

《1 引言》
1 引言
概念性流域水文模型广泛应用于洪水预报和水资源管理等众多领域,模型模拟的效果如何除了模型结构的合理性外,模型参数的选择至关重要,其通常作法是通过调整水文模型参数值,得到一组参数,使模型的输出尽可能的接近实际观测值。水文模型参数优选一直是水文预报的重要内容,国内外研究较多的水文模型参数优选方法主要有单纯形法、 SCE - UA[1] 、遗传算法[2] 等。其中 Duan 等人于 1992 年提出的 SCE - UA 算法结合了单纯形法、随机搜索和生物竞争进化等方法的优点,可以一致、有效、快速地搜索到水文模型参数全局最优解,因在水文模型参数优选中得到了广泛的运用 [1 , 3] 。然而传统的水文模型参数优选方法一般采用单一的目标函数(如实测与模拟水文过程的离差平方和)来评价模型参数的好坏,往往不能恰当地描述由观测资料所反映出来的各种水文特征。例如,在作水库入库洪水预报时,人们不仅关心洪峰流量和峰现时间的预报精度,而且还关注洪量和洪水过程线的预报结果;另外,现代水文预报模型能模拟出流量以外的许多可观测变量,如温度、土壤含水量以及其他一些物理化学变量[4] 。用单一目标函数优选出来的参数常常无法同时满足上述这些要求,因此,研究探讨多目标参数自动优选方法,在理论和实践中均具有重大的现实意义[5] 。
结合 SCE - UA 搜索策略和陈守煜的多目标模糊优选理论[6] ,提出了水文模型参数模糊多目标 SCE - UA 优选方法。通过对湖南省双牌水库新安江模型参数率定应用实践表明,由该方法优选得到的参数用于实际作业预报是完全可行的,且比标准 SCE - UA 算法更能反映流域水文特征,使得模型输出流量与实测流量过程更加吻合。
《2 水文模型参数模糊多目标 SCE - UA 优化》
2 水文模型参数模糊多目标 SCE - UA 优化
《2.1 目标函数》
2.1 目标函数
目标函数用来评价实测流量与模拟流量过程的吻合程度,不同的目标函数用来评价水文过程的不同特征,目标函数的选择对优选结果至关重要。根据水文水情预报规范,洪峰流量、峰现时间及场次洪水总量合格率是评判参数率定好坏的重要标准。因此定义以下几个常用的目标函数[7] 。
总体水量误差

用以评价总体流量是否平衡;
均方差

用以评价实测与模拟流量过程线的吻合程度;
洪峰流量均方差


用以评价实测与模拟洪峰流量的吻合程度;
峰现时差
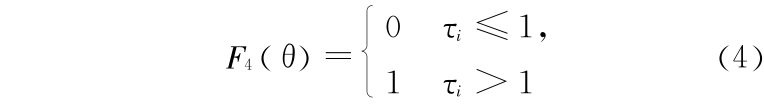
式中  为实测流量序列,
为实测流量序列, 为模拟的流量序列,N 为流量序列数,Mp 为洪峰个数,
为模拟的流量序列,N 为流量序列数,Mp 为洪峰个数, 为第 j 个洪峰过程序列数,
为第 j 个洪峰过程序列数, 为峰现时差(时段数),θ 为待优选参数矢量。
为峰现时差(时段数),θ 为待优选参数矢量。
《2.2 Pareto 解集》
2.2 Pareto 解集
水文模型多目标参数优选目标函数可表示为 F(θ)={ F1(θ),F2(θ),…,Fm (θ)},各目标函数之间互相制约,往往没有一个点比其他所有点绝对最优,问题的解并非唯一,而是由许多可行解组成的集合,即 Pareto 解集(或非劣解) [4 , 8] 。根据定义, Pareto 解集中任一 θp 具有以下特性:
1)对于任意非 Pareto 解 θd ,必存在一 θp ,使得 Fk(θp)< Fk(θd),k = 1 ,2 ,…, m。
2)在 Pareto 解集中不存在最优解 ,使得 Fk()<Fk(θp), k = 1 ,2 ,…, m 。
,使得 Fk()<Fk(θp), k = 1 ,2 ,…, m 。
《2.3 多目标模糊优选》
2.3 多目标模糊优选
假设满足约束条件的待优选参数样本个数为 n ,目标函数个数为 m ,第 j 个样本的目标函数用 xij (i = 1 ,2 ,…,m ; j = 1 ,2 ,…,n)表示,则可得到有限样本的多目标评价矩阵  ,水文模型多目标参数优选问题可用多目标模糊优选模型进行求解。为了增加可比性,需要对目标规格化,收益类目标采用
,水文模型多目标参数优选问题可用多目标模糊优选模型进行求解。为了增加可比性,需要对目标规格化,收益类目标采用
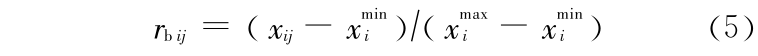
成本类目标采用

