

《1. 引言》
1. 引言
据美国土木工程师协会(American Society of Civil Engineers, ASCE)报道,美国有超过56 000座桥梁存在“结构缺陷”。对老化桥梁进行经济有效的管理正在成为美国国家交通部门和政府面临的一项艰巨任务。在做出任何修复及预防决策之前,都需要对桥梁进行可靠的状态评估。尽管这种担忧会促使桥梁业主进行频繁的桥梁结构检查,但传统的无损评价(NDE)与目测检查法的应用均需对单个元素进行逐点检查,以在结构中发现具有多个缺陷的位置。此外,考虑到检测人员的人身安全,检测过程中需关闭桥梁。这些方法往往耗时长、成本高、主观性强,且高度依赖于检测人员的经验。许多研究小组一直在探索可替代的结构健康监测(SHM)方法来应对这些限制[2-4]。尽管全局性的SHM技术似乎很有前景,但该方法只能对结构行为进行粗略评估,而不能提供详细信息[5-6]。此外,由于噪声信号、传感器缺陷或采集系统设置的问题,对由SHM法收集到的结果进行解读也并非易事。
近年来,基于视觉的检测方法在民用基础设施损坏检测实践中越来越受到重视。有许多研究都旨在检测裂缝、腐蚀等设施表面的缺陷。例如,分割[7]、滤波[8-9]和基于立体视觉的方法[10]已被用于检测结构系统中的裂缝和类似裂缝的特征。基于视觉的方法通常遵循两个步骤来检测裂缝[11]。在第一步,研究者将使用统计滤波器对图像进行滤波,并在局部提取裂缝特征以融合图像。第二步则是清除和链接图像片段以定义裂缝[11]。研究者还开发了消除阴影的算法来消除此类图像中的阴影,并准确定位裂缝[12-13]。然而,桥梁的检测数据是在各种情况下收集的,因此具有很大差异。诸如由照明条件和失真引起的噪声、对先验知识的依赖以及图像数据的质量等问题对裂缝检测的可靠开展仍然具有挑战性。
为解决这些问题,一种具有可行性的方案是部署机器学习(ML)方法。基于ML的方法已广泛用于SHM和NDE [14-16]领域。这些方法一般用于解释从测试系统收集的信号数据,因此,它们往往能反映出关于结构系统状况的有用信息。最近,该领域的工作重点是整合图像特征提取与ML技术来开发新型的SHM和NDE系统[17-19]。然而,使用过度提取或错误提取的特征通常会使模型开发变得非常复杂。卷积神经网络(CNN)可以通过提取有效的图像特征来克服这个问题。CNN是一类深度学习算法,其灵感来自于动物的视觉皮层[20]。这种方法可以有效地捕捉图像的网状拓扑结构。由于神经元连接稀疏,加上合并过程会缩小图像尺寸,因此需要更少的计算量。此外,CNN在大量的分类工作中亦表现出了可靠的性能[21,26]。由于其在图像数据处理中出色的表现,CNN正在成为SHM系统的有效工具[22-25]。最近,Azimi和Pekcan [27]介绍了一种用于SHM的CNN方法,该方法使用迁移学习技术来压缩响应数据。他们的CNN模型经加速度响应历史数据训练而得。随后又通过实验数据对所建立的模型进行验证。Soukup和Huber-Mörk [28]提出了一种基于CNN的铁路缺陷检测方法。Cha等[29]提出了一种应用于混凝土表面的深度学习裂缝损伤检测系统。Da Silva和de Lucena [30]开发了一个用于混凝土裂缝检测的CNN图像分类器。尽管已经取得了可喜的进步,但现有的基于深度学习的SHM方法仍存在计算强度大、训练时间长等方面的缺陷。这些限制不仅影响了这些方法在实践中的实用性,并且还阻碍了实时状态评估系统的开发。
