

《1 前言》
1 前言
路径规划技术是机器人自主导航的关键支撑技术之一,是指在具有障碍物的环境内按照一定的评价标准,如最小工作代价、最短路径等,从起始位置到达目标位置搜索一条无碰路径[1] 。近年来,随着人工智能的发展,模糊逻辑[2] 、遗传算法[3] 、蚁群算法[4] 等方法在路径规划中的应用取得了很大的进展,显示出较好的鲁棒性和全局优化能力。但模糊逻辑存在经验不完备性;遗传算法编码复杂、效率低;蚁群算法的路径发现能力受限于栅格大小的划分[5] 。从路径规划发展来看,仿生智能算法是主要应用趋势。
由生物免疫系统启发而来的人工免疫系统,因其自组织、自学习和免疫记忆等优点为解决工程问题尤其是机器人技术提供了新契机[6] 。20世纪80年代,Farmer等人基于免疫网络学说给出了免疫系统的动态模型[7] 。基于该动态模型,1996年日本学者Ishiguro等[8] 率先提出了一种行为仲裁系统,并在垃圾自动回收上得到评估。Meshref 等[9] 实现了分布式自主机器人系统中的狗羊放牧问题。Farmer模型体现了较好的鲁棒性和柔韧性,但是缺乏全局优化能力。基于生物免疫网络理论,文献[10]设计了一种新的机器人路径规划算法。该算法通过学习获取规则和清晰规则,具有很强的空间搜索能力和规则发现与再学习能力,但在搜索精度和路径收敛性能方面还有待进一步提高。为了更好地解决复杂环境中的移动机器人路径规划问题,本文提出了一种改进的基于势场导向权的人工免疫网络路径规划算法。
《2 人工免疫网络规划模型及其定义》
2 人工免疫网络规划模型及其定义
《2.1 生物免疫系统》
2.1 生物免疫系统
生物免疫系统是高等脊椎动物体内能够识别和排除抗原性异物、保护机体内免受损害及维持体内环境稳定的极为复杂的生物学系统。生物免疫学发展至今已经取得了不少研究成果,但人类对自然免疫系统的认识还不是十分充分。目前被普遍接受的理论主要有克隆选择和独特型网络。后者是1973年由丹麦学者Jerne在克隆选择的基础上提出[11] ,其原理如图1所示。由图1可看出,免疫系统是由淋巴系统网络所组成,淋巴细胞之间通过通讯来完成免疫系统任务。抗体 Ab1的独特位 Id1通过 Ab2的侧位 P2刺激 B 细胞 2,而从抗体 2 的角度看, Ab1的Id1相当于抗原,因此与抗体Ab1相关的B细胞将受到Ab2抑制。而Ab3的Id3相对于Ab1而言又是抗原,Ab1又将受到Ab3刺激。整个网络成员通过相互刺激与抑制构成一个闭环链,具有识别自身和非自身的分辨能力。
