

《1 引言》
1 引言
预测或预报, 特别是中长期预报是自然与技术科学领域内的一个难题, 具有十分重要的理论与实际意义。由于水文现象本身的复杂性, 目前还很难用严密的物理方法对水文现象进行描述, 人们主要借助数理统计方法以及其他一些不确定的方法来描述水文现象, 以弥补物理方法的不足
《2 智能预报模式》
2 智能预报模式
因果联系是客观世界普遍联系和相互制约的表现形式之一。自然界中任何一个或一些现象或因子都会引起另一个或另一些现象或因子的产生。设以y代表多因子作用下的某种现象, 它是人们需要预报的对象, 称预报对象。xi (i=1, 2, …, ) 代表影响y的各种因子, 称预报因子。显然, 预报对象y是多因子作用的结果。
设有n个预报对象组成样本集合, 其特征值向量为y= (y1, y2, …, yn) , 应用规格化公式即预报对象y对模糊概念
进行规格化得到yr= (yr1, yr2, …, yrn) = (yrj) , 式中max yj, min yj分别为预报对象的最大、最小特征值。
每个样本值对应着筛选出的m个预报因子特征值, 对于n个样本, 则有预报因子特征值矩阵:
其中xij为样本j因子i的特征值。由于m个预报因子特征值的物理量纲不同, 且有的预报因子特征值与预报对象特征值之间呈正相关, 有的为负相关, 故矩阵式 (2) 应进行规格化。规格化公式要求对xij取值的正或负都适用。对正、负相关的预报因子采用不同的规格化公式, 全部预报因子特征值的规格化数, 均对应于模糊概念
预报因子特征值xij与预报对象y之间呈正相关, 或两者的相关系数为正时, 其规格化采用
预报因子特征值xij与预报对象y之间呈负相关, 或两者的相关系数为负时, 其规格化采用
式中
矩阵式 (2) 经规格化变换为元素在[0, 1]区间的预报因子特征值规格化矩阵, 即对模糊概念
根据文献
输入层节点i直接将信息传递给隐含层节点, 故节点的输出与输入相等, 即
隐含层节点的激励函数采用笔者模糊优选Sigmoid函数
式中wij为输入层节点i到隐含层节点k的连接权重。
网络输出层节点p的激励函数也采用模糊优选Sigmoid函数, 其输入、输出函数分别为
式中wkp为隐含层节点k到输出层节点p的连接权重。网络的实际输出upj就是网络对输入样本集xrij的响应。设样本j的期望输出为yrj, 其平方误差为
则n个样本的平均误差为
由式 (6) 至式 (10) , 可以推出BP神经网络权重调整公式。隐含层节点k与输出层节点p的连接权重调整量为
η为学习效率。输入层节点i与隐含层节点k的连接权重调整量为
式中
则权重调整公式为
式中t为迭代次数。应用模型式 (11) 至式 (15) , 选定网络误差, 就可根据模糊优选BP神经网络迭代算法, 确定网络的连接权重值, 使实际输出与期望输出的平均误差E最小。但由于神经网络BP模型的误差函数为平方型, 存在局部极小值问题, 且收敛速度较慢。为此, 将模糊优选神经网络BP算法与遗传算法结合起来, 用混合算法对网络进行训练。其训练步骤如下:
Step 1: 设有n个训练样本, 已知预报对象的规格化向量、预报因子的规格化矩阵分别为:
随机给出初始权重值, 作为模糊优选BP神经网络训练的初始值, 输入矩阵xR, 给定网络训练计算误差的精度ε。
Step 2: 应用式 (12) 和式 (11) 计算输入层和隐含层、隐含层和输出层的连接权重调整量值。
Step 3: 应用式 (14) 和式 (15) 计算调整后的权重值。