本研究提出了一种用于检测桥面裂缝的实时深度学习方法。为此,我们将一维(1D)卷积神经网络(CNN)与被称为长短期记忆(LSTM)的人工循环神经网络(RNN)架构相结合。本研究提出的1D-CNN-LSTM算法使用的是传输到频域而不是空间域的图像进行训练。采用这种策略可以有效减少计算时间、提高检测精度。我们将在下文讨论该系统在实时裂缝检测方面的效率。本文结构如下:第2节介绍了深度学习方法的相关细节;第3节概述了该检测方法以及用于模型校准的数据库,并描述了预处理步骤与网络架构;第4节提供了检测结果,并讨论了该方法在其他测试数据集上的应用;第5节提供了与现有深度学习方法和两种常用的边缘检测器方法的比较研究;最后一节则进一步讨论并得出结论。
《2. 方法》
2. 方法
《2.1. 卷积神经网络》
2.1. 卷积神经网络
深度学习是ML的一个子集,能够使用多层人工神经网络结构从原始数据中提取更高层次的特征。深度学习也被称为深度神经学习或深度神经网络。在这类技术中,CNN是最为人所熟知的深度学习架构。CNN的灵感来自于动物视觉皮层的生物学过程[31-32]。在视觉处理中,单个的皮层神经元会对特定的各个区域做出响应。然后,不同神经元各自的视野会被部分重叠以实现对整个视野的覆盖。CNN至少在其一层中使用数学运算卷积进行一般矩阵乘法[33]。一个CNN通常由一个输入层、多个卷积层、池化层、全连接层和一个输出层组成。通常,输入层以形状张量(图像数量×图像宽度×图像高度×图像通道)的形式呈现。卷积层会对输入的局部区域应用多个滤波器,以提取图像的特征图,其张量的形状为图像数量×特征图宽度×特征图高度×滤波器数量。例如,如果输入A张图像,每张图像大小为M × N像素、含C个颜色通道,则输入张量的形状将为A × M × N × C。假设滤波器的数量为k,滤波器i的权重为W,b为滤波器i的偏差,x表示滤波器窗口补丁,a为激活函数[如整流线性单元(ReLU)、sigmoid和tanh],那么在给定每个图像的滤波器i的情况下,x的卷积定义如下:
(1)
滑动滤波器窗口,使其通过每张图像[每张图像在所有维度上的补丁窗口大小为f × f × C和步长为s(即滤波器在每个方向上的移动步长)],则卷积输出大小为
《图1》
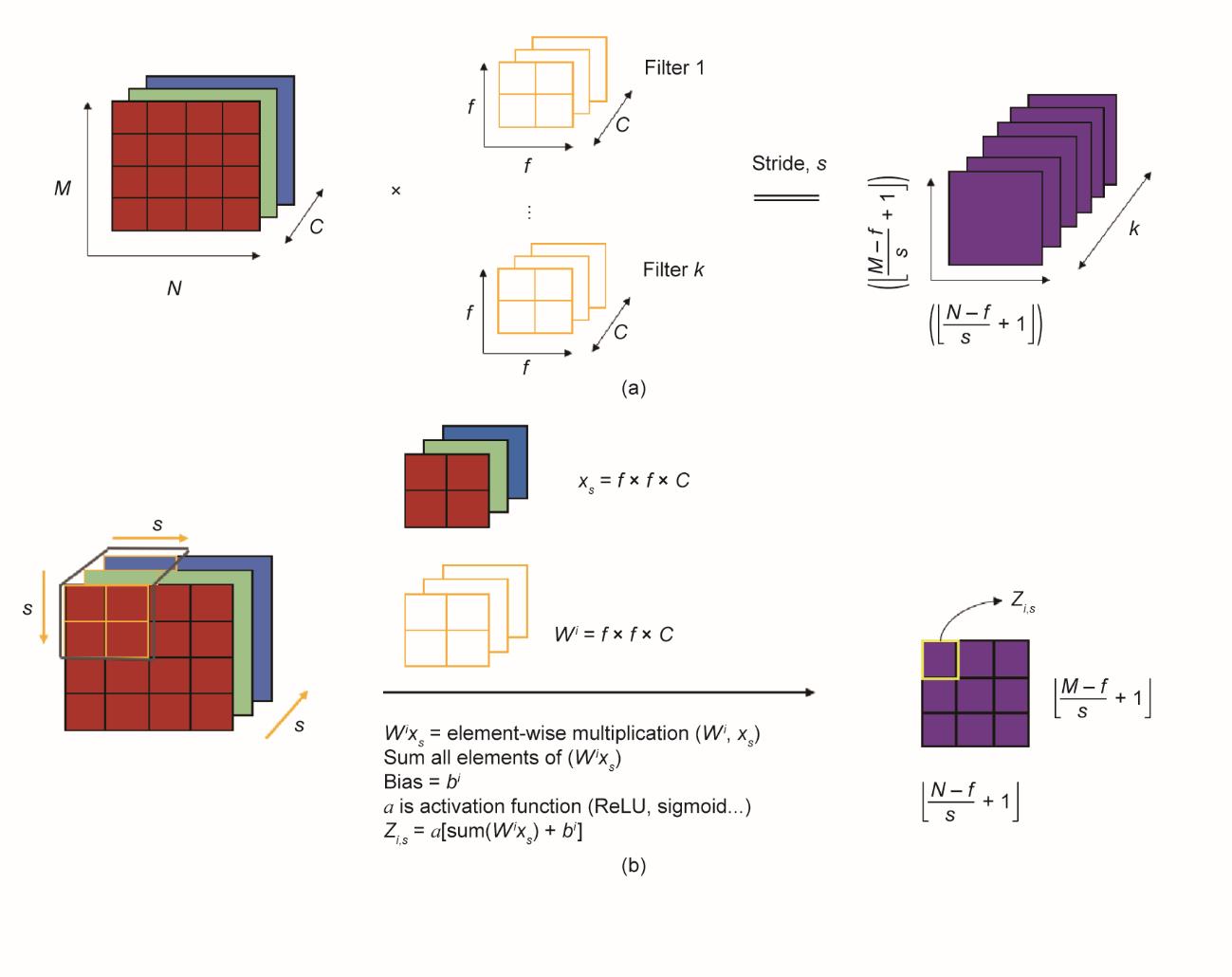
图1 卷积层的细节。(a)每个图像通过卷积层的整体卷积过程;(b)每个单独滤波器的详细卷积过程。
卷积层通常有一个池化层。通过池化层,一层神经元簇的输出可以被整合到下一层的单个神经元中以减少数据的维度[20]。池化过程可以根据输出的期望计算最大值或平均值。最大池化计算上一层每个局部神经元簇的最大值,并将其传递至下一层;平均池化将上一层的局部神经元簇的平均值传递至下一层。例如,
(2)
根据之前的研究[34],在图像数据集上,最大池化可以提供比平均池化更好的性能。CNN的最后一层是全连接层,它将计算每一类的分数,并将一个层中的每个神经元与另一个层中的每个神经元相连。展平矩阵通过一个全连接层来实现对图像的分类。广泛使用的CNN结构通常由若干输入层、卷积层、池化层、全连接层以及输出层组成[35-37]。图2为一个CNN结构的示例。
《图2》
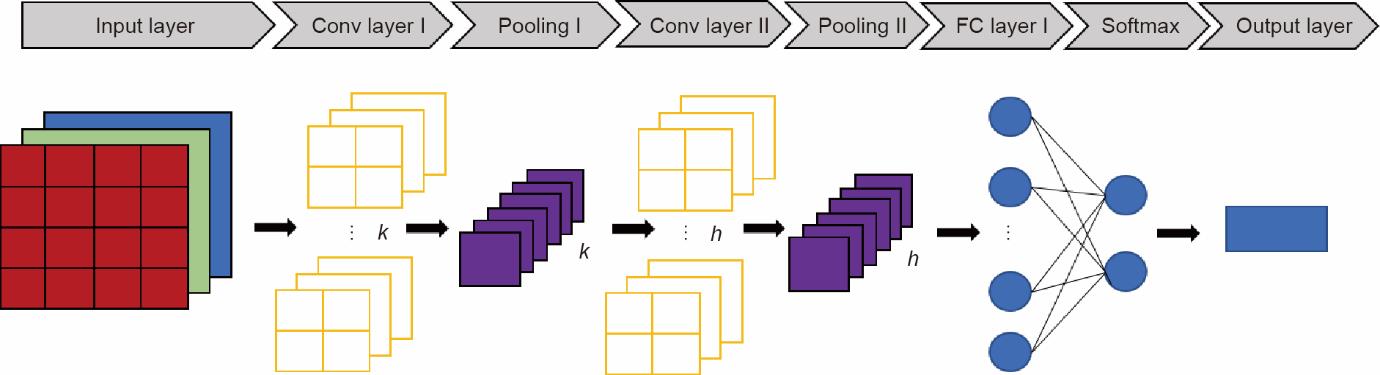
图2 一个CNN架构的示例。k和h是不同层的过滤器的数量;Conv:卷积的。
根据卷积维度与方向的不同,CNN有1D、二维(2D)和三维(3D)之分。1D-CNN在一个维度(沿一个轴)进行卷积计算,而2D-CNN和3D-CNN则分别在两个和三个方向计算卷积值。在本研究中,我们将使用1D-CNN来提取与学习展平图像频率信号的特征。图3展示了一个简单的1D卷积示例。
《图3》

图3 N个示例的1D卷积。
《2.2. 长短期记忆网络》
2.2. 长短期记忆网络