《图1》
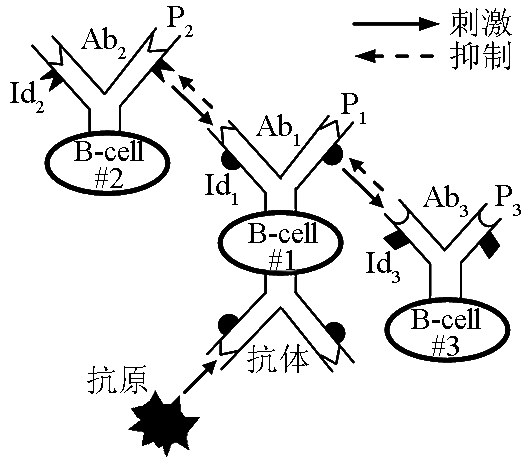
图1 独特型网络模型
Fig.1 Jerne’s idiotypic networks
《2.2 人工免疫网络路径规划模型》
2.2 人工免疫网络路径规划模型
为了实现移动机器人的免疫路径规划,本文将移动机器人所处环境作为抗原,抗原的表位是包含障碍物和目标信息的环境信息。将机器人的移动行为作为抗体,抗体的独特位同样是环境信息,对位是机器人运动命令。抗原和抗体匹配称为刺激,不匹配称为抑制,主要通过抗原抗体的亲和度来衡量。
借鉴Jerne的独特型免疫网络模型,本文构建如图2所示的人工免疫网络规划模型(各抗体下方用不同形状表示其独特位和对位)。不失一般性,本文将路径规划问题研究限制于室内平面环境中。对应的免疫智能体是如图3所示的一个虚拟全方位平面移动机器人。机器人四周配备8个虚拟传感器,检测方向为1~8,检测距离分近、中、远。机器人可以按8个命令C={ ,b,c,d,e,f,g,h }运动,分别代表{前进、左前进、右前进、左平移、右平移、左后退、右后退、后退},当机器人到达目的地时采用停止命令。机器人从起点S 出发,根据抗原抗体的匹配进行空间搜索直至终点G[12] 。因此从起点到终点将形成一个人工免疫网络,抗体的连接取决于机器人所在环境以及运动命令清晰度。路径规划的实质就是要找到由抗体构成的一个内图,该内图所描述的机器人运动轨迹是最优的。
,b,c,d,e,f,g,h }运动,分别代表{前进、左前进、右前进、左平移、右平移、左后退、右后退、后退},当机器人到达目的地时采用停止命令。机器人从起点S 出发,根据抗原抗体的匹配进行空间搜索直至终点G[12] 。因此从起点到终点将形成一个人工免疫网络,抗体的连接取决于机器人所在环境以及运动命令清晰度。路径规划的实质就是要找到由抗体构成的一个内图,该内图所描述的机器人运动轨迹是最优的。
《2.3 基本定义》
2.3 基本定义
为了便于人工免疫网络规划算法的描述,首先给出如下基本定义[5] 。
《图2》
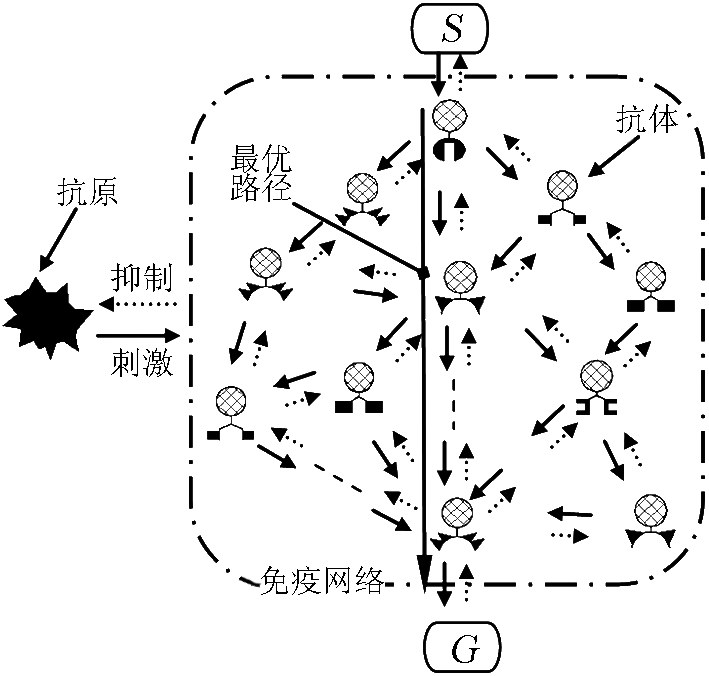
图2 人工免疫网络规划模型
Fig.2 Planning model of artificial immune
《图3》
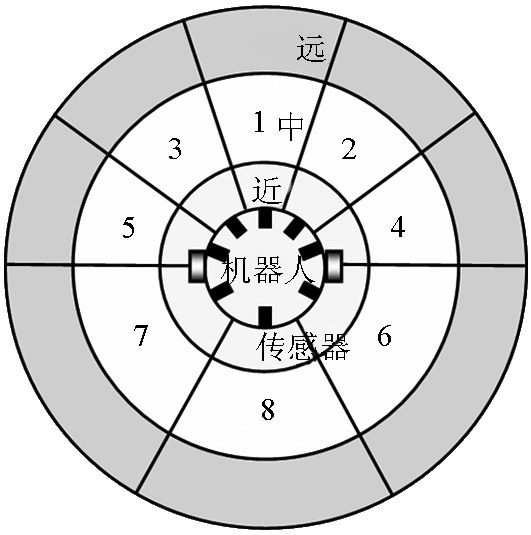
