



车牌自动识别技术在智能交通系统中的应用十分重要。车牌定位是车牌自动识别的关键和前提。国内外学者对车牌定位进行了广泛的研究, 提出了许多算法。车牌定位的基本方法是基于车牌的特征提取车牌区域
针对目前国内使用的1992式车牌 (前牌) , 笔者提出了一种基于纹理和小波分析的车牌定位方法。针对图像背景复杂, 且车牌所占比例较小的特点, 提出了一种确定基元分类阈值的二值化方法;根据车牌字符的分布规律, 提出了二值纹理基元分析方法, 生成车牌候选区域;为了从候选区域中提取出车牌区域, 基于小波分析提取车牌区域竖笔画特征, 采用隶属度定量表征车牌竖笔画特征、位置特征及形状特征, 并给出了综合这些特征, 从候选区域提取车牌区域的方法。
《1 车牌候选区域生成》
1 车牌候选区域生成
1992式机动车牌照中的字符呈横排布局, 如果沿水平方向考察, 其灰度变化呈一定规律。本文基于纹理分析, 生成车牌候选区域。纹理分析以一维二值纹理基元 (以下简称纹理基元或基元) 为基本单位。纹理基元是像素的集合, 可用以下结构表示:〈位置, 类型, 长度〉。纹理基元的位置属性等于其起始点相对原点在水平方向偏移的像素数, 类型属性依据基元分类阈值分为黑、白两类, 而长度属性则是基元所涵盖的像素数。
《1.1基元分类阈值的确定》
1.1基元分类阈值的确定
牌照区域在整个车辆图像中只占很小部分, 基元分类阈值的设置应达到将车牌字符的笔画灰度与背景灰度区分开来的目的。常用的阈值选取方法一般分为全局阈值法和局部阈值法两类。全局阈值法对整个图像只计算一个阈值, Otsu算法
《1.1.1 图像灰度统计方法》
1.1.1 图像灰度统计方法
在牌照区域的局部图像内, 字符笔画与车牌背景间的亮度反差形成明显而密集的边缘, 上升缘与下降缘交替出现。这种密集、交替的边缘可以作为牌照区域的一个特征。在逐行扫描图像进行直方图统计时, 可以着重考察其中的边缘点及其数量、位置、类型等, 根据上述几项指标判断所经区域是否类似于车牌区域, 若类似则统计其中的像素灰度, 否则认为是无关部分而跳过, 由此得到有针对性的直方图。具体步骤如下:
1) 在图像行扫描时, 考察各个像素点与其相邻像素的灰度差, 当灰度差超过一定阈值时, 即认为当前像素是一个边缘点。如果像素行中的边缘点的有序集合元素数量足够多, 分布密集, 而且类型基本匹配 (上升边缘和下降边缘交替) , 则认为该集合所界定的区域是类似于车牌的目标区域, 对其中的像素灰度进行统计。边缘点 (x, y) 应满足的条件是:存在n≤M (M, n∈N) , M为常数, 使
式中G (x, y) 为点 (x, y) 的灰度值, T为阈值。
