
《1 引言》
1 引言
人类改造自然的方案规划与设计过程总体上反映了最大化效益、最小化成本这一基本优化原则。最大化效益、最小化成本实质上是一个多目标的优化问题 (MOP) 。效益可能包括多种效益, 如经济效益、政治效益与社会效益等;成本或损失也可能包括生产成本与非生产成本, 或与此相关联的其他目标如环境污染等方面损失。航天器总体设计中的有效载荷、射程、推力等指标参数的综合是一个典型的多目标的优化问题。控制工程中控制系统的稳、准、快等时域指标与稳定域度、系统带宽等频域特性的综合问题也是一个多目标工程优化设计问题。此外还有社会发展与国民经济的中长远发展计划的优化与决策问题等。一般说来, 科学与工程实践中的许多优化问题大都是多目标的优化与决策问题。
传统的多目标优化方法往往将其转化为各目标之加权和, 然后采用单目标的优化技术。但是, 这样做存在几大缺点:a.不同性质的目标之间单位不一致, 不易作比较;b.各目标加权值的分配带有较大的主观性;c.优化目标仅为各目标的加权和, 优化过程中各目标的优度进展不可操作;d.各目标之间通过决策变量相互制约, 往往存在相互矛盾的目标, 致使加权目标函数的拓扑结构十分复杂。基于传统数学规划原理的多目标优化方法在实际工程优化问题中往往表现出一定的脆弱性, 因此, 有必要研究高效实用的多目标优化与决策的算法及理论。
多目标优化/决策问题不存在唯一的全局最优解, 而是存在多个最优解的集合。多目标问题最优解集中的元素就全体目标而言是不可比较的, 一般称为Pareto最优解集
虽然Rosenberg曾提到可用基于遗传的搜索算法来求解多目标的优化问题
实际的多目标问题不仅是一个优化问题, 而且最后往往归结为一个决策问题。运筹学研究领域曾采用数学规划的多目标优化技术对与设计领域紧密相关的多目标决策问题 (MODM) 作过一些研究
《2 多目标优化问题的数学描述》
2 多目标优化问题的数学描述
最小化与最大化问题可以相互转化, 因此, 仅以无约束最小化多目标问题为研究对象。
一个多目标问题可以表示如下, 其中决策向量x∈Rm, 目标向量y∈Rn:
定义1 优劣性 (dominance / inferiority) 如果目标向量解u = (u1, u2, …, un) 部分小于目标向量解v = (v1, v2, …, vn) , 也就是∀i∈{1, 2, …, n}, ui ≤ vi ∧∃ j∈{1, 2, …, n}, uj <vj, 则称u优于v, 记为up<v。 反之, 如果目标向量解u = (u1, u2, …, un) 部分大于目标向量解v = (v1, v2, …, vn) , 也就是∀i∈{1, 2, …, n}, ui ≥ vj∧∃ j∈{1, 2, …, n}, uj>vj, 则称u劣于v, 记为up>v。
定义2 非劣最优解 (Pareto optimal) 只有不存在决策变量xv∈Rn, 使得相应的目标向量解v =f (xv∈Rn) = (v1, v2, …, vn) 优于目标向量解u =f (xu∈Rn) = (u1, u2, …, un) , 即vp<u , 则称决策变量xu∈Rn为多目标问题的非劣最优解。
