

《1. 引言》
1. 引言
铝电解槽是一个多变量、能量以及物料实时保持动态平衡的复杂系统。在生产过程中,添加氟化铝能够降低电解质初晶温度,进而降低电解质温度,从而能够减少铝损耗[1,2]。通过准确添加氟化铝在一定程度上可以获得一个规整的炉膛[3]。一些研究表明内型规整的炉膛能够获得较高的电流效率[4,5]。然而,不合理的氟化铝添加量可能会引起炉帮的较大波动,难以获得理想的能量平衡点。由于电解过程的内在复杂性,氟化铝添加量决策主要依赖于工艺人员和领域专家,这对于经验不够丰富的工艺人员是难以胜任的。因经验丰富的工艺人员日益减少以及在业内的频繁流动,过量添加或者欠量添加氟化铝的情况经常发生。因此,亟需一种科学的方法确定准确的氟化铝添加量。
这些问题引起了国内外研究人员的关注。关于氟化铝添加量决策的研究主要有三类,所有这些研究主要集中在控制氟化铝浓度上。第一类主要是依赖经验的决策方法,该方法取决于氟化铝在电解槽内的动态变化。通过分析电解质样品来监测氟化铝浓度,但化验样品频率很低。该方法显示了氟化铝浓度与温度之间具有较强的相关性[6]。在控制反馈回路中的氟化铝浓度调整策略中,使用具有时滞的温度和电解质样品分析值,建立逻辑规则库是这些策略的核心[7–9]。第二类研究认为氟化铝添加量是与目标氟化铝浓度偏差值和(或)温度的函数。在实践中,炉帮厚度的变化会引起氟化铝浓度的改变,并提出了一些线性回归模型[10–12]。在第三类研究中,主要是基于氟化铝物料平衡和(或)能量平衡,提出了一些添加量决策方法。通过分析氟化铝在电解槽的质量演化,构建了氟化铝添加量决策模型,结合详细的过程分析和工艺知识并采用估计和解耦的方法,实现了氟化铝浓度的在线控制[13–17]。第一类决策方法依赖于人类经验,而人类主观性很容易影响知识模型的构建。由于氟化铝添加量决策的复杂性,第二类方法很难捕获氟化铝添加的所有复杂特征。由于在铝电解槽中存在许多检测盲区,因此使用第三类方法难以实现氟化铝的精细化添加。
已有的氟化铝添加量决策方法主要是采用数据驱动以及知识驱动。然而,基于数据驱动方法难以捕获电解槽的复杂特性,基于知识驱动方法可能存在主观性。因此,期望提出一种历史生产数据以及专家经验融合的方法。模糊认知图具有直观和表示因果关系简单等特性,为解决上述问题提供了可能[18]。模糊认知图广泛应用于决策分析、控制建模以及预测中[19–22]。比如,在文献[23]中,为了跟踪光伏阵列的最大功率点,模糊认知图用作一种模糊控制器。在文献[24]中,结合TOPSIS构建了一个模糊多属性决策模型。在文献[25]中,模糊认知图用于评估隧道掘进机的性能,其中引入了经验知识。
模糊认知图由概念节点和边组成,前者引入了定性分析,后者量化了因果关系程度[26]。每一个概念节点代表一种状态。在已有的文献中节点间的因果关系程度通常是由决策者给定,这种因果关系代表了一个节点对另外一个节点的影响程度[27]。通过经验知识选取概念节点以及给定因果关系程度是上述方法的核心[28]。然而,主观性可能影响了构建模糊认知图的准确性[29]。目前,模糊认知图学习方法分为三种,包括基于Hebbian学习法[29‒31]、演化策略[32,33]以及前两种方法的混合策略[34,35]。尽管这些方法广泛应用于模糊认知图的学习中,但是这些方法可能会使学习过程陷入局部最优。
本文提出了一种数据与知识协作的方法,这种方法能够结合专家经验知识以及铝电解数据。基于模糊决策树以及聚类方法,数据用于提取模糊规则,同时结合数据采用STA对权重进行训练寻优。氟化铝添加量决策初始框架首先由专家给出,上述提取的规则用于修正初始框架。这样就可以解决需要依靠权威专家进行模糊认知图建模的问题。基于模糊认知图的氟化铝添加量准确性对权重较为敏感,在此采用STA进行训练优化[29]。将模糊认知图学习结果进行去归一化便可得到氟化铝添加量。对于氟化铝添加量决策,采用强化模糊认知图的决策方法第一次实现了专家经验和数据的融合,并在本研究中验证了该策略的有效性。
本文的框架如下,第2节分析了氟化铝添加的重要性和难点。第3节给出了模糊决策树和改进模糊k 均值。引入了STA优化方法用于训练获取权重。第4节介绍了初始框架的设计以及学习策略。第5节构建了基于强化模糊认知图的氟化铝添加量决策模型,证明了所提方法的有效性。最后一节给出了结论。
《2. 氟化铝添加的相关分析》
2. 氟化铝添加的相关分析
《2.1. 氟化铝的作用分析》
2.1. 氟化铝的作用分析
对铝电解的研究由来已久,由于电解槽的复杂性以及高度非线性,最优的铝电解操作依然是一项具有挑战性的问题。过热度是电解质温度和初晶温度的差值。在电解过程中,合适的过热度使得氧化铝溶解在电解质中,并在电解槽底部产生铝液[4]。文献[2]表明电解质温度上升10 ℃可使得电流效率下降1.2%~1.5%。添加氟化铝使得在较低温度下依然有合适的过热度成为可能。由于在电解中氟化铝逐渐消耗,需要往电解槽中添加氟化铝。然而,不合理的氟化铝添加量可能使得氧化铝溶解性能降低,导致阳极效应频发,最终影响电解槽的物料平衡和能量平衡。当添加氟化铝过量时,过热度增大导致炉帮熔化,影响电解槽的使用寿命。因此,氟化铝添加量决策对铝电解过程非常重要。铝电解槽的示意图如图1所示。
《图1》
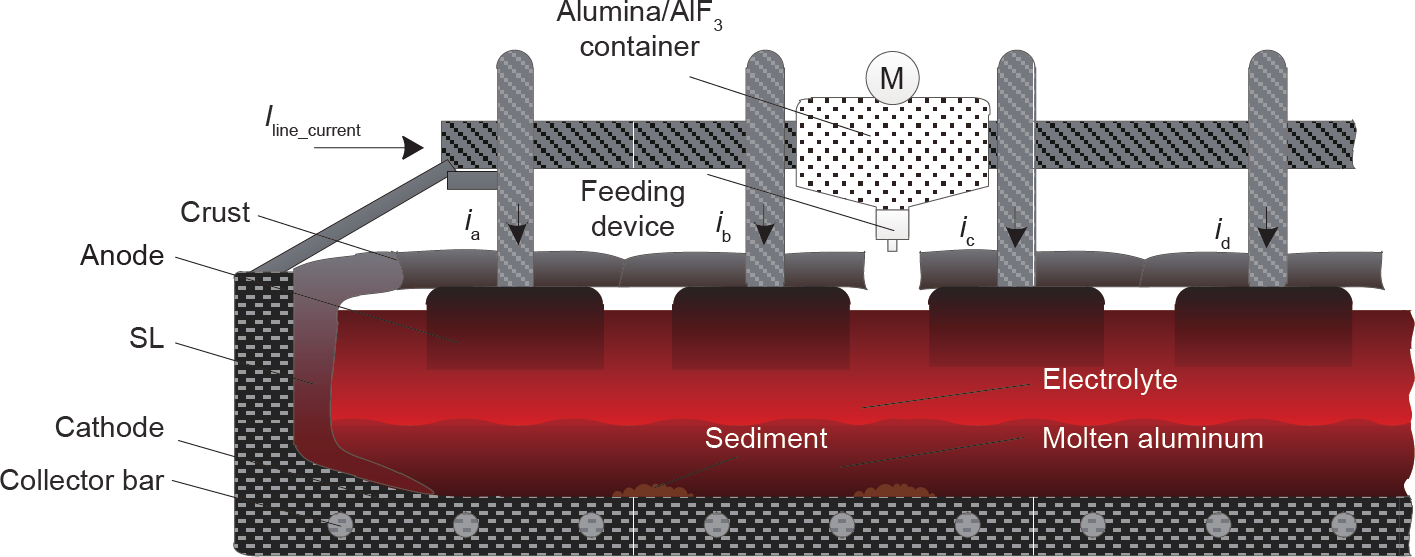
图1. 铝电解槽示意图。
《2.2. 氟化铝的演化分析》
2.2. 氟化铝的演化分析
氟化铝演化分为两类,第一种是氟化铝的中和反应,这是因为氧化铝中含有氧化钠以及氧化钙等杂质,与氟化铝会发生中和反应。第二种包括氟化铝的挥发以及循环,在电解过程中氟化铝、NaAlF4 、氟化钙以及氧化铝颗粒在高温的作用下,会伴随着氟化氢气体挥发走。为了减少污染,电解槽上方安装了一种尾气收集装置。随着温度降低,不稳定的NaAlF4 将会分解为氧化铝和氟化铝。由此尾气得到了净化,纯净的氟化铝将会重新添加到电解槽中[14]。
《2.3. 氟化铝添加量决策的难点分析》
2.3. 氟化铝添加量决策的难点分析
氟化铝添加量决策中需要考虑许多因素,增加了决策的复杂性。类似于其他工业过程,铝电解受到内部以及外部的干扰,如图2所示。但是也有别于其他工业工程,铝电解槽存在高温强腐蚀性,温度高达960 ℃。在这样高温
以及多相场耦合的电解质中发生着剧烈的电化学反应。
《图2》