RNN是一类适用于顺序数据的深度学习。一般RNN有短期记忆的问题。如果一个序列非常长,RNN将很难将信息从前面的步骤传送到后面的步骤。换句话说,如果处理信号很长,RNN可能会从一开始就丢失一些重要信息。此外,RNN在反向传播过程中存在梯度消失问题。例如,如果梯度值变得极小,则学习过程不会有显著改善。在典型的RNN中,小梯度会使得各层的学习过程停止。为解决这些问题,本研究引入了长短期记忆(LSTM)网络方法[38]。LSTM是一个具有内部门的不变的RNN架构,可用于信息流调节。LSTM由三个阈值结构组成,用于过滤空输入和冗余信息,并融合相似的信息。图4显示了LSTM的工作机制。C-1和C表示序列中的单元状态,它们作为传送带来传递信息。另外设计三个门,向单元状态中添加或移除信息。门是由一个sigmoid神经网络层以及一个逐点乘法运算(pointwise multiplication)操作所组成的。Sigmoid层的输出介于0到1之间,用来描述每个信息组分应该通过的程度。第一个门被称为“遗忘门”(forget gate),它决定哪些信息需要被删除。例如,如果输出数字等于0,那么这个信息组分应该被完全删除[38]。式(3)显示了该计算过程。第二个门用于决定哪些信息需要被添加到单元状态中。这包括了sigmoid层的更新输出以及一个由tanh层产生的新的候选值。随后将上述信息添加到单元状态中以更新状态,如式(4)~(6)所示。最后一步是决定需要输出什么信息。如式(7)和式(8)所示,单元状态通过一个sigmoid层和一个tanh层来产生最终输出。
(3)
(4)
(5)
(6)
(7)
(8)
式中,f和i是sigmoid层的输出;
《图4》

图4 LSTM的机制。
《3. 混凝土裂缝实时检测方法的提出》
3. 混凝土裂缝实时检测方法的提出
如上一节所述,CNN在特征提取方面功能强大。然而,特征融合在整体模型性能中发挥着更加重要的作用。全连接层广泛用于将提取的特征与调整后的权重简单地相结合。然而,尽管全连接层在特征融合方面具有不错的性能,但它们往往不足以提取高层次的信息。为了解决这个问题,本研究将1D-CNN与LSTM结合作为特征融合层。在序列数据的长期依赖方面,已有研究证明LSTM可以有效融合特征[42-48]。在桥梁检测中,输入的混凝土桥面图像是在某一时刻拍摄的单一图像,而非一个序列。因此,在本研究中,LSTM被应用于特征层而不是输入层。在1D-CNN特征提取阶段,卷积核被用来扫描整个图像频率矢量,以提取图像中所有对象的特征。将卷积核移动步长设置为小于核本身的大小,可以确保每个扫描区域都有重叠部分。因此,卷积核提取的特征块之间有很强的依赖性,可以作为LSTM层进行特征融合的等效数据输入。然后应用全连接层来进一步融合从前几层获得的足够的特征。图5展示了本文所提出的桥梁混凝土裂缝实时检测方法的框架。如图所示,第一步是收集一个数据库,其中包含数千张开裂与非开裂混凝土桥面的图像。然后,数据库被分为训练、验证和测试子集。训练和验证数据集被传递到预处理阶段,此阶段的图像被转换到频域。可以说,表面裂缝的边缘形状往往对应高频。因此,可以利用高通滤波器(HPF)来滤除与背景相对应的低频。滤波后,图像频率矩阵被展平为矢量频率信号。这些矢量被用来训练上述1D-CNN-LSTM算法。通过在整个图像中引入滑动窗口,我们可以将该方法应用于测试图像。带有裂缝的局部窗口将保留在输出图像中。
《图5》
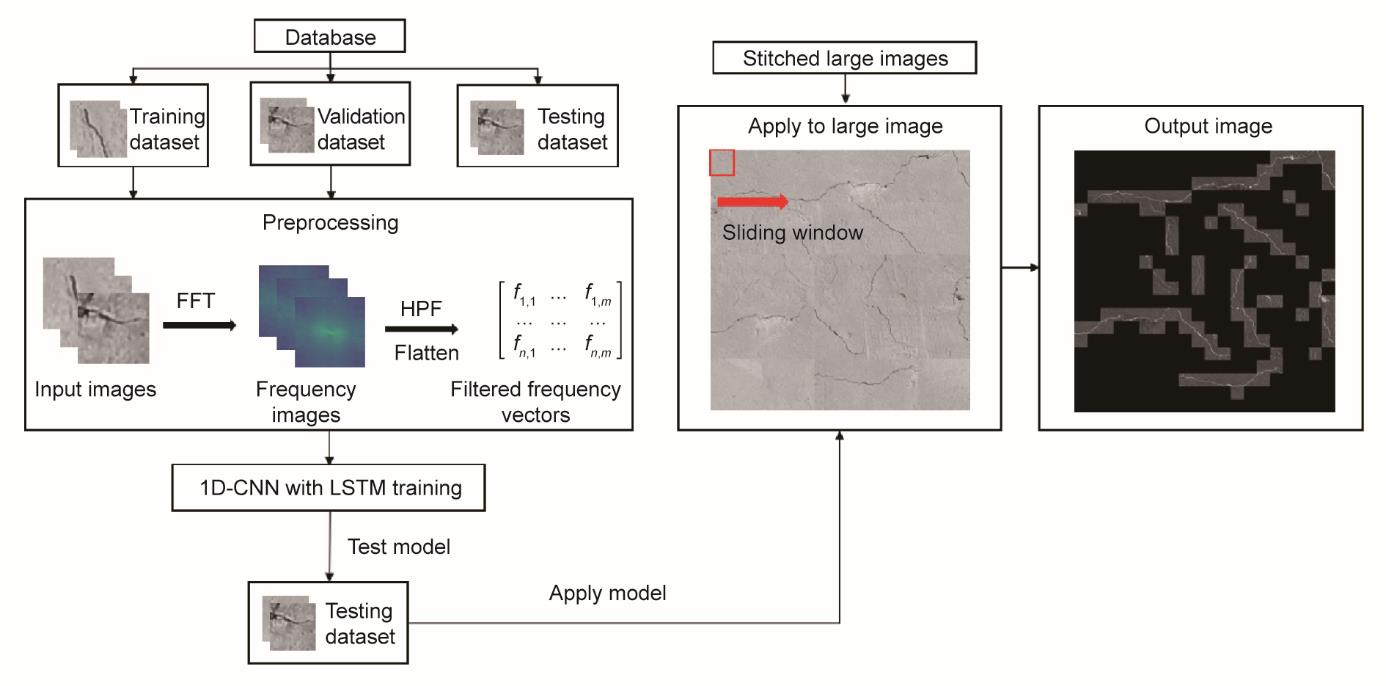
图5 本文所提出的检测方法框架。FFT:快速傅里叶变换。
《3.1. 数据库》
3.1. 数据库