图3 免疫智能体
Fig.3 Immune agent
定义1:抗原(Ag)代表机器人所处室内平面环境。

式(1)中,IAgO 为障碍物信息,按照传感器检测方向和距离编码, IAgO =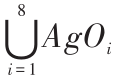 。
。 ,AgOi ∈{00,01,10,11},集合元素分别表示 i 方向无障碍、近距离障碍、中等距离障碍和远距离障碍。IAgG 为目标信息,按照检测方向编码,IAgG =
,AgOi ∈{00,01,10,11},集合元素分别表示 i 方向无障碍、近距离障碍、中等距离障碍和远距离障碍。IAgG 为目标信息,按照检测方向编码,IAgG =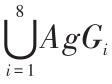 。 ,AgGi ∈{0,1},集合元素分别表示i 方向无目标和有目标。
。 ,AgGi ∈{0,1},集合元素分别表示i 方向无目标和有目标。
定义2:抗体(Ab)代表机器人针对环境信息产生的对应行为。
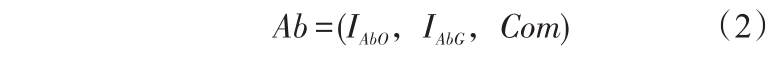
式(2)中,IAbO 为障碍物信息,IAbO =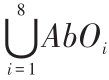 ,,AbOi ∈{00,01,10,11}。IAbG 为目标信息,IAbG =
,,AbOi ∈{00,01,10,11}。IAbG 为目标信息,IAbG =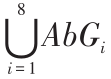 ,,AbGi ∈{0,1},集合元素定义同抗原;Com 为运动命令,Com ∈C 。
,,AbGi ∈{0,1},集合元素定义同抗原;Com 为运动命令,Com ∈C 。
定义3:用抗原抗体的亲和度ζ 来描述抗原抗体的匹配程度。
由图3看出,机器人前方障碍信息比后方的贡献大,而正前方的障碍物信息贡献最大,正后方的贡献最小,机器人左侧和右侧的贡献对称相等。为了体现环境编码中不同位置在抗原抗体亲和度中的不同贡献,本文亲和度定义如下
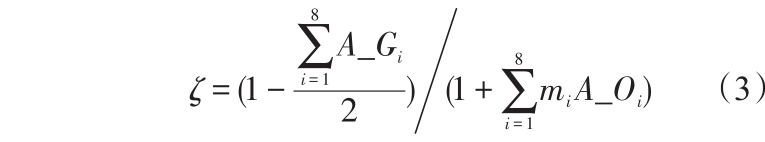