图2. 铝电解过程中的内部和外部环境。
外部干扰以及内部环境对铝电解过程主要有以下三方面的影响:
(1)换极、出铝以及抬母线将会对能量平衡造成影响,引发氟化铝浓度的改变。
(2)炉帮、沉淀熔化或者凝固都会对氟化铝浓度造成影响。然而,由于高温特性,这种影响程度难以获得。
(3)由于时滞影响,添加氟化铝对电解槽的影响是延迟的,温度将不会立即发生改变。经过一段时间后,炉帮厚度将会变薄,造成能量的损失。因为炉帮变薄,氟化铝浓度将会降低,热量也将产生损耗,此后电解质温度将会稍许地恢复。
因此,氟化铝添加量决策的难度将会增加,原因如下:
(1)干扰:外界操作对氟化铝浓度会有未知的影响。
(2)机理建模复杂性:由于电解质的高温强腐蚀,没有实时测量分析电解成分的装置。氟化铝浓度的测量主要通过长时间的采样以及化学分析。氟化铝浓度的变化难以实时获得。另外,氟化铝浓度的演化过程是非常复杂的,难以建立一种模型去描绘这种过程。
(3)欠量/过量添加:由于时滞的影响,氟化铝添加与过热度的变化不同步,容易造成氟化铝的欠量或者过量添加。
《2.4. 氟化铝添加量决策方法》
2.4. 氟化铝添加量决策方法
基于上述分析,提出了一种新的氟化铝添加量决策方法,如图3所示。这种方法包含基于数据驱动的方法以及知识驱动的方法两个方面。模糊认知图的概念选择、权重取值范围以及初始框架的构建采用专家经验。改进模糊k均值用于构建模糊隶属度函数值,此处属于基于数据驱动的方法。然后,模糊决策树用于提取模糊规则,这些规则对初始框架进行修正。STA优化方法用于训练获取权重。最后,获得了一种基于强化模糊认知图的氟化铝添加量决策模型。总的来说,知识用于引导构建模型,数据用作修正模型。
《图3》

图3. 氟化铝添加量的解决方法。
《3. 所提方法的背景》
3. 所提方法的背景
《3.1. 模糊认知图》
3.1. 模糊认知图
作为一种具有简单直观的图形表示性能和高效推理的模型,模糊认知图是模糊逻辑和神经网络的结合体,并得到了广泛的应用[19]。模糊认知图由概念节点和影响程度组成[20]。模糊认知图的构建主要依赖于具有丰富经验知识的专家,将这些经验知识转化为节点的选择以及关联程度的给定。图4列举了一个简单的模糊认知图实例,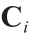 代表一个节点,其数值为
代表一个节点,其数值为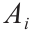 。 表示概念节点的 活跃程度,其取值范围为[0, 1]或[–1, 1] [19,36]。权重表示节点 对节点
。 表示概念节点的 活跃程度,其取值范围为[0, 1]或[–1, 1] [19,36]。权重表示节点 对节点 的影响程度,取值范围为[−1, 1],在三阶逻辑情况下取值为{−1, 0, 1}。然而,三阶逻辑难以描述真实情况 [37]。邻接矩阵如W所示。
的影响程度,取值范围为[−1, 1],在三阶逻辑情况下取值为{−1, 0, 1}。然而,三阶逻辑难以描述真实情况 [37]。邻接矩阵如W所示。
《图4》