由所有非劣最优解组成的集合称为多目标优化问题的最优解集, 也称为可接受解集或有效解集, 记为Ptrue;相应非劣最优解的目标向量称为非支配的目标向量 (non-dominated) , 由所有非支配的目标向量构成多目标问题的非劣最优目标域 (Pareto front) , 记为PFtrue。 Ptrue与PFtrue由具体的多目标优化问题中各目标函数所决定, 是一个确定的不变集合。由优化算法所发现的非劣最优解组成的集合记为Pknown与PFknown, 使用演化算法求解多目标优化问题时, 隐含下列假设之一在某些赋范空间 (如欧氏空间, RMS赋范空间等) 中成立:Pknown = Ptrue, Pknown ⊂Ptrue或PFknown∈[PFtrue, PFtrue+ε] 。
《3 多目标优化与决策问题的求解技术分类》
3 多目标优化与决策问题的求解技术分类
《3.1多目标演化算法任务组成》
3.1多目标演化算法任务组成
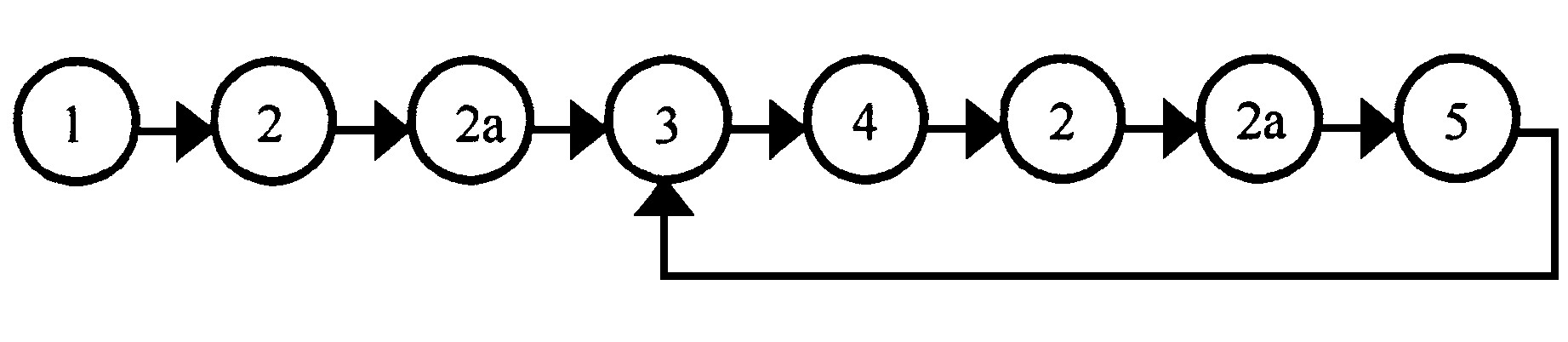
多目标演化算法的任务分解如图1所示, 由以下功能任务单元组成:1为种群初始化过程;2为适应值评估过程;2a为向量目标→标量适应值转换过程;3为杂交操作;4为变异操作;5为选择过程。可见其主要任务组成与单目标优化演化算法相同, 其中2a部分是单目标演化算法所没有的。2a任务是把多目标问题解的向量表示转化为标量化的适应值, 决策者对各目标的偏重程度、权衡优先次序与对各目标的期望值, 通过2a部分转化为决策过程中的效用值, 对多目标演化算法的研究主要集中在2a部分, 不同的转换机制决定了不同的多目标演化算法。
《3.2多目标问题优化与决策的关系》
3.2多目标问题优化与决策的关系
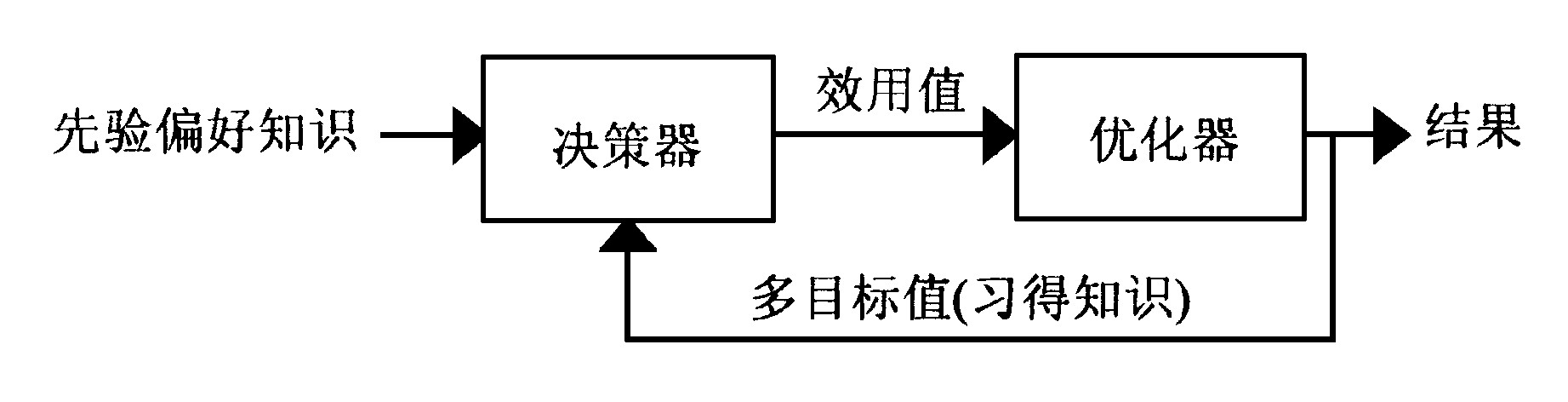
与单目标优化问题的本质区别在于多目标问题的解是一个非劣最优解的集合, 实际的多目标问题往往希望按某些可以定量或定性的领域约束、目标偏好或难以表述的专家经验, 从这一非劣最优解集中选择唯一现实可行的最优方案。图2表示多目标优化与决策系统的基本构成方式, 非劣最优解的搜索过程由优化器实现, 解的选择过程由决策器完成。优化器可由演化算法等多目标优化算法实现, 而决策器则由决策专家或具有领域决策知识的专家系统承担。决策器可以从优化器对非劣最优域的搜索过程中不断获得与精炼决策信息, 而不断变化与丰富的决策信息可以逐步引导优化器搜索最感兴趣的非劣最优域。决策信息决定了非劣最优域的性质以及对最终解的选择结果, 一般以决策者对目标的偏好关系与程度、目标期望值、权衡优先次序、效用函数、模糊逻辑等表示, 因此, 多目标优化问题最终表现为一个与问题相关的本质主观的决策过程。有关偏好信息处理参见文献
《3.3多目标问题演化算法分类》
3.3多目标问题演化算法分类
多目标演化算法是在多目标数学规划技术的基础上发展起来的。根据决策者对各目标主观偏重程度与非劣最优解搜索过程之间的相互影响关系, 多目标优化技术可分为三大类:先验优先权技术, 优先权演化技术与后验优先权技术。
