



《1 引言》
1 引言
高性能计算机自诞生以来已走过了漫长的历程,在1964—2000年的36年中,运算速度从1 Mflo/s提高到 12 Tflo/s,高性能计算机不仅在运行速度上提高了7个数量级,而且在体系结构、软硬件技术、算法和应用等方面都发生了巨大的变化。现代科学技术没有哪一项像计算机发展如此迅猛,更新换代如此迅速。由于科学和工程计算需求的牵引,以及正在发展的知识经济的驱动,高性能计算机的发展是永无止境的,提高计算机的运算速度是计算机发展中永恒的主题。如今,计算机科学家和工程师们计划在2005~2010年把高性能计算机的运算速度提高到拍次每秒。实现这样的宏伟目标,决不是一帆风顺的。当前,高性能计算机突破了太量级以后,正面临着极其严峻的挑战。
《2 举世瞩目的30年》
2 举世瞩目的30年
在过去的30多年中,高性能计算机经历了三个发展阶段,即萌芽阶段、向量机鼎盛阶段和大规模并行处理机(MPP)蓬勃发展阶段。
《2.1 萌芽阶段(1964—1975年)》
2.1 萌芽阶段(1964—1975年)
萌芽阶段有代表性的计算机包括1964年的CDC 6600、70年代初的ASC和STAR-100向量机、1974年的ILLIAC-Ⅳ并行机。CDC 6600被公认为世界上第一台巨型机,运算速度1 Mflo/s。STAR-100是世界上最早的向量机,由于研制周期长,所采用的技术如磁芯存储器等在机器研制完成时已落后,未能进入市场。ILLIAC-Ⅳ是最早的SIMD阵列计算机,原计划由4个象限共256个处理单元组成,实际只安装了一个象限,由于其编程模式与当时使用的大型机大相径庭,程序员必须考虑问题的规模如何与固定的机器规模相适应,加上机器稳定性差,使该机未能得到推广。
《2.2 向量机鼎盛阶段(1976—1990年)》
2.2 向量机鼎盛阶段(1976—1990年)
1976年Cray公司推出 Cray-1向量机,开始了向量机的发展阶段。在短短10多年中,相继出现了Cray-2、Cray-XMP、Cray-YMP和Cray-C90,DEC公司的VAX 9000,Convex公司的 C 3800系列,NEC公司的SX系列,富士通公司的VPP系列等。向量机得以发展的原因是向量处理对提高机器运算速度十分有利,主要表现在:
1)有利于流水线的充分利用,可以缩短周期,提高主频;
2)有利于多功能部件的充分利用,特别是“链接”功能增加了并行处理能力;
3)减少了程序中辅助指令条数,缩短了程序运行时间。
到80年代,出现了并行向量多处理机(PVP),依靠并行处理,进一步提高运算速度。向量机成为当时高性能计算机的主流产品,占领了高性能计算机90 %的市场。然而,事物的发展总有一定的限度。到80年代末,SX-3时钟周期已达到2.9 ns,时钟周期进一步提高难度很大。Cray-3机,时钟周期2 ns,进度一再推延,样机完成后难以形成产品。SSI公司研制的SS-1向量机,计划时钟周期为1 ns,也因困难大而中止。
