

《1.引言》
1.引言
一直以来,道路检测都被认为是无人车领域的关键技术,并吸引了广大研究者的关注。迄今为止,道路检测取得了显著进展[1–3]。然而,仅基于道路检测的自动驾驶决策可能仍无法处理一些紧急情况,例如,由于突然转向的车辆或行人使得所检测到的道路变得不可行这种情况。事实上,在驾驶汽车时,人类驾驶员通过将障碍物与非障碍物分类来理解情景,而不仅仅是识别道路。因此,在紧急情况下,出于安全原因,人类驾驶员可以选择在通常不被视为道路的平坦区域上行驶。对于无人车而言,检测这种“平坦区域”而不是检测道路区域,可以为决策过程提供更全面的知识,使无人车更像人类驾驶员。
虽然大多数现有的道路检测方法通过训练在标签清晰的道路数据集上实现了不错的效果,但由于场景布局、光照和天气条件的高度可变性,如何检测在城市和乡村环境中道路标识不明确场景下的道路和车道仍然十分困难。迄今为止,该问题还没有可靠的解决方案,迫切需要提出一种鲁棒而有效的解决方法。
在图像分割中,物体的边界通常出现在深度不连续处。因此,图像分割应该与深度不连续性检测相融合。在投影几何中,类似形是指投影空间的同构,它是一种线到线的双射关系,即所谓的共线。在此,我们引入一个类似于共线中双射的新概念:共点映射。共点映射是一种点到点的双射,它将来自激光传感器的点映射到图像分割边缘的点上。在给定空间域下,将投影空间用一组点的法向矢量表示。由于光照变化,道路的不平坦以及二维(two-dimensional,2D)图像中的阴影,一些共点不是类似形。为了克服这些问题,本文使用点云数据的法向矢量而不是原始点云数据,后文中有详细描述。在这种情况下,可以清楚地表征像素深度数据的融合,并将像素深度的类似形定义为共点映射。
因此,本文提出了一种自适应的可行驶区域的检测方法,该方法利用共点映射将单目相机获得的像素信息与激光传感器获得的空间信息融合,如图1所示。其中,通过将每个激光点的空间位置与图像像素的坐标结合,建立Delaunay三角剖分图[4],以此得到激光点之间的空间关系,并利用三角剖分三角形的法向矢量完成激光点的障碍分类;接下来,通过自学习模型将障碍物分类结果与图像超像素融合来定位初始可行驶区域;然后,在不同特征空间中计算候选可行驶区域,这些特征包括:可行驶程度(drivable degree,DD)特征、法向量(normal vector,NV)特征、颜色特征和强度特征;最后,利用贝叶斯框架融合候选区域以获得最终的可驱动区域。本文使用ROAD-KITTI benchmark[5]进行实验测试。实验结果表明,与其他融合方法相比,本文所提出的方法无需形状或高度信息的假设条件和训练过程,且取得了最优越的性能;该结果验证了我们的方法具有鲁棒性和高泛化能力。
《图1》

图1.本文所提出的检测方法的框架。该方法大致可分为三个步骤:数 据融合、特征提取和特征融合。
本文的主要贡献如下:
(1)提出了一种基于数据融合的无监督检测方法,该方法无需强假设,确保了在多变的城市交通场景下的泛化能力。
(2)引入了共点映射这一新概念,它描述了激光传感器和相机之间进行数据融合的一种新型约束。
(3)设计了一个名为DD的新特征,以描述激光点的可行驶程度。
《2.相关工作》
2.相关工作
鲁棒的道路区域检测方法是无人车的关键组成部分。在过去的几十年中,出现了许多针对该问题的解决方法。根据采集数据的传感器不同将这些方法进行分类:单目相机、立体视觉、激光传感器和多传感器的融合。
基于单目视觉的方法已广泛用于道路检测。与其他传感器相比,视觉传感器体积小、成本低、易于安装。此外,视觉传感器可以提供丰富的视觉信息,具有广阔的检测范围。最重要的是,视觉传感器的原理和结构类似于人类感知组织的原理和结构。通常利用视觉场景的2D信息检测道路区域,如颜色、角点、纹理、边缘和形状。对于颜色信息,通常利用RGB颜色空间、HSI颜色空间[7]或其他颜色空间进行图像分割。Jau等[8]比较了不同光照条件下的RGB和HSI颜色空间分割效果。Finlayson等[9]提出了基于物理的光照不变颜色空间原理,实现了无阴影影响的图像表征,本文也使用了该颜色空间模型。此外,通过利用用于捕获原始彩色图像的相机光谱特性,Maddern等[10]提出了另一种光照不变颜色空间,减少了由太阳光引起的光照变化的影响。
另一个热门研究课题是基于卷积神经网络(convolu-tional neural network,CNN)的方法,该方法取得了巨大成功[11,12]。最初,CNN用于解决分类问题[13,14];然而,随着近期出现的一系列工作[15,16]基于CNN的语义分割方法进入了高潮时期。
然而,道路的概念与其他视觉概念不同,因为视觉中的像素外观不是检测道路区域的唯一标准,像平坦度之类的物理属性对道路的概念判定影响更大。这表明仅依靠单目视觉的方法不够可靠。尽管基于CNN的方法已经可以实现良好的性能,但它们严重依赖于训练过程,可能无法处理崭新的道路场景,并且可能具有过拟合问题。与场景分类[17]或相似性学习[18]等问题不同,道路区域检测是一种病态条件问题,需要使用2D信息来解决三维(three-dimensional,3D)真实世界场景下的任务。虽然可以利用许多如地平线和消失点之类的3D线索来缓解这个问题[19–21],然而,这些3D线索的检测本身就是一个未解决的问题[22,23];一些几何假设可能导致检测失灵或降低泛化能力,如图2所示。
《图2》