1D-CNN-LSTM模型是利用一个数据库开发的,该数据库包含4800张人工标记的有裂缝和无裂缝的混凝土桥面图像[54]。该数据库包括窄至0.06 mm和宽至25 mm的裂缝。图像大小为256 × 256像素。为了提高检测精度,图像会被分解为64 × 64像素的子图像。在4800张可用图像中,有4300张图像被裁剪成17 200张小图像。在剔除模糊或包含角裂缝的图像后,最终有16 789张图像作为本研究的数据集。剩余的500张桥面图像则被随机拼接成20幅大小为1280 ×1280像素的图像,以测试所开发的分类器的泛化能力。
《3.2. 频域数据预处理》
3.2. 频域数据预处理
在许多研究中,图像是在空间域中处理的。也就是说图像均被按照原样处理,没有进一步进行预处理。在空间域中,像素值会随场景的变化而变化,而图像的处理是基于像素值的。因此,处理图像的一个更有效的方法是将其转换到频域[49]。通过进行离散傅里叶变换(DFT),图像可以从空间域转换到频域。在频域中,值和位置由正弦关系表示,正弦关系取决于图像中出现像素的频率。在这个域中,像素位置由其x和y频率表示,其值由振幅表示。我们可以将图像转换到频域,以确定哪些像素包含更重要的信息,以及是否出现重复模式。换句话说,在频域中,我们处理的是像素值在空间域中的变化率。由于图像的频率与像素值变化率有关,因此图像的频率分量可分为两部分:对应于图像中的边缘区域的高频分量,以及对应于图像中的平滑区域的低频分量。已有许多研究人员将此特性应用于图像的滤波、压缩与重建[50-52]。DFT是一种采样的傅里叶变换;因此,它不包含构成一幅图像的全部频率,而仅包含一组足够大的样本,以充分描述空间域图像。频率数与空间域图像的像素数相对应,所以空间域和傅里叶域的图像大小是一致的。对于一个大小为M × N像素的图像,其2D DFT可以呈现如下:
(9)
式中,
另一方面,频域中的图像可以被转换回空间域。对应的傅里叶逆变换为:
(10)
对大图像而言,快速傅里叶变换(FFT)通常可以降低维度复杂度并减少计算时间。FFT产生复合值,包括实部和虚部或幅度和相位。在图像处理中,通常只显示幅度,因为它包含了空间域的大部分几何结构信息。幅度与相位可以表示如下:
(11)
(12)
式中,
《图6》
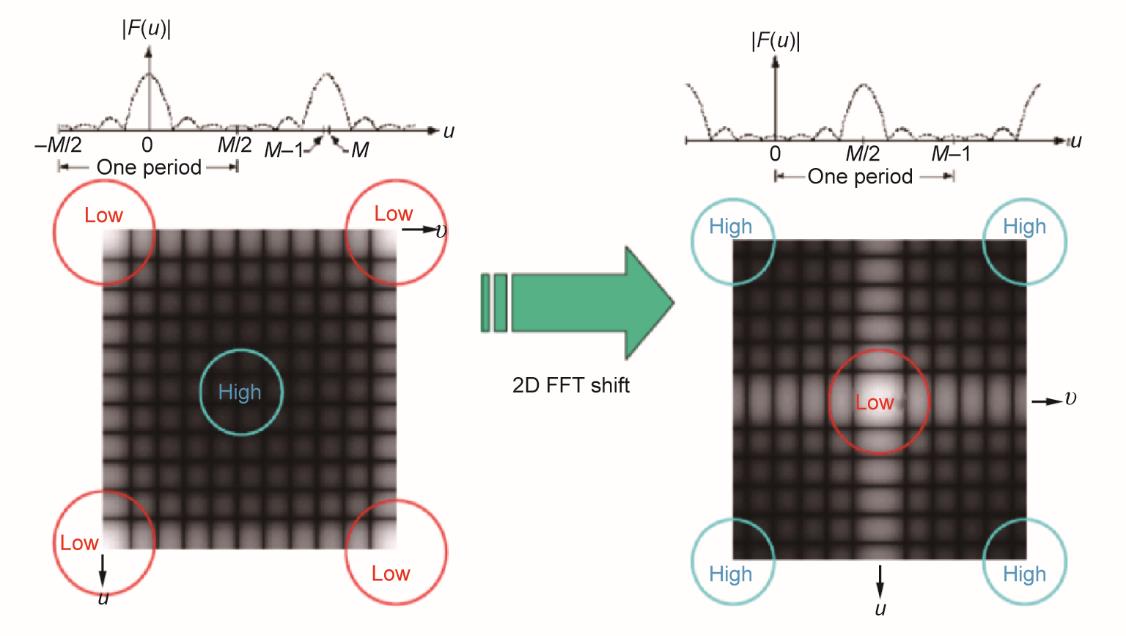
图6 一个2D图像的频率中心转移,其中u和v表示空间频率。
将图像转换到频域可以显著提高CNN训练速度。用原始图像训练网络,比如在空间域中使用2D卷积所进行的那样,对于桥面数据而言并非是一个有效的解决方案。相反,训练是在频域中进行的,这更像是1D信号模式识别。因此,在预处理阶段,首先将RGB通道中的图像读取到灰度图像矩阵中。然后,FFT被应用于图像矩阵中的每个图像。频率图像的中心发生转移,可算得每个图像的幅度。图7展示了有裂缝和无裂缝图像的频率分布之间的显著差异。如图7所示,有裂缝的图像频谱有线状火花,而没有裂缝的图像频谱中则没有这种火花。与平滑背景区域相对应的低频被HPF所滤除。显然,有裂缝与无裂缝图像之间的主要区别体现在高频域。频率滤波比等于0.5,意味着只保留前50%的高频。我们会对0.2~0.7的频率滤波比进行测试以获得最佳性能,并最终从中选择0.5作为阈值。任何高于阈值的频率都将被保留,而所有的低频都将被替换为0。滤波之后,计算每个图像的频率幅度矩阵,并将其展平为一个频率幅度向量。图8显示了有裂缝和无裂缝图像的原始幅度和经过滤波后的幅度。将预处理后的图像数据重构成形状为图像数量×展平频率向量长度×1的矩阵。重构后的数据将被用于开发以LSTM为输入层的1D-CNN。
《图7》

图7 (a)有裂缝图像;(b)有裂缝图像的频谱;(c)无裂缝图像;(d)无裂缝图像的频谱。
《图8》

图8 (a)有裂缝图像的幅度;(b)有裂缝图像的滤波幅度;(c)无裂缝图像的幅度;(d)无裂缝图像的滤波幅度。