式(3)中,A_Gi 为i 方向抗原和抗体的目标信息的逻辑运算值,即A_Gi =(AgGi ⊕ AbGi );A_Oi 为i方向抗原和抗体的障碍物信息的逻辑运算值,即 A_Oi =(AgOi1 ⊕AbOi1 )+(AgOi2 ⊕AbOi2 );mi 为障碍物信息贡献权值。根据实验,本文分别取{2、0.5、0.5、0.15、0.15、0.1、0.1、0.01}。
《3 人工势场法及其导向权》
3 人工势场法及其导向权
在基于人工免疫网络的路径规划算法中,抗体在抗体网络中的转移效率直接影响到算法的搜索性能。文献[10]按照抗体生命力进行转移概率的设计,但搜索能力和网络收敛性能较差。为了提高抗体的转移效率,文献[5]融合蚁群算法,将命令清晰度和抗体转移后的距离变化作为变量设计了转移概率。文献[12]将势场法的规划结果作为先验知识,对文献[5]中的命令清晰度进行优化,进一步提高了抗体的转移效率。为了更有效地利用势场法并提高抗体的转移效率,本文将人工势场法的规划结果作为导向权,构建了新的抗体转移算子,从而优化人工免疫网络的路径规划算法。
人工势场法是由Khatib于1986年提出来的,其基本思想是:在目标位置构造引力势场Uatt和在障碍物周围构造斥力势场Urep,机器人在Uatt的引力Fatt和 Urep的斥力Frep共同作用下向目标运动。
设X、Xobs、Xgoal分别为机器人、障碍物和目标的位置向量。引力势场通常定义为(4)
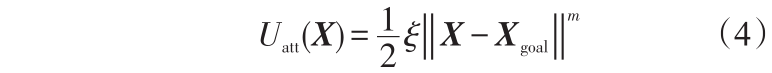
式(4)中,  为欧氏距离;ξ 为引力场正比例系数;m 为引力势场系数(m 取值不同,引力势场形状也不同,通常m 取2)。
为欧氏距离;ξ 为引力场正比例系数;m 为引力势场系数(m 取值不同,引力势场形状也不同,通常m 取2)。
引力通常取引力势场的负梯度
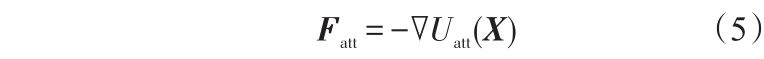
当m=2时, Fatt =ξ 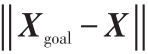
斥力势场通常定义为
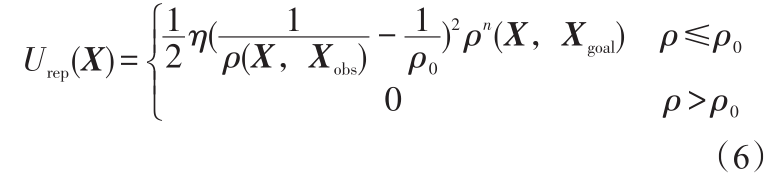
式(6)中,η 为斥力场正比例系数;ρ0 为障碍物影响距离;n 为正常数; 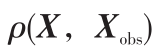 =
=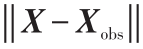 ;
;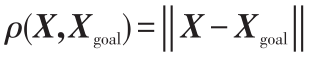 。
。
斥力同样定义为斥力势场的负梯度