《2.3 MPP蓬勃发展阶段(1990—)》
2.3 MPP蓬勃发展阶段(1990—)
90年代开始,MPP摆脱了多年来徘徊不前的局面,开始走向大发展。各种新技术层出不穷,如虫孔寻径技术、微内核操作系统、并行编译等。这一时期出现了若干代表机型:BBN公司的TC 2000,Intel公司的Paragon,TMC公司的CM-5,KSR公司的KSR-1,Cray公司的T3D,IBM公司的SP2等。1996年是MPP的丰收年,推出的MPP包括:Cray公司的T3E
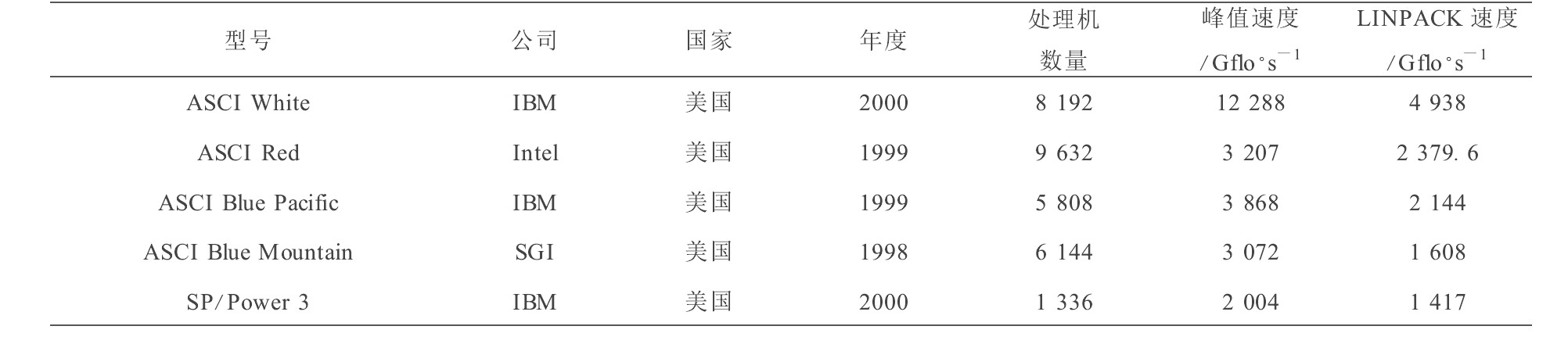
表1 TOP 500前5台高性能计算机(据2000年11月TOP 500)
Table 1 TOP 5 high performance computers (from TOP 500 Nov. 2000)
《图1》
《2 MPP发展形势》
2 MPP发展形势
高性能计算的需求是永无止境的,如全球气候予测、石油勘探、核武器模拟、航空航天设计、人类基因研究、生物科学研究等均需要更高性能的计算机。美国能源部(DOE)的ASCI计划是一个很好的例证
美国国防部(DOD)提出的“高性能计算现代化计划(HPCMP)”,旨在以高性能计算为手段将最新的科学技术尽快用于提高武器性能、提高战斗能力和防卫系统的水平。计划分10个领域,如计算流体动力学,计算化学和材料科学、大气/海洋建模和模拟等,都需要更高性能的计算机。
从系统结构的分类来看,高性能计算机除了传统的SMP、PVP、MPP外,还有一些新的动向:a.定制高性能向量CPU构造PVP系统仍在发展,日立SR 8000是一台高性能PVP系统,在TOP 500前20名中占有4台,其定制CPU采用伪向量机制实现向量功能,性能为12 Gflo/s,是当前商用CPU性能的10倍。b.由用户购买PC机/工作站自行搭建的Beowulf系统开始涌现。Sandia国家实验室搭建的Cplant系统是一个例子。该系统用商用互连硬件Myrinet将580个Alpha工作站连接起来,以Linux为操作系统,峰值性能达580 Gflo/s,在TOP 500中已排在第84位,该系统正向1 600个CPU扩展。c.采用商用 SMP(SSMP) 构造Cluster系统逐步成为较流行的方法
《4 MPP关键技术》
4 MPP关键技术
MPP继续发展的关键技术主要在于以下三个方面:可扩展性、友善性和可用性。
《4.1 可扩展性》
4.1 可扩展性
MPP在规模越来越大时,可扩展性问题突出表现在体系结构、系统软件和并行算法三个方面。
《4.1.1 体系结构的可扩展性》
4.1.1 体系结构的可扩展性
摩尔定律在今后十多年中仍将成立,微处理器的内部工作频率越来越高,加之超标量、超流水线和同时多线程(SMT)等技术的使用,使CPU芯片性能不断提高。而互连网络的带宽和延迟很难与结点运算能力相匹配。此外,用户级点对点的消息传送产生较大的软件开销,用户的可见带宽比网络物理带宽低。