式中  ,
, 
 。根据陈守煜教授提出的多目标模糊优选理论,建立多目标模糊优选模型目标函数[9]
。根据陈守煜教授提出的多目标模糊优选理论,建立多目标模糊优选模型目标函数[9]

其中  。
。
《2.4 模糊多目标 SCE - UA 算法》
2.4 模糊多目标 SCE - UA 算法
Duan 等人于 1992 年提出的 SCE - UA 算法结合了单纯形法、随机搜索、生物竞争进化以及混和分区等方法的优点,可以一致、有效、快速地搜索到水文模型参数全局最优解[1] 。笔者在 SCE - UA 算法的基础上,结合 Pareto 排序和多目标模糊优选的优点,提出了模糊多目标 SCE - UA 算法(FMOSCE - UA , fuzzy multi-objective SCE - UA),其基本流程如图 1 所示。
《图 1》

图 1 模糊多目标 SCE - UA 算法流程图
Fig.1 Flowchart of the FMOSCE-UA algorithm
主要步骤如下:
Step 1 初始化,首先确定水文模型参数个数 n ,种群规模 s ,种群的分区数目 p ,每个分区的样本数 m = s/p ,以及总循环次数 L 。
Step 2 根据决策变量(水文模型参数)的先验分布,生成 s 个样本{θ1 ,θ2 ,…,θs },对每个样本求出其目标函数 F(θi),u(θi)。在缺乏先验知识的情况下,先验分布一般定为均匀分布。
Step 3 按照目标函数值 u(θi)从高到低的顺序,将 s 个样本的信息存储在数组 D[1 : s , 1 : n + h + 1]中,其中第 1 到 n 列存储水文模型参数向量,第 n +1到 n + h 列存储目标函数值 Fj (θi),第 n + h + 1 列存储目标函数值 u(θi),h 为目标函数个数。
Step 4 将整个种群 D 分成 p 个分区,C 1 ,C 2,…,C p,每个分区包含 m 个样本,Ck = D [ p(j -1)+ k ,1 : n + h + 1],j = 1 ,2 ,…,m 。 Step 5 对每个分区采用 FMOSCE (fuzzy multi- objective competitive complex evolution)算法进行独立并行演化计算。 FMOSCE 算法基本流程见图 2 。
《图 2》