《3.3. 1D-CNN-LSTM 模型结构》
3.3. 1D-CNN-LSTM 模型结构
最优的1D-CNN-LSTM结构是通过广泛的试错方法进行选择的,并使用TensorFlow模块进行开发[55]。最优网络由一个输入层、四组卷积层、一个最大池化层、一个LSTM层、两个全连接层和一个输出层组成。对于每个卷积层,都要进行批量归一化处理。ReLU函数被用作卷积层的激活函数。Sigmoid和softmax函数分别是第一和第二全连接层的激活函数。总网络参数为230 082,可训练参数为229 378。在训练过程中,本研究选择随机梯度下降作为优化器,在16 789张图像中选择32张作为最小批量。为了加快收敛速度,该模型采用了自适应对数递减的学习率。初始学习率和权重衰减分别为0.1和0.0001。为避免过度拟合,采用了0.9的动量值。此外,在LSTM层和第一个完全连接层之后添加dropout约束。Dropout率设置为0.5。网络中还增加了提前停止功能,当模型性能没有显著改善时,该模型会自动停止训练。表1显示了该1D-CNN-LSTM模型的结构。
《表1》
表1 1D-CNN-LSTM模型的结构
| Layer (type) | Output shape | Number of pa-rameters | Filter size | Number of fil-ters | Stride | Activation func-tion | |
|---|---|---|---|---|---|---|---|
| Layer 1 | conv1d_1 (Conv1D) | (Input#, 4096, 32) | 128 | 3 | 32 | 1 | — |
| BN_1 (Batch Normalization) | (Input#, 4096, 32) | 128 | — | — | — | — | |
| activation_1 (Activation) | (Input#, 4096, 32) | 0 | — | — | — | ReLU | |
| Maxpooling_1 (MaxPooling) | (Input#, 2047, 32) | 0 | 4 | — | 2 | — | |
| Layer 2 | conv1d_2 (Conv1D) | (Input#, 2047, 64) | 6 208 | 3 | 64 | 1 | — |
| BN_2 (Batch Normalization) | (Input#, 2047, 64) | 265 | — | — | — | — | |
| activation_2 (Activation) | (Input#, 2047, 64) | 0 | — | — | — | ReLU | |
| Maxpooling_2 (MaxPooling) | (Input#, 511, 64) | 0 | 4 | — | 4 | — | |
| Layer 3 | conv1d_3 (Conv1D) | (Input#, 511, 128) | 24 704 | 3 | 128 | 1 | — |
| BN_3 (Batch Normalization) | (Input#, 511, 128) | 512 | — | — | — | — | |
| activation_3 (Activation) | (Input#, 511, 128) | 0 | — | — | — | ReLU | |
| Maxpooling_3 (MaxPooling) | (Input#, 127, 128) | 0 | 4 | — | 4 | — | |