体系结构的可扩展性直接影响整机系统的效率。MPP规模越来越大,数千个至数万个处理机构成一个大系统。系统效率下降的原因除了网络通信能力与结点运算能力不匹配以外,还因为系统规模扩大后原子操作、锁操作所用的时间也增大。在大系统中程序的并行部分运算时间缩短,串行部分运算时间比例增大,也对效率发生很大影响。
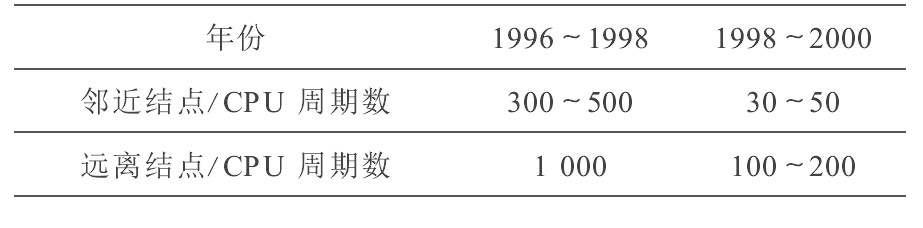
解决体系结构可扩展性的关键之一是提高互联网络的性能,并采用各种降低延迟和隐藏延迟的技术。ASCI Path forward计划将高速互联网络列为首要难题,投资1 000万美元在“千兆位系统网络”项目上。表3所列指标是为研制10~100 Tflo/s系统必须达到的网络延迟要求,远程存储访问要压缩到100~200个CPU周期,比当前的网络通信水平要提高一个数量级。
降低延迟的技术是从体系结构、硬件实现和操作系统方面尽可能减少点到点的传输延迟。相关技术有:采用NUMA结构或CC-NUMA结构;增大Cache和本地存储器容量;避开TCP/IP协议,旁路OS,结点间通信在用户层实现,如VIA和ST;用硬件实现广播、归约、置换、以及轻量级全局同步,提高全局操作的速度。
隐藏延迟的技术是借助通信与计算并行、通信与通信重迭等手段使访存延迟不直接影响结点的计算,同时充分利用程序的局部性特征进行空间域优化和时间域优化,将多数远程访问转化为近地访问,使远程访问的比例减到最小。其方法有:指令流水;数据予取技术;数据流缓冲机制;多线程机制;伪向量机制;消息重叠;数据重分布技术;动态页面迁移和复制技术等。
《4.1.2 系统软件的可扩展性》
4.1.2 系统软件的可扩展性
操作系统面对数万个CPU或数千个结点的系统,必须设计成可扩展、可移植、标准化的分布并行操作系统,这是十分困难的。首先要解决集成的全系统范围的资源分配和管理问题。面对NUMA结构下极其庞大又分布的系统资源,资源分配、管理和调度策略将决定系统中所有资源是否能最充分的利用,系统各部分是否能最充分的并行,并且为此付出的系统开销能减少到最小
并行编译器的优化问题,是提高机器效率的另一个关键问题。并行编译器要对应用程序进行全局指令流、数据流分析,分析指令相关性和数据局域性,采用多种优化措施,充分发挥体系结构提供的功能和特点,获得高效性。当前,高性能计算机走向消息传送与共享存储相结合的混合结构,给并行编译增添了新的手段,同时也增加了新的难度
《4.1.3 并行算法的可扩展性 》
4.1.3 并行算法的可扩展性
当前,相关性较强的问题在并行计算机上求解仍面临许多难题。如高度稀疏矩阵课题,并行效率仍较低。另一方面,高性能计算机在今后10年内将发展到(1~10)×104个CPU,需要将问题分解为具有百万路以上的并行性,并行计算方法的研究是至关重要的。同时,要研究适应今后主流体系结构的优化算法,如何在算法中设法减少通信延迟,采取计算与通信重叠的措施,以达到高效计算的目的。
