

《1 引言》
1 引言
在生产调度系统中, 存在大量的不确定因素, 这可用随机性、模糊性等来表示。利用模糊理论和随机理论来对生产调度问题进行建模势在必行, 因此数学规划发展已成了一个大分支——不确定规划, 包括随机规划和模糊规划
近年来, 许多学者针对生产调度系统, 建立了确定性调度模型
《2 生产系统的模糊性分析》
2 生产系统的模糊性分析
实际问题中约束条件是带有弹性的。一般问题都是用清晰系数或硬约束来做的, 得到的确定性方案不能完全表述具有模糊性质的生产调度系统。这些模糊因素大都体现在约束条件中, 也有可能在性能指标中有所体现。
对生产调度问题, 一般存在如下模糊性:
1) 加工期的模糊性 生产过程中, 原料的特性及其供给状况、设备的性能及其使用条件、能源的供应和废品的出现以及工人的技术水平和主动性、积极性等等, 均会影响加工完成进度, 因此加工期是不确定的, 存在模糊性。
2) 交付期的模糊性 迄今为止, 所有调度问题均被认为, 工件的交付期是固定的、清晰的。实际并非如此, 工件的交付期与客户的满意度关系甚为密切, 不同客户对工件的交付期要求不同, 并非都要求其严格固定, 在开放车间 (open shop) 调度中更是如此。交付期的模糊性实际上普遍存在。理解和充分利用交付期的满意度, 可充分发挥设备的利用率等, 尤其有利于供不应求、满负荷运行状态的生产进度安排。
3) 产品的外部需求量和销售量的模糊性 众所周知, 市场是动态变化的。市场对产品的需求受产品价格、供求、国家政策、人们生活质量等众多因素的影响。由于市场的波动, 产品的销售量在未来的一段时间内也是不定的。
4) 产品销售价格和原料价格的模糊性 价格被认为是一个定值。但市场需求瞬息万变, 价格的动态性易知, 销售价格和原料价格都是模糊变量。
5) 存贮容量的模糊性 存货是指企业在生产经营过程中为销售或耗用而储备的物资。在现代企业中, 存货不仅品种繁多, 且占用的资金数量也很大。一个好的存贮策略, 既可以使总费用减小, 又可避免因缺货影响生产和销售。目前, 生产系统最优存贮容量的研究很多, 为了确定最优存贮容量常需要确定存贮容量的上下限, 而存贮容量的上下限往往也是不确定的, 是模糊变量。
6) 人类决策行为的模糊性 人们在实践活动中获得的知识不可避免地带有模糊性, 往往利用这些模糊知识去分析、解决问题。决策者一般具有模棱两可的知识、经验和信息, 不一定能据此获得最优解, 而且人们掌握的是一些不完全的信息, 这些信息很难归结为某一个精确的值。在这种情况下, 更自然地采用模糊集合来表示所得到的信息。
《3 间歇过程生产调度的模糊建模方法》
3 间歇过程生产调度的模糊建模方法
模糊建模是指从模糊信息的描述到建立一个适当的模糊数学模型的过程。1993年Kondili以STN为工具, 提出了基于间歇化工过程的确定性调度模型MILP (mixed integer linear programming)
《3.1 适于模糊的参数》
3.1 适于模糊的参数
与生产系统的模糊性分析相对应, 为便于建模, 可用设备加工能力的模糊性来表达加工期的模糊性。设备的加工能力
销售价格