| Layer 4 | conv1d_4 (Conv1D) | (Input#, 127, 128) | 49 280 | 3 | 128 | 1 | — |
| BN_4(Batch Normalization) | (Input#, 127, 128) | 512 | — | — | — | — | |
| activation_4 (Activation) | (Input#, 127, 128) | 0 | — | — | — | ReLU | |
| Maxpooling_4 (MaxPooling) | (Input#, 31, 128) | 0 | 4 | — | 4 | — | |
| Layer 5 | lstm_1 (LSTM) | (Input#, 128) | 131 584 | — | — | — | — |
| Layer 6 | dense_1 (Dense) | (Input#, 128) | 16 512 | — | — | — | Sigmoid |
| Layer 7 | dense_2 (Dense) | (Input#, 2) | 258 | — | — | — | Softmax |
《4. 裂缝检测结果》
4. 裂缝检测结果
《4.1. 性能分析》
4.1. 性能分析
数据库中有裂缝与无裂缝图像的比例为1∶2。预处理后的16 789张人工标记的图像数据库被随机分为训练、验证和测试集,比例分别为70%、15%和15%。图9显示了训练和验证过程中的损失与准确性。在训练和验证数据方面,该方法具有很高的准确性。在第49和40代中,训练与验证的准确率分别实现了各自的最大值,即99.05%和98.9%。最终测试精度为99.25%。我们保存了最优的模型,以期将其应用于未见过的测试数据集。仿真是在一台台式电脑上进行的。CPU型号:Intel® Xeon® CPU E5-1650 v4 @ 3.60 GHz;GPU:NVIDIA Quadro K420;内存:31.9 GB。总训练时间为1 h 12 min 4 s。
《图9》
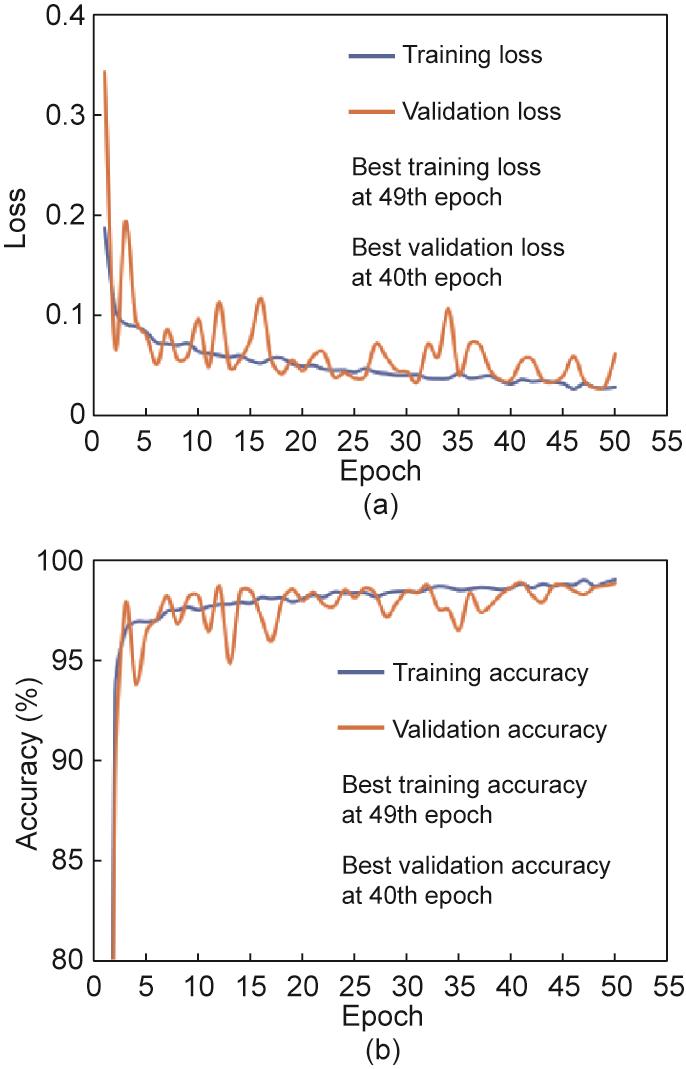
图9 该1D-CNN-LSTM模型的损失(a)和准确性(b)。
《4.2. 1D-CNN-LSTM模型的运行》
4.2. 1D-CNN-LSTM模型的运行
我们在Python 3.7中开发了用于混凝土桥梁裂缝检测的运行代码。按照第3节所述的程序,大尺寸图像被分解成大小为64 × 64像素的小图像组。每个图像组都被转换到频域,并用相同规格的HPF进行滤波。然后将上述模型作为一个局部窗口滑过每个图像组,将该组中的小图像分类为有裂缝或无裂缝图像。为了获得更多的连续裂缝,本研究采用了重叠的局部滑动窗口。图10提供了滑动过程的简要描述。如图11所示,使用重叠的滑动窗口后,检测到的裂缝更加连续。带有裂缝的小图像将被保留并随后输出,最终使其恢复到其在大尺寸图像中的原始位置。所有其他没有裂缝的小图像都被消除。图12显示了裂缝检测的实施框架。如前所述,500张尺寸为256 × 256像素的图像被拼接成20张尺寸为1280 × 1280像素的大图像,以测试训练后模型的泛化能力。每幅图像的输出时间仅为5~7 s。图13展示了两张测试图像的裂缝检测结果。其运行精度计算如下:
(13)
(14)
式中,ACC和ER分别代表准确率和错误率。TP、TN、FP和FN分别是真阳性、真阴性、假阳性和假阴性的数量。参见图13,运行精度分别为98.5%和97.75%;因此,错误率分别为1.5%和2.25%。
《图10》

图10 重叠的滑动窗口的示意图。
《图11》

图11 使用重叠和非重叠窗口检测到的裂缝。
《图12》