《4.2 友善性》
4.2 友善性
《4.2.1 提供单一系统映像》
4.2.1 提供单一系统映像
无论系统多么庞大,存储器层次、互连网络及I/O系统多么复杂,用户使用起来都像使用微机一样方便,这就是单一系统映像的最终目的。单一系统映象的含义包括多方面,如单一文件系统、单一用户登录结构、单一进程管理、单一存储空间等。目前在系统规模很大时解决单一系统映像问题仍是一大难题。
《4.2.2 人机友好的编程环境 》
4.2.2 人机友好的编程环境
它包括高性能并行编译器和高效的调试环境和性能监测工具。并行语言需要解决标准化和可移植性问题,今后一个时期的重点是支持“结点共享”或分层的多级分布共享存储系统的标准可移植语言。在MPP规模很大时,其调试环境和监测工具的友善性和方便性也是一大难题,其标准化工作也应予以高度重视。
《4.3 可用性》
4.3 可用性
可用性是在硬件系统可靠性的基础上,借助软件技术提高系统可用程度的度量。由于硬件元器件固有的失效率和系统中不可避免的偶发性故障,大规模并行计算机的平均故障间隔时间已经下降到数天甚至数小时,可靠性问题变得十分严重。必须采取更有效的可靠性措施,存储器系统和重要的数据通路实行全面的ECC校验,其他一些部分采用奇偶校验或CRC校验。对于消息具有错误后重发功能,硬软件相配合实现错误后复算功能。分布于全系统的维护诊断电路能通过状态监测和边界扫描全面统计和分析系统的故障情况。
在硬件可靠性措施基础上,通过软件进一步提高系统可用性。如保留恢复功能、动态故障隔离功能、自动降级运行并在硬故障消除后自动回复的功能等行之有效的方法,但增加系统设计的复杂性。
综上所述,大规模并行计算机可扩展性、友善性和可用性的提高,有赖于并行算法、程序设计、编译技术、体系结构、系统硬件和系统软件等方面的共同努力。
《5 神威高性能计算机》
5 神威高性能计算机
由国家并行计算机工程技术研究中心研制的神威高性能计算机是一个可扩展的大规模并行处理系统。
《5.1 概况》
5.1 概况
该系统采用同构、分布共享主存储器、平面格栅网体系结构,由主机系统、前端系统、磁盘阵列系统和软件系统组成。其结构框图如图1所示。主机系统包括一个可缩放的12×12平面格栅网、96个运算结点、8个前端结点、16个I/O结点、维护管理系统和电源系统。每个运算结点包括4个单元处理机和1个消息处理机,前端系统包括6台前端机、2个系统控制台,磁盘阵列系统包括16台磁盘阵列。
运算结点是系统完成运算功能的主体部件。每个单元处理机由高性能微处理器、片外Cache、128 MB局部存储器、高带宽内部总线等构成。消息处理机实现单元处理机与外部的通信和数据传送,并与单元处理机的运算重叠进行;同时实现运算结点间的广播、归约等全局操作和轻量级全局“与”同步;完成一组结点间的数据重分布功能。