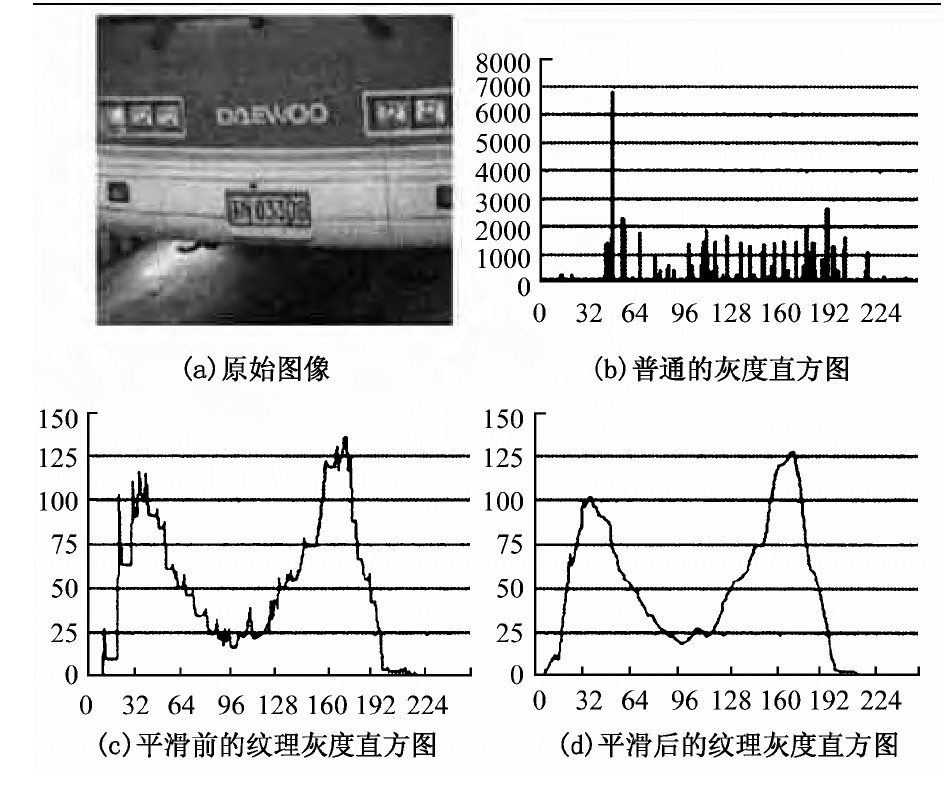
2) 边缘点之间像素的灰度统计方法是按条纹计数。边缘限定的区间被认为是一个亮度较均匀的条纹, 条纹涵盖的灰度范围中的所有灰度值对应的各计数值都增加1。这种方法的优点, 一是可以平衡字符笔画与背景的峰值, 还可对灰度直方图起到平滑作用。为了减小直方图的锯齿, 本文采用邻域均值法对直方图进行平滑处理。图1显示了本文方法与普通灰度直方图的区别。
《1.1.2 基元分类阈值的确定》
1.1.2 基元分类阈值的确定
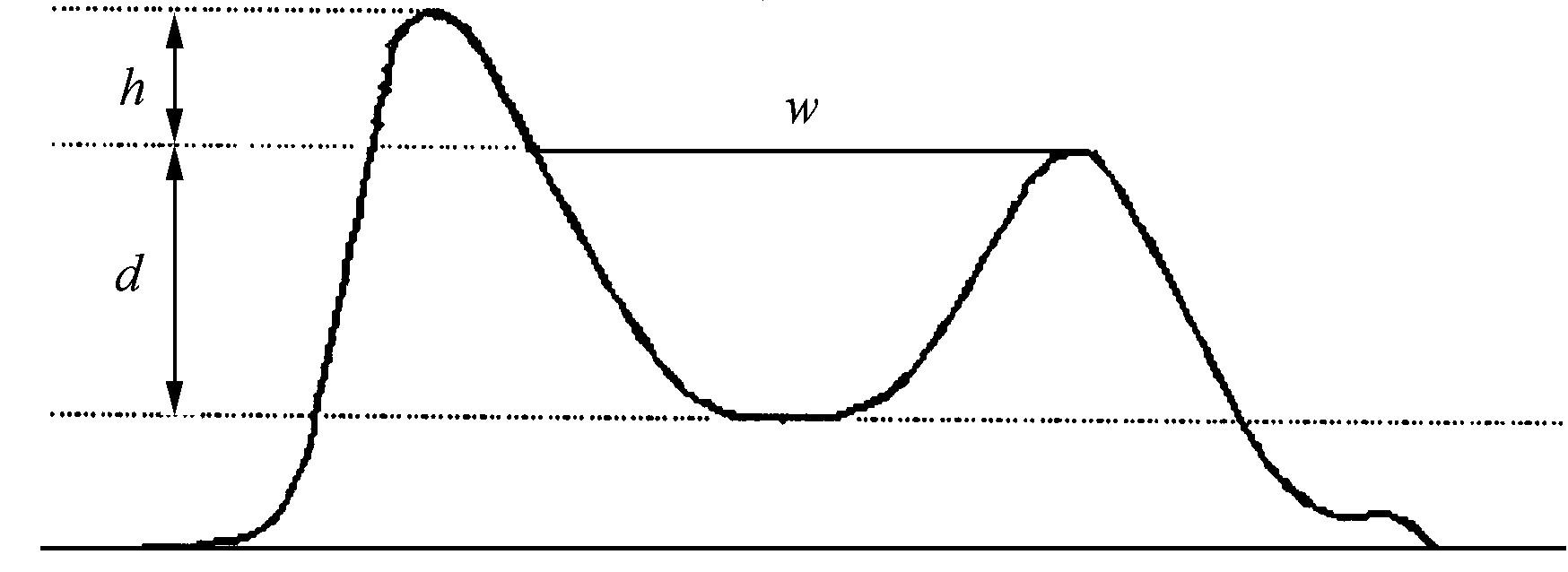
在理想情况下, 通过以上方法得到的灰度直方图曲线将存在两个明显的高峰 (主峰和次峰) , 实际中可能存在主峰不是一个理想单峰的情况, 在其最高点附近存在无法完全平滑的毛刺, 或者伴有一个副峰。如果简单地使用搜索局部极值的方法来寻找次峰, 找到的极有可能是上述毛刺或副峰。笔者提出同时寻找次峰和谷底的方法, 将次峰的搜索与谷底的考察结合起来, 可有效地解决这一问题。这种方法的基本思路是, 在搜索区域内逐一考察各个候选位置, 假设其是曲线的次峰, 在它与主峰之间寻找谷底, 计算以下度量指标:w (谷宽) ×d (谷深) /h (主次峰高度差) , 使该指标取最大值的位置, 即为次峰位置。图2显示了各特征指标的含义。
分别采用Otsu法、Niblack法及本文提出的阈值选取方法, 获取基元分类阈值, 并应用于车牌定位算法, 三种算法的计算时间及车牌定位率见表1。由表1可见, 本文的阈值选取方法定位率最高, 计算时间比Otsu法略长, 综合性能最佳, 在本文的定位算法中, Niblack法效果不好。
Table 1 Comparison of three thresholding methods
《表1》
阈值方法 | Otsu法 | Niblack法 (窗口15×15) | 本文方法 |
车牌定位率/% | 89.22 | 64.96 | 96.23 |
计算时间/ms | 0.94 | 198.3 | 3.79 |
《1.2候选区域基元序列提取》
1.2候选区域基元序列提取
《1.2.1 从像素行生成纹理基元链》
1.2.1 从像素行生成纹理基元链
基于纹理分析的车牌候选区域生成算法, 基元的集合用链的形式保存, 称为基元链。以链的形式表示一行像素对应的基元有序集合时, 应在基元结构的基础上增加一个成员, 构成四元组:〈起始位置, 颜色, 长度, 下一基元〉。
将像素行转换成纹理基元链的基本方法是逐一考察其中的像素, 首先按照基元的分类阈值确定该像素归入纹理基元时应属的类型, 然后比较该类型是否与最近生成的纹理基元类型一致, 如果两者相同则将该像素并入上述基元 (基元的长度延伸) , 否则以该像素为起始点创建一个新基元。