式(7)中, ;
; ;
; 为由障碍物指向机器人当前位置的单位向量;
为由障碍物指向机器人当前位置的单位向量;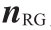 为由机器人当前位置指向目标位置的单位向量。
为由机器人当前位置指向目标位置的单位向量。
根据人工势场法的原理,机器人的避障角度为

设某抗体运动命令方向与x 轴的夹角为θx ,则定义该抗体运动命令的人工势场导向权为
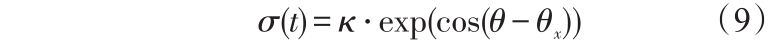
式(9)中,κ 为调整系数。
由式(9)可看出,当抗体命令执行方向与机器人的避障方向越接近,导向权越大。
《4 基于势场导向权的免疫网络路径规划算法》
4 基于势场导向权的免疫网络路径规划算法
《4.1 主要算子》
4.1 主要算子
1)抗体转移算子。为了提高抗体的选择效率,本文将抗体命令清晰度、抗体转移的距离变化和势场导向权作为变量,构建如下的抗体转移概率

式(10)中,τi (t)为抗体第 i 号运动命令的清晰度;α 为抗体命令清晰度启发因子;σi (t)为抗体第 i 号运动命令的导向权;β 为势场导向权启发因子;qi (t)为抗体第i 号命令的目标启发函数;γ为目标启发因子。
qi (t)的表达式如下

式(11)中,Δd 为机器人执行8个命令后与目标点的距离变化结果集合;l 为调整系数,且l > 0。
匹配抗体命令的选择主要通过轮盘赌算法,这既保证了命令选择的合理性,又保证了特殊小概率事件发生的可能性,实现了对抗体命令集遍历选择的可能。
2)抗体命令清晰度学习算子。抗体在转移过程中,往往会产生碰撞或因陷入局部极小而造成的徘徊。为了解决抗体转移过程中存在的上述问题,本文采用式(12)的抗体命令清晰度学习策略。
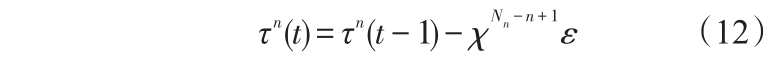
式(12)中,n 为当前所处位置在抗体链中的层数;Nn 为抗体链总层数;χ 为学习可变系数,且 χ< 1;ε 为学习定系数,且ε > 0。
抗体命令清晰度学习的目的是减小造成碰撞和徘徊的抗体运动命令的参与机会,增加其他抗体运动命令的参与机会。