人类决策行为的模糊性在模型中主要体现在隶属函数、偏好及方案的选择上 (见3.3节) 。
综上所述, 需要模糊的变量为:设备的加工能力
《3.2 生产调度的模糊模型》
3.2 生产调度的模糊模型
假设:有N 种产品, 有NE 种能源, 各加工设备所需能源是已知的;Blit∈R+为t时刻开始在设备i上加工的作业l批量;Xlit∈{0, 1}, Xlit=1表示t时刻在设备i上开始作业l的加工, 加工中或未加工皆为零;Ijt∈R+为t时刻开始的单位时间内化工产品j的存贮量, Ij0为调度期开始前化工产品j的存贮量;GEkl∈R+, GEklU∈R+, k=1, 2, …, NE分别为t时刻开始的单位时间内能源k的需求量和最大供应量, GEkU∈R+为调度期内能源k的最大消耗量;τ∈R+为划分的调度时间间隔, 一个调度时间间隔称为一个单位时间, τli∈R+为设备i处理作业l所需的加工时间数 (时间间隔的个数) ;θlj∈R+和
各集合有如下关系:
3.2.1 约束条件
1) 设备分配
2) 产品的产量与消耗约束
3) 生产设备的容量约束
由于最大容量和最小容量往往是一个不确定值, 可以用模糊数表示。
4) 存贮容量约束
式 (4) 表示t时刻化工产品j的存贮量应满足的约束, 其中
5) 能源供应约束
6) 物料平衡约束
式 (6) 表示t时刻化工产品j的存贮量与t-1时刻化工产品j的存贮量之差等于t时刻产品出产量与t时刻产品的消耗量之差。
7) 原料供应约束
由于市场作用, 供需情况是不断变化变化的, 因此产品的外部供应量是一个模糊变量。
8) 产品需求约束
式 (8) 表示存贮、加工量与产品的外部需求之间应满足的关系, 由于市场作用, 外部需求量时刻都在变化, 是不确定值, 故用模糊数表示。
9) 加班工时约束
3.2.2 性能指标
最大利润
式 (1) 至式 (10) 形成了生产调度的MIFCLP模型。
《3.3 模糊信息的描述与表达》
3.3 模糊信息的描述与表达
在上述模糊模型中, 有6类变量具有模糊性, 将其描述为可以计算的数学形式尤为重要。因为模糊是由于概念上的模糊性或各种模糊因素的影响而造成定性处理时的不确定性, 它反映了人们对模糊概念或模糊信息的认识, 强调了人在系统综合评价中的重要性。
一般模糊规划中常将模糊数表达为L-R型
例子中, 隶属度函数均采用铃型径向基函数 (也可采用其他隶属函数, 如高斯函数和薄板样条函数等) 为
其中, {对于aik, bik, cik而言, k, i=1, 2, 3, …, n}为参数集。参数c确定了函数的中心, 参数a确定了函数的宽度, 参数a和参数b共同确定了函数的斜度。
《4 模糊算法》
4 模糊算法
虽然模糊模拟在经过多次采样之后, 可能得到一个较好的解, 有可能是最优解, 但其效率太低, 尤其是求解大规模问题时会耗时巨大, 与转化为普通规划后的求解算法相比, 失去了其优越性。大多数情况下, 模糊约束和模糊目标的重要性不同, 因此后者考虑的情况不周全。究其原因, 主要是尚未充分有效地利用原问题中的信息。所以, 综合二者特点, 提出一种既能考虑到目标和约束的不同重要程度, 又能避免模拟的低效率的算法, 即普通模糊算法 (SFA, simple fuzzy algorithm) , 步骤如下:
Step 1 初始化任务参数和遗传算法参数, 包括种群规模npop、交叉概率Pc、变异概率Pm和进化代数ngen等;
Step 2 初始产生npop个满足一定置信度水平的染色体;
Step 3 对染色体进行交叉和变异操作, 同样需要检验是否满足一定置信水平;
Step 4 在此置信水平上, 计算所有染色体的目标值;
Step 5 根据目标值使用基于序的评价函数计算所有染色体的适应度 (即目标值) ;
Step 6 用旋转赌轮选择染色体;
Step 7 重复步骤Step 3至Step 6直到达到预先设定的停止规则;
Step 8 把最好的染色体作为最优解。
为了采用以上算法并且体现置信水平, 需要将MIFCLP模型化为如下的模糊机会约束规划模型:
其中, x是决策向量, ξ是模糊参数向量, f (x, ξ) 是目标函数, gj (x, ξ) ≤ 0是约束函数。目标值
《5 实例仿真》
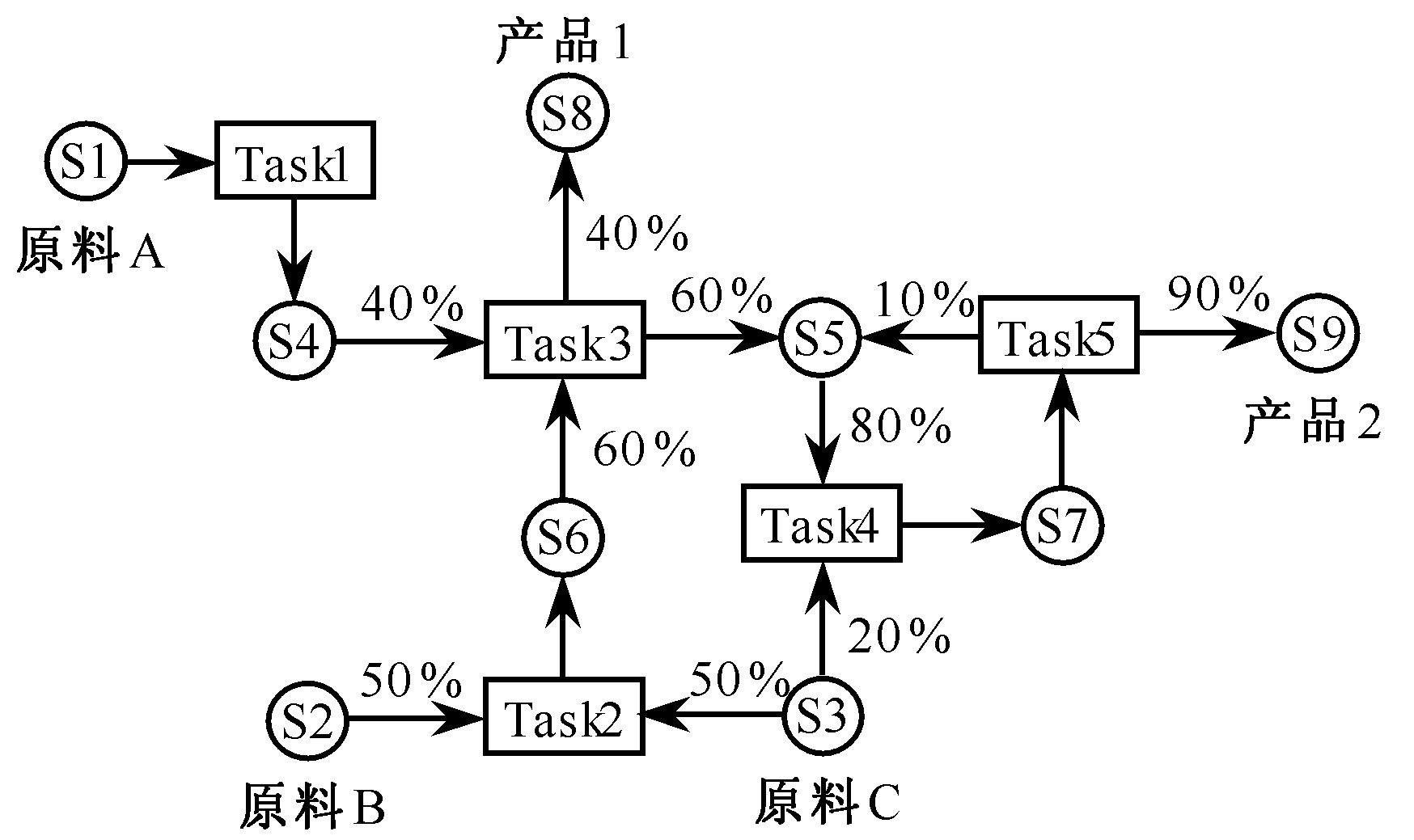
5 实例仿真
实例为一批处理化工过程的调度问题, 生产调度的清晰模型采用文献
在模型中, 均不考虑产品的产量与消耗约束、能源约束、原料供应约束、加班约束;性能指标中只考虑最大利润。在文献
表1实例数据
Table 1 Example data
《表1》
| S81 | S82 | S83 | S84 | S85 | ||||
估计销量 |
15 | 25 | 10 | 15 | 30 | |||
| S91 | S92 | S93 | S94 | S95 | ||||
| 25 | 35 | 55 | 45 | 75 | ||||
设备加工上限 |
V11U | Vl2U | Vl3U | V54U | ||||
| 100 | 80 | 50 | 200 | |||||
存贮容量上限 |
I4U | I5U | I6U | I7U | ||||
| 100 | 200 | 150 | 100 | |||||
单位原料费用 |
η1 | η2 | η3 | |||||
| 2 | 2 | 2 | ||||||
单位存贮费用 |
h4 | h5 | h6 | h7 | ||||
| 0.5 | 0.5 | 0.5 | 0.5 | |||||
单位产品售价 |
μ8 | μ9 | ||||||
| 12 | 5 | |||||||
| θ14 | θ26 | θ35 | ||||||
作业1产出比例 |
1.0 | 1.0 | 0.6 | |||||
系数θlj |
θ38 | θ47 | θ55 | θ59 | ||||
| 0.4 | 1.0 | 0.1 | 0.9 | |||||
|
|
|
|
|
|||||
作业1消耗比例 |
1.0 | 0.5 | 0.5 | 0.4 | ||||
系数 |
|
|
|
|
||||
| 0.6 | 0.2 | 0.8 | 1.0 | |||||
表2清晰模型和模糊模型的结果比较
