



《1 引言》
1 引言
半个多世纪以来, 经过人们的不断努力神经网络得到了长足发展, 其应用领域也几乎渗透到各个学科。尤其是在1989年, 多层神经网络被证明是连续函数的一致逼近器
本文在文献
《2 过程神经元网络模型》
2 过程神经元网络模型
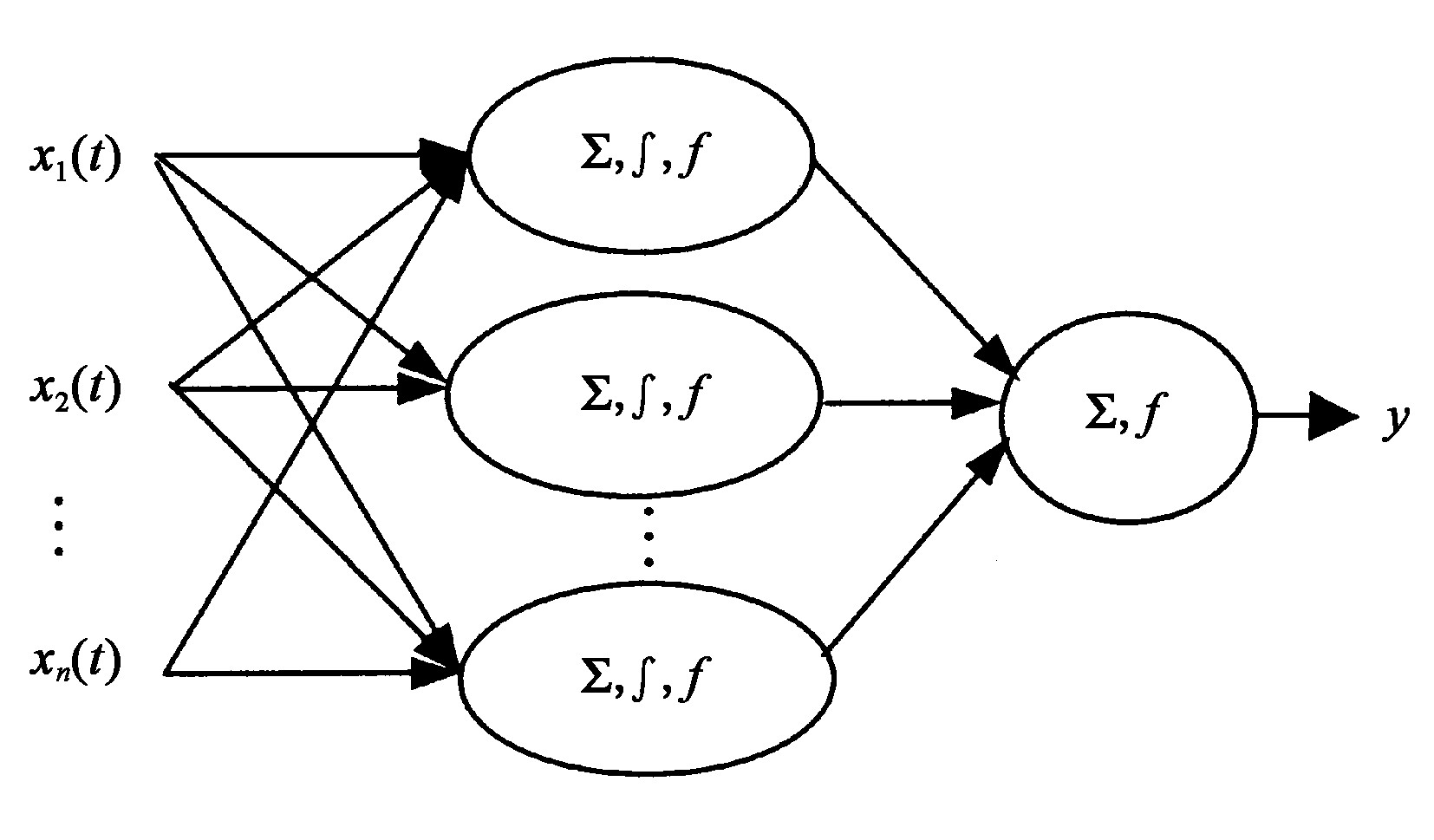
过程神经元的结构与传统MP模型的结构相类似, 由加权、聚合和激励运算三部分组成。与传统神经元不同之处在于过程神经元的输入和权值可以是时变的, 其聚合运算既有对空间的多输入汇聚, 亦有对时间过程的累积
其中, 输入层有n个单元, 中间层 (隐层) 具有m个单元, 输出层为线性关系。过程式的输入与输出之间关系为:
式 (1) 中, vi为隐层到输出层的连接权值, w
《3 学习算法》
3 学习算法
过程神经元网络的学习可借鉴传统的梯度下降法, 如BP算法。将式 (1) 重写为
其中
给定K个样本:
其中dk 为第k个样本的输出 (期望输出) 。网络误差函数可取
由梯度下降法, 网络权值学习规则为
其中 i=1, 2, ..., m; j=1, 2, ..., n;α, β, γ为学习速度。令
则
若取f (u) = (1+e-u) -1, 则f′ (u) =f (u) · (1-f (u) ) 。
算法描述如下:
步1 给定误差精度ε; 累计学习迭代次数s=0; 学习最大迭代次数M ;选取权值基函数bl (t) , l=1, 2, …, L。
步2 初始化权值和阈值
步3 由式 (3) 计算误差函数E, 如果 E<ε 或 s>M 转步5。
步4 按式 (4) ~ (6) 修正权值和阈值; s+1→s; 转步3。
步5 输出学习结果; 结束。
由于过程神经网络与传统的神经网络有较大的区别, 尤其是引入了权值基函数和积分运算。从数学意义上讲, 在函数空间中会有无穷多的基函数存在, 但常用的基函数有三角函数、多项式函数、Fourier 基函数、小波基函数等。过程神经网络中的基函数, 在某种意义上, 用于将与时间有关的输入函数映射成为人们熟悉的光滑函数, 即磨光算子。为避免冗余的叠加, 基函数常被选择为正交基, 在本文的实验中采用了正交基函数。在实验部分的两个例子中发现, 采用正交基函数会使得网络的训练速度明显加快。如采用如下正交基函数
这里ξl = l / ent T 。当然, 也可以选择其它基函数, 有时对于具体的问题还会有更好的基函数。笔者建议在选取基函数时, 首先要选正交基函数, 再是所选取的基函数要便于计算。但是, 为什么正交基函数会使得网络的学习速度加快, 还有待于更深入的研究。