《3.3.1 先验优先权技术 (决策→搜索) 》
3.3.1 先验优先权技术 (决策→搜索)
决策器事先 (主观) 设置各目标的优先权值, 将全体目标按权值合成一个标量效用函数, 把多目标优化问题转化成单目标优化问题。优点是多目标问题的决策过程隐含在标量化的总效用函数中, 对总效用函数的优化过程也是相应多目标问题的决策过程;缺点是很难获得各目标精确的先验优先权值, 而且相应多目标问题的Pareto最优解搜索空间受到限制。先验优先权技术可分为排序聚合方法与标量化聚合方法两类。
1) 排序聚合方法[19]
按目标的先验优先顺序, 解的优劣比较从最高优先级的目标开始, 如上一级目标出现平局, 则开始下一优先级目标的比较直至平局结束;算法采用排序选择法。特点是简单易执行, 所得多目标问题的解皆为Pareto最优解, 但当目标数过多时, 因对目标空间搜索的不平衡特性, 算法易收敛于非劣最优域的局部区域。
2) 标量化聚合方法
将多目标优化问题转化为单目标优化问题的方法, 可分为线性聚合方法与非线性聚合方法。非线性聚合方法又可分为乘性聚合方法、目标向量方法与最大最小方法。线性聚合方法即常规的加权法, 根据各目标的重要性赋以相应权值, 采用标准化的权向量对各目标进行线性加权, 原多目标问题化为单目标优化问题。Fonseca与Fleming指出, 由任何正的加权向量形成的加权目标函数的全局最优解一定是非劣最优解。线性聚合方法的特点是简单易执行, 但在非凸搜索空间中找不到适当的Pareto最优解。非线性聚合方法将多目标以非线性形式转化为单目标, 如乘性聚合方法以各目标之乘积形式转化为单目标优化问题
《3.3.2 优先权演化技术 (决策←→搜索) 》
3.3.2 优先权演化技术 (决策←→搜索)
优先权决策 (决策器) 与非劣最优解的搜索过程 (优化器) 交替进行 (参见图2) , 变化的优先权可产生变化的非劣最优解集, 决策器从优化器的搜索过程中提取有利于精炼优先权设置的信息, 而优先权的设置则有利于优化器搜索到更感兴趣的非劣最优域。优先权演化技术中一般可采用后验优先权技术中的多目标演化算法。可以认为优先权演化技术是先验优先权技术与后验优先权技术的一种有机结合。
《3.3.3 后验优先权技术 (搜索→决策) 》
3.3.3 后验优先权技术 (搜索→决策)
优化器进行非劣最优解的搜索, 决策器从搜索到的非劣最优解集中进行选择, 选择过程就是一个优先权的决策过程。包括独立采样法与合作搜索法, 而合作搜索法又分为目标选择法、聚合选择法与Pareto选择法, 其中Pareto选择法又可分为Pareto排序法、Pareto排序与小生境法、同类群法及Pareto最优保持法。独立采样法以各目标的多种聚合形式对解空间进行独立搜索, 算法每次运行即是以不同加权向量形成聚合目标函数独立采样问题的非劣最优域
此外, 如果按适应值赋值方法分类, 多目标优化技术可分为基于Pareto最优概念与不基于Pareto最优概念的两大类技术。基于Pareto概念的优化技术采用Pareto最优概念对多目标解进行比较与排序, 并基于Pareto排序进行适应值赋值, 如MOGA算法
