

《1 引言》
1 引言
人类获取的信息 80 % 来源于图像媒体, 15 % 来源于语音。这说明图像是人们生活中信息交流最为重要的信息载体,也是蕴含信息量最大的媒体。数字化信息的今天,数字图像数据的压缩是十分必要的,也是现代多媒体通信的一个基本问题。 20 世纪 80 年代中后期, Barnsley 等人提出分形图像压缩编码的概念,作为一种新的具有较高压缩比潜力的图像编码方法,越来越受到广泛关注。 Jacquin 提出的全自动分形图像编码使得分形图像编码进入了一个新的时代。然而传统的分形图像编码方法采用过搜索的方式,而且计算复杂,因此编码速度一直是分形编码实用化的一大障碍。针对分形编码的这些缺陷,分析了迭代函数系统不会改变图像块的改进方差的基础上,提出了基于改进方差的分形图像编码方法。实验表明,该方法在保证快速性的同时,重建图像的质量得到了进一步的提高。
《2 分形图像编码算法简介》
2 分形图像编码算法简介
图像中存在着各种各样的信息冗余,结构冗余就是其中的一种。分形图像编码就是利用图像各部分之间的相似性去除冗余信息,以达到图像压缩的目的。编码过程中,首先将图像分割成互不重叠的值域块和可重叠的定义域块。对每一个值域块,寻找一个经仿射变换后能与此值域块匹配误差最小的定义域块。对所有的值域块,其对应匹配的定义域块的位置信息和仿射变换参数一起构成了分形图像压缩的分形码。这些分形码被定义为作用于图像空间的一些算子。当将这些分形码作用于任意图像时,首先将图像分割为互不重叠的值域块,然后将每一值域块用其对应的经仿射变换后的域块代替。由于这些算子必须是压缩映射的,所以当用这些算子对任意的图像进行迭代时,图像最终收敛于算子唯一的不动点,拼贴定理证明,这样的不动点可以很好地表示原始图像,从而可用分形码来表示原始图像,进而实现图像压缩的目的。
《3 算法分析》
3 算法分析
根据分形图像编码过程,可以假设原始图像的值域块 R 的大小为 n X n,则定义域块 D 的大小为 2n × 2n,对一个特定的值域块 R,其最佳匹配是通过对所有的定义域块 D 抽样以后,分别与 R 进行比较,计算它们之间的误差并取其最小值来实现的。 误差函数为[1]

其中 k = n x n, R 为值域块矩阵, D 是经过抽样以后的定义域块矩阵; I 为全 "1" 矩阵;s 和 o 为实数,分别是仿射变换因子和亮度平移因子。
式 (1) 是判断 2 个图像块相似程度大小的依据,针对每一个值域块 R,都要对定义域块集中的所有 D 进行如上的三种复杂计算,从而找出最佳匹配块;因此编码过程的计算时间主要由参数计算、值域块 R 的数量、搜索空间三部分组成。
为了提高编码速度,需要解决下面三个问题。
1) 参数计算 误差函数中包含 2 个参数分别为 s 和 o,在计算误差之前,必须通过式 (2) 和式 (3) 将参数计算出来之后再应用到式 (1) 中。对于参数的计算,可以采用文献[1]中提到的方法。认真分析式 (1),可得到下面形式:
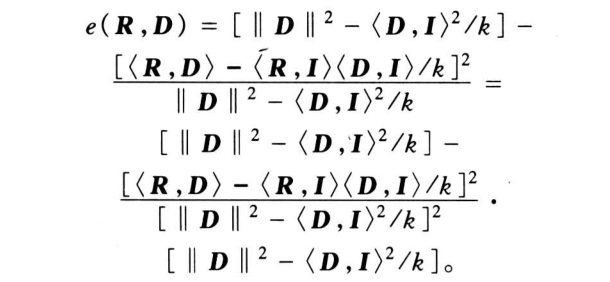
由式 (2) 可将误差函数简化为
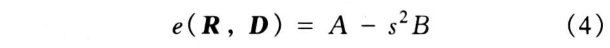
其中