时间积分 (或聚合) 是过程神经网络与传统神经网络的最大区别。由于在过程神经网络中输入是与时间相关的量, 即与时间有关的函数, 而输出只是一个静态向量, 显然在输入与输出层之间应有某些神经元来完成对时间的聚合运算。 时间聚合可以有多种形式, 如求极值max (bl (t) , x (t) ) , 做卷积运算bl (t) *x (t) , 计算内积〈bl (t) , x (t) 〉等等, 其中bl (t) , x (t) ∈[0, T]。 本文中选取内积运算, 这也是前文中所见到的。对于输入为一连续函数的情况, 实际计算时一种常用的数值处理方法是将输入x (t) 在 [0, T]上N等分。而对于一个实际问题, 在多数情况下, 不可能知道x (t) 在[0, T]上的所有值, 通过实验的方式获得的只是部分值, 有时这些数据在[0, T]上分布甚至是非等距的。对于这种情况有两种选择:a. 直接采用这些实际的非等距的数据作为过程神经网络的输入;b. 对原始数据加以处理, 使得它们之间具有相同的间距。前一种选择虽然能够反映实际数据的情况, 但却容易带来较大的计算误差;而后一种选择可以避免由于不同间距引起的计算误差。对原始数据的处理可分为两步, 第一步是由原始数据构造拟合曲线x (t) ;第二步再将x (t) 在[0, T]上进行N等分。
《4 应用举例》
4 应用举例
过程神经网络可以用于任何输入为时间的函数而输出为一静态向量的问题, 这类问题在实际中大量存在。这一节给出两个这样的例子, 一个是有关聚合化学反应温度变化对生成物分子数的影响问题;另一个是在渗流实验中各参量的变化最终反映油藏区域采收率问题。这两个问题是石油开发和加工中遇到的重要的实际问题。
《4.1例1 丙烯酰胺均相聚合化学反应》
4.1例1 丙烯酰胺均相聚合化学反应
该聚合反应是化学实验中一类重要的化学反应, 在这类反应的诸影响因素中, 温度是影响生成物浓度和反应时间的重要因素。为了得到温度变化与生成物浓度之间的函数关系, 传统的做法是借助于微分动力学和热力学方程。但由于物理模型的复杂性以及由实验带来的测量误差的不可测性, 往往难以找到两者之间的真实关系, 而过程神经网络正好适合求解这类问题。下面根据丙烯酰胺均相聚合化学反应的实验数据来处理这一问题。
表1列出了丙烯酰胺均相聚合反应实验的部分结果。表1中t 表示从0时刻开始以分钟计的累积时间, Ti (i =1, 2, ..., 9 ) 表示第i组实验的温度 (℃) 测试结果;Nm为每组实验对应生成物的分子数 (106 cm-3) , 即丙烯酰胺均相聚合反应生成物的浓度。