平面格栅网将所有运算结点、I/O结点及前端结点连成一个有机整体。Y方向12个结点中,8个用于运算结点,4个用于I/O结点及前端结点。通过X方向的扩展实现不同规模的系统。它采用Wormhole 传输技术,支持结点间的高速通信;支持网络的分割与重构;支持任意长度消息包的传输;并具有网络路由容错和数据校验功能。
I/O结点用来管理外存储器系统(磁盘阵列),提供系统文件服务。I/O结点由高速处理器、存储器、Mesh网接口适配器和SCSI-2接口适配器等组成。除磁盘阵列外也可挂接其它具有SCSI接口的外围设备。
前端系统由前端机网关,前端机(含前端机工作站、可视化工作站、系统控制台)和周边设备组成,提供人机交互界面和网络功能。前端机系统的主体是前端的高性能工作站,它通过接口适配器与主机系统的前端机网关相连接。一个前端机网关与一台前端机工作站构成一个前端结点。
软件系统的组成和功能:
· 操作系统为自行研制的、采用Mach微内核技术、并保持与OSF/1系统兼容的分布式并行操作系统;
· 支持多种文件系统及并行I/O;
· 交互式和批式作业管理;
· 多种目前流行的并行程序设计语言:并行C、HPF、OpenMP、Java;
· 并行程序开发和支持环境:PPME、MPI、PVM和科学计算软件库;为用户开发并行程序提供了易于使用、方便灵活、直观清晰、功能丰富的综合性工具集,基于Motif界面, 提供对系统效率、状态以及操作系统行为的动态监测及系统组合切割等功能;
· 远程用户环境;
· 网络安全接入系统;
· 分布式数据库管理系统;
· 科学计算可视化系统;
· 维护管理系统和诊断系统。
《5.2 特点》
5.2 特点
神威高性能计算机具有如下特点:
1)采用分布共享体系结构提高系统总体性能 神威机采用分布共享存储体系结构,各类不同的功能模块通过高速互连网连接起来,支持NCC-NUMA全局共享。分布式并行操作系统实现全局协调一致的运行和管理。结构上的分布特性保证系统可扩展、可分割;逻辑上的共享特性使系统更具透明性和可编程性。
2)减少消息传送开销实现高速并行处理 采用消息处理机及高速路由器,减少消息传递的延迟时间和开销。系统提供全局操作和同步机构,提高了系统的协同操作能力,加速程序执行速度。
3)具有多种编程模式提高系统可编程性 同时支持消息传送型、分布共享型以及结点共享型三种并行程序模式,以满足不同用户开发大规模并行计算程序的需求。
4)设计结构新颖的操作系统支持系统扩展 操作系统采用两级分布式结构和多虚空间多重映射与主动消息相结合的技术,实现了在分布式共享结构下操作系统的可扩展性。
5)采用多种优化技术提高系统效率 采用相关性分析、数据流分析、通讯优化和数据重分布等多种优化措施,提高并行程序的执行效率。
6)采用自顶向下分层设计实现系统单一映像 系统实现了单一文件系统、单一IP登入、单一存储空间、单一任务控制管理、单一资源和系统管理。提高系统的友善性。
7)实施高密度组装 它确保系统性能和可靠性神威机大板面高密度的印制板和表面安装技术对于减少信号传输延迟、提高系统性能起到了重要作用,同时对系统质量和可靠性起了保证作用。
《5.3 应用》
5.3 应用