式 (4) 中仅含有一个参数 s, A 和 B 可以在进行匹配搜索之前预先处理,因此采用文献 [1] 中的这种简化形式,使误差函数的计算非常简单,有利于提高编码速度。
2) 值域块 R 的数量如果 R 数量越大,编码时间就会越长。在编码过程中,首先需要把图像进行分块,块的尺寸越小,所得到的图像块数量就越多,编码时间就会越长;可以通过增大 R 块的尺寸来减少其数量,从而缩短编码时间,但是, R 块的尺寸越大,它与整体的相似性就越小,这样得到的译码图像的质量就会下降。为了解决这个问题,通常采用四又树的分割方法,也是目前分形图像编码中采用较多的一种分割方法,在图像较平坦的区域使用尺寸较大的 R 块,其他区域采用尺寸较小的 R 块,从而使前面提到的问题得到解决。
3) 搜索空间 搜索空间中所含定义域块 D 的数量越多,编码所消耗的时间越长。传统的分形图像编码方法采用过搜索的方法。其实,对于一个给定的值域块,与它较相似的定义域块仅有几个至十几个,而为了这少量的定义域块,传统的分形编码却付出了很大的代价,即在整个定义域集中进行搜索。搜索范围之大是影响分形图像编码速度最主要的原因,因此解决搜索空间问题是研究的重点。在分析了收缩仿射变换不会改变图像块的改进方差的基础上,给出了一种新的快速分形图像压缩方法。这种方法按照特定的预选条件,对定义域集进行处理,排除大部分的非相似块,相似匹配只在最后剩下的较少部分中进行,而大大缩短了搜索时间。
《4 相关研究》
4 相关研究
前面提到,编码过程中影响编码速度最关键的地方是在对相似块的搜索部分。分块的尺寸大小反映了搜索空间的大小,尺寸越小,形成的搜索空间就越大,相应的编码时间更长。然而为了保证图像的重建质量,必须把图像分成较小的块,这样才能保证能够找到相似程度较大的匹配块。很多学者针对减少搜索空间来加速分形编码领域做了大量的研究工作。这里,主要分析采用图像块元素间的统计特性来提高分形图像编码速度的几种方法。
统计的方法 通常包括描述性统计和推测性统计。描述性统计包括均值、方差等,将数据本身包含的信息加以概括、总结、浓缩、简化,使问题变得更加清晰、简单,易于理解,便于处理。
方差 能够很大程度上反映图像的灰度特性,且分形图像编码中采用的仿射变换是一种线性变换,图像块经仿射变换后,方差值保持不变,因此近几年很多学者根据方差的这一特点纷纷提出了各种基于方差的快速编码方法[2,3],并收到了较好效果。
信息熵 当某一数据的概率分布已知时,就可以根据概率分布情况来获取一些相当有价值的东西,信息熵就是其中的一种。信息熵是对信息的度量,由于图像块中各个像素点灰度的熵值能很好地描述图像像素点灰度的分布特征,它表达了图像块所包含的信息丰富程度,而且图像的各种拓扑变化都不会影响熵值,所以谭郁松等提出基于熵值的图像分形压缩算法[4]。
改进方差 方差是反映样本数据的绝对波动状况,方差与均值的比值即变异系数能反映样本数据的相对波动状况,因此更能反映样本的波动性。但是,图像块的变异系数经过收缩仿射变换之后其数值将会改变,因此对方差采用一种改进形式,使其在收缩仿射变换过程中是一个不变量。这样,根据每一个图像块的改进方差形成一个预选条件,从而达到减少搜索空间的目的。
在图像块的改进方差不会随仿射变换而改变的情况下,提出了一种新的快速分形图像编码方法。
《5 改进的快速分形编码算法》
5 改进的快速分形编码算法
《5.1 迭代函数系统 (IFS) 的改进方差不变性》
5.1 迭代函数系统 (IFS) 的改进方差不变性
首先对迭代函数系统下一个定义:如果一个平面图形上的各点经过线性变换后,图形上各点的距离比原有距离小,那么就称这种线性变换是收缩仿射变换,由若干个收缩仿射变换组成的集合称为选代函数系统。
定义改进方差计算公式为:

其中  (D) 代表 D 的方差;E(D) 代表 D 的均值。
(D) 代表 D 的方差;E(D) 代表 D 的均值。
在分形图像编码过程中,对于任意的排列块,在寻找最佳匹配块时,其收缩仿射变换是一种线性变换。在这些变换过程中,其改进方差将保持不变性。
引理 给定线性映射  : D → R,则 D 和 R 的改进方差相等。D 和 R 分别是f的定义域和值域。
: D → R,则 D 和 R 的改进方差相等。D 和 R 分别是f的定义域和值域。
证明 设 的形式为  ,其中
,其中 
 0,则
0,则

由式 (7) 可以得

故命题成立。
定理 基于仿射的 IFS 变换将不会改变图像的改进方差。
证明 由引理可知,单个仿射映射不会引起图像块改进方差的变化,即  。
。
依据定义, IFS 仅由有限个仿射变换组成,设为 反复应用引理,不难得到
反复应用引理,不难得到 其中
其中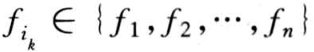 ,故命题成立。
,故命题成立。
《5.2 新编码方案的提出》
5.2 新编码方案的提出
改进方差算法主要依据这样一个事实:尽管定义域块与值域块的改进方差很接近并不意味着二者会有较好的匹配,但是如果两者差别很大,则一定是不匹配的。根据改进方差的 IFS 不变性形成一个判别条件,将搜索空间限制在一个相对较少的范围内,从而降低了搜索空间,大大提高了编码速度。
在搜索过程中,首先要选定一个窗口,对于此窗口的选择也有不同种方法。文献[3]中采用的是定义占匹配块集合一定比例的搜索窗口尺寸 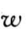 %,搜索窗口中有 (/2) % 的匹配块方差比最佳匹配的方差低,另外 (/2) % 比它高。这种方法的弊端就是假设匹配块都出现在其中的(/2) % 的那一部分,那么另外的一部分就是很大的浪费。文献[4]中采用将域块熵值按照大小进行排序,然后划分为 N 份区间,得到集合
%,搜索窗口中有 (/2) % 的匹配块方差比最佳匹配的方差低,另外 (/2) % 比它高。这种方法的弊端就是假设匹配块都出现在其中的(/2) % 的那一部分,那么另外的一部分就是很大的浪费。文献[4]中采用将域块熵值按照大小进行排序,然后划分为 N 份区间,得到集合  ;在此基础上,将所有域块进行分类。根据目标块
;在此基础上,将所有域块进行分类。根据目标块 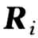 熵值的所属类别,并在相同类的域块集中进行匹配。这里存在一个缺陷,当 的熵值位于集合
熵值的所属类别,并在相同类的域块集中进行匹配。这里存在一个缺陷,当 的熵值位于集合  的左边界或右边界时,此目标块 R 就得不到很好的匹配。因此采用了一种对于一个目标块 R,先计算其与所有 D 块判别条件的绝对差,然后进行排序选出最小的几个,形成一个搜索匹配空间。这样,满足了匹配块集合的改进方差与最佳匹配的改进方差最接近的条件,并且避免了上面提到的两种弊端。新的编码方案具体步骤如下:
的左边界或右边界时,此目标块 R 就得不到很好的匹配。因此采用了一种对于一个目标块 R,先计算其与所有 D 块判别条件的绝对差,然后进行排序选出最小的几个,形成一个搜索匹配空间。这样,满足了匹配块集合的改进方差与最佳匹配的改进方差最接近的条件,并且避免了上面提到的两种弊端。新的编码方案具体步骤如下:
Step 1 原图划分为可重叠的 2 N × 2 N 域块
Step 2 计算出所有域块的 F(D) 值。
Step 3 计算出所有值块的 F(R) 值。