3)抗体命令清晰度更新算子。当完成抗体网络的一次搜索后,需对所选择的相应运动命令予以激励,使其清晰度得到提高。当下次任务遇到同样抗原时,该命令被选择的概率将会增大,从而形成一个正反馈机制。另外,为了保证抗体库的动态特性,所有抗体运动命令的清晰度又将按照一定的遗忘率消逝。这样,随着规划的不断进行,不用的或不合理的抗体运动命令将逐渐死去,可行且较优的抗体命令将被保存下来,从而进一步提高了免疫网络规划算法的搜索速度。在本文中,抗体命令清晰度更新算子定义如下

式(13)中,ρ 为抗体命令清晰度遗忘率;μ 为常数;L 为规划的路径长度。
由式(13)可看出,免疫规划路径越短,说明抗体网络中的抗体执行命令越正确,相应抗体命令获得的激励程度越大,其清晰度也就变得更高。
《4.2 算法流程》
4.2 算法流程
步骤1:初始化参数。包括ξ,η,ρ0,κ,α,β,γ, χ,ε,μ,最大循环次数Tmax等相关参数。
步骤2:初始化规划任务。
步骤 3:抗原识别。提取环境信息,根据式(1)进行抗原编码。
步骤4:抗体匹配。根据式(3)从规则库中寻找大于临界亲和度且为最大的匹配抗体。如果有执行步骤5,否则按照式(2)生成新抗体。
步骤 5:按式(10)计算匹配抗体或新抗体命令集的选择概率,并用轮盘赌算法进行选择实现抗体转移。
步骤 6:判断机器人是否发生徘徊或碰撞。若未发生则执行下一步,否则按照式(12)进行抗体命令清晰度学习并转步骤3。
步骤 7:判断是否到达终点。若没有则转步骤 3,否则保留最优路径解,并按照式(13)进行抗体命令清晰度的更新。
步骤 8:判断是否完成所有循环的搜索。若没有则转步骤2,否则输出最优路径。
《5 仿真实验与讨论》
5 仿真实验与讨论
为了验证本文提出的改进的免疫网络路径规划算法(IINA)的有效性,本文基于MATLAB 7.0语言,针对图4两种室内平面环境进行路径规划实验(其中起点为 S,终点为 G,各种黑色形状为障碍物),并与基本免疫网络算法(SINA)和蚁群算法(ACA)进行了比较。算法收敛条件是:最优抗体(蚂蚁)路径长度连续15代未发生改善。考虑到算法的随机性,每种环境每种算法共进行了30次独立随机实验。在获得局部曲折的最优抗体(蚂蚁)路径后,本文对其进行了平滑处理以适合机器人行走。
《图4》
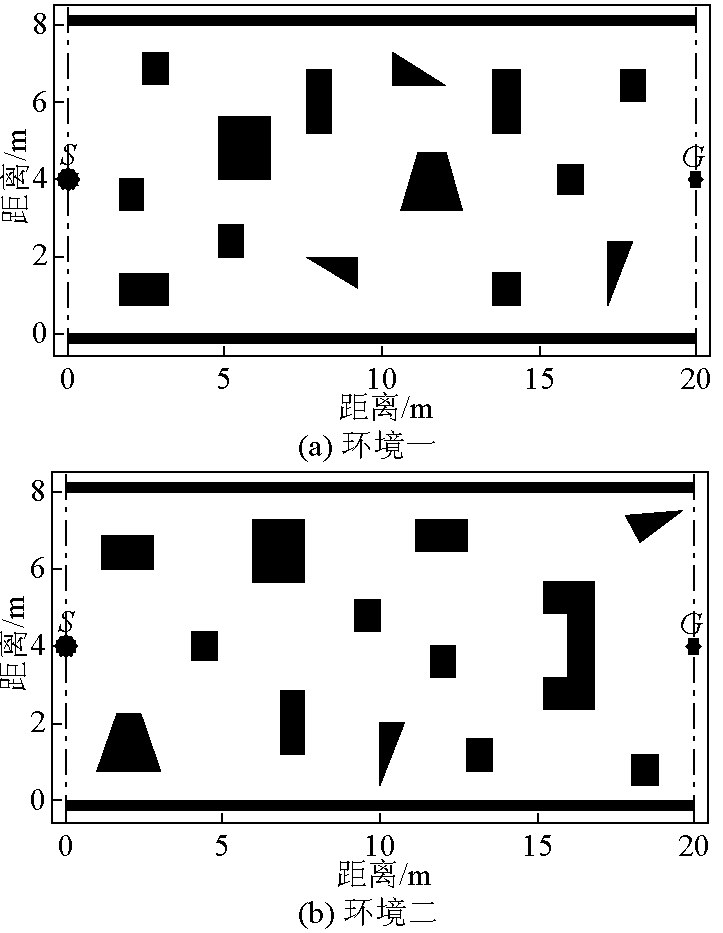
图4 仿真环境
Fig.4 Simulation environments
