

《1、 引言》
1、 引言
激光粉末床熔融(PBF)是最重要的增材制造(AM)方法之一,涉及以熔池为基本单元的一维(1D)到二维(2D)和三维(3D)逐步打印过程[1]。熔池特征对L-PBF成型件的微观结构和性能有直接影响,因此对打印质量至关重要[2‒5]。值得注意的是,熔池特征与激光功率和扫描速度等关键工艺参数密切相关[6‒7]。例如,熔池尺寸不足可能会导致缺乏熔合缺陷[8‒10]。相反,过深的熔池则可能导致液态金属的气体/金属界面出现深层匙孔,它是大的球形孔的潜在来源,这些球形孔会在快速凝固过程中被捕获[2]。因此,对熔池特征与工艺参数之间的关联性进行定量预测,将是对PBF打印工艺智能化管理的有力支持,并将进一步实现打印质量的精确控制[11‒12]。
激光粉末床熔融(L-PBF)输入变量与结果之间的正向和逆向预测是一个重要的主题[13],其中工艺条件和打印结果是理解和控制打印过程的关键因素[1]。正向预测是使用工艺参数作为输入来预测目标熔池尺寸。相反,逆向预测中所需的工艺参数必须使用特定的熔池尺寸作为输入来预测。这些双向预测可以成为智能控制打印因素的强大工具,以获得PBF成型件的理想微观结构和机械性能[14]。尽管使用MLP的正向预测已被报道于金属电弧焊[15‒16]、激光PBF [17]和定向能沉积(DED)[18‒19]中,但仍缺乏对所需AM工艺条件的反向预测[20‒21]。
作为一种数据驱动的方法,深度学习可以用于AM数据的预测,而不需要明确了解AM复杂的机理[22‒24]。多层感知器(MLP)可以成为预测AM的几何特征和打印参数的有效工具[25‒26]。例如,人工神经网络被用来评估激光DED期间AA2024合金沉积的工艺参数[18]。MLP被用来预测激光PBF工艺不同激光功率和扫描速度下的几何特征,在一个新的数据集上总体准确率高达90% [17]。深度学习模型也可以利用过程监测数据获得熔池特征[27‒30]。例如,Schmid等[31]提出了一种自动测量打印件横截面上的熔池尺寸的方法。无监督的深度学习区分了由高速摄像机获得的熔池图像[32]。遗传算法(GA)被成功用于逆向预测,以获得与目标焊接几何形状对应的电弧电流、电压和扫描速度组合[33]。然而,使用GA很耗时[33‒34],而且GA高度依赖于选择和变异标准[35]。相比之下,MLP可以提供快速的预测,并具备在大量数据中映射非线性关系的强大能力[35]。简而言之,深度学习模型可用于AM数据的复杂相关性的准确预测和有效处理,并有利于打印过程优化和原位智能控制[36]。应该注意的是,MLP的数据驱动特性要求模型训练的数据集有足够的数量和较好的质量[13,20]。因此,高质量的深度学习模型训练需要准备足够的实验和建模数据[37]。
在熔池中会发生多种物理过程,如原材料的快速加热和冷却过程;熔池中液态金属在表面张力、马兰戈尼应力、反冲压力和重力作用下的急剧流动;以及熔池金属的快速凝固[2,38‒39]。在不同的打印条件下,这些物理过程将产生具有不同几何形状和尺寸的熔池[40],物理过程与熔池表现出高度的非线性关系。熔池尺寸的确定通常是通过实验和表征进行的。然而,试错实验往往耗费时间和成本,而且产生的数据量有限。在只用实验数据这种情况下,由于用于模型训练的数据不足,使用深度学习模型对L-PBF的输入变量和结果进行预测的准确性就会降低。
高置信度机理模型可以在对典型实验结果进行适当的验证后用来帮助增加数据集[40‒41]。用于训练深度学习模型的大量高质量源数据可以通过融合实验和仿真的方法来获得。此外,通过实验观察熔池的时空变化、热传导和液态金属流动是具有挑战性的,会导致对复杂打印过程的机理理解不足。相反,多物理过程数值模型可以帮助揭示关键打印因素的时空变化,如熔池的演变和演变产生的结果[2,6,24,42]。通过这种方式,可以更好地理解实验现象的内部机理,有助于分析某些数据集的可学习性和深度学习模型的预测性能。此外,虚拟打印可以节约成本,为典型案例提供更多的设计灵活性。
然而,机理模型也存在从熔池数据到工艺参数数据的逆向预测的挑战[2]。为此,深度学习模型(如MLP)可以作为一个实现PBF打印双向预测的潜在的强大方法。经过逆向预测,预想的熔池尺寸可以通过预测的工艺参数得到,这对控制打印缺陷很有帮助。简而言之,上面讨论的三个主要模块——深度学习模型、L-PBF实验和机理模型——应结合起来,形成一个预测和理解关键工艺条件与熔池特征的平台,以克服它们各自的局限性[2,6,43]。
据我们所知,本工作中提出的这种将深度学习模型、L-PBF实验和机理模型结合起来的系统方法,在文献中还很缺乏。在所提出的新框架下,L-PBF实验提供了基本数据,可用于验证机理模型和训练深度学习模型。机理模型有助于增强训练深度学习模型的数据集。基于物理信息的深度学习模型被用于工艺参数与熔池尺寸之间的正向、逆向预测。这项研究为确定所需熔池特征的工艺条件提供了直接的支持,从而为促进智能化AM的发展提供了一个新颖而有用的思路。