Step 4: 应用式 (7) 和式 (8) 计算样本集的实际输出值 (向量) , 并用式 (10) 计算输出样本集的平均误差E。
Step 5: 设ΔE (t) 为前后两次迭代结果输出值E的差值, 即ΔE (t) =E (t) -E (t-1) , 若ΔE (t) <Δ (Δ为预先设定的判断收敛速度缓慢性的指标) , 转入加速遗传算法
Step 6: 根据预先设定的遗传算法参数:群体规模、优秀个体数目、加速次数、变量 (权重) 变化范围, 应用加速遗传算法AGA进行循环计算之后, 再次转入模糊优选BP神经网络进行训练。
Step 7: 重复步骤Step 2至Step 6, 直至全局误差小于预先设定的计算误差精度ε。
Step 8: 输出经过训练后的智能网络的连接权重值, 供智能预报之用, 训练结束。该网络由于结合了模糊优选、神经网络与遗传算法的有关原理, 故称其为智能网络。
智能预报步骤如下:
Step 1: 将预报对象的前期预报因子的实测值, 应用式 (3) 和式 (4) 作规格化处理后, 输入已经学习、训练后的智能网络。
Step 2: 智能网络对输入做出响应, 给出输出yrj, 根据预报对象y样本资料的max yj与min yj值, 应用式 (1) 计算预报值:
《3 水文中长期智能预报方法》
3 水文中长期智能预报方法
水文中长期预报有着极为重要的理论与实际意义。目前实用中存在的主要问题是预报精度较低, 难以有效地指导生产实践。为了探索提高水文中长期预报精度的有效途径, 在智能预报模式的基础上, 提出水文中长期智能预报方法。
实践表明, 表征水资源自然属性的水文现象y是一种多因子xi综合作用的结果。
一般说来, y与单一因子之间的线性相关关系不会很好, 但从成因的角度来看, y毕竟与每个影响作用于它的单因子有着成因方面的联系, 这就从本质上决定了y与每一个单因子之间又有一定的关系。因此计算预报对象y与每一个预报因子xi之间的线性相关系数, 根据统计相关分析有
式中ρi为预报因子xi与y的线性相关系数;
用相关系数ρi绝对值的大小来衡量各个预报因子对预报对象作用影响的大小, 筛选预报因子, 并由此确定预报因子, 然后用筛选的预报因子特征值, 根据建立的水文中长期智能预报模式与方法对y做出预报。如果预报检验达到规定的精度要求, 则可以按筛选的预报因子与建立的模式进行预报, 并在预报实践中随着资料的增多不断完善模式中的计算参量, 进一步提高预报精度。否则, 应进行反馈, 再次筛选预报因子, 如此反复, 直到达到要求, 即确定出合适的预报因子为止。
《4 实例计算》
4 实例计算
水文现象具有确定性 (必然性) 与非确定性两方面。而非确定性包含两个侧面:水文特征值大小出现的随机性与特征值“丰”、“枯”在识别过程中的模糊性。水文现象模糊性的基本特点是识别中的亦此亦彼性
新疆伊犁河雅马渡站的23年实测年径流量及其相应的前期4个预报因子特征值列于表1。其中因子x1为前一年11月至当年3月伊犁气象站的总降雨量;因子x2为前一年8月欧亚地区月平均纬向环流指数;因子x3为前一年5月欧亚地区经向 (经度方向) 环流指数;因子x4为前一年6月的2.8 THz太阳射电流量。
根据训练所必要的资料数量, 并考虑预报检验的需要, 将前20年资料用于确定智能预报模型参数, 后3年资料用于检验。下面应用雅马渡站的年径流资料, 阐明智能预报模式与方法的详细步骤。
1) 建立对模糊概念