《1.2.2 纹理基元链的去噪》
1.2.2 纹理基元链的去噪
消除纹理基元链噪声的基本思想是视基元链中长度小于一定限度的基元为噪声基元, 若仅存在孤立噪声基元, 则将其对应的像素段并入邻近的非噪声基元中;如果基元链中存在若干个连续噪声基元, 则应根据其属性作相应的处理:如果噪声基元段的总长度未超出噪声的长度上限, 则将其归并入邻近的非噪声基元中;否则将其中的所有噪声基元合并为一个新基元, 新基元的类型
式中wi表示第i基元的长度;ti表示第i基元的类型;ti=0或1。
《1.2.3 基元序列及其提取》
1.2.3 基元序列及其提取
通过对1992式机动车牌照的分析, 车牌纹理区域对应的基元段在基元数量、长度、类型分布等方面具有不同于基元链中其他部分的特征, 具备这些特征的基元段称为基元链中的特征基元序列 (简称基元序列) 。
正常情况下, 车牌中字母、数字的笔画上下贯通, 与水平扫描线的交点数量在1~3个之间;对于汉字, 可能与部分扫描线无交点, 但有交点时交点的数量也有一定限度, 其最大值一般不会超过5。基元序列的最大长度和最小长度分别取决于牌照区域的最大宽度和最小宽度。此外, 受车牌字符的排列方式及笔画分布规律的约束, 基元序列中基元的长度也不会超过一定的上限。
为提高基元序列提取的效率, 笔者将搜索的目标由基元序列改为其最大分序列。为此, 先定义以下三个概念。
1) 分序列:
基元序列中的特定片段, 其首尾基元的类型相同。
2) 主基元:
分序列组成基元中与首尾基元同类型者称为主基元, 分序列类型即为主基元类型。
3) 最大分序列:
出自同一基元序列且类型相同的各分序列中长度最大者称为最大分序列。一个基元序列包含两个不同类型的最大分序列, 分别对应于它的两种基元类型。
搜索最大分序列的基本方法是首先在基元链中标记出当前类型的所有基元, 然后检查以这些基元为端点的各基元片段是否满足最大分序列的长度、数量等特征条件, 在同起点的合格基元片段中选择最长的一个作为该类型该起点的最大分序列。
基元的长度, 除了要求其最大值不超过片段总长度的一定比例外, 还要考察其波动程度。波动程度用片段内基元长度的标准差式 (4) 与平均值式 (3) 之比式 (5) 来衡量。经统计分析, 牌照区域内的基元长度标准差与平均值之比r不会大于一定限度。
基元长度的平均值为
基元长度的标准差为
比值为
式中xi表示片段中i基元的长度;n为基元总数。
基元序列包含主基元类型不同的两个最大分序列, 它们都将被检测到, 但其代表的内容是重复的, 因此必须进行合并以产生唯一的基元序列。合并的基本方法是取并集, 若并集区间的长度超限, 则不进行合并, 认为两个最大分序列分别代表不同的基元序列。