《4 典型多目标演化算法的比较与分析》
4 典型多目标演化算法的比较与分析
多目标与单目标优化问题的本质区别是, 前者一般是一组或多组连续解的集合, 而后者只是单个解或一组不连续的解。得到一个解集合的近似解集比得到单个解的近似解难得多。本节代表性地介绍文献中五种比较常见的多目标演化算法:多性别遗传算法
《4.1多性别遗传算法》
4.1多性别遗传算法
Allenson在做直线管道路径规划时提出了一种有性别的二目标优化演化算法
《4.2向量评估遗传算法 (VEGA) 》
4.2向量评估遗传算法 (VEGA)
Shaffer与Grefenstette利用演化算法对不同尺度的多目标优化问题分别处理, 可在一次演化计算过程中并发地搜索多个非劣最优解
Fourman提出了与VEGA 类似的算法。Fourman算法
《4.3多目标遗传算法 (MOGA) 》
4.3多目标遗传算法 (MOGA)
Fonseca与Fleming提出的多目标遗传算法 (MOGA)
《4.4非劣性分层遗传算法 (NSGA) 》
4.4非劣性分层遗传算法 (NSGA)
非劣性分层遗传算法 (NSGA)
NSGA算法的种群排序不同于MOGA算法, 前者排序序号是连续的, 后者可以是断续的;NSGA算法的适应值赋值方式不同于MOGA算法, 前者与非劣最优解的比较范围有关, 后者仅与序号有关;NSGA算法的适应值共享方式也不同于MOGA算法, 前者是基于决策向量空间距离共享适应值, 后者是基于目标向量空间距离共享适应值。NSGA算法的优点是优化目标个数任选, 非劣最优解分布均匀, 允许存在多个不同的等价解;缺点是算法效率 (包括计算复杂度与最终解Pknown的优度) 较低, 且对共享参数σshare的依赖性较大。
《4.5小组决胜遗传算法 (NPGA) 》
4.5小组决胜遗传算法 (NPGA)
小组决胜遗传算法 (NPGA)
对多目标演化算法的系统比较研究还不足以说明上述算法的优劣。Zitzler与Thiele等
《5 多目标演化算法研究中的相关问题》
5 多目标演化算法研究中的相关问题
《5.1多目标问题非劣最优域的性质》
5.1多目标问题非劣最优域的性质
无论问题规模 (维数) 的大小, 任何非劣最优解域PFtrue都应有理论上的极限。例如, PFtrue一定是单调的, 并且PFtrue应该具有渐近边界
《5.2测试函数设计》
5.2测试函数设计
为了提高算法研究与比较的效率, 必须设计一些能反映实际多目标优化问题基本特征的标准测试函数集, 它包含多目标问题领域的基本知识。Whitley等曾提出多目标优化/决策问题的测试函数设计准则
演化计算曾经使用过不同的测试函数, 如五个单目标优化函数 (F1~F5)
《5.3算法性能的评估技术》
5.3算法性能的评估技术
对各种多目标演化算法的性能比较研究必须建立在某种度量标准上。已有的性能比较方法有绝对评估方法
《5.4算法收敛性分析》
5.4算法收敛性分析
对一般多目标优化问题收敛行为的理论分析有助于改进现有算法的收敛性。Rudolph
《5.5并行实现与终止条件》