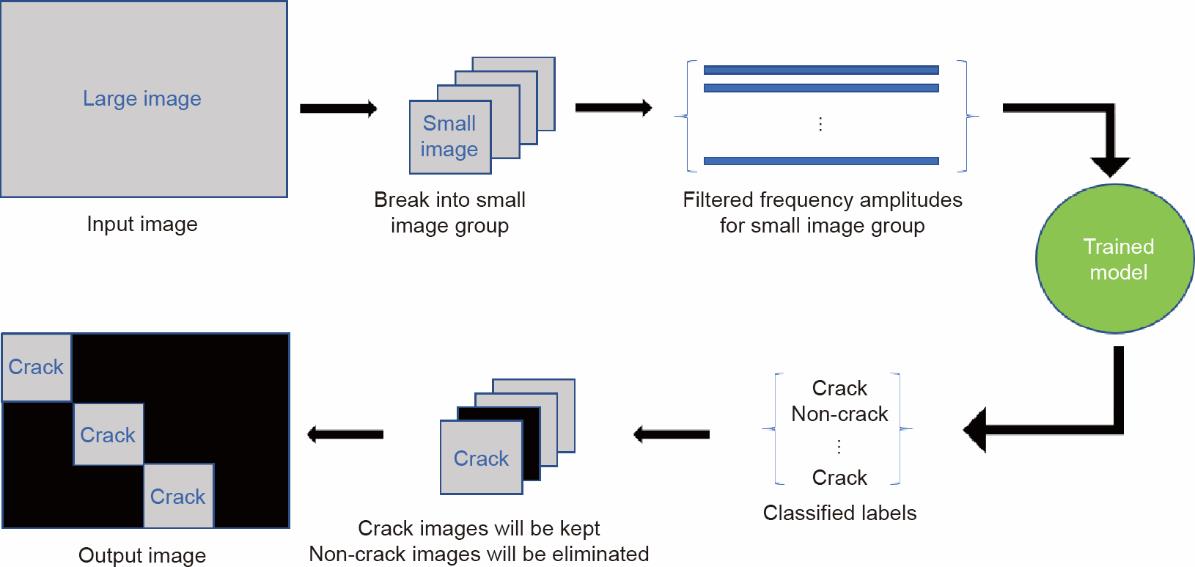
图12 1D-CNN-LSTM混凝土裂缝检测的运行过程。
《图13》

图13 两张测试图像的裂缝检测结果。
《5. 比较研究》
5. 比较研究
为了更深入地了解该1D-CNN-LSTM方法的运行速度与准确性,本研究将其与现有的深度学习方法以及两种常用的边缘检测器(即和检测器)进行了比较。在应用于裂缝检测的深度学习领域,几乎所有的现有研究都是基于经典的CNN结构和空间域中的图像训练开展的[29-30]。因此,本研究还开发了一个与Cha等[29]最近的研究成果相类似的2D-CNN网络。我们使用同样的数据对2D-CNN方法进行训练、验证与测试。2D-CNN结构的详细信息如表2所示。总参数和可训练参数分别为896 770和896 322。表3总结了比较研究结果,如表中所示,本研究所提出的方法不仅提供了更优良的检测性能,并且所需的总参数与可训练参数显著减少。最值得注意的是,在校准阶段和运行阶段,2D-CNN方法的计算成本分别比本研究提出的1D-CNN-LSTM方法高出约129%和710%。2D-CNN和其他现有的基于深度学习的方法的处理速度慢的原因在于它们处理的是空间域中的图像。此外,在预处理阶段应用HPF可以减少冗余的数据信息,从而加快处理速度。1D-CNN-LSTM的快速运行使其成为实时检测桥面裂缝的理想选择。此外,图14显示了1D-CNN-LSTM、Canny和Sobel边缘检测器在一个测试样本上的简单比较结果。如图所示,1D-CNN-LSTM方法明显优于边缘检测法。事实上,由于混凝土表面不平整,Canny法几乎无法检测到任何裂缝,而Sobel法只检测到了部分裂缝,并且结果受到噪声背景的严重干扰。
《表2》
表2 用于裂缝检测的经典2D-CNN网络的结构
| Layer (Type) | Output shape | Number of pa-rameters | Filter size | Number of fil-ters | Stride | Activation func-tion | |
|---|---|---|---|---|---|---|---|
| Layer 1 | conv2d_1 (Conv2D) | (Input#, 64, 64, 32) | 320 | 3 | 32 | 1 | — |
| BN_1 (Batch Normalization) | (Input#, 64, 64, 32) | 128 | — | — | — | — | |
| activation_1 (Activation) | (Input#, 64, 64, 32) | 0 | — | — | — | ReLU | |
| Maxpooling_1 (MaxPooling) | (Input#, 63, 63, 32) | 0 | 2 | — | 1 | — | |
| Layer 2 | conv2d_2 (Conv2D) | (Input#, 63, 63, 64) | 18 496 | 3 | 64 | 1 | — |
| BN_2 (Batch Normalization) | (Input#, 63, 63, 64) | 265 | — | — | — | — | |
| activation_2 (Activation) | (Input#, 63, 63, 64) | 0 | — | — | — | ReLU | |
| Maxpooling_2 (MaxPooling) | (Input#, 31, 31, 64) | 0 | 2 | — | 2 | — | |
