

泥浆在建筑、地质、电力、水利等部门的应用非常普遍,对于建筑工程施工及其质量控制非常重要,然而要用传统的取样法对泥浆的物理参数进行在线监测是比较困难的。借助超声学方法可以有效地监测泥浆的体积浓度等物理参数,而且可以实现在线监测或实时监测。通常的做法是借助于超声波在泥浆介质中的传播,通过超声波信号的参数变化,反演泥浆浓度等介质的参数。由于建筑上使用的泥浆成分的多样性,还很难找出一个准确的理论模型。因此必须借助一些先验知识并采取数据处理技术对泥浆浓度进行反演,特别是对泥浆浓度超过 20 % 的情况。
模式识别技术[1] 在海洋遥感、计算机信息处理、自动控制等领域有广泛的应用前景。在基于声衰减和声速等介质的声学参数[2] 的泥浆浓度反演的过程中,将模式识别技术用于数据拟合、分类等处理过程,并提出了一种合理的数据分析方法[3 , 4] ,可以在高浓度的泥浆系统中使用。
《1 最近邻归类法介绍》
1 最近邻归类法介绍
最近邻法是统计模式识别中比较直观、简单的方法,是常见的一种非参数分类方法。把每个训练样本作为该类的中心点,对未知类别的模式 X 进行它与训练样本距离的计算,并取最小值,将该训练样本作为其归属类别。图 1 是一个二维二类的例子,其中 X1,X2 为 2 个自由度, W1,W2 为两类。两类的分界面是分段线性的。
《图 1》
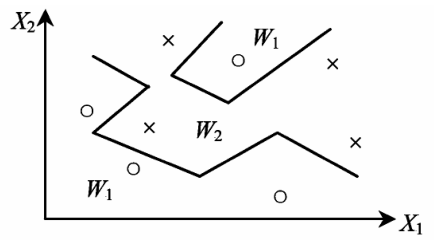
图 1 最近邻法
Fig.1 Nearest neighbor
理论证明,最近邻方法的平均错误率 P 与最小错误率贝叶斯分类器平均错误率 P * 的关系为
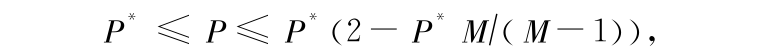
其中 M 为分类数。当样本数趋于无穷时, P 略大于 P *,但小于 2 P * 。最近邻方法得到这样的错误率,是远远满足实际要求的。
最近邻方法计算量太大。在泥浆反演的实际工作中,笔者结合聚类算法,对这种方法做了改进。
《2 聚类算法介绍》
2 聚类算法介绍
聚类算法在统计理论、数据分析等方面应用极其广泛。聚类结果有一定的主观因素,衡量结果是否合理应该从它是否符合实际情况来确定。
离差平方和准则是一种简单常用的聚类准则。设有 N 个样本,分成 K 个群,{X1,X2 ,…, XK },第 j 个群 Xj 有 Nj 个样本,其中心点为