5.5并行实现与终止条件
多目标优化演化算法中的并行实现方式也是值得研究的问题。向量目标评估与相应解的适应值赋值是算法并行性开发中可以首先考虑的两个任务。因为各目标函数可以彼此独立地并行计算, 因此, 开发各目标计算的并行性可以大大提高算法的并行效率。种群中个体的Pareto排序、共享函数与小生境规模计算可以独立执行, 将此两项任务并行实现可提高算法效率。此外, 种群初始化、杂交与变异、选择等必须顺序执行的任务可集中在主机上执行, 同时主机可控制向量目标评估与适应值赋值并行执行。
多目标演化算法终止条件的确定也是一个值得研究的问题。现有的终止条件是, 或采用固定的种群代数, 或每隔一定代数对所得Pknown所对应的PFknown的几何图形进行分析, 以确定算法是否已取得足够完整且均匀的非劣最优解集, 但这些方法仅适应三个目标以下的优化问题。
《5.6实际多目标问题处理》
5.6实际多目标问题处理
多目标优化与约束条件满足是同一问题的两个方面, 都是对一组函数进行优化, 因此二者可相互转化。多目标优化过程中约束不等式的满足问题可转化为最小化相应约束函数直至约束条件满足, 相反, 如果仅把多目标优化问题中的一个目标看成优化对象, 而其余目标均视为约束条件, 则多目标优化问题也可以转化为带约束条件的单目标优化问题。多目标优化技术可以通过对所有设计目标同时进行优化, 来寻找各种满足设计目标与约束条件的设计方案。设计过程中的主观因素来源于设计者已有设计知识与对问题领域认识的局限性, 设计专家对各设计目标的偏重程度往往只能定性地说明, 这些对各设计目标的定性偏重程度可用于对种群的排序, 如果设计目标过多, 也可用来计算其相应的加权值
《5.7算法的逆向应用》
5.7算法的逆向应用
从直接与间接多目标加权和的优化方法联想到, 把一个复杂目标函数的优化转化成一个多目标的优化问题, 也就是把一个高维复杂函数分解成一些比较简单的函数之间的协同优化, 以子函数的协同演化提供原目标函数的种群多样度, 预防过早收敛。因为解群的收敛方向是由适应值函数的拓扑结构或图景所决定的演化压力所驱动, 将复杂的适应值图景拆成比较简单的图景, 也许是提高种群多样度防止过早收敛的一种有效措施, 同时也是提高演化算法控制参数与初始种群设置的鲁棒性的一种有效措施
《6 结语》
6 结语
按适应值赋值方式, 多目标演化算法可分为基于Pareto最优概念与不基于Pareto最优概念的两大类算法。多性别遗传算法与向量评估算法本质上仍然是加权和方法, 只有建立在Pareto最优概念上进行个体排序的多目标遗传算法、非劣性分层遗传算法以及小组决胜遗传算法, 才有可能搜索到多目标优化问题的非劣最优解集。
多目标优化与决策的演化算法有待更深更广的研究工作。多目标演化算法的性能比较必须建立在测试函数的基础上, 并采用统一的性能度量标准进行定量比较, 严密的算法比较还有待研究。对基于Pareto最优概念的多目标演化算法的动态行为理论分析尤其是收敛性分析亦有待探索。











 京公网安备 11010502051620号
京公网安备 11010502051620号