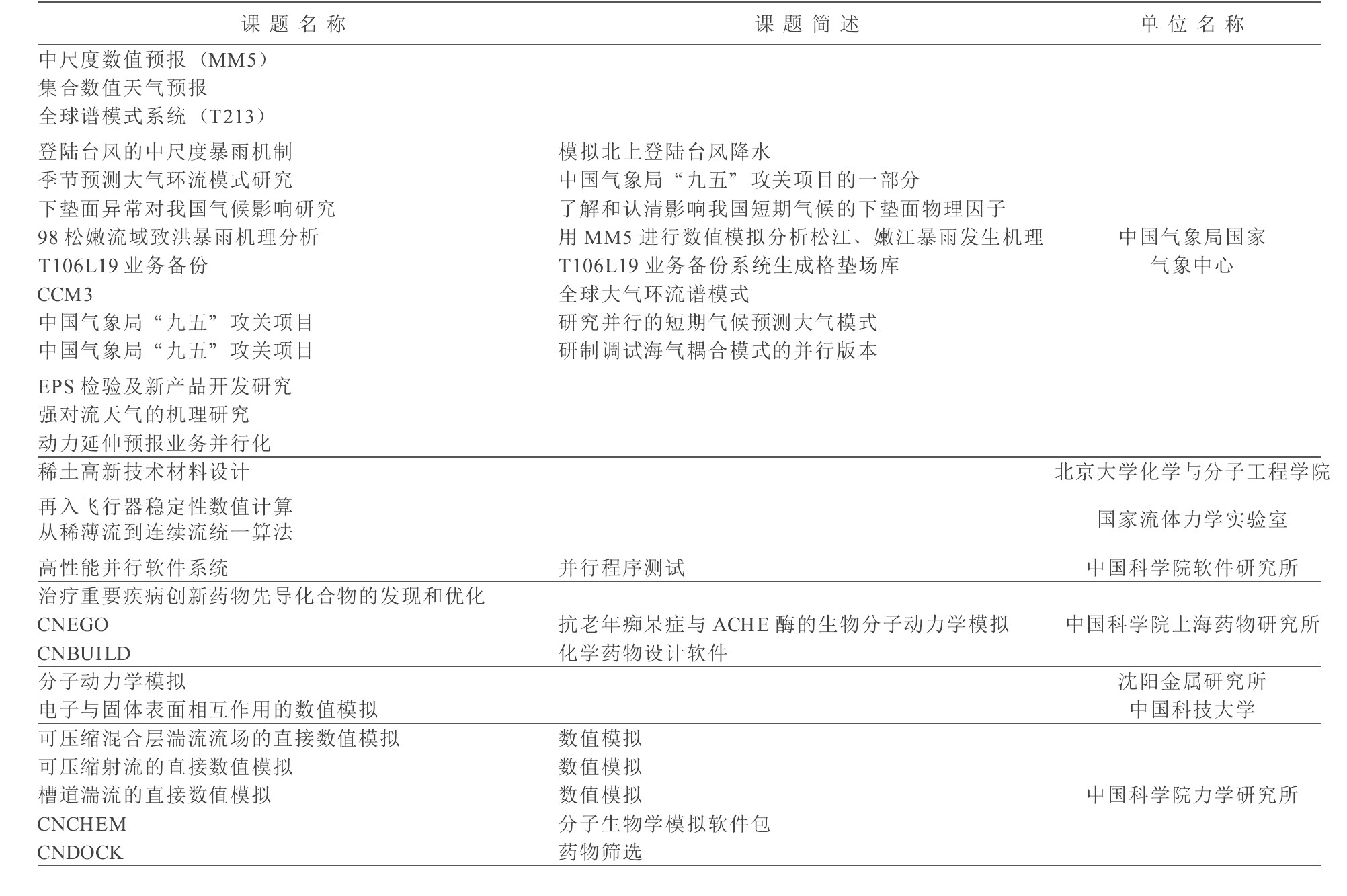
神威机为我国高端计算提供了良好的计算平台,在气象、石油、药物、航空航天等方面获得了可喜的应用,如表4所示。
投入准业务运行的气象集合数值天气预报是国家气象局的大型应用软件,在神威机上同时运行32个样本在国内尚属首次,达到世界先进水平(美国达17个样本,欧洲达52个样本)。
中科院上海药物研究所的药物分子与生物大分子相互作用的数值模拟课题,在神威机上使用约1/4的资源,用40 000 CPU小时实现了青蒿素抗病反应过程的数值模拟,得到很好的结果。经专家审查,认为该项目已经达到国际先进水平。
计算机药物筛选软件在神威计算机系统上实现并行化,这是国内首次将此类软件移植到高性能计算机上,使得计算机药物筛选的效率提高100多倍。原来需3个月的工作现在可在1日内完成,因此可大大缩短新药研究的周期。
石油地震成像系统在神威计算机上的移植和并行化工作,使三维叠前偏移这一计算量巨大的处理技术达到实用化。在神威机上用50 h完成了200 km2、500万道三维地表数据的叠前处理。同样的工作,使用32个CPU的SGI Origin 2000需要900 h以上。
中国船舶工业总公司708研究所2项研究课题分别是水面船只粘性计算和流场计算。该课题是通过计算指导船体设计,提高船舶的动力性能,在神威系统上仅用72PE运算十几小时即告完成。
中国科学院力学研究所的课题是湍流直接数值模拟,该项目是国家和中国科学院系统的重点科研项目,以前在国内无法计算。在神威机试算后,获得了国际领先水平的成果,并显示出神威机很好的加速比,如图2所示。
《6 结语》
6 结语
发展科学技术的三个重要手段是理论、实验和计算。高性能计算属于计算这一范畴,在验证理论的正确和避免昂贵的实验方面有着不可替代的作用。但高性能计算机的市场需求较小,因而必须得到政府的重点扶植,一旦成熟,借助市场驱动加速其发展。
在进入新世纪之际,只有敢于面对严重的挑战,才能赢得发展的机遇。a.发展高性能计算机的关键在于体系结构、逻辑设计、软件技术和并行算法,这些方面恰恰是我国优势所在。b.我国在高性能计算机的研究方面已取得了很好的成绩,基本掌握了研制高性能计算机的关键技术。c.自由软件和公开源码的大趋势为我国自行开发系统软件和增强安全性提供了良好机遇。
与此同时,要大力提高我国高性能计算机的应用水平。当前,能在数百、数千个CPU的系统上运行的应用课题大都处于起步或尚未开发的阶段。要加强研制单位和应用单位间的沟通和协作。选好突破口,然后逐步扩展。随着我国高性能计算的应用向宽度和深度发展,高性能计算机将在更多的领域得到推广和应用。
“雄关漫道真如铁,而今迈步从头越”。我们相信,只要抓住机遇,努力拼搏,我国有能力在高性能计算机技术上赶超世界先进水平,为国民经济建设发挥重大作用。











 京公网安备 11010502051620号
京公网安备 11010502051620号




