional imaging system》
4.2. Comparison with conventional imaging system
Fig. 5 demonstrates the results from our engram imaging system and the conventional imaging system on the computer synthetic scene with quantitative evaluation in Table 1. Five persons are covered by the whole wide-FoV video, and the highresolution video block is designed to scan all the persons circularly. Each scanning cycle for one person contains one high-resolution frame and 19 low-resolution frames. The results show that our system can dramatically improve the visual quality. In the conventional imaging system, the person becomes blurry, especially the faces, once the local camera moves to other persons. In our system, the persons can be kept at high resolution for a long time with the help of the engram. We demonstrate faces with different view angles for two representative persons. Our image system can recover the details of the faces and hairs, such as the eyes, nose, and mouth.
《Fig. 5》

Fig. 5. Results on synthetic data. Two representative persons are highlighted.
《Table 1》
Table 1 Quantitative comparison with state-of-the-art methods for different sequences.
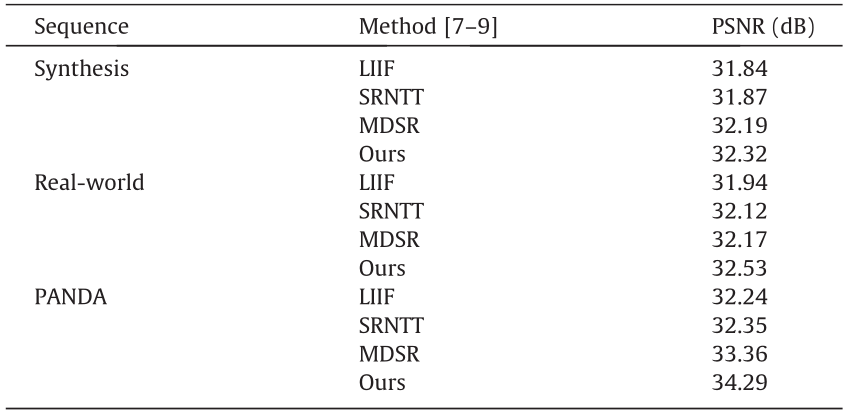
LIIF: local implicit image function; MDSR: multi-scale deep super-resolution system.
We also tested our results using real-world data (Fig. 6). This video was captured on the campus of the Harbin Institute of Technology, Shenzhen. The same scanning strategy was used to generate the data. Several typical frames of two representative persons are cropped and shown below the panoramic image. The results show that our system can successfully recover small details, such as fingers. Our system can recover different expressions from very low-resolution observations with the help of the engram.
《Fig. 6》

Fig. 6. Results on real-world data (dynamic). Two representative persons are highlighted. The red and blue trajectories denote their moving path.
In addition to dynamic persons, some static objects also benefit from our imaging system, as shown in Fig. 7. Compared with the state-of-the-art SISR, multi-scale deep super-resolution system [51], and SRNTT algorithms [32], our method successfully restores the recognizable Chinese characters (red block); this is almost impossible without the engram. The quantitative results are presented in Table 1. The quantitative results show that our method achieves a higher PSNR than the local implicit image function and SRNTT approaches, especially on the PANDA dataset.
《Fig. 7》