Table 1 Experiment results of super-high molecular-weight polyacrylamide
《表1》
t/min | T1/℃ | T2/℃ | T3/℃ | T4/℃ | T5/℃ | T6/℃ | T7/℃ | T8/℃ | T9/℃ |
0 | 17 | 18 | 18 | 18 | 14 | 15 | 15 | 14 | 13 |
10 | 19 | 16 | 21 | 18 | 15 | 16 | 16 | 15 | 15 |
20 | 23 | 16 | 23 | 18.5 | 17 | 16 | 18 | 16 | 16 |
30 | 27 | 17 | 26 | 21.5 | 20 | 16.5 | 21 | 17.5 | 18 |
40 | 30 | 18 | 31 | 24.5 | 22 | 18 | 25 | 19.5 | 19 |
50 | 34 | 19 | 36 | 28.5 | 25 | 20 | 30 | 22 | 21 |
60 | 39 | 20 | 43.5 | 34 | 28 | 22 | 36 | 24 | 23 |
70 | 45 | 21 | 52.5 | 38 | 33 | 24 | 40 | 26.5 | 25 |
80 | 52 | 22.5 | 59 | 46 | 38 | 29 | 54 | 30.5 | 27 |
90 | 64 | 24 | 68 | 56 | 46 | 32 | 64 | 35.5 | 30 |
100 | 73 | 26 | 73 | 63 | 52 | 36 | 73 | 43 | 34 |
110 | 81 | 28 | 77 | 74 | 60 | 40 | 76 | 54.5 | 41 |
120 | 82 | 32 | 79 | 78 | 66 | 44.5 | 77 | 67 | 44 |
130 | 84 | 36 | 83 | 93 | 72 | 50.5 | 78 | 79.5 | 49 |
140 | 88 | 45 | 87 | 95 | 76 | 57.5 | 79 | 83 | 54 |
150 | 92 | 54 | 96 | 97 | 81 | 66.5 | 84 | 87 | 65 |
160 | 101 | 64 | 98 | 100 | 83 | 67 | 86 | 93 | 77 |
170 | 113 | 68 | 102 | 110 | 94 | 69 | 89 | 98 | 80 |
(Nm) * | 18.11 | 18.38 | 18.94 | 18.53 | 14.96 | 17.01 | 17.54 | 19.15 | 16.44 |