图4. 简单的模糊认知图实例。

给定初始状态A(t ) = [A1 (t ); A2 (t ); … ; An (t )](n 代表节点数)和邻接矩阵W,然后每个节点的新状态可通过如下方式进行迭代计算获得。

式中, (t + 1)为概念节点 在时刻t+1的值; (t )为节点 在时刻t 的值;wji 为邻接矩阵W的元素;f 为阈值函数,可将结果映射到区间[0, 1]或[−1, 1] [35]。
《3.2. 状态转移优化算法》
3.2. 状态转移优化算法
学习方法对模糊认知图的计算结果非常重要[29]。迄今为止,基于Hebbian学习法、进化方法以及混合方法在许多文献中得到了应用[38,39]。采用这些方法的目的是获得合适的邻接矩阵。
本文引入了全局优化算法STA [40–43]。每个解被当作问题的一种状态,当前解决方案的更新被认为是一种状态转换。STA候选解的生成过程如下:
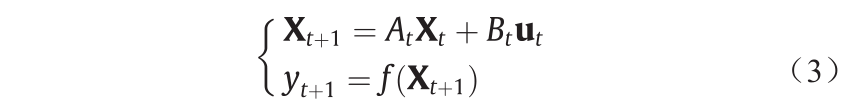
式中, 代表候选方案;At 和Bt 代表变换算子;ut为关于X以及历史状态的函数;
代表候选方案;At 和Bt 代表变换算子;ut为关于X以及历史状态的函数; 为目标函数。
为目标函数。
候选解决方案是根据以下四个特殊的状态转换操作算子生成的。
1)旋转变换
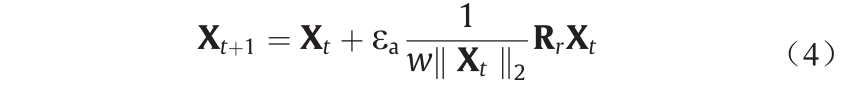
式中,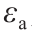 为旋转因子;
为旋转因子; 为随机矩阵;
为随机矩阵;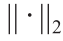 为向量的2-范数。在给定半径
为向量的2-范数。在给定半径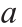 的情况下,通过超球面域内的旋转变换得到候选解;旋转变换是一个局部搜索算子。
的情况下,通过超球面域内的旋转变换得到候选解;旋转变换是一个局部搜索算子。
2)平移变换

式中, 为平移因子,每一个
为平移因子,每一个 是一个从0到1的随机变量。平移转换可以生成一个行搜索,只有在其他转换操作符可以找到更好的解决方案时才会执行。
是一个从0到1的随机变量。平移转换可以生成一个行搜索,只有在其他转换操作符可以找到更好的解决方案时才会执行。
3)伸缩变换
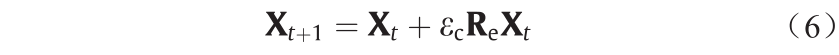
式中,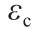 为伸缩因子,
为伸缩因子, 为一个随机对角矩阵,它里面的每个元素服从高斯分布。伸缩变换具有使
为一个随机对角矩阵,它里面的每个元素服从高斯分布。伸缩变换具有使 中的每个元素伸缩变换到[–∞, ∞]的功能,从而实现在整个空间进行搜索。
中的每个元素伸缩变换到[–∞, ∞]的功能,从而实现在整个空间进行搜索。
4)坐标搜索
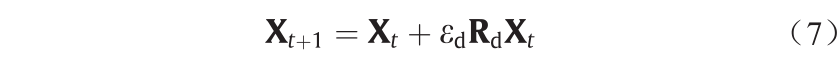
式中,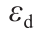 为正常数,称作坐标因子,
为正常数,称作坐标因子, 是一个随机对角稀疏矩阵,它只在某个随机位置有非零元素,且该元素服从高斯分布。坐标搜索具有沿着坐标轴方向搜索的功能,它的目的是为了增强单维搜索能力。
是一个随机对角稀疏矩阵,它只在某个随机位置有非零元素,且该元素服从高斯分布。坐标搜索具有沿着坐标轴方向搜索的功能,它的目的是为了增强单维搜索能力。
对于一个给定解,可以通过状态转换算子产生许多不同的候选解。在本文设定可以产生30个候选解,在每一次迭代计算中,变换运算符是交替独立应用的。根据目标函数采用STA优化方法可以找到模糊认知图最优的邻接矩阵。
《3.3. 知识提取以及隶属度函数设计》
3.3. 知识提取以及隶属度函数设计
3.3.1. 基于模糊决策树的知识提取
本文中提取到的知识采用模糊规则的形式进行表示,并将这些规则对初始框架进行修正。已有许多从数据中提取知识的方法,其中包括神经网络[44]、支持向量机[45]等。尽管这些方法能够构建一种知识库,但对于模糊不确
定信息性能较弱[46]。在铝电解中工艺人员常采用模糊语言描绘电解槽状态[1]。此外,经验不够丰富的人员难以理解上述方法产生的结果。因此,期望提出一种方法,通过该方法获得的结果简单明了,不存在黑箱化,便于工艺人员理解。在本文中引入了模糊决策树进行知识提取。
模糊决策树归纳法可以将技术人员的认知不确定性明确地表达、度量并融入到知识归纳法中。在归纳过程中,该方法可以减少模糊证据分类的模糊性[46]。因此,模糊决策树归纳法适用于处理铝电解过程中的认知不确定性问题[46]。
3.3.2. 基于改进模糊 k 均值的隶属度函数设计
用于提取模糊规则的隶属度通常由专家提供,然而,专家的主观性可能会影响提取结果。为此,提出了一种隶属度函数设计方法。由于电解槽生产环境恶劣,实测数据中存在大量噪声,甚至出现孤立点。为了解决传统的模糊k 均值对孤立点敏感的问题[47],提出了一种改进的模糊k均值算法。基于改进的模糊k 均值,我们得到k 个聚类中心c1 ,c2 ,…,ck ,其中,k 等于实际模糊划分的个数。
样本点xi 到聚类中心ck 的距离定义如下:

式中,xi 和xj 分别为第i 个和第j 个样本点;ck 为第k 个聚类中心;N为相邻样本点个数;U为邻域采样点的集合; αk 为平滑因子,当样本空间越均匀时, αk 值越小。 αk的定义如公式(9)和公式(10)所示。
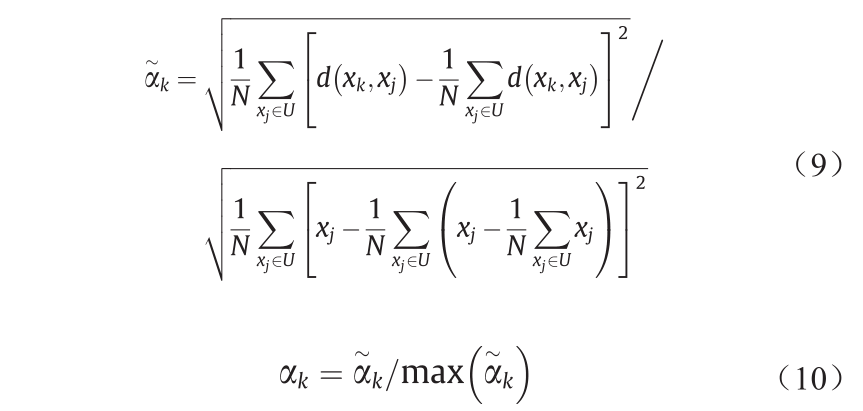
样本点xi属于第k类的隶属度为µik :
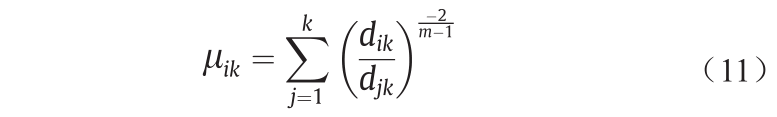
计算聚类中心如公式(12)所示:
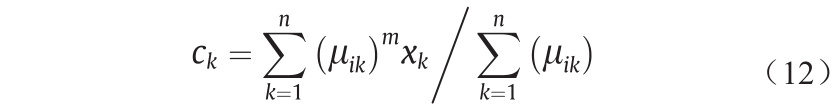
式中,m为加权指数,默认值为2。
针对每个概念的模糊划分,构建了一种基于聚类中心的隶属度函数如公式(13)至公式(15)所示。
当i = 1时,隶属度函数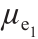 如公式(13)所示。
如公式(13)所示。

当1 < i < k,隶属度函数如公式(14)所示。

当i = k,隶属度函数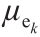 如公式(15)所示。
如公式(15)所示。
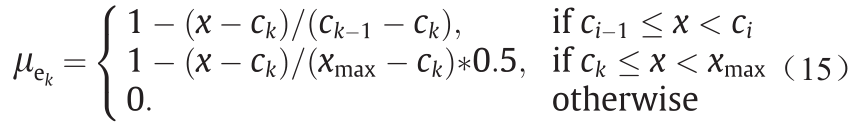
其中, 为样本x 隶属于第i 个模糊划分的隶属度;ci 为第i 个聚类中心;xmin 和xmax 分别为最小值和最大值。
在本节中,我们得到了基于改进的模糊k 均值的k 个聚类中心和基于公式(13)至公式(15)的模糊划分的隶属函数。基于这些方法,我们可以得到用于提取模糊规则的生产数据的隶属度。
《4. 构建新的氟化铝添加量决策模型》
4. 构建新的氟化铝添加量决策模型
氟化铝添加量的计算通常采用简单的公式或由技术人员决定。然而,由于电解槽的复杂性,公式很难捕获所有特征,技术人员的经验知识并不总是正确的。因此,基于数据驱动或知识驱动方法保证了氟化铝添加量的准确性。本节结合模糊认知图、知识获取方法和数据处理方法,构建了基于数据和知识协作的氟化铝添加量决策模型,主要步骤如下。
步骤1:概念节点和取值范围以及概念之间的因果关系由专家确定,给出氟化铝添加量决策模型的初始框架,这一步是基于知识驱动的。
步骤2:生产数据经过预处理,包括选择和转换。然后,得到了基于改进模糊k 均值的聚类中心,用于生成每个模糊划分的隶属度函数。利用隶属度提取模糊规则。这一步是数据驱动的。
步骤3:利用模糊规则对初始结构进行修正,得到了氟化铝添加量决策模型的期望框架。这一步是知识驱动的。
步骤4:引入STA来训练优化权重,得到了最终的添加量决策模型,得到了期望的氟化铝添加量。这一步是数据驱动的。
步骤5:通过加料装置将目标添加量加入电解槽中。
基于以上步骤,氟化铝添加量决策模型构建过程的细节如下。
《4.1. 氟化铝添加量决策模型初始框架的设计》
4.1. 氟化铝添加量决策模型初始框架的设计
经过咨询和调研,专家选出13个概念节点,不仅可以覆盖氟化铝添加量决策模型的特性,还可以降低计算复杂度。表1列出了13个变量以及对应的模糊划分。
《表1》
表1 概念节点的模糊划分
定义1. 相邻两天间的差值被定义为一个计算周期:
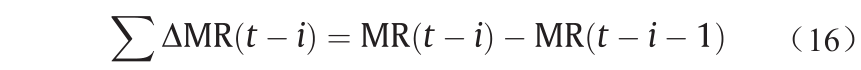
式中,MR(t )为在t 时刻的分子比值,MR(t − i )代表第t − i 天的值。其他变量的定义与分子比类似。
定义2. 由于铝电解的特殊性,MR变化不明显。难以用较少的计算周期来反应MR最近的变化,但是也没有必要考虑更多的计算周期。在实践中,MR的四个计算周期的累积值是合理的,其定义如下:
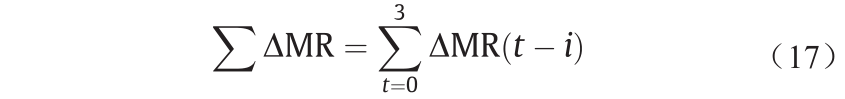
根据经验知识,MR是NaF与AlF3 的比值[4]。MR越低,电解质温度(ET)越低[1]。炉帮的厚度随着ET的变化而变化;此外,MR的变化可能是由于过去几天的电解质凝固或炉帮熔化引起的,ET越高,MR越高[1]。因此,节点C1 和C2 之间存在连接。此外,电解质电阻随MR的变化而变化,平均电压(MV)越高,ET越高[1]。因此,对于设定电压和氟化铝添加量,应考虑MR、ET和MV,并且存在从MR、ET和MV到AFA的连接。这些累积的变化表明了概念的变化趋势。显然,存在从∑ΔMR、∑ΔET、∑ΔMV到AFA的连接。铝水平(AL)的散热和电解质水平(EL)的保温性通常用于调节电解槽能量平衡。AL越高,ET越低;EL越高,ET越高。MV用于调节能量输入。由于对能量变化的影响,应该存在从MR、ET、MV和AL到设置电压(SV)的连接。因此,在氟化铝添加量决策建模中应考虑这些因素以及累积量。实际上,出铝量(TA)、AFA和SV用于调整能量平衡并相互影响。
基于以上分析,得到了氟化铝添加量决策模型的初始结构,如图5所示。初始结构将使用第3.3.1和3.3.2节中提出的方法进行重构。然而,节点的影响程度仍然是未知的。在下一节中,我们将引入STA来优化训练权重。
《图5》