图2. 比较在3D线索可能起作用或失败下的不同道路场景。(a)3D线索运作良好;(b)由于消失点的移动和道路形状的弯曲,3D线索可能失败。
近年来,激光传感器的出现激励了许多基于激光传感器的道路检测方法,这些方法可以提供对真实世界3D场景的深度增补测度。这些方法使用激光点的空间位置分析场景,并将平坦区域识别为道路,可以做如下分类。
(1)基于网格的方法。由于点云数据量庞大,通常使用基于2D网格的方法[24–26]来减采样,同时计算网 格内点的统计信息以表征每个网格,可能包括平均高度 和最大高度差等统计。虽然这些方法简单直接,对噪声 鲁棒且高效,但难以确定合适的阈值。
(2)基于平面拟合的方法。这些方法的基本假设是,道路是平坦且平滑的,可以通过多个参数进行平面拟合[27,28]。典型的平面估计方法已经很成熟,如随机抽样一致算法(random sample consensus, RANSAC)[29] 。然而,由于缺乏真正的地面激光点,这些方法在复杂交通场景下可能失效。
基于相邻点之间空间关系的方法。这些方法[30,31]利用相邻点之间的空间关系来提取特征(如法向量)或建立概率模型,以便估计地面激光点或障碍物激光点(如路缘激光点)。
以上所有基于激光传感器的方法都受到点云数据稀疏性的影响,这使得单纯利用激光点是难以重建场景细节的。
检测道路区域可视为两类标签问题,条件随机场(conditional random field,CRF)框架在该领域得到广泛应用[32,33]。根据各个观测,CRF框架将该问题定义为计算数据集整体标签的最大后验概率问题。这是一个通用框架,通过设计能量函数和势函数的不同的通道来定义不同的观测结果。因此,为了平衡不同来源的数据并获得最佳融合结果,基于CRF的方法被广泛用于融合[34,35]。然而,基于CRF的方法会带来很大的计算消耗和存储消耗,并且需要手动标记的数据。
为了克服上述缺点,本文提出了一种基于共点映射的自适应的检测方法,该方法通过将激光传感器的数据与单目相机的数据融合以检测可行驶区域。首先,该方法包含几个预处理步骤:利用超像素分割获得后续步骤的最小图像处理单元;通过交叉校准和共点映射将激光点投射到RGB图像上;利用三角剖分对激光点进行预处理,以建立激光点之间的空间关系。接下来,利用预处理结果进行像素深度数据融合,并利用数据融合结果完成障碍物分类。然后,将超像素与障碍物分类结果相结合,得到初始可行驶区域。之后是特征提取,本文采用DD特征、NV特征、颜色特征和强度特征,所有这些特征都能够以自学方式计算出可行驶概率。最后,在超像素层面,利用贝叶斯框架获得可行驶区域的联合概率分布图。
本文所提出的方法在三个主要方面区别于其他方法:
(1)不需要强假设,不需要标记数据进行训练;
(2)通过利用共点视角和融合激光传感器与单目相机,对光照变化鲁棒,并且可以应对复杂场景;
(3)采用超像素分割,用超像素替换像素作为最小处理元素,这种处理的优点将在后面详述。
不同于一些缺乏特征层面融合的方法[36,37],本文所提出的方法将单目视觉与激光传感器相结合,获得了数据层面和特征层面的丰富信息。此方法自学习地提取融合特征。此外,共点视角和超像素表征使得该方法更具有鲁棒性和有效性。实验结果表明,本文的方法比其他方法具有更高的检测精度。因此,我们认为,本文所提出的方法是一种泛化能力强、实用性高且自适应的无人车的可行驶区域的检测方法。
《3.基础理论》
3.基础理论
本章叙述了新方法所需要的基础理论,包括图像的超像素表征、激光点在RGB图像上的投影过程以及对数 色度空间的建立过程。
《3.1.超像素表征》
3.1.超像素表征
超像素算法最早由Ren和Malik[38]提出。一个超像素代表在颜色或纹理上相近的一组像素,这种表示方式保留了原始图像的大部分结构信息。
本文利用超像素代替像素作为图像处理步骤中的最小处理单元,以辅助寻找候选可行驶区域。由于超像素方法性能的提升,用超像素代替像素降低了计算和存储成本,且不会带来较大的精度牺牲。此外,超像素将颜色信息考虑在内,使得算法在处理复杂照明情况下仍可以获得鲁棒的结果。
为了更好地分割原始图像,超像素方法应该满足两个要求:首先,超像素的生成速度应该快;其次,生成的超像素应“附着”在图像边缘上。
根据参考文献[39,40],一种名为“边缘附着”的超像素满足上述要求,故本文采用边缘附着超像素的生成方法。该方法是在简单线接口计算(simple line interface calculation,SLIC)方法[41]的基础上添加了对边缘的考虑,利用这个增加的边缘项,生成的超像素可以更好地附着到物体边缘,从而保留更多的图像结构信息,同时也产生更好的物体边缘分割。
《3.2.激光点投影过程》
3.2.激光点投影过程
如图3所示,本文参照文献[42],将激光传感器的坐标系投影到相机坐标系下。激光坐标系下任一3D点p_laser = (xl, yl,, zl,, 1)T投影到相机坐标系下对应点p_camera =(xc, yc, zc, 1)T的计算公式如下:
《图3》