*每组实验对应生成物的分子数 (106 cm-3 )
图2给出了描述丙烯酰胺均相聚合反应实验温度 (℃) 随时间 (min) 变化的9组曲线, 每条曲线对应一组实验生成物的分子数。对于过程神经网络而言, 每条曲线对应一个与时间相关的输入序列, 而生成物的分子数为过程神经网络的输出。
本例中训练过程神经网络的各参数选取如下:1个输入节点;18个权值基函数;22个隐层节点;1个输出节点。学习速率为0.05;最大学习次数为5 000;学习精度为0.001。
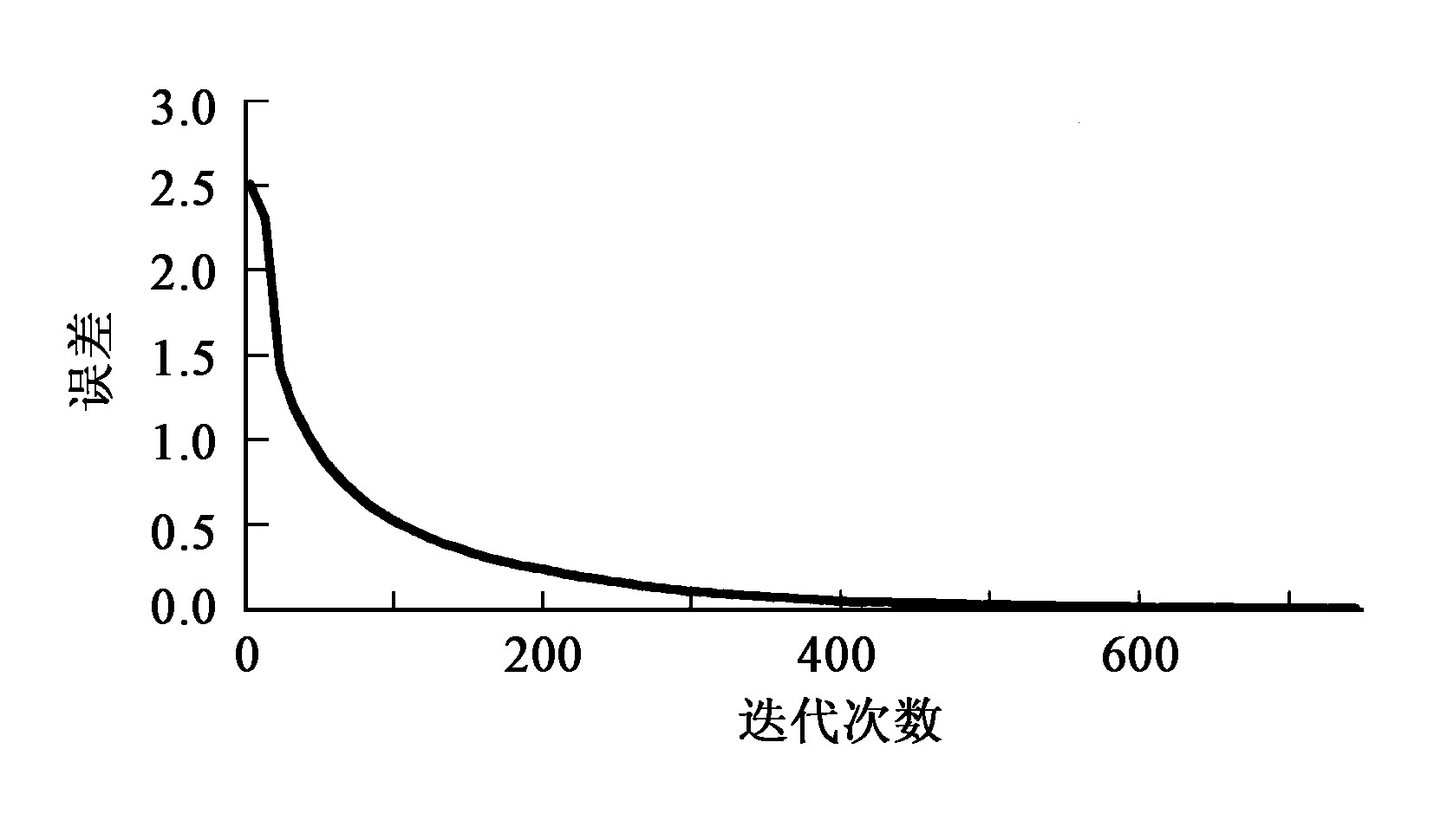
图3 给出了用38个样本训练过程神经网络的误差变化曲线, 学习过程经过在610次迭代后即可达到给定的误差精度 (0.001) 。为了测试学习完后的过程神经网络的泛化能力, 笔者用5个非训练样本进行测试, 并与实际值进行比较, 测试的结果见表2。
Table 2 Identification results for test samples
《表2》
预测分子数/106 cm-3 | 13.60 | 18.63 | 13.94 | 14.76 | 16.85 |
实际分子数/106 cm-3 | 15.61 | 15.74 | 16.53 | 15.42 | 18.22 |
绝对误差/106 cm-3 | 2.01 | 2.89 | 2.59 | 0.66 | 1.37 |
相对误差/% | 12.9 | 18.4 | 15.7 | 4.3 | 7.5 |
《4.2例2 石油地质中的渗流问题》
4.2例2 石油地质中的渗流问题
渗流问题的研究是石油储量预测中很有意义的工作。传统预测石油储量的方法是通过一定量的实验室模拟油藏含油岩石渗流实验的数据和相关的数学力学模型来计算油层的采收率, 从而进一步估算石油储量。但这种方法需要建立和求解复杂的数学力学模型, 且渗流问题是影响因素较多的非线性问题, 建模精确度低, 求解难度大, 适应性差, 故实际中难以满足石油储量预测的要求。
渗流是一个与过程有关的问题, 利用过程神经网络建立实验室数据与油层采收率之间的关系, 从而避免了上述复杂的数学模型问题。表3 给出了实验室含油岩石体积为595.75 cm3的渗流实验的一组记录, 其中, t为时间, Vw为其产水量 (mL) , Vo为其产油量 (mL) , Wp为其含水率 ( 单位体积内产水量与产油量和产水量 之比 ) , Δp为压力差 (kPa) 。以上4个量 (Vw, Vo, Wp, Δp) 是与时间有关的变化量, 作为过程神经网络的输入。与该组实验对应的油层的采收率R=24.14 %, 作为过程神经网络输出。实际上, 这样的渗流实验有若干组, 如用其中的8组记录就可以构成过程神经网络的8个学习样本。