则 Xj 群内所有点和中心点 mj 的距离平方和为
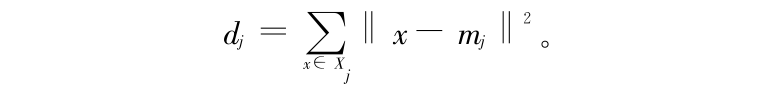
K 个群的类内离差平方和为

如果分类恰当, dj 和 J 应当比较小。以 J 最小作为分群准则,这样就应该把 x 分到离它最近的中心所代表的群中去。这种分类方法用在未知点“群”距离较大的场合尤其合适。
《3 泥浆浓度反演的基本原理》
3 泥浆浓度反演的基本原理
假设泥浆系统是分层均匀的,超声信号通过泥浆以后,信号幅值和声速发生明显的变化[5 ,6] ,通过对声衰减和声速的变化来反演泥浆浓度。实验发现,对小粒径泥浆粒子,体积浓度低于 20 % 时,衰减与体积浓度近似成正比关系,高于 20 % ,二者没有明显的线性关系;声速在低于 20 % 浓度时,声速随浓度增加而降低,高于 20 % 时,声速随浓度增加而增加,但都没有明显的正比关系。
在研究声衰减、声速和泥浆浓度的关系时,由于存在体积浓度 20 % 的分界点,所以考虑分段研究。为了论述方便,将用统一的函数来近似表示它们的关系。
假设体积浓度  与声衰减 α 满足函数关系式为
与声衰减 α 满足函数关系式为
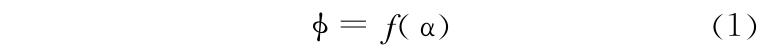
体积浓度 与声速 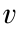 满足关系式为
满足关系式为

令 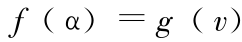 ,得到
,得到
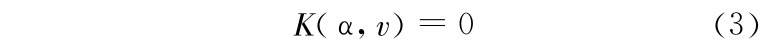
得到的实验数据是离散值,进行数据拟合,用式(1)至式(3)表示它们的关系。假设函数分段连续。
由式(1)可以得到 随 α 的变化率为

由式(2),可以得到 随 的变化率为

经过多次实验,根据聚类准则对实验数据进行处理,建立的数据库为(α, ,),通过(α, )反演 。通过测定的(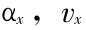 ),将根据数据库中的训练样本求出
),将根据数据库中的训练样本求出 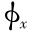 的值。实际上()未必是建立样本库中的数据,此时根据最小距离法,求出样本库中离()最近的点的体积浓度 ,再根据式(4)和式(5)进行修正,将修正值作为 的反演值。
的值。实际上()未必是建立样本库中的数据,此时根据最小距离法,求出样本库中离()最近的点的体积浓度 ,再根据式(4)和式(5)进行修正,将修正值作为 的反演值。
《4 模式识别在反演中的具体应用》
4 模式识别在反演中的具体应用
假设数据库中的 α 和 的关系如图 2 所示(对训练样本已经进行过聚类处理,图 2 中‘×’代表训练样本)。将训练样本点记为{ A1 , A2 ,…, Aj ,…},分别把样本库中的相邻 2 点作为一类(同一个点属于 2 类),即取{ Aj , Aj + 1 }, j  1 作为一类。对于一未知浓度的泥浆系统,得到一组样本点(去掉离大部分样本点距离较远的点),如图 2 中的‘○’表示。首先,对样本点进行凝聚处理,找到其中心点的位置,假设中心点为 O ,将未知样本归类的过程是计算 O 与每一类{Aj , Aj + 1}的中心位置的距离,找到最小值作为其归属类 K∶{ AK , AK + 1 }, K 中的 2 个样本点记为 M 和 N 。通过 O 向 MN 的连线作垂直线交于 P 点,如图 3 所示。
1 作为一类。对于一未知浓度的泥浆系统,得到一组样本点(去掉离大部分样本点距离较远的点),如图 2 中的‘○’表示。首先,对样本点进行凝聚处理,找到其中心点的位置,假设中心点为 O ,将未知样本归类的过程是计算 O 与每一类{Aj , Aj + 1}的中心位置的距离,找到最小值作为其归属类 K∶{ AK , AK + 1 }, K 中的 2 个样本点记为 M 和 N 。通过 O 向 MN 的连线作垂直线交于 P 点,如图 3 所示。
《图 2》

图 2 未知样本与数据库样本
Fig.2 Unknown and database sample
《图 3》

图 3 获得 p 点
Fig.3 Access point p
在 P 点,由式(4)和式(5)求得( ,
,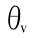 )。
)。
> 表明,此点声衰减随泥浆浓度变化更快,此时,在校正数据时 P 点应该向 Δα 减少方向的直线上移动,如图 4 所示。
《图 4》