图3. 激光点和图像像素点的对齐示例。这里,每个激光点的深度用不同颜色展示,以便更好地查看对齐效果。

式中, 表示旋转矩阵,本文通过附加全为零的行和列将转化为一个4×4的矩阵,并设置(4,4) = 1。
表示旋转矩阵,本文通过附加全为零的行和列将转化为一个4×4的矩阵,并设置(4,4) = 1。 表示转换矩阵,计算公式如下:
表示转换矩阵,计算公式如下:

式中,  分别表示旋转矩阵和平移向量,如文献[42]所示:
分别表示旋转矩阵和平移向量,如文献[42]所示:
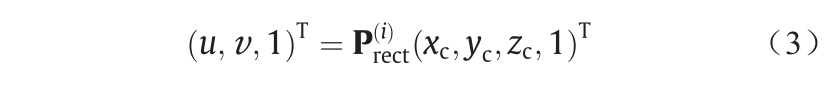
式中, 表示所有点pc在第i个相机平台下的投影矩阵(本文使用第二个相机),则相机坐标系下的位置信息(ui, vi)可由上述公式求得。
表示所有点pc在第i个相机平台下的投影矩阵(本文使用第二个相机),则相机坐标系下的位置信息(ui, vi)可由上述公式求得。
经过投影和矫正就可以得到对齐后的激光点集 =
= ,其中Pi= (xi, yi, zi, ui, vi)。
,其中Pi= (xi, yi, zi, ui, vi)。
《3.3.对数色度空间》
3.3.对数色度空间
根据文献[36],为了获得对阴影和光照条件鲁棒的颜色特征,本文将RGB彩色图像(I)变换为对数色度空间(Ilog),得到光照不变图像Il–c。每个对数色度空间中的{log(R/G), log(B/G)}像素值对应于原始RGB图像中的{R, G, B}像素值。如图4所示,本文通过将{log(R/G), log(B/G)}像素值投影到角度为θ的正交轴上,从而获得灰度图像。角度θ定义了与光照变化线正交的不变方向, 其数值取决于设备本身,可以进行校准。本文按照参考文献[43]将θ设置为45°,Ilog可以根据如下公式计算:
《图4》
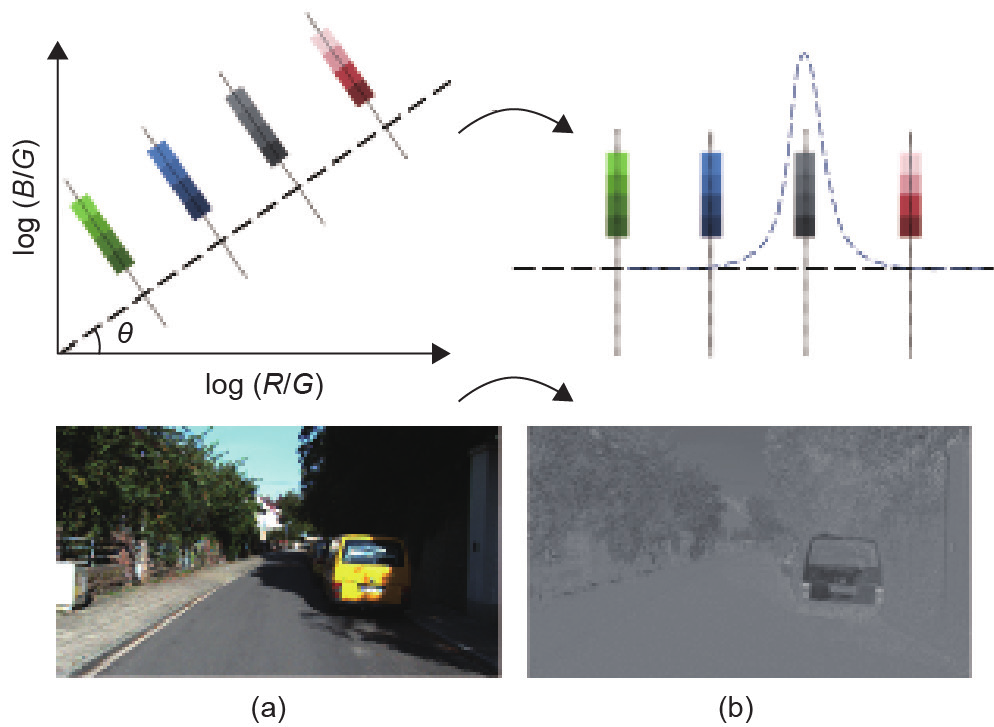
图4.从(a)图表示的RGB空间到(b)图表示的对数色度空间的转换示例图。从图中可以看出,经过转换后,阴影被成功地去除了,同时, 道路和其他物体(即黄色汽车和绿色植物)之间的色差保留较完整。
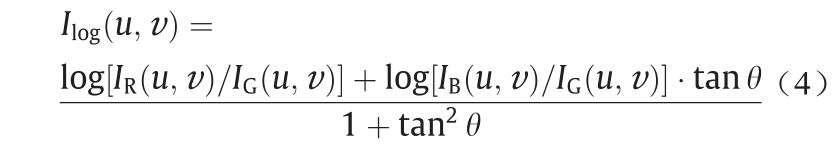
《4.像素 - 深度数据融合》
4.像素 - 深度数据融合