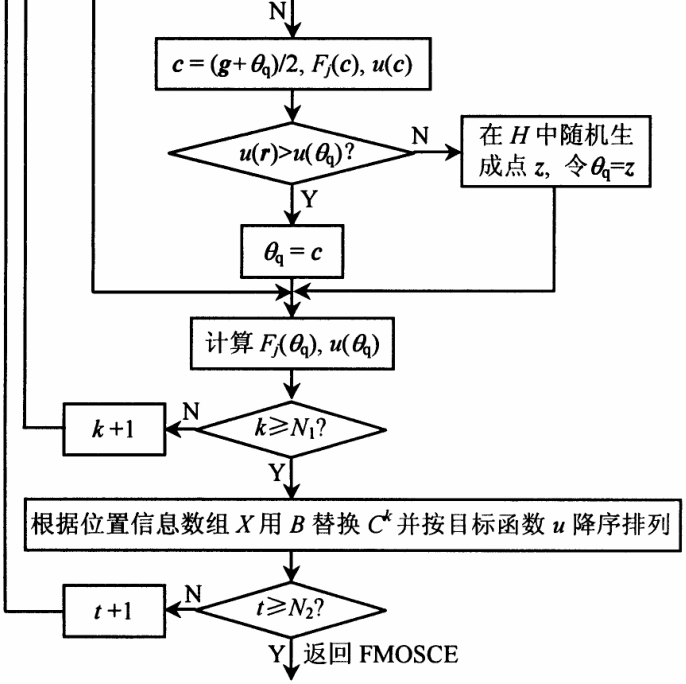
图 2 FMOSCE 算法流程图
Fig.2 Flowchart of FMOSCE strategy of the FMOSCE-UA algorithm
Step 6 将更新后的种群分区 Ck 进行混合,按照目标函数值u(θi)从高到低的顺序将所有 s 个样本重新排列,重新构造数组 D 。
Step 7 如果满足收敛条件或者累计循环次数达到总循环次数 L ,终止循环;否则返回 Step 4 。若累计循环次数达到总循环次数 L 但未得到优化结果,终止循环后提示用户调整参数重新进行计算。
FMOSCE 算法的主要步骤如下:
Step 1 初始化。输入 q ,N1,N2 ,2  q m ,N1,N2
q m ,N1,N2  1 。
1 。
Step 2 Pareto 排序。将分区 Ck 的所有 Pareto 解归为 1 类,然后再将分区 Ck 剩余样本的 Pareto 解归为 2 类,依次类推,直到将分区 Ck 的所有样本归类。也就是说分区 Ck 的每个样本都分配了一个值 ra ∈[1,Rmax ],Rmax m ,ra 越小越接近 Pareto 解。
Step 3 给 Ck 每个样本分配一个选择概率。
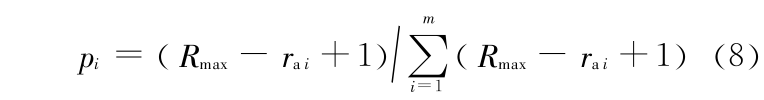
Step 4 根据选择概率 pi 从 Ck 中随机选择 q 个不同样本存入数组 B [1 : q ,1 : n + h + 1],将各样本在数组 Ck 的位置存入数组 X 。
Step 5 按照以下步骤生成子孙:
Step 5a 按照目标函数值 u(θi)从高到低的顺序对数组 B 和 X 排序,并计算

Step 5b r = 2 g - θq 。
Step 5c 如果 r 落在参数空间 Ω 内,则计算 Fj(r),u(r),跳到 Step 5d ;否则计算包含 Ck 的最小空间 H  Rn ,在 H 中随机生成点 z ,令 r = z ,Fj(r)= Fj(z),u(r)= u(z)。
Rn ,在 H 中随机生成点 z ,令 r = z ,Fj(r)= Fj(z),u(r)= u(z)。
Step 5d 如果 u(r)> u(θq),用 r 代替 θq,跳到 Step 5f ;否则计算 c =(g +θq)/2 ,Fj(c),u(c)。
Step 5e 如果 u(c)> u(θq),用 c 代替 θq ,跳到 Step 5f ;否则在 H 中随机生成点 z ,计算Fj(z),u(z),用 z 代替 θq 。
Step 5f 重复 Step 5a … Step 5e N1 次。
Step 6 根据位置信息数组 X 用数组 B 替换原数组 Ck ,并对 Ck 按照目标函数值 u(θi)从高到低排序。
Step 7 重复步骤 Step 2 … Step 6 N2 次。
《3 应用实例 》
3 应用实例
双牌水库位于湘江支流消水下游,集水面积为 10 594 km2 ,该流域处在亚热带季风气候区,暖湿多雨,多年平均降雨量1 500 mm ,多年平均流量 300 m3/s ,双牌水库洪水预报通常采用三水源新安江模型[10] 。采用双牌水库 1985 — 1995 年共 30 场洪水进行参数率定,并以 1999 — 2000 年 11 场洪水对优选参数进行校核。
模糊多目标 SCE - UA 算法采用的参数为:目标函数采用 2.1 节介绍的按照水文水情预报规范定义的 4 个目标函数,即 h = 4 ;目标函数权重向量取 w ={0.25 0.25 0.25 0.25};模型参数个数 n =16 ,根据文献[1] 推荐参数取值;每个分区的样本数 m = 2n + 1 ,每个区抽取的样本数 q = n + 1(作为父样本进行进化计算),N1 = 1 ,N2 = 2n + 1 ,分区数 p = 8 。双牌水库三水源新安江模型 FMOSCE - UA 参数优选结果如表 1 所示,采用该优选参数对用于率定和检验的历史洪水分别进行模拟,其洪水模拟结果的性能指标分别见表 2 和表 3 。
《表 1》
表 1 参数优选结果
Table 1 Results of parameters value calibrated by FMOSCE - UA