Table 1 Observed annual runoff quantities and factors feature values of Yamadu Hydrographic Sation at Yili River, Xinjiang
《图1》
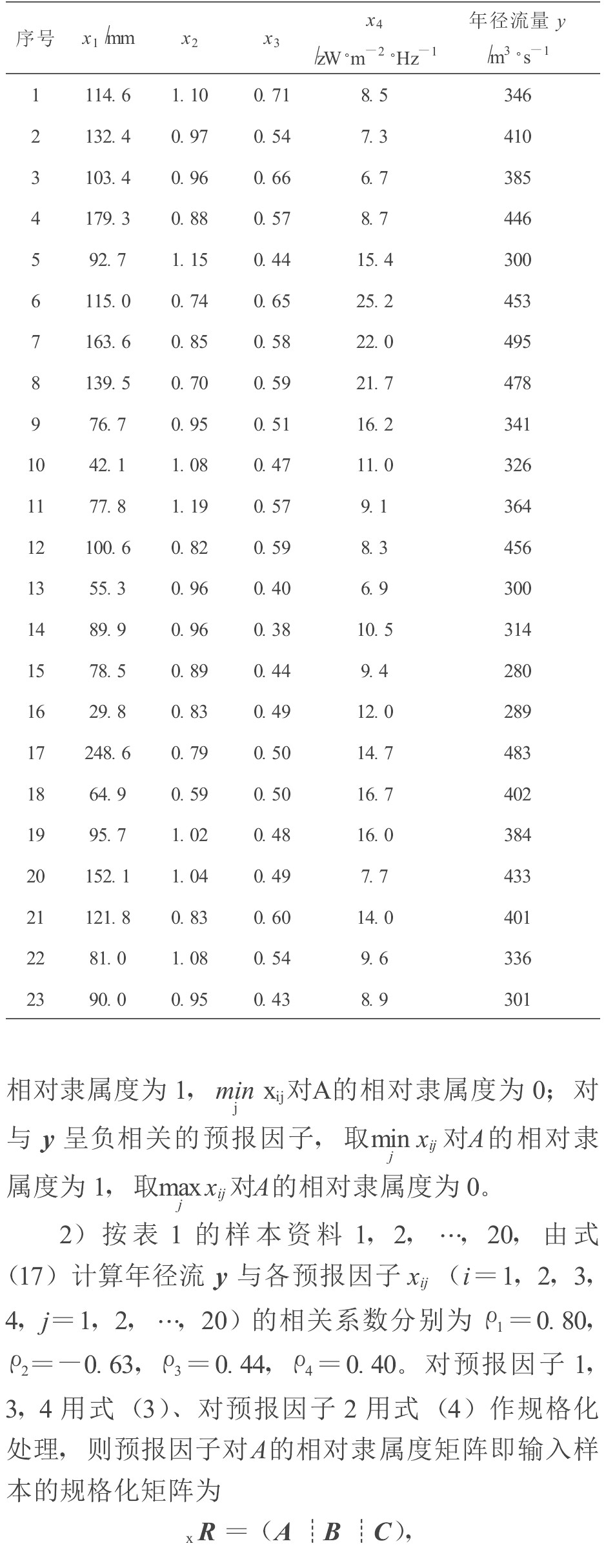
2) 按表1的样本资料1, 2, …, 20, 由式 (17) 计算年径流y与各预报因子xij (i=1, 2, 3, 4, j=1, 2, …, 20) 的相关系数分别为ρ1=0.80, ρ2=-0.63, ρ3=0.44, ρ4=0.40。对预报因子1, 3, 4用式 (3) 、对预报因子2用式 (4) 作规格化处理, 则预报因子对
《图2》

用式 (1) 计算得到预报对象对
yr= (0.277, 0.587, 0.466, 0.762, 0.053, 0.796, 1.0, 0.917, 0.252, 0.180, 0.364, 0.811, 0.053, 0.699, 0.228, 0, 0.942, 0.549, 0.461, 0.121) 。
将表1中前20年资料作为智能预报的训练样本。网络的拓扑结构为:设置3层网络, 根据预报因子数输入层设4个节点, 根据经验隐含层设4个节点, 输出层为1个节点。
设置误差精度和智能预报混合算法的运行参数。误差精度ε=0.005, BP神经网络的学习效率0.8, 遗传算法的群体规模30, 优秀个体数目5, 加速循环次数2, 各个权重变化范围为其本身的0.5倍。应用智能预报模式与混合算法对智能网络进行训练后, 得到智能网络输入层节点与隐含层节点的连接权重矩阵为
隐含层节点与输出层节点的连接权重向量为
智能网络训练预报值与实测值的对比结果列于表2。
对雅马渡站最后3年的年径流量作预报检验如下:将表1中序号21, 22, 23的预报因子xi用式 (3) 和式 (4) 作规格化, 得到预报因子对
Table 2 Contrasting of training samples to observed quantities
《表1》
样本号 |
预报值/m3·s-1 | 实测值/m3·s-1 | 相对误差/% |
1 |
377.335 | 346 | 9.056 |
2 |
416.515 | 410 | 1.589 |
3 |
393.343 2 | 385 | 2.167 |
4 |
470.487 1 | 446 | 5.49 |
5 |
311.738 3 | 300 | 3.913 |
6 |
471.262 9 | 453 | 4.032 |
7 |
482.055 | 495 | 2.615 |
8 |
484.572 5 | 478 | 1.375 |
9 |
364.734 9 | 341 | 6.96 |
10 |
283.613 5 | 326 | 13.002 |
11 |
344.92 | 364 | 5.242 |
12 |
419.756 | 456 | 7.948 |
13 |
280.808 3 | 300 | 6.397 |
14 |
292.886 4 | 314 | 6.724 |
15 |
305.424 4 | 280 | 9.08 |
16 |
290.468 4 | 289 | 0.508 |
17 |
494.728 6 | 483 | 2.428 |
18 |
423.821 6 | 402 | 5.428 |