本文没有利用可以直接探测障碍的传感器[44],而是通过将激光传感器提供的空间位置信息与单目相机提供的外观信息相融合以寻找障碍物。本章将介绍像素和深度数据融合的过程。简单而言:第一步,将超像素与激光点融合,以提高方法的效率和鲁棒性;第二步,本文称之为“共点映射”过程,包括将激光传感器得到的深度点与图像分割边缘上的像素点融合,以消除平坦区域内的激光点;最后一步是空间信息和图像坐标之间的融合,此过程通过生成无向图来建模激光点和障碍物之间的空间关系。
《4.1.基于超像素的图像预处理》
4.1.基于超像素的图像预处理
本文采用3.1节中描述的超像素生成方法。除了上述优点之外,本文发现,超像素和激光点是互补的:第一,激光点包含无法从单目相机获得的空间位置信息;第二,超像素是稠密的,因此像素和激光点融合后可以得到两者的鲁棒局部统计。此外,超像素还包含激光传感器无法捕获的颜色信息。因此,本文利用超像素代替像素,作为图像处理步骤中的最小单位。另外,第5节叙述了使用超像素分割获得初始可行驶区域特征的算法。
《4.2.基于共点映射的边缘信息双射》
4.2.基于共点映射的边缘信息双射
由于激光点和图像像素本质上属于在相同场景相同时间下的不同观测,所以它们反映的是相同的结构信息。因此,二者之间的投影应该满足某些特定约束。受投影几何中的共线概念的启发,本文引入了一种新的概念,即“共点映射”,来描述这种约束。类似于共线的双射,共点映射定义了将激光传感器得到的点映射到图像分割边缘上的像素点的双射。
使用共点映射可以提升对齐性能并消除不需要的激光点。具体而言,边缘可以被视为影响像素的外观和激光点结构的基本元素。像素和激光点之间的边缘信息的双射是数据融合的关键。对齐像素和激光点时,两者的边缘信息必须正确对齐。使用交叉校准可以获得初始对齐结果。接下来,本文通过共点映射来改善对齐效果。类似的,边缘信息的双射可以消除位于平坦区域中的冗余激光点,加速计算过程。而且,因为平坦区域内可能存在噪声激光点,这种消除也可以提高算法的鲁棒性。
如图5所示,本文仅使用共点映射来消除平坦区域内的激光点。首先,使用所有超像素的边缘获取整个图像的边缘池。显然,此过程存在许多冗余边缘信息。但是,考虑到边缘池保留了所有真实边缘,具有边缘信息完整性,这是一种合理的做法。实际上,本文采用图像扩张来减少对齐误差。接下来,保留位于边缘池中的激光点,丢弃其他点。实验结果表明,27%的激光点被消除了,且这种消除没有牺牲算法精度,这一发现表明,共点映射是可行且有效的。
《图5》