Fig. 7. Results on real-world data (static objects). From top to bottom, low resolution observation, results from state-of-the-art SISR, multi-scale deep superresolution system (MDSR) [51], and RefSR SRNTT algorithms [32], and those from our engram imaging system.
《4.3. Effectiveness of the engram association module》
4.3. Effectiveness of the engram association module
We also conducted experiments to verify the effectiveness of the engram association module. Two factors were considered: the engram buffer size and the association strategy. For the former, we chose 2%, 5%, 10%, and 20% of the video size, and tested their performance. For the association strategy, we compared our trained strategy model with a random selection method. Fig. 8 illustrates the results of the study. As expected, increasing the engram size benefits the imaging quality, but the improvement becomes minor when over 10%. Our trained engram association module shows superior performance to the random method, especially when the engram size is small.
《Fig. 8》
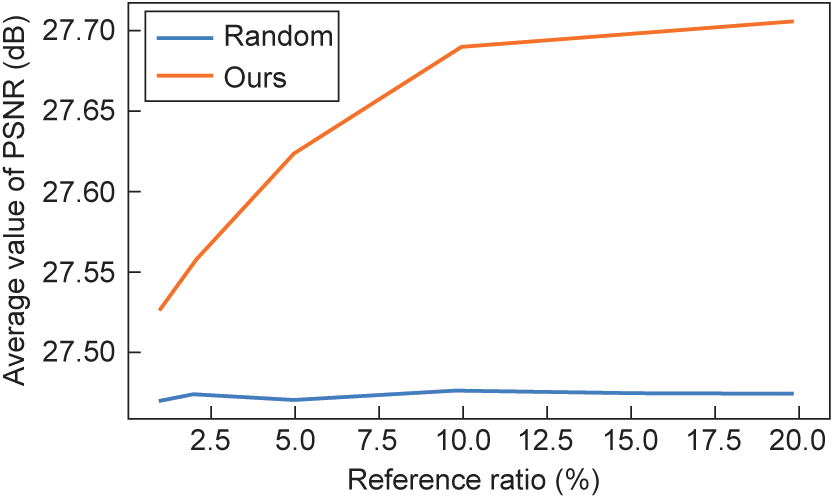
Fig. 8. Plots show the effectiveness of our engram association module.
《4.4. Ablation study》
4.4. Ablation study
An ablation study was conducted to verify the effectiveness of the three modules in our engram imaging system. There are three important modules in our system, EPU, instance-level observation module, and instance-level engram module, corresponding to three regions in the human brain.
(1) Without EPU. The EPU corresponds to the PFC of the human brain. As described in Section 4.2, we tested a random method and untrained perceptual distance, but the references were still selected from the same person. Without the EPU, the engram association module can hardly find the correct engram vector belonging to the same person or object. Thus, we randomly selected the engram vectors from the entire engram. Engram vectors could also be selected from other persons or objects.
(2) Without instance-level engram. The instance-level engram module corresponds to the cortical memory in the human brain, and is responsible for saving the abstracted and consolidated engram. Without it, we can no longer consolidate the useful feature vectors and inhibit meaningless ones. In addition, the instance-level observations can only save short-term content (similar to the hippocampus of the human brain). Hence, we used random patches from the entire image frame of nearby frames as the engram vectors in this subsection.
(3) Without instance-level observation. Without instancelevel observation, the system degrades to a SISR system, so the feature vector of the observation itself is used as the engram vector.
Fig. 9 shows the results of the ablation study. As expected, the full system has the highest PSNR and best visual quality (distinguishable face). Without any of the three modules, the reconstruction quality drops dramatically, and the faces become very blurry.
《Fig. 9》

Fig. 9. Results of ablation studies. w/o: with/without.
《5. Conclusions》
5. Conclusions
To achieve high-performance imaging, we proposed an engramdriven videography system with dual feedforward and feedback pathways. The feedforward pathway extracts instance-level representations to form the engram used by the feedback pathway to synthesize future high-resolution images, similar to that in the human visual system. In the feedforward pathway, a videographic entropy equilibrium concept is proposed for deciding whether to consolidate the information to the instance-level engram or inhibit it, leading to a compact and highly efficient representation. In the feedback pathway, a ranking-based engram association module is combined with a feature domain warping and synthesis module to generate spatially and temporally consistent high-resolution content. Experiments on both computer synthetic and real-world images/videos demonstrate that our engram-driven videography can generate high-quality results using only 5% high-resolution observations and 95% low-resolution observations. In addition, with the help of the associated engram, we can recover the highresolution details of small instances. Such techniques can also be used for image/video super-resolution, low-cost gigapixel imaging, VR/augmented reality (AR) content representation and compression (foveated rendering), and so on. We believe that the engram-driven videography will open new avenues for image/ video capturing, understanding, and storage, leading to a nextgeneration visual sensation system.
《Acknowledgments》
Acknowledgments
The authors would like to thank Yijie Deng, Xuechao Chen, Xuecheng Chen, and Puhua Jiang for their great help, as well as the Shuimu Tsinghua Scholar Program. Project funded by National Natural Science Foundation of China (62125106, 61860206003, and 62088102), in part by Shenzhen Science and Technology Research and Development Funds (JCYJ20180507183706645), in part by Ministry of Science and Technology of China (2021ZD0109901), in part by Beijing National Research Center for Information Science and Technology (BNR2020RC01002), China Postdoctoral Science Foundation (2020TQ0172, 2020M670338, and YJ20200109), and Postdoctoral International Exchange Program (YJ20210124).
《Compliance with ethics guidelines》
Compliance with ethics guidelines
Lu Fang, Mengqi Ji, Xiaoyun Yuan, Jing He, Jianing Zhang, Yinheng Zhu, Tian Zheng, Leyao Liu, Bin Wang, and Qionghai Dai declare that they have no conflict of interest.











 京公网安备 11010502051620号
京公网安备 11010502051620号