《1.3基元序列的生长》
1.3基元序列的生长
在行扫描时, 如果新生成的基元序列与此前已有的基元序列满足匹配条件, 可将两序列按一定的规则合并。合并产生的新实体仍具有基元序列的基本属性, 可将其看作扩展了区域范围的基元序列 (或称序列区域) 。重复上述操作, 直至扫描完毕, 这一过程称为基元序列生长。
《1.3.1 基元序列的匹配条件》
1.3.1 基元序列的匹配条件
新生的基元序列与已有序列的匹配条件是两者在水平方向应存在近似包含关系。
设基元序列A, B的水平范围分别为[A1, A2]和[B1, B2] (A1<B2, B1<A2) , 则有:
两者交集的长度为
若 (min (lhA, lhB) -lhA∩B) /lhA∩B≤δ , 则基元序列A, B的水平方向存在近似包含关系。其中, δ为预定义阈值, 0<δ<1。
与某个已有基元序列存在近似包含关系的新生基元序列可能不止一个, 必须从中选出“最佳”的一个作为匹配对象。本文提出综合距离指标, 与已有序列综合距离最小的新生基元序列就是最佳匹配对象。两个基元序列A, B间的综合距离按式 (6~9) 计算。
中心点间的距离为
综合距离为d=ds+de+dm (9)
《1.3.2 基元序列的合并》
1.3.2 基元序列的合并
满足匹配条件的两基元序列, 根据不同情况, 按以下规则进行合并:
1) 新生序列的长度与已有序列区域的长度相近。合并后的序列区域取二者的最小外接矩形。若外接矩形的宽度超过牌照区域的最大宽度值, 则取两序列中较宽一个的水平范围作为合并后序列区域的水平范围。
2) 新生序列的长度明显大于已有的序列区域。已有的序列区域在合并该新生序列时其水平范围保持不变, 只在垂直范围上取并;同时, 该新生序列作为一个潜在的新纹理区域的起始位置被保留。
3) 新生序列的长度明显小于已有的序列区域。合并产生垂直范围相同、而水平范围不同的两个新区域, 一个取已有序列区域的水平范围, 另一个取新生序列的水平范围。
《2 牌照区域提取》
2 牌照区域提取
经过上节纹理分析得到的序列区域是牌照的候选区域, 为了提取出车牌区域, 需进一步对候选区域进行筛选。候选区域筛选的基本思路是考察这些区域与理想车牌图像区域之间的相似程度。本文将候选区域与理想车牌区域之间的相似程度用区域某些有代表性特征的隶属度来表征, 采用区域的竖笔画特征、位置特征、形状特征等来描述车牌区域。
《2.1区域竖笔画特征及其提取》
2.1区域竖笔画特征及其提取