图5.共点映射的示例图。与(b)图不同,(a)图仅保留靠近超像素边缘的激光点。虽然丢弃了许多点,但也成功地保留了激光点结 构信息。
《4.3.障碍物分类》
4.3.障碍物分类
障碍物分类过程可以看作寻找映射函数ob(Pi )的过程,其中:

分类结果如图6所示。
《图6》
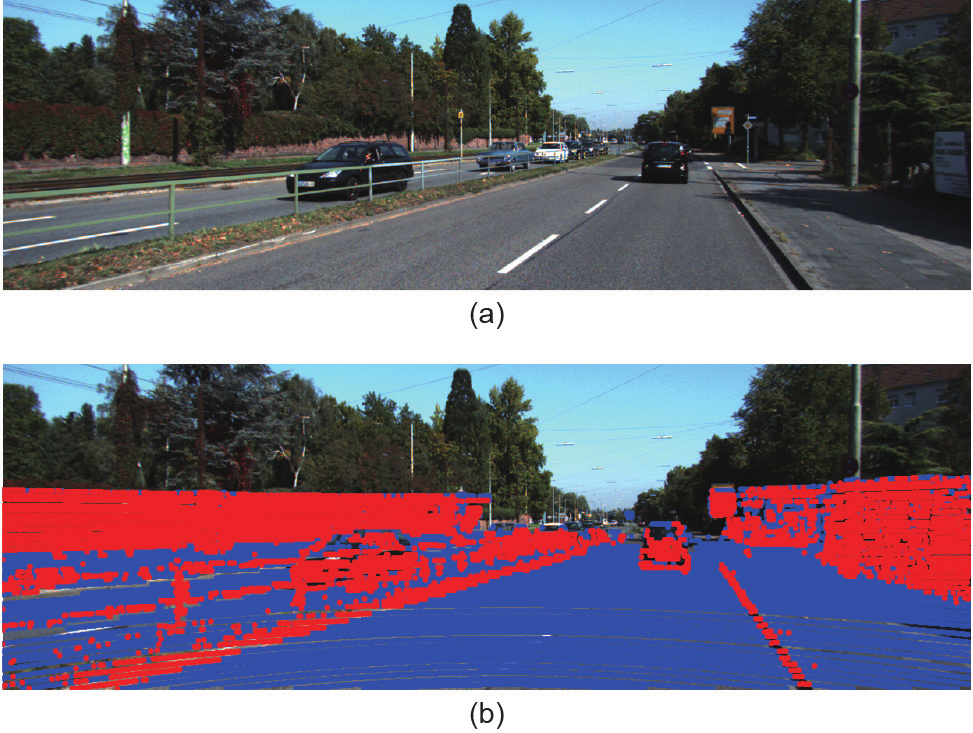
图6. 障碍物分类的结果。该结果表明本文提出的方法不受障碍物像素外观的影响,可以很好地检测出障碍物(即路缘石、墙壁和汽车)。
我们认为ob(Pi)的值仅取决于点Pi周围表面的平坦程度,现实世界中这种平坦程度信息蕴藏在激光点云数据中。因此,障碍物分类问题被分解为两个子问题,即如何找到Pi的周围表面和如何确定这些周围表面是否平坦。
本文通过利用Delaunay三角剖分来解决第一个子问题[4]。对于平面中的一组点集的Delaunay三角剖分,该 集合中的任何点都不在该三角剖分中的任一三角形的外接圆内。此属性使得空间的每个点平均具有6个相邻三角形,其最近邻图是Delaunay三角剖分的子图,因此Delaunay三角剖分可用于在激光点云数据之间建立空间关系。对于每一点Pi = (xi , yi , zi , ui , vi ),本文对其像素坐标系(ui , vi )运用三角剖分构建无向图 其中E 表示Pi之间的具有空间关系的有效边的集合。Pi的周围 表面由公式{(ui , vi )| j = i or Pj∈Nb(Pi )}定义的表面三角形组成,其中,Nb(Pi )表示与Pi连接的点的集合。这里需要剔除欧式距离不满足如下公式的边(Pi, Pi):
其中E 表示Pi之间的具有空间关系的有效边的集合。Pi的周围 表面由公式{(ui , vi )| j = i or Pj∈Nb(Pi )}定义的表面三角形组成,其中,Nb(Pi )表示与Pi连接的点的集合。这里需要剔除欧式距离不满足如下公式的边(Pi, Pi):

式中,||Pi–Pi||表示(xi, yi, zi)和(xi, yi, zi)的欧氏距离;ε表示最大边长阈值。
对于第二个子问题,Pi周围表面的平坦程度可以通过其相邻三角形的法向量度量,将Pi的所有相邻三角形的法向量的均值作为Pi 的法向量,表示为
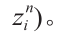 。由此,可以根据如下公式得到ob(Pi ):
。由此,可以根据如下公式得到ob(Pi ):

式中,c为手动设置的参数;Nb(Pi)表示与Pi连接的点的集合,Pi的法向量就是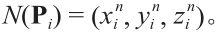 可以这样理解该公式:如果Pi的法向量与地面夹角大于c,则Pi被分类为障碍物点;反之,为非障碍物点。c定义了最大角度阈值,实验中取60°。计算法向量以分类障碍物的过程如图7所示。
可以这样理解该公式:如果Pi的法向量与地面夹角大于c,则Pi被分类为障碍物点;反之,为非障碍物点。c定义了最大角度阈值,实验中取60°。计算法向量以分类障碍物的过程如图7所示。
《图7》

图7. 障碍物分类的图示。每个黑点代表一个激光点。点之间的空间关 系由平面Delaunay三角剖分得到,在激光传感器坐标系下计算三角形 的法向量(黑色箭头:相邻三角形的法线向量;橙色箭头:中心点的 法向量,通过计算周围的黑色箭头的均值得到)。
《5.可行驶区域检测》
5.可行驶区域检测
本节介绍了该方法的关键步骤——可行驶区域检测。首先,从障碍物分类结果获得方向射线图IDRM。接下来,通过将IDRM与超像素结合来获得初始可行驶区域,本文采用不同观测的不同特征表征初始可行驶区域;然后,自学习地计算在初始可行驶区域内的每个超像素属于可行驶区域的概率;最后,利用贝叶斯框架融合由各个特征得到最终可行驶区域的概率图。
《5.1.计算初始可行驶区域》
5.1.计算初始可行驶区域
5.1.1.射线检测
按照算法1计算IDRM。
算法1 计算方向射线图

首先,本文将任一Pi都转换到极坐标系下,以便更好地表示可行驶区域。也就是说,(ui, vi)被转换为极坐标, 坐标系原点是图像的最中间底部的像素(记为Pbase)。因此,用P表示 ,其中,
,其中,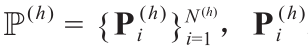 表示属于第h角度范围内的点。P的稀疏性带来了两个影响精度的新问题:第一,如何克服连线的“泄漏”问题, 如图8 所示;第二,如何从稀疏射线中获得稠密的像素区域。
表示属于第h角度范围内的点。P的稀疏性带来了两个影响精度的新问题:第一,如何克服连线的“泄漏”问题, 如图8 所示;第二,如何从稀疏射线中获得稠密的像素区域。
《图8》