图 4 寻找最优点 P′
Fig.4 Search for the optimum point P′
在 P 点处,Δα>Δ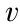 ,所以将 P 移向 P′ 点,在 P′ 点处,Δα<Δ,移动幅度可以近似使 P′ 点处满足
,所以将 P 移向 P′ 点,在 P′ 点处,Δα<Δ,移动幅度可以近似使 P′ 点处满足  。
。
< 的情况下,声速在该点对泥浆浓度的反演影响更大,此时 P 点应该向Δ 减少的方向移动。
= 时, P 与 P′ 重合。
设| MP′|/| P′N|= L ,令(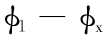 ) / (
) / (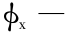
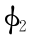 )= L ,得到的反演数据为
)= L ,得到的反演数据为

在一定条件下,测得的泥浆体积浓度(0.75 ~ 25.63) % 与相应的声衰减、声速的数据见表 1 ,并建立其样本数据库。
由表 1 得到的衰减与声速的关系见图 5 。
《表 1》
表 1 实验测得体积浓度与声衰减和声速的关系
Table 1 Experiment data about concentration , attenuation and velocity

《图 5》
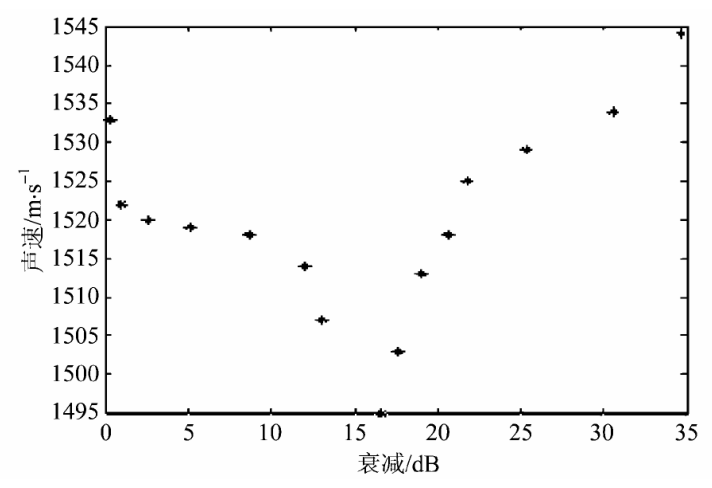
图 5 实验测得衰减和声速关系
Fig.5 Relation between attenuation and velocity in experiment
根据上述数据处理方法得到的结果和实测数据见表 2 。理论计算值和实际测量值的对比曲线见图 6 和图 7 。
《图 6》
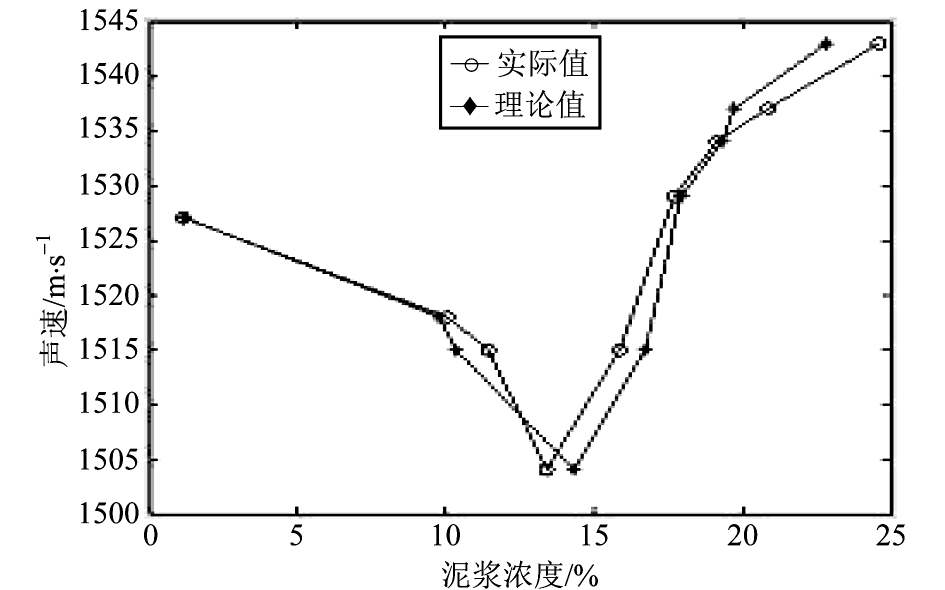
图 6 泥浆浓度与声速关系
Fig.6 Relation between concentration and velocity
《图 7》
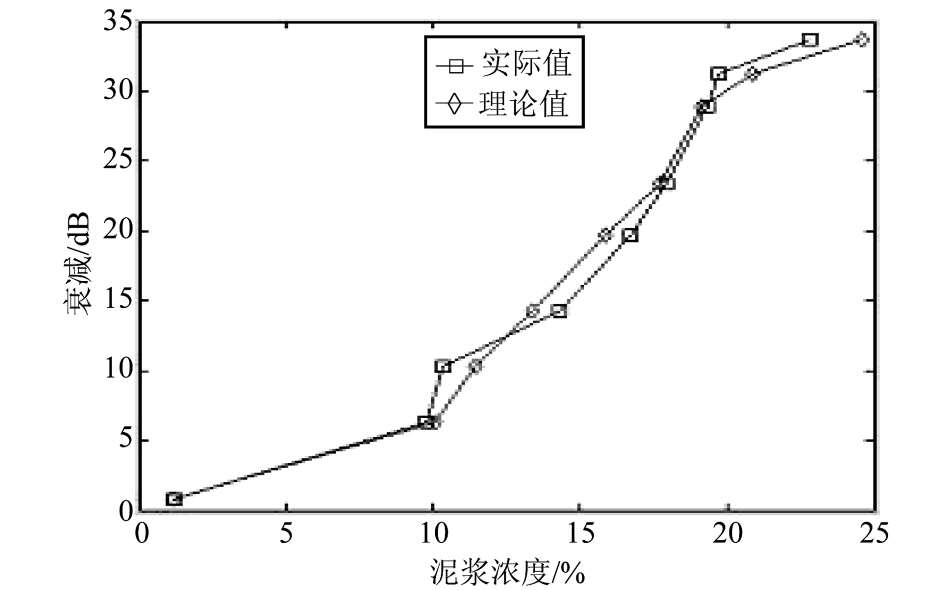
图 7 泥浆浓度与声衰减关系
Fig.7 Relation between concentration and attenuation
《表 2》
表 2 误差分析
Table 2 Error analysis