通过观察可以发现, 上节算法提取出的候选区域主要包括牌照区域、斑块区域和条纹区域 (见图3) 。本文采用“竖笔画”特征来区分这三类区域, 基于小波分析方法提取竖笔画特征。所谓竖笔画, 是指图像区域内长度 (实际为垂直延伸度) 及水平偏移程度满足一定要求的纵向条纹。
对图像f (x, y) 进行正交小波分解
式中g (·) 和h (·) 分别为与小波函数对应的重构高通和低通滤波器;j=1;kd为加权系数, 0.4≤kd≤0.5。
提取竖笔画特征的过程如下:首先将候选区域图像放大至64×640, 并进行细化处理, 然后对图像进行小波分解, 得到D22jf和D32jf, 用式 (10) 重构竖笔画特征图像。小波基函数采用Daubechies小波函数db4。重构得到的竖笔画可能存在一些断点, 本文对竖笔画图像二值化, 然后采用形态学
通过对车牌竖笔画图像的分析, 垂直延伸度达到区域高度1/3以上, 水平偏移量不超过一个字符宽度的竖笔画数n在7至16之间 (相交的笔画只计一次) , 其灰度均值h在10至30之间。候选区域与理想车牌区域的竖笔画特征的接近程度可用隶属函数μV (n, h) 表示。μV (n, h) 由竖笔画数隶属函数μN (n) 和灰度均值隶属函数μH (h) 按式 (11~13) 求得。
μN (n) 和μH (h) 的表达式分别为
式中:n为竖笔画数;n0和n1为常数, 取值分别为4和18左右。
式中h为区域竖笔画图像灰度均值;h0和h1为常数, 取值分别为0和45左右。
通过隶属函数求出隶属度, 根据隶属度可很好地将牌照区域与斑块区域和条纹区域区分开。图4中, 牌照区域的隶属度为1, 斑块区域和条纹区域区的隶属度均为0。
《2.2区域位置特征》
2.2区域位置特征
实际应用中, 牌照区域在整个车辆图像中的位置相对固定, 处于一定范围内。可将区域的位置作为候选区域的特征。矩形区域在图像中的位置可用其中心点的坐标 (x, y) 来表示。候选区域位置与理想车牌区域的接近程度可用隶属函数μW (x, y) 表示。μW (x, y) 由式 (14~16) 求得。
式中[x1, x2]和[x0, x3]分别是牌照区域中心点水平坐标的理想区间和极限区间; [y1, y2]和[y0, y3]分别是牌照区域中心点垂直坐标的理想区间和极限区间, 具体数值依据摄象机与汽车之间的相对位置确定。
《2.3区域形状特征》
2.3区域形状特征
1992式机动车牌照 (大型汽车、小型汽车的前牌) 中, 牌照区域的高度为90 mm, 长度为440 mm, 宽高比为4.89。牌照编号区域的长度为409 mm, 相应的宽高比为4.54。可以认为区间[4.54, 4.89]是车牌区域宽高比的理想范围。宽高比可作为候选区域的形状特征。
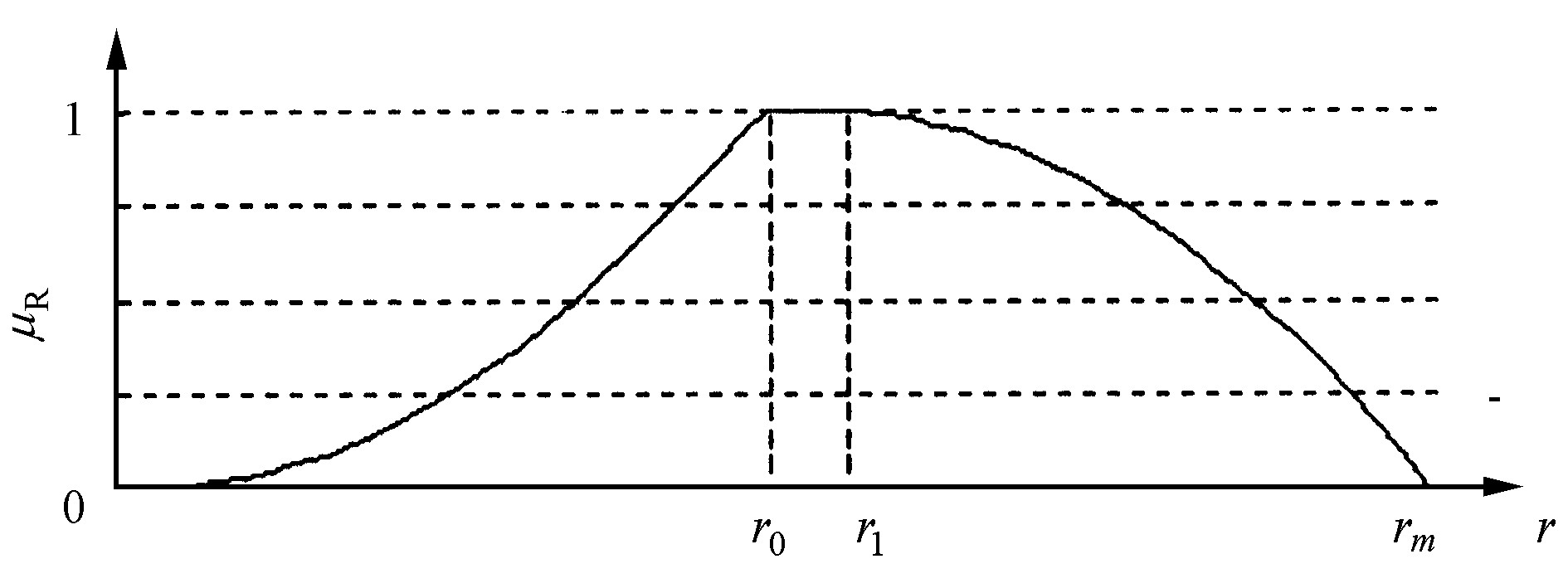