图5. 氟化铝添加量决策模型初始框架。
《4.2. 基于 STA 学习的模糊认知图》
4.2. 基于 STA 学习的模糊认知图
构建简单的模糊认知图,可以通过专家经验给定权重,但如图5所示的复杂模糊认知图,专家经验无能为力。因此,迫切需要开发一种学习算法。在本研究中,STA被引入作为一种学习算法来消除专家干预。虽然STA被广泛
应用于许多领域[40–43],但这是首次将其用于模糊认知图的学习过程。当目标函数达到最小值时,得到模糊认知图的一组期望权值,从而获得邻接矩阵。
目标函数必须定量地度量给定候选解决方案的适用性;它迭代计算概念的估计值和实值之间的差值。在所提方法中,概念和权值的预定义区间的目标函数如公式(18)所示。在铝电解过程中,概念值在一定范围内变化,需要将概念值限制在一个区间内, 。在实践中,因果关系的程度可以是正的,也可以是负的。例如,铝水平越高,损失的热量越多,可知AL与ET之间影响程度为负值,ET和EL间的影响程度为正值。因此,权重值须根据实际情况限定在一定范围内:
。在实践中,因果关系的程度可以是正的,也可以是负的。例如,铝水平越高,损失的热量越多,可知AL与ET之间影响程度为负值,ET和EL间的影响程度为正值。因此,权重值须根据实际情况限定在一定范围内: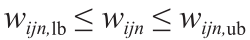 。
。
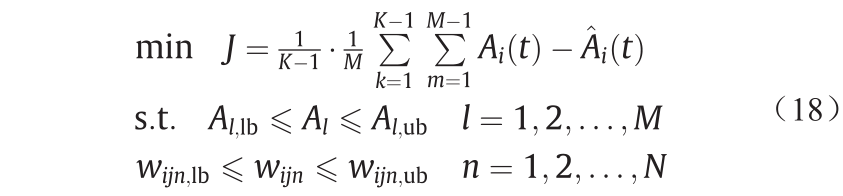
式中,N 和M 是权重和概念节点数量;K 为学习次数;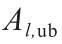 和
和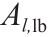 为上、下界;
为上、下界;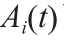 可通过公式(2)计算获得;
可通过公式(2)计算获得;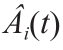 为期望值;
为期望值; 为每个权重的上、下界值。
为每个权重的上、下界值。
《5. 结果与讨论》
5. 结果与讨论
为了验证所提方法的可行性,本节讨论了在铝电解过程中添加AlF 3 的实验研究结果,收集了2016年6月和2016年7月的工业数据。在铝电解过程中,每天都要测量AL、MV、EL和ET,每两天测量一次MR,将最近两天的平均值用于缺失值。MR、ET、MV、AL和EL以及相应的累积变化如图6、图7所示。
《图6》

图6. MR、ET、MV、AL和EL的值。
《图7》

图7. MR、ET、MV、AL和EL的累计变化值。
《5.1. 氟化铝添加量决策模型的框架修正》
5.1. 氟化铝添加量决策模型的框架修正
为了解决氟化铝添加量决策建模过程中需要专家介入的问题,提出了一种结合改进模糊k 均值和隶属函数生成方法的知识提取方法。
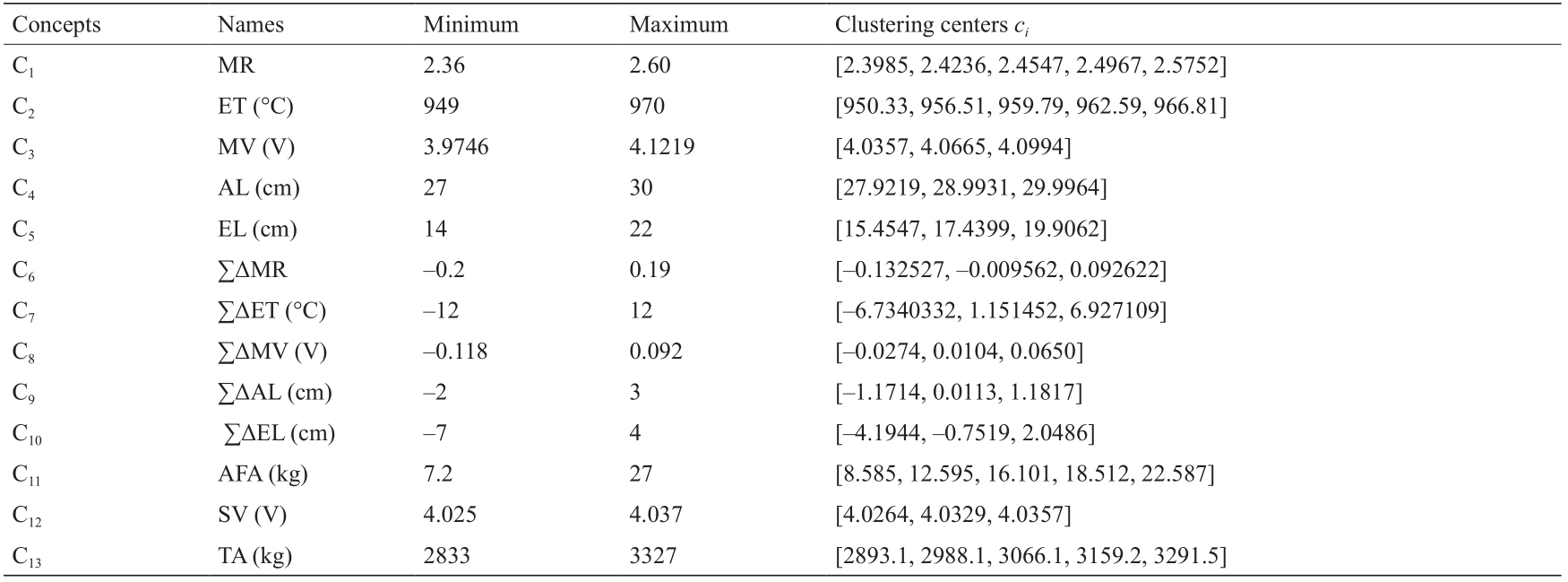
首先,由改进模糊k 均值生成聚类中心,统计结果如表2所示,包括最小值、最大值和聚类中心。聚类中心的数量等于模糊分区的数量。MR、∑ΔMR、TA、SV和AFA的隶属函数如图8所示。概念的其他隶属函数与图8所示的相似,在此省略以节省空间。
《表2》
表2 基于改进模糊k 均值的聚类中心ci
《图8》