Table 2 Results comparison between the crisp model and the fuzzy model
《表2》
指标 |
清晰模型/% | 模糊模型 SFA算法/% |
模糊模型 模糊模拟/% |
|
利 润 / 元 |
>900 |
100 |
||
>1000 |
100 | 100 | ||
>1100 |
97 | |||
>1200 |
98 | 93 | 92 | |
>1300 |
97 | 85 | 92 | |
>1400 |
60 | 61 | 67 | |
>1500 |
18 | 41 | 45 | |
>1600 |
0 | 11 | 23 | |
>1700 |
0 | 2 | 2 | |
>1800 |
0 | 0 | 2 | |
利润范围 /元 |
1280~1567 | 990~1727 | 1092~1818 | |
时间 /s |
<1.7 | 53~67 | 180 | |
% 表示运行结果高于某一范围的次数占总次数的百分数
由表2可以看出, 由于模糊因素的存在, 对模糊模型的求解是以牺牲时间为代价的。然而对模糊模型, 不论模拟、不模拟所得的结果都比清晰模型好很多, 清晰方法在1 600之后没有解, 而模糊的方法都至少有11%的解。此例子很明显地表明, 模糊模型MIFCLP是可行的。
《6 MIFCLP模型的优点》
6 MIFCLP模型的优点
所提出的模糊建模方法是针对模糊规划问题中的参数而言的。它通过对各种类型的生产调度系统的分析, 充分有效地考虑这些参数的实际意义, 融入专家经验知识, 把适于模糊的参数进行模糊化, 并且选取合适的隶属函数, 从而建立起精简、符合实际的间歇过程生产调度模糊模型, 其优点如下:
1) 模型结构清晰、灵活实用, 而将参数全部模糊化后的模型虽然通用, 但无疑只是从数学角度来考虑的, 而数学上或理论上的最优解未必是符合实际需要的, 也可能是实际无法得到的。并且, 由于模糊模型的求解更加复杂、耗时, 那么全模糊的模型求解时间将很长。而所提出的模糊模型在这个方面有很大改进。
2) 根据实际需要, 把某些不确定的因素或参数用相应的模糊数来处理, 模糊数 (有时称为模糊区间数) 的选择灵活;
3) 由于模糊因素的存在, 放宽了约束, 扩大了解的搜索范围, 使得某些或全部性能指标得到改善。尤其对大规模问题, 约束众多, 相互矛盾, 而描述成模糊约束后能解决此问题, 显示其优越性;
4) 在此模型基础上, 可针对具体问题做具体分析, 参考此模糊的方法对其他具体的参数或变量进行相应的模糊化。
《7 结语》
7 结语
由于生产调度系统本身的复杂性、不确定性, 基于对模型与实际的差异考虑, 将模糊数的概念引入到生产调度中, 提出了一种通用的模糊建模方法。由于模糊参数是对模型不准确的一种反映, 因此所提出的方法能够比精确系数的方法更好地解决模型与实际的差异。对于大规模问题, 笔者将做进一步研究。为了证明模糊建模的优越性, 因此用了最普通的算法。关于算法部分, 将另行论述。











 京公网安备 11010502051620号
京公网安备 11010502051620号