《5 误差分析》
5 误差分析
由表2的数据可以看出,理论计算值和实际测量值之间有一定的误差,一方面是实验过程中的存在测量和观测误差,这主要是由于高浓度泥浆很容易沉淀,影响观测数据的准确度;另一方面,由于测量过程中气泡的存在和悬浮质粒径大小分布的离散性以及温度、压力等都影响测量数据的准确性,这就要求获取比较多的样本,并在建库之前对数据进行合理的预处理。理论分析可知,反演泥浆浓度取自由度越多,反演结果就越准确,但在实验中,仅取两个自由度(声衰减、声速)来反演泥浆浓度,已经能够达到比较理想的效果。在实验过程中,注意减少误差的存在,在建库之前对数据进行合理的校正处理,反演结果会更加理想。
《6 结语》
6 结语
影响泥浆中的声速的因素除了泥浆的浓度外,还有其他许多物理和环境等方面的因素,笔者主要从泥浆的声速以及对声能量的衰减量方面进行分析研究。通过对实验数据的凝聚处理和对样本库的数据分类处理,不仅简化了数据处理过程,而且在一定程度上降低了样本库的数据量,降低了建立数据库的工作量。所提出的凝聚求最小距离来确定归类方法,在泥浆浓度反演的过程中,减少了实验误差,较好地满足了实际需要。











 京公网安备 11010502051620号
京公网安备 11010502051620号