图8. 基于改进的模糊k 均值产生的关于公式(13)至公式(15)的隶属度函数。(a)和(b)分别为分子比以及变化累积值的隶属度函数; (c)~(e)分别为TA、SV和AFA的隶属度函数。
其次,由于氟化铝添加量决策模型的复杂性,专家很难描述其因果关系。模糊规则是概念之间关联关系的表达,也是隐性知识表示的一种手段,如下所示。
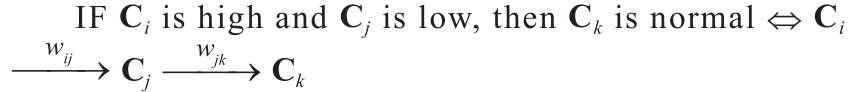
因此,可以基于知识提取方法来挖掘关联规则。采用模糊决策树以提取模糊规则,其变量包括MR、ET、MV、AL、EL、 ∑ΔMR、 ∑ΔET、 ∑ΔMV、 ∑ΔEL、 ∑ΔAL、AFA、SV和TA。这些变量的隶属度是模糊决策树的输入,基于公式(13)至公式(15)产生。算法1~6中为模糊决策树归纳方法的伪代码。 其中,G和GGambiguity 分别为分类不确定性和模糊度函数。 分别为第i个属性以及第i 个分类的数据集。S 和
分别为第i个属性以及第i 个分类的数据集。S 和 分别为模糊包含度以及第i 个属性的第j个划分。另外,
分别为模糊包含度以及第i 个属性的第j个划分。另外, 分别为第i 个属性的第j 个划分数据以及第i 个分类的第j 个划分数据。ms 和G_CE分别为划分数目和每个父节点的模糊度。AMBIGUITY为歧义性函数。C_mu 和
分别为第i 个属性的第j 个划分数据以及第i 个分类的第j 个划分数据。ms 和G_CE分别为划分数目和每个父节点的模糊度。AMBIGUITY为歧义性函数。C_mu 和 分别为分类隶属度以及每个父节点和子节点每个模糊划分的分类歧义性。ClassAmbiguityWithP为父节点的分类歧义性函数。mu E模糊证据的隶属度。mu F为每个模糊划分的隶属度。mu C为每个分类的隶属度。
分别为分类隶属度以及每个父节点和子节点每个模糊划分的分类歧义性。ClassAmbiguityWithP为父节点的分类歧义性函数。mu E模糊证据的隶属度。mu F为每个模糊划分的隶属度。mu C为每个分类的隶属度。


由于氟化铝添加量决策的复杂性和技术人员认知的局限性,一些规则被忽略。由于铝电解过程的特殊性,不仅 影响
影响 , 也影响 。由于模糊决策树产生了大量的模糊规则,我们只给出与专家建议的规则不同的具体规则。这些规则用于修改氟化铝添加量决策模型初始结构,如下所示。
, 也影响 。由于模糊决策树产生了大量的模糊规则,我们只给出与专家建议的规则不同的具体规则。这些规则用于修改氟化铝添加量决策模型初始结构,如下所示。
• If C1 is high and C2 is high and C4 is normal and C7 is low then C11 is very high;
• If C1 is very high and C2 is normal and C3 is high and C4 is low and C9 is high then C11 is very high;
• If C1 is high and C2 is very low and C5 is high and C10 is low then C13 is very high;
• If C3 is low and C1 is normal and C6 is high and C7 is high and C8 is high and C9 is high then C11 is very low;
• If C3 is low and C5 is high then C13 is high.
• If C4 is high and C1 is normal and C6 is high and C7 is high then C12 is low;
• If C5 is normal and C1 is normal and C2 is normal and C3 is high and C4 is low then C11 is high;
• If C8 is high and C10 is low then C13 is low;
• If C10 is normal and C8 is low and C9 is high then C12 is high.





第三,基于上述模糊规则,找出这些概念之间的潜在联系。通过新发现的规则重构初始框架;氟化铝添加量决策模型的新结构如图9所示。
《图9》

图9. 重构后的氟化铝添加量决策模型框架。
知识获取的过程是基于数据驱动的方法。利用上述特殊规则对初始结构进行重构,得到强化结构。重构过程涉及数据与知识的融合,是一个数据与知识协同的过程。
《5.2. 模糊认知图学习用于氟化铝添加量决策》
5.2. 模糊认知图学习用于氟化铝添加量决策
目前,我们得到了氟化铝添加量决策模型的理想结构。在接下来的章节中,我们将基于STA来获得强化FCMs的权重。向量Ainitial 表示在铝电解过程中给定时间内,概念的初始状态。由于A i 值在[−1, 1]中,实际生产数据按公式(19)进行归一化。
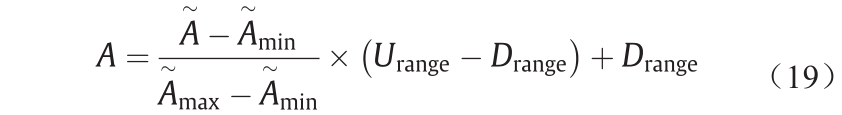
式中,  为节点真实值;
为节点真实值; 为最大值和最小值;Urange 和Drange 为归一化后的最大值和最小值。如果真实值全部为正,则Urange = 1以及Drange = 0;当真实值中存在负值,则Urange = 1及Drange = –1。
为最大值和最小值;Urange 和Drange 为归一化后的最大值和最小值。如果真实值全部为正,则Urange = 1以及Drange = 0;当真实值中存在负值,则Urange = 1及Drange = –1。
最后,我们需要获得真实的氟化铝添加值,须将Afinal进行去归一化处理,如公式(20)所示。
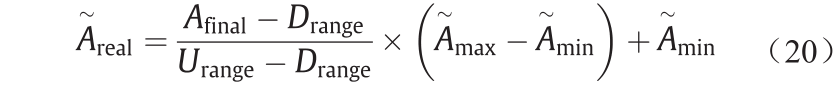
式中,Afinal 为概念节点迭代计算后的最终值;  为实际情况下的真实值。
为实际情况下的真实值。
节点初始值为Ainitial ,如下所示:

阈值函数如下所示:

向量Afinal 为模糊认知图可达的最终状态,Afinal,STA 为基于STA的最终值。

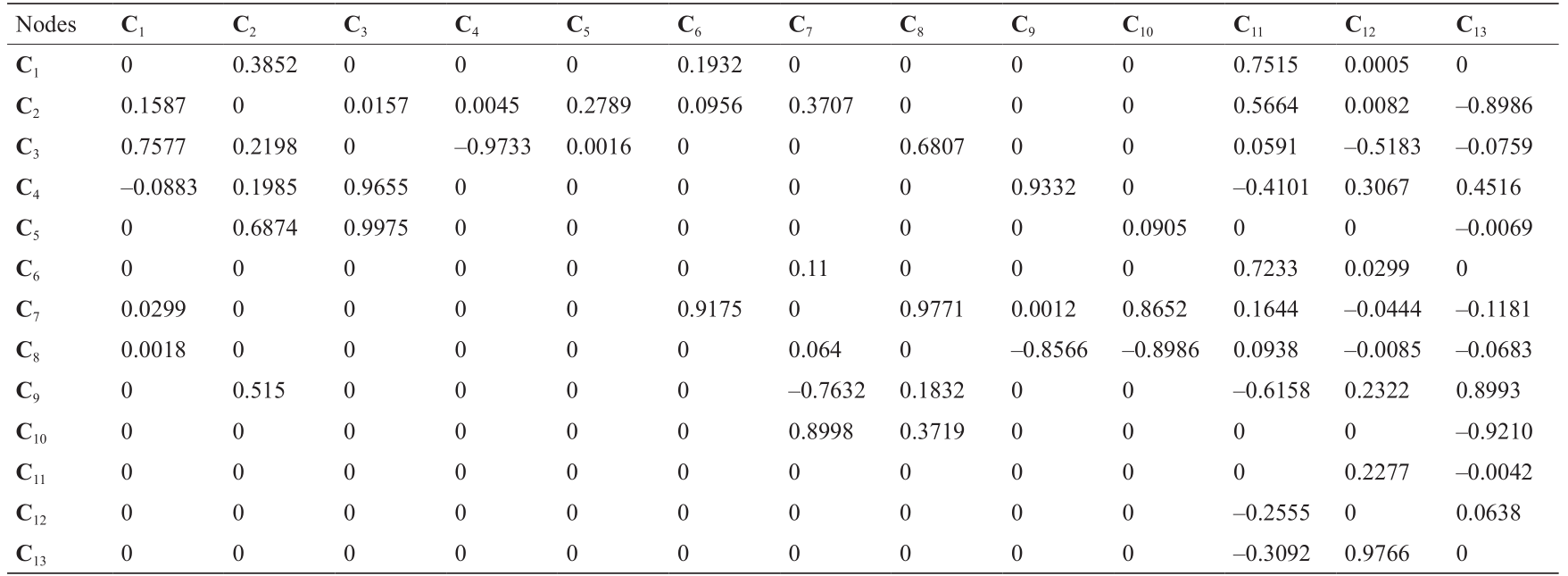
节点间的权重值如表3所示。
《表3》
表3 关于图9中节点间的权重
基于STA、FCM的学习结果如图10所示。为了与STA进行比较,选择了Dickerson和Kosko [48]提出的差分Hebbian学习(DHL)算法,结果如图11所示,共有50次的迭代计算结果。结果表明,在第32次迭代之后,模糊认知图达到一个平衡区域,而基于STA需要进行16次迭代。使用上面的Afinal ,Afinal,DNL 如下所示:

《图10》

图10. 基于STA的模糊认知图学习结果。
《图11》

图11. 基于差分Hebbian学习的模糊认知图学习结果。
从图12可以看出,基于粒子群优化(PSO)算法并经过37次迭代后,模糊认知图收敛到一个稳定的区域。在Afinal 相同的情况下,基于PSO的节点值Afinal,PSO 如下:

《图12》
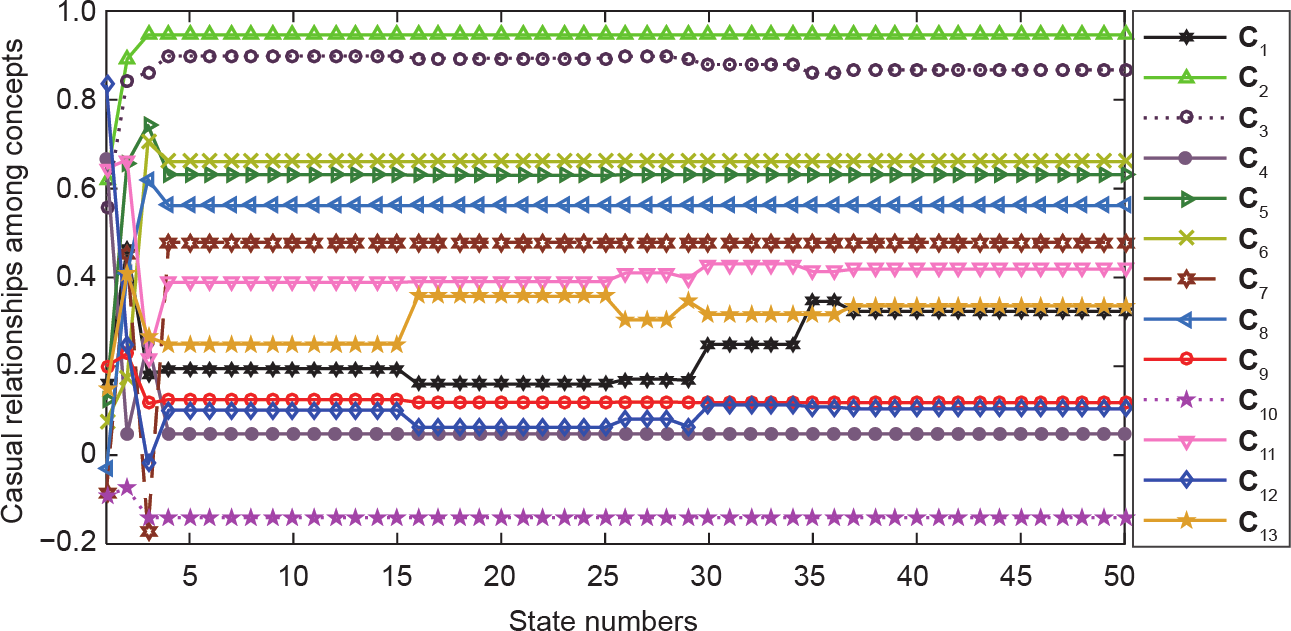
图12. 基于PSO学习的模糊认知图学习结果。
图13为迭代100次结果,在第74次迭代后,趋于稳态;该算法收敛速度较慢,收敛稳定。在上述Afinal 条件下,基于GA的概念的最终计算值Afianl,GA 如下:

《图13》

图13. 基于GA学习的模糊认知图学习结果。
从图10至图13可以看出,基于STA的收敛速度要快于基于DHL、PSO和GA的收敛速度。为了验证本文提出的AFA策略,利用式(20)将基于STA、DHL、PSO和GA计算的C11 值转换为真实值。
首先,较低的针振、摆动以及平均电压值是AlF3 添加结果优于工艺人员的标志。对应较低的针振、摆动以及平均电压值,选择C1 ~C13 的真值进行验证。针振、摆动以及平均电压的数据如图14所示。
《图14》

图14. 针振、摆动以及平均电压值。
其次,分别采用STA、DHL、PSO和GA计算氟化铝添加量。对已有的氟化铝添加量决策方法进行比较,包括线性规划模型[12]和模糊控制方法[49]。在实际中,由于氟化铝被分成批次进行添加,每次添加量为1.6 kg。基于修正后的结构和初始结构的氟化铝添加次数分别如图15、图16所示。此外,结合初始框架并采用传统模糊k 均值的氟化铝添加次数如图17所示。表4给出了基于改进模糊k 均值并采用修正结构和初始结构的氟化铝添加分析结果,以及基于传统模糊k 均值并采用初始结构的氟化铝添加分析结果。
《表4》
表4 基于修正和初始结构各种学习算法的MPAE

《图15》

图15. 修正结构下各算法的添加次数。(a)基于STA的添加次数; (b)基于DHL; (c)基于PSO; (d)基于GA; (e)基于线性规划模型; (f)基于模糊控制。
《图16》

图16. 初始框架下各算法的添加次数。(a)基于STA; (b)基于DHL; (c)基于PSO; (d)基于GA。
《图17》

图17. 采用修正结构和传统模糊k 均值时各算法的添加次数。(a)基于STA的添加次数; (b)基于DHL; (c)基于PSO; (d)基于GA。
第三,表4和图16、图17显示,在初始结构下,使用STA,基于传统模糊k 均值和改进模糊k 均值的AFA的MPAEs分别为10.1028和10.0766。这意味着在初始结构下,基于改进模糊k 均值和STA的AFA可以获得更高的精度。与上述结果相比,由表4和图15可知,当AFA的MPAE为6.2521时,基于修正结构下的STA和EFKM,其结果低于上述结果。这说明基于修正结构的AFA的精度要大于基于初始框架的AFA。
《5.3. 总结》
5.3. 总结
基于强化模糊认知图设计了一种用于氟化铝添加量决策的数据和知识协作模型。从生产数据库中选择数据,并从铝电解专家和生产数据中提取知识。为了减少对专家的依赖,使用了知识提取技术来丰富氟化铝添加量决策模型的结构。数据驱动的方法被用来消除专家的主观性,知识驱动的方法被用来指导氟化铝添加量决策模型的构建。由于铝电解过程的复杂性,技术人员很难提供所有模糊规则。改进模糊k 均值和模糊决策树被用于模糊规则提取,以重建氟化铝添加量决策模型的初始结构。由于权重数量较多,专家很难提供这些权重。在本研究中,通过引入STA解决了该问题。从本质上讲,这项研究的主要任务是基于数据驱动和知识驱动的方法,提出一种使用FCM的氟化铝添加量决策的新策略。实际上,这是第一次将基于FCM的数据和知识协作引入氟化铝添加量决策。
本文选取对应于低针振、低摆动以及低平均工作电压的生产数据。首先,根据图10至图13可知,STA具有比其他学习方法更快的收敛速度,同时基于STA的MPAE低于基于其他学习算法的MPAE。其次,基于改进模糊k 均值的MPAE低于基于传统模糊 均值的MPAE,与初始结构相比,在修正结构下基于STA的MPAE更低。此外,最大绝对误差等于0.4498意味着在实际进料量和计算值之间仅存在0.8094 kg的误差,对于复杂的铝电解过程而言,这是可接受且合理的。第三,与现有的氟化铝添加量决策方法相比,该方法具有更好的性能。
均值的MPAE,与初始结构相比,在修正结构下基于STA的MPAE更低。此外,最大绝对误差等于0.4498意味着在实际进料量和计算值之间仅存在0.8094 kg的误差,对于复杂的铝电解过程而言,这是可接受且合理的。第三,与现有的氟化铝添加量决策方法相比,该方法具有更好的性能。
《6. 结论》
6. 结论
本文提出了基于强化模糊认知图实现数据和知识协作的氟化铝添加量决策策略。在实际中,AFA由技术人员决定,他们将数据报告与经验知识相结合,给出氟化铝添加量。模糊认知图能够捕获各种知识、处理复杂模型和知识问题的有效工具。因此,对于铝电解工艺人员而言,模糊认知图比其他策略更容易理解。知识驱动技术用于概念选择和初始结构构建,数据驱动方法用于知识提取以重建初始结构,从而丰富了知识库。引入了学习算法STA来训练优化模糊认知图权重,并将结果与其他学习算法的结果进行比较。此外,将提出的氟化铝添加量决策方法与现有研究的策略进行了比较,结果表明,所提出方法是有效的,且比其他氟化铝添加量决策方法更有效。所提出的方法将有可能应用于氟化铝添加的自动决策中。结果表明,对于氟化铝添加量决策,基于强化模糊认知图具有增强的潜在性能。这些结果鼓励我们继续解决另一个具有挑战性和相关性的问题,即铝电解过程中下料间隔优化问题。
《致谢》
致谢
本项目由国家自然科学基金(61773405、61533020、61621062、61725306)和中南大学创新工程(502390003)资助。
《Compliance with ethics guidelines》
Compliance with ethics guidelines
Weichao Yue, Weihua Gui, Xiaofang Chen, Zhaohui Zeng, and Yongfang Xie declare that they have no conflicts of interest or financial conflicts to disclose.











 京公网安备 11010502051620号
京公网安备 11010502051620号