表1为3种算法的规划性能比较。从4种路径长度来看,SINA路径最长,显示出其全局规划能力较弱,IINA引入了势场法,并将其规划结果作为先验知识构建了引导权,从而设计了新的抗体转移概率,较好地提高了抗体的转移效率,使得IINA的规划能力明显优于 SINA。ACA 具有全局优化能力,其信息素的正反馈机制增强了其优化能力,使得其规划路径整体上优于 SINA,但劣于 IINA。从平均收敛代数看,SINA 虽收敛最快,但仅一种局部收敛,而基于势场导向的抗体转移加快了算法的收敛速度,使其收敛性能优于ACA。
《表1》
表1 3种算法的性能比较
Table 1 Performance comparison among three algorithms
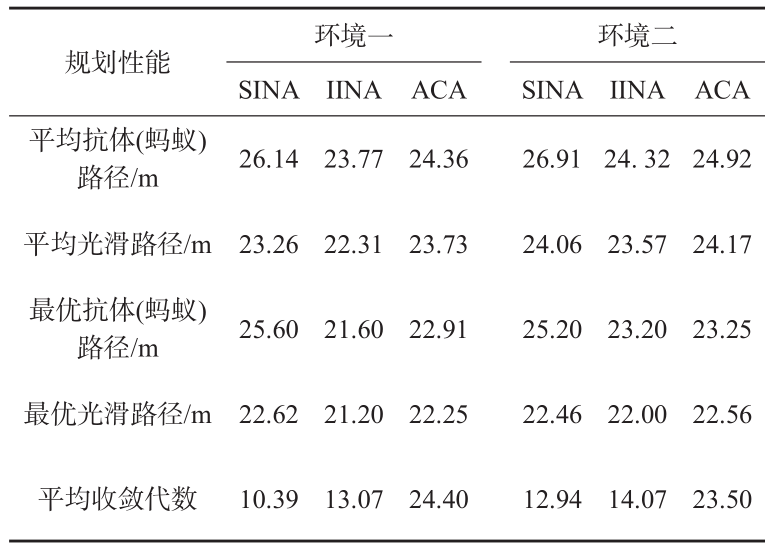
图 5 为 3 种算法在两种环境下的平均收敛曲线。由图 5 可看出,SINA 的平均规划性能最弱; IINA 有了明显的提高,既具备了与 ACA 相似的收敛速率,且其规划性能是3种优化算法中最优的。
《图5》
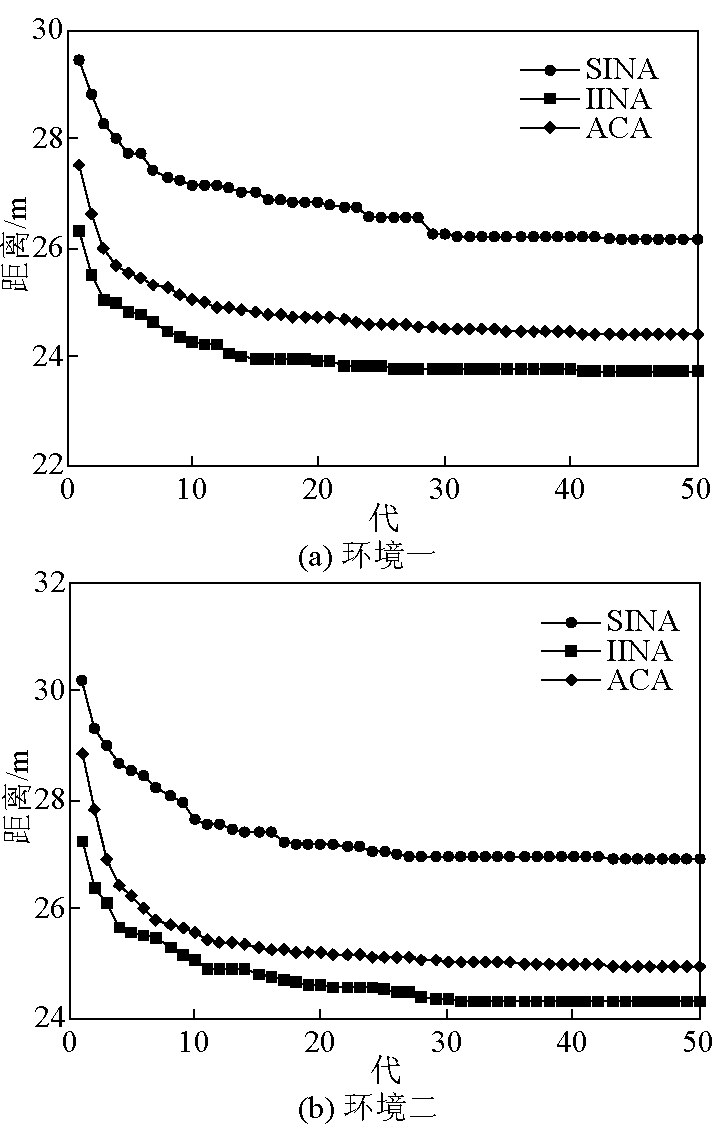
图5 3种算法的平均收敛曲线
Fig.5 Average convergence curves of three algorithms
图6给出了3种算法在环境二里的最优规划结果及对应的光滑路径。由图6可看出,3种算法都能找到各自最优路径,显示出较好的鲁棒性和柔韧性,IINA所规划的路径长度最短。
《图6》
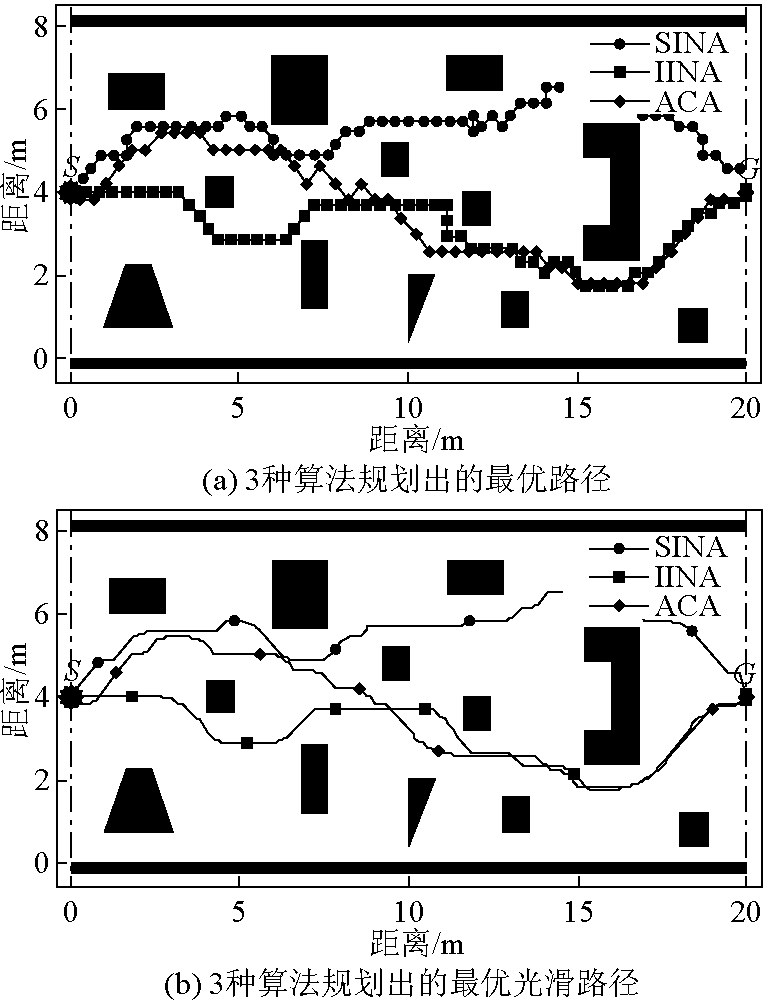
图6 环境二中3种算法的最优规划结果
Fig.6 Optimal planning results of three algorithms in environment II
《6 结语》
6 结语
基于生物免疫学的人工免疫系统,由于其自组织、自学习、自识别和自记忆能力,为路径规划研究开辟了一个新的领域。为了解决复杂环境中移动机器人的自主导航问题,本文基于丹麦学者Jerne的独特型网络假设,构建了免疫网络规划模型。为了进一步提高免疫网络规划模型中抗体的转移效率,研究中引入了计算量小、实时性好的人工势场法,将其规划结果作为先验知识,设计了基于势场导向权的改进人工免疫网络路径规划算法。实验结果表明,在最优规划能力和网络收敛性能方面,新算法IINA比SINA有了明显提高,在解决移动机器人的路径规划问题上具有较好的应用前景。











 京公网安备 11010502051620号
京公网安备 11010502051620号