| Layer 3 | conv2d_3 (Conv2D) | (Input#, 31, 31, 128) | 73 856 | 3 | 128 | 1 | — |
| BN_3 (Batch Normalization) | (Input#, 31, 31, 128) | 512 | — | — | — | — | |
| activation_3 (Activation) | (Input#, 31, 31, 128) | 0 | — | — | — | ReLU | |
| Maxpooling_3 (MaxPooling) | (Input#, 7, 7, 128) | 0 | 4 | — | 4 | — | |
| Flatten () | (Input#, 6272) | 0 | — | — | — | — | |
| Layer 4 | dense_1 (Dense) | (Input#, 128) | 802 944 | — | — | — | Sigmoid |
| Layer 5 | dense_2 (Dense) | (Input#, 2) | 258 | — | — | — | Softmax |
《表3》
表3 2D-CNN和1D-CNN-LSTM方法的比较
| Method | Total parame-ters | Trainable pa-rameters | Training accu-racy | Validation ac-curacy | Testing accu-racy | Training time | Implementation output time |
|---|---|---|---|---|---|---|---|
| Standard 2D-CNN | 896 770 | 896 322 | 98.52% | 98.12% | 97.80% | 2 h 45 min 16 s | 38–59 s per image |
| 1D-CNN-LSTM | 230 082 | 229 378 | 99.05% | 98.90% | 99.25% | 1 h 12 min 4 s | 5–7 s per image |
《图14》

图14 (a)原始图像;(b)1D-CNN-LSTM方法的输出;(c)Canny边缘检测器的输出;(d)Sobel边缘检测器的输出。
《6. 结论》
6. 结论
本研究提出了一种新的混凝土裂缝检测方法,该方法集成了1D-CNN、LSTM和图像频域中的学习过程。数千张的有裂缝和无裂缝混凝土桥面的图像被用来训练、验证和测试本研究所提出的1D-CNN-LSTM算法。经观察,1D-CNN-LSTM模型在训练、验证和测试数据集上的准确率分别为99.05%、98.90%和99.25%。该运行框架能够成功地部署训练有素的模型,对未标记的大尺寸图像进行高精度的裂缝检测。尽管在运行过程中,假阳性和假阴性的比率已经令人满意,但随着更多训练数据的引入,模型的性能仍然有提升空间。通过将本研究提出的方法与现有的基于深度学习的方法以及两种边缘检测器法进行比较,我们发现1D-CNN-LSTM的性能要优于其余方法。与其他研究过的CNN算法相比,1D-CNN-LSTM方法的一个显著优势是其训练与运行所需的时间明显更短。这一点对于实时混凝土裂缝检测而言至关重要,特别是在无人机检测等自动化桥梁检测的应用场景中。这一成果有效地验证了频域数据预处理的效率。未来的研究可以专注于使用更大和更多样化的数据集来开发模型。在频域中将其他高效的深度学习方法(如Yolo)与LSTM相结合也可能成为未来研究的合适主题。











 京公网安备 11010502051620号
京公网安备 11010502051620号