《表 2》
表 2 参数优选率定洪水性能指标
Table 2 Performance of calibrated floods by FMOSCE - UA



《表 3》
表 3 参数优选检验洪水性能指标
Table 3 Performance of validated floods by FMOSCE - UA

新安江模型参数优选成果统计:峰值相对误差合格 25 次,合格率为 83.3 % ;峰现时间合格 27 次,合格率为 90.0 % ;场次洪水总量误差合格 28 次,合格率为 93.3 % 。
新安江模型优选参数校核成果统计:峰值相对误差合格 10 次,合格率为 90.9 % ;峰现时间合格 11 次,合格率为 100 % ;场次洪水总量误差合格 10 次,合格率为 90.9 % 。从 1999 年和 2000 年的实际洪水资料的检验成果来看,该优选参数完全可以用于实际洪水预报。
表 4 列出了双牌水库三水源新安江模型分别采用模糊多目标 SCE - UA 算法和标准 SCE - UA 算法(目标函数采用确定性系数)参数优选结果对历史洪水的模拟成果。由表 4 可以看出,不管采用 FMOSCE - UA 或是 SCE - UA 的参数优选结果,其洪量合格率相差不大,但是峰差和峰现时间合格率 FMOSCE - UA 比 SCE - UA 有较大的改善。这是因为 FMOSCE - UA 综合考虑了流量过程均方差、洪峰流量均方差以及峰现时差等表征水文过程的不同特征的目标函数,使得优选的参数更能反映流域水文特征,模拟流量与实测流量过程更加吻合。
《表 4》
表 4 FMOSCE - UA 和 SCE - UA 算法结果对照表
Table 4Comparison of model’s output statistics by FMOSCE - UA and SCE - UA

《4 结语》
4 结语
在 SCE - UA 算法的基础上,结合 Pareto 排序和多目标模糊优选的优点,提出了模糊多目标 SCE - UA 算法。模糊多目标 SCE - UA 算法继承了 SCE - UA 算法定期洗牌的策略,增强了分区间的信息共享,在分区进行进化计算时,用 FMOSCE 算法代替了 CCE 算法,分区内样本的选择概率按照 Pareto 归类分配,同一类的样本被选中作为父样本的概率相等,这样可以保证样本的多样性,达到更好的全局收敛效果。另外,样本按照模糊多目标函数的方式,更全面的考虑了流量过程均方差、洪峰流量均方差以及峰现时差等水文过程的不同要素,使得优选的参数更能反映流域水文特征,模型输出流量与实测流量过程更加吻合。由于模糊多目标 SCE-UA 算法采用各分区独立进化的策略,可以充分利用并行计算的优点,大大提高算法的计算速度和求解质量。











 京公网安备 11010502051620号
京公网安备 11010502051620号