Step 4 针对一个目标块 ,计算绝对差  并从小到大进行排序。
并从小到大进行排序。
Step 5 选出前 M 个域块形成搜索空间,进行相似匹配操作,利用式 (4) 找到具有最小误差的域块。
Step 6 如果该最小值小于事先取定的误差域值 T,则停止该块的匹配;否则将本目标块进行四叉树划分,进行下一步匹配。
《6 实验结果与分析》
6 实验结果与分析
为了验证判别条件 F(X) 的有效性,并方便实验的进行,首先将上面的操作步骤做了稍微改变,即先不采用四又树分割方案,而是将图像均匀地分成 4 × 4 的等大值域块。这样,分别利用三种统计特性,方差、熵值和所提出的 F(X) 条件分别对标准的 256 × 256 的 Lena 图像进行分形编码。实验结果见表 1。
《表 1》
表 1 不同算法及 M 值的实验结果
Table 1 Experimental results with different algorithms and the values of M
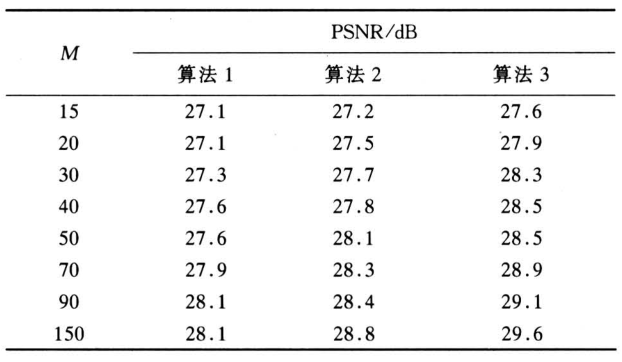
表 1 中 PSNR 表示解码图像的峰值信噪比,算法 1 是利用方差作为判别条件;算法 2 是利用熵值作为判别条件;算法 3 是利用 F(X) 值作为判别条件。三种方法除了判别条件不同外,均采用统一的编码步骤。从表 1 中可以看出,由判别条件不同而产生了不同的译码效果。从 M 所取的几个值中可看出,算法 1 的效果较算法 2 稍微差一些,而算法 3 比算法 1 和算法 2 的效果都要好。实验结果进一步表明,判别条件 F(X) 可以与分形压缩相结合,并能收到很好的效果。
在上述的编码 Step 5 中,要先选出前 M 个定义域块形成搜索空间,然后再进行相似匹配。其中 M 的选取对译码图像的质量有很大影响,从表 1 中可以看到,随着 M 值的增大 PSNR 值也不断增大,但增加的幅度却越来越小,表明大部分图像块已经得到了最佳匹配,只剩下一小部分需要靠 M 值的增大才能获得最佳匹配。所以,在相似匹配的过程中设置一个门限值,当误差小于门限值时结束这一目标块的匹配,并将当前的定义域块作为此目标块的最佳匹配,然后转到下一目标块。这样可以进一步缩短计算时间。
在改进编码方案中,编码的性能直接与 2 个参数 (M,T) 的选取有关,如果采用三层四叉树分割,那么每一层中 2 个参数的选取值又可以不同。为了使三种方案便于比较,实验中采用统一的四叉树分割方案和统一的参数值,这样保证压缩比相等的情况下,比较其他两方面就可以了,其结果见表 2。 从这些数据中可以看到,当压缩比 CR 一定时,无论是在重建图像的质量还是压缩时间方面,新的压缩算法都优于其他两种算法。经实验表明,此方法优于基于方差的快速编码方案以及与统计特性相关的快速编码方案。
《表 2》
表 2 压缩比相等时不同编码算法的实验结果
Table 2 The experimental results with different cases at the same compression ratio

《7 结语》
7 结语
在研究图像的定义域块和值域块之间相似性的基础上,提出了一种新的基于改进方差的快速编码算法并提出一种独特的窗口划分方案。该方法利用图像块的改进方差作为预先条件,使搜索匹配的范围限制在一个很小的范围内,从而使编码速度得到提高。在压缩比一定的情况下,与文献 [3] 和文献 [4] 中提出的快速算法相比,编码速度以及解码图像的质量得到了进一步提高。











 京公网安备 11010502051620号
京公网安备 11010502051620号