图8“泄漏”问题的示意图。(a)为“泄漏”问题示意图:绿点是Pbase;在(b)中,检测射线由白线表示;(c)表示最小滤波的结果示意图;(d)展示了最小滤波处理之前(蓝色曲线)和之后(橙色)的每个射线长度的对照图。
为了解决第一个问题,本文在图像坐标系下对射线长度进行滤波,如图8(d)所示。由于汽车的宽度不可忽略,因此一条射线所代表的区域是否可行驶还取决于该区域的宽度。也就是说,如果射线辐射的区域太窄以至于不能满足车身通过,无论该区域多么平坦,都不是可行驶的。因此,采用最小滤波对射线长度进行处理,解决了“泄漏”问题,如图8(c)所示。
对于第二个问题,最直接的解决方案是增大。但是,这样做会加剧第一个问题。因此,本文将IDRM与超像素融合以获得初始可行驶区域。如4.1节所述,此解决方案有两个优点:首先,它通过用超像素替换像素,大大减少了数据量;第二,它融合了深度信息和颜色信息。
在IDRM与超像素融合之后,本文用一组超像素的点集表示初始可行驶区域,该点集定义为
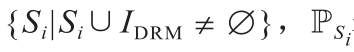 ,表示投影在超像素Si区域内的激光点的集合。由此,以下所有特征的计算均是基于超像素而不是像素,既引入鲁棒的局部统计,又加速了整个算法.
,表示投影在超像素Si区域内的激光点的集合。由此,以下所有特征的计算均是基于超像素而不是像素,既引入鲁棒的局部统计,又加速了整个算法.
5.1.2.计算 DD 特征
检测可行驶区域的算法需要精选的合理的表征特征。本文提出了DD特征,如算法2所示。
算法2 计算DD特征

将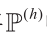 中的点按与
中的点按与 在图像坐标系下的距离进行处理,使得
在图像坐标系下的距离进行处理,使得 中的点均满足:
中的点均满足:
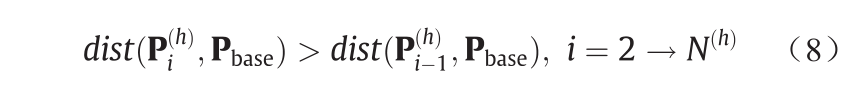
图9展示了DD特征值计算的示意图。图10(c)显示了引入DD特征后的效果[45]。
《图9》
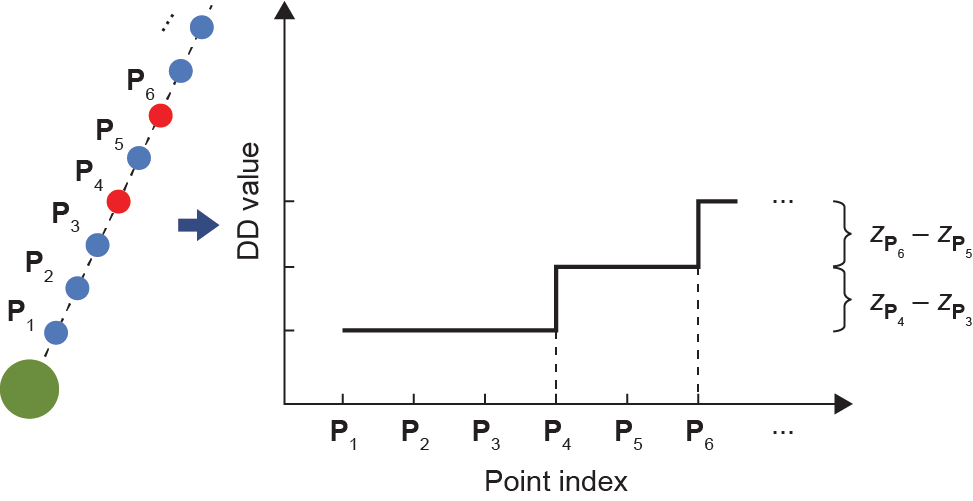
图9.DD计算的示意图。左侧的黑色虚线表示IDRM中的射线。蓝点表示非障碍物激光点,红点表示障碍物激光点,大绿点表示Pbase。在该图中,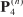 被分类为障碍点;接下来,将
被分类为障碍点;接下来,将 之间的高度差加到
之间的高度差加到![]() 之后的所有点的DD特征值上,如
之后的所有点的DD特征值上,如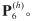
《图10》

图10.IDRM、DD特征计算结果和最终概率图的展示图。(a)显示原始图像,其中包含不同的场景,如汽车遮挡、重影和道路消失点的漂移。(b)显示了相应的IDRM,覆盖了足够的可行驶区域,以生成合理的Sint。(c)显示了DD特征[44],区域越蓝,可行驶程度越大。图中可见,真实道路区域非常蓝,人行道介于蓝色和红色之间,而汽车和障碍物等障碍物则为红色。(d)显示最终可行驶区域的概率图,证明本文所提出的方法在不同情况下表现良好。第六行和第八行中的红色框说明了我们的方法对小目标(如第二列中的框内的灯杆)的处理效果良好。灯杆前面的点的DD特征值很高,但是在这些灯杆后面的区域中的点DD特征值突然下降,表明这些小目标已被成功检测到。
《5.2.自适应的特征模型》
5.2.自适应的特征模型
基于所获得的初始可行驶区域,可以从不同概率空间中的4个特征自适应地学习候选可行驶区域,此4个特征为:DD、NV、颜色和强度特征。
5.2.1.DD 特征
每一超像素D(Si)的DD特征值由如下公式计算:

由于 与点的高度差相关,可知,
与点的高度差相关,可知, 越小,Pi所对应的区域的可行驶程度越高。为了得到候选可行驶区域,构造一个类高斯模型用于表征DD特征的自适应概率空间,计算如下:
越小,Pi所对应的区域的可行驶程度越高。为了得到候选可行驶区域,构造一个类高斯模型用于表征DD特征的自适应概率空间,计算如下:

式中,μD和 为此类高斯分布的参数,可由基于
为此类高斯分布的参数,可由基于 的概率统计,不需要手动设置或者训练;
的概率统计,不需要手动设置或者训练; 为在给定NV特征度量下,Si属于可行驶区域的概率。
为在给定NV特征度量下,Si属于可行驶区域的概率。
5.2.2.NV 特征
根据4.3节,法向量在 方向上的值越大,表面可行驶程度越大。因此,本文定义了每个超像素点的NV特征,用N(Si)表示。通过计算PSi 中
方向上的值越大,表面可行驶程度越大。因此,本文定义了每个超像素点的NV特征,用N(Si)表示。通过计算PSi 中 的最小值得到N(S i)。类似于上述DD特征计算,构造包含参数μn 和
的最小值得到N(S i)。类似于上述DD特征计算,构造包含参数μn 和 的类高斯模型表征自适应概率特征空间:
的类高斯模型表征自适应概率特征空间:
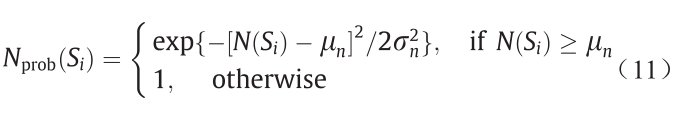
式中,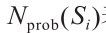 表示在给定NV特征度量下,Si属于可行驶区域的概率。估计参数μn和
表示在给定NV特征度量下,Si属于可行驶区域的概率。估计参数μn和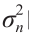 的过程与5.2.1节中相同。因此,该模型也是自适应的,不涉及手动设置。
的过程与5.2.1节中相同。因此,该模型也是自适应的,不涉及手动设置。
5.2.3.颜色特征
如3.3节所述,利用光照不变图像来获得Sint的颜色特征。与D(Si)和N(Si )类似,使用高斯参数μc 和 建立参数化的概率模型:
建立参数化的概率模型:
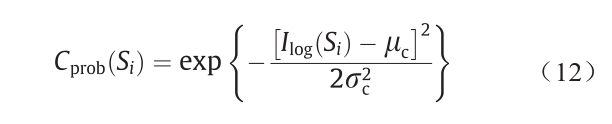
式中,Cprob(Si)表示在给定颜色特征下,Si属于可行驶区域的概率;Ilog(Si)表示Si在颜色空间转化后得到的像素值。
5.2.4. 强度特征
Si的强度特征Sg(Si )度量了超像素的平坦程度,是IDRM与每个超像素的重叠部分。在强度特征下,Si是属 于可行驶区域的概率建模如下:

式中,A(Si )表示Si所占图像坐标系中的区域;dist(Si ,Pbase)表示图像坐标系下Si与Pbase的距离。
《5.3. 贝叶斯框架》
5.3. 贝叶斯框架
本文利用贝叶斯框架进行特征融合。根据相机和激 光传感器的观测结果,找出每一超像素属于可行驶区域 的后验概率,表示为 ,其中,
,其中, 代表上述的所有观测:
代表上述的所有观测:

接下来,将从上述4个特征获得的概率图作为先验条件概率。假设各个超像素是条件独立存在的,则每个超像素属于可行驶区域的后验概率如下:

式中,p(Si = R)表示超像素Si属于可行驶区域的概率,通过对整个图像集的Sint求平均来得到。
《6.实验结果和讨论》
6.实验结果和讨论
为了测试新方法,本文在ROAD-KITTI benchmark上进行实验,使用了289个训练图像和290个测试图像[5]。在鸟瞰图(bird’s eye view,BEV)下,使用以下6个指标对实验结果进行评估:最大F测量(max F-measure,MaxF)、平均精度(average precision,AP)、精确度(precision,PRE)、召回率(recall,REC)、误报率(false positive rate,FPR)和假负利率(false negativerate,FNR)。实验使用了3个数据集:标记的城市数据集(urban marked,UM)、多标记城市数据集(urbanmultiple marked,UMM)和未标记的城市数据集(unmarked,UU)。为了证明本文所提出方法的有效性(下文表中使用“Our method with co-point”表示),本文将其与ROAD-KITTI benchmark上的利用激光传感器的前三最优的方法(HybridCRF、MixedCRF和LidarHisto)进行比较。因为本文提出的方法采用的数据融合与参考文献[36]中使用的方法(RES3D-Velo)类似,本文也列出了与RES3D-Velo方法的对照实验结果。为了显示通过共点映射消除激光点所产生的影响,本文比较了带有和未带有共点映射的方法。此外,本文在训练集上展示了带有共点映射方法的性能,以证明该方法是无监督的。
如表1至表4所示,我们的方法在UMM和UU数据集中,在PRE和FPR度量上取得最佳效果,表明其很好地覆盖了道路区域。就表4来看,我们的方法在AP、PRE和FPR度量上均取得最优性能,表明此方法在不同场景中具有鲁棒性。与没有共点映射的方法相比,我们的共点映射方法消除了大约30%的激光数据(表5),但仍然得到了类似的优越性能。这一发现表明,共点映射可以成功地保留图像的语义结构。最重要的是,虽然我们的方法是无监督的,但与监督方法相比,此方法具有很大竞争力和优势。
《表1 》
表1 与目前最优的三种方法在UM (BEV)数据集上的对照实验结果