19 |
365.132 5 | 384 | 4.913 |
20 |
420.777 | 433 | 2.823 |
将上面矩阵输入训练好的智能网络, 输出相应的预报对象y特征值规格化向量或对
将向量yr代入式 (16) 得到预报检验值列于表3。由预报检验值的相对误差可见, 智能预报的检验精度令人满意。
Table 3 Forecasting prove-test results
《表2》
样本号 |
预报值/m3·s-1 | 实测值/m3·s-1 | 相对误差/% |
21 |
447.678 7 | 401 | 11.641 |
22 |
343.173 6 | 336 | 2.135 |
23 |
306.968 9 | 301 | 1.983 |
《5 讨论》
5 讨论
由于神经网络初始权重以及遗传算法初始群体的产生都是随机的, 因而算法的结果会产生不稳定现象。如果算法的模型选择合理, 算法的参数设置合适, 计算结果就会相对比较稳定。为验证算法的稳定性, 选用同样的BP神经网络和遗传算法参数, 分别单独进行5次计算, 其预测结果如表4。
Table 4 Forecasting prove-test results under different number
《表3》
次数 |
样本序号 | 预报值/m3·s-1 | 实测值/m3·s-1 | 相对误差/% | 平均相对误差 /% |
计算时间 /s | 神经网络 循环次数 |
遗传算法 循环次数 |
| 21 | 440.001 3 | 401 | 9.726 | |||||
1 |
22 | 342.053 4 | 336 | 1.820 | 4.039 | 93 | 40 | 15 |
| 23 | 302.772 6 | 301 | 0.589 | |||||
| 21 | 426.703 4 | 401 | 6.41 | |||||
2 |
22 | 336.385 4 | 336 | 0.115 | 2.545 | 99 | 202 | 16 |
| 23 | 304.342 5 | 301 | 1.11 | |||||
| 21 | 438.551 6 | 401 | 9.364 | |||||
3 |
22 | 327.054 7 | 336 | 2.662 | 5.391 | 79 | 42 | 13 |
| 23 | 313.485 2 | 301 | 4.148 | |||||
| 21 | 442.031 8 | 401 | 10.232 | |||||
4 |
22 | 334.675 6 | 336 | 0.394 | 4.263 | 113 | 79 | 19 |
| 23 | 294.492 5 | 301 | 2.162 | |||||
| 21 | 435.332 8 | 401 | 8.562 | |||||
5 |
22 | 325.330 4 | 336 | 3.173 | 5.481 | 100 | 272 | 15 |
| 23 | 315.171 5 | 301 | 4.708 |
从表4可以看出, 每一次计算的预报和实测值都很接近, 预报精度较高, 满足中长期水文预报所要求达到的精度。算法平均循环次数为97次, 而且每次运行速度差别不大, 说明算法在保持高效的同时, 稳定性也很高。











 京公网安备 11010502051620号
京公网安备 11010502051620号