Table 3 A record for seepage experiments
《表3》
t/h | Vw/mL* | Vo/mL* | Wp/% | Δp/kPa |
0 | 0 | 8.4 | 0 | 5.59 |
4 | 8.4 | 0.8 | 91.3 | 3.14 |
8 | 8 | 0.4 | 95.24 | 2.99 |
12 | 8 | 0.3 | 96.39 | 3.04 |
16 | 8.3 | 0.25 | 97.08 | 2.94 |
20 | 8.8 | 0.2 | 97.78 | 2.89 |
24 | 9 | 0.15 | 98.36 | 2.84 |
28 | 9.4 | 0.1 | 98.95 | 2.96 |
32 | 9.7 | 0.1 | 98.98 | 2.84 |
36 | 9.5 | 0.1 | 98.96 | 2.89 |
40 | 9.55 | 0.05 | 99.48 | 2.89 |
44 | 9.75 | 0.05 | 99.49 | 2.89 |
48 | 7.15 | 0.05 | 99.31 | 2.84 |
* 含油岩石体积为595.75 cm3的产水量和产油量
本例中训练过程神经网络的参数选取如下:4个输入节点;43个权值基函数;20个隐层节点, 1个输出节点。学习速率为0.05;最大学习次数为30 000;学习精度为0.05。图4 给出了用上述样本和学习参数训练过程神经网络的误差变化曲线。这种方法用于发现渗流过程实验数据与采收率之间的映射关系比较简单, 易操作, 所得结果能够满足实际需求。
《5 结语》
5 结语
过程神经网络是传统神经网络在时间域上的扩展, 从神经生物学的角度出发更符合生物神经元的运行机制, 可在求解大量与时间有关的过程式输入问题方面发挥较大作用。由于这种模型属首次提出, 还有许多问题, 尤其是网络的学习与泛化, 有待研究和完善。由于过程神经网络的输入是一个过程, 其数据量一般较大, 在网络训练中往往要花费较大的时间和空间开销。而对于较少的训练样本, 网络的泛化能力一般较低。因此, 如何选择权值基函数和提高网络的学习速度是一个值得研究的问题, 如何精选学习样本以便提高学习速度和泛化能力, 是过程神经网络重点研究的另一个问题。











 京公网安备 11010502051620号
京公网安备 11010502051620号