候选区域宽高比与理想牌照区域宽高比的接近程度可用隶属函数μR (r) 表示。由于采用上节纹理分析的车牌定位算法分割出的纹理区域在宽度方面容易偏大, 因此区域的宽高比常略高出其真实值。考虑这一特点, 应使隶属度向偏高的比例值倾斜, 设计宽高比的隶属函数如式 (17) , 函数曲线如图5所示。
式中:r为区域的宽高比;r0=4.54;r1=4.89;rm=r0+r1。
《2.4车牌区域的提取》
2.4车牌区域的提取
对候选区域依据一定的规则进行比较, 最终选出最优区域作为车牌区域。候选区域的比较, 依据区域的中心位置自下而上进行。根据实验观察, 大多数干扰区域位于牌照区域之上, 将比较规则向位置在下的区域倾斜, 可以有效地排除这些干扰。设当前的最优区域为A, 与其进行对比的区域为B, A与B的中心位置坐标分别为 (xA, ya) 和 (xB, yB) , 且yB≥yA;宽高比分别为rA和rB;竖笔画特征图像的竖笔画数、区域灰度均值分别为nA, nB和hA, hB, 则比较规则根据A, B之间的位置关系, 分为以下两种情况:
1) B完全在A之上。若μW (xB, yB) +μR (rB) +ksμV (nB, hB) >k (μW (xA, yA) +μR (rA) +ksμV (nA, hA) ) , 则B优于A。其中k和ks为加权系数, 1.5<ks<2.5, 1<k<1.5。
2) 其他情况。若μW (xB, yB) +μR (rB) +ksμV (nB, hB) >μW (xA, yA) +μR (rA) +ksμV (nA, hA) , 则B优于A。
运用上述规则对所有候选区域进行比较后, 最终可以提取出车牌区域。最后根据总隶属度μ, 按以下规则对提取的区域进行检验:
若μ≥kδ1, 且μV (n, h) ≥kδ2, 则可确认该区域为车牌区域;否则, 拒绝该区域。其中, μ= (μV (n, h) +μW (x, y) +μR (r) ) /3;kδ1, kδ2为阈值, 0.6≤kδ1≤1, 0.6≤kδ2≤1。
《3 结语》
3 结语
针对目前国内使用的1992式车牌, 笔者提出了基于纹理与小波分析的车牌定位方法, 结合车牌的位置和几何特征, 实现了车牌自动定位, 为车牌识别系统提供了一种实用的车牌定位方法。采用本文的方法, 对公路收费站现场拍摄的371幅图像进行了测试, 定位正确率达到96.23%, 错误率1.08%, 拒绝率2.69%。造成定位错误与拒绝的主要原因是车牌严重污损。测试结果表明, 笔者所提出的方法具有优良的定位性能和很强的实用性。











 京公网安备 11010502051620号
京公网安备 11010502051620号