《表2 》
表2 与目前最优的三种方法在UMM (BEV)数据集上的对照实验结果

《表3 》
表3 与目前最优的三种方法在UU (BEV)数据集上的对照实验结果
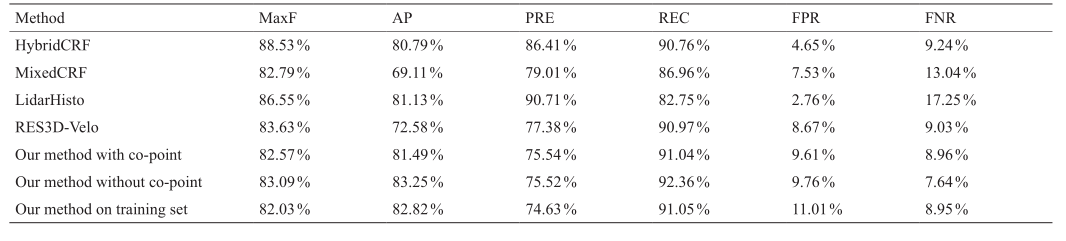
《表4》
表4 与目前最优的三种方法在URBAN (BEV)数据集上对照实验结果,URBAN数据集结合了UM、UMM 和 UU数据集,此结果为以上三种数据集上取得结果的平均值

《表5 》
表5 本文方法所使用的激光点数量

此外,为了验证特征融合过程对算法性能的改善程度,本文将特征融合的结果与每个特征得到的概率图、Sint以及基准进行了比较,如表6至表9所示。同样使用上述数据集的训练集进行对照实验。从表6至表9可以看出,特征融合对MaxF和AP度量改善效果显著。
与使用全部激光点的方法(见下文表中“Fusion without co-point”)相比,具有共点映射的方法在训练集中平均减少了约30 %的激光点(表5),但仍然取得了类似的性能。
《表6 》
表6 在UM训练集(BEV)上的融合性能分析

《表7 》
表7 在UMM训练集(BEV)上的融合性能分析

《表8 》
表8 在UU训练集(BEV)上的融合性能分析

《表9 》
表9 在URBAN训练集(BEV)上的融合性能分析

Sint在REC和FNR度量上表现出优异的性能,与“基准”有近似的FPR,因此,Sint用于估计参数是合理可行的,详见第5节。
如图11所示,在ROAD-KITTI数据集中,由红线围住的图像区域不是被标定为道路真实值的区域。然 而,鉴于这些区域大都平坦可供行驶,并且检测可行驶区域是本研究主要关注的问题,本文倾向于将这些 区域识别为前景。在图11所示的情况下,本文的方法取得的FPR值更高。实际上,这些有界区域具有模糊的语义,包括人行道和道路之间的过渡区以及停车场的入口和车辆开到人行道之前的斜坡。必要时,这些区域中大都可用于车辆行驶。在现实生活中,我们期望自动驾驶汽车会在紧急情况下选择这些平坦区域作为候选道路(如避开突然转弯的车辆)。因此,规划算法应该充分考虑这些区域。
《图11》

11. 具有模糊语义的区域的示例图。由红线围住的图像区域在狭义上不是“道路”,但是这些区域中的许多区域是为车辆行驶而设计的。
《7.结论和工作展望》
7.结论和工作展望
本文提出了一种基于共点映射的自适应可行驶区域检测方法,该方法融合了像素信息和激光点的空间信息,计算了4个特征(DD、NV、颜色和强度特征),并将各个特征在贝叶斯框架中进行融合。基于数据融合,此方法克服了使用单个传感器在处理高度随机和复杂的城市交通场景时的缺点。此方法不需要强假设、训练过程或标记数据。此外,本文使用ROAD-KITTI bench-mark进行实验,证明了此方法的效率和鲁棒性。关于未来的工作,首要任务是将道路划分为可行驶区域和在紧急驾驶情况下可供行驶的区域。接下来,需要一个能够更好地处理模糊语义问题的可行驶区域数据集。最后,需要使用现场可编程门阵列(field-programmable gate array,FPGA)实现此方法,以便在自动驾驶汽车上进行实时应用。
《致谢》
致谢
本研究得到了国家自然科学基金(No. 61773312)、国家重点研发计划(No. 2017YFC0803905)和学科人才引进计划(No. B13043)支持。
《Compliance with ethics guidelines》
Compliance with ethics guidelines
Ziyi Liu, Siyu Yu, and Nanning Zheng declare that they have no conflict of interest or financial conflicts to disclose.











 京公网安备 11010502051620号
京公网安备 11010502051620号