《2、 研究方法》
2、 研究方法
《2.1 激光粉末床熔融实验》
2.1 激光粉末床熔融实验
本研究中采用的材料为AA2024铝合金,通过真空气体雾化(VIGA)制备得到,粒径范围约为20~95 µm。打印前,先将粉末置于60 ℃的烘箱中烘干4 h,以去除潜在的残余水分并确保粉末的流动性。实验中,每组的单层铺粉厚度均设定为50 μm。本次实验使用的打印机型号为Concept Laser M2,该设备采用了半径为40 μm的掺钇光纤激光,其名义激光功率为400 W,波长范围为1064~1100 nm。打印过程中,成形环境通过填充氩气进行保护,以使氧含量保持在0.1%以下。更多实验细节介绍详见本团队之前的论文[7,44]。
如表1所示,实验过程通过变换L-PBF打印的激光功率和扫描速度获得多份单道样品。研究人员通过一系列单变量实验考察了熔池特性与激光功率或扫描速度之间的依赖关系。此外,本研究采用线性能量密度(即激光功率除以扫描速度)评估MLP模型预测精度的敏感性。每组实验通过打印正方形轮廓获得相同工艺参数的四个单道样品,并通过测量方形轮廓样品的单道尺寸,取其平均值作为验证机理模型的实验结果。
《表1》
表1 激光粉末床熔融实验的工艺参数
| Sample No. | Laser power (W) | Scanning speed (mm·s-1) |
|---|---|---|
| 1 | 220 | 300 |
| 2 | 270 | 300 |
| 3 | 300 | 300 |
| 4 | 220 | 600 |
| 5 | 270 | 600 |
| 6 | 300 | 600 |
| 7 | 350 | 600 |
| 8 | 220 | 900 |
| 9 | 270 | 900 |
| 10 | 300 | 900 |
| 11 | 350 | 900 |
| 12 | 220 | 1100 |
| 13 | 270 | 1100 |
| 14 | 300 | 1100 |
| 15 | 350 | 1100 |
| 16 | 220 | 1500 |
《2.2 激光粉末床熔融的机理模型》
2.2 激光粉末床熔融的机理模型
为了计算激光粉末床熔融过程中发生的复杂冶金传输现象,本研究采用了基于OpenFOAM开发的现象学模型,以同时求解质量、动量和能量守恒方程以及VOF (volume of fluid)方程[8]。该模型的详细信息请详见本团队之前的文章[8,38‒39]。本研究还计算并展示了熔池和沉积道的几何特征的时空变化。由于熔池在恒定工艺参数的线性扫描过程中经历了显著的瞬态过程,所以熔池的尺寸需要等其进入准稳态后才能确定[38]。此外,机理模型计算域的长、宽、高分别为1000 μm、400 μm、500 μm,铺粉厚度为50 μm。打印材料的热物理性质如表2 [7]所示。
《表2》
表2 用于计算的AA2024合金热物理属性[]
| Property | Value |
|---|---|
| Solidus temperature (K) | 811 |
| Liquidus temperature (K) | 905 |
| Evaporation temperature (K) | 2743 |
| Density of metal (kg·m‒3) | 2780 |
| Thermal conductivity of liquid metal (W·m-1·K-1) | 85.5 |
| Thermal conductivity of solid metal (W·m-1·K-1) | 188 |
| Specific heat of liquid metal (J·kg-1·K‒1) | 1140 |
| Specific heat of solid metal (J·kg- 1·K‒1) | 768.8 + 0.3 |
| Viscosity of liquid metal (Pa·s) | 0.0015 |
| Temperature coefficient of surface tension (N·m-1·K-1) | -0.155 × 10‒3 |
| Gas constant (J·K-1·mol-1) | 8.314 |
| Stefan‒Boltzmann constant (W·m-2·K-4) | 5.67 × 10‒8 |
| Latent heat of fusion (J·kg-1) | 2.97 × 105 |
| Latent heat of evaporation (J·kg-1) | 1.12 × 105 |
实验采用的激光功率的区间为100~350 W,以25 W为间隔划分;扫描速度的区间为300~1500 mm∙s-1,以150 mm∙s-1为间隔划分。两组工艺参数通过组合得到99组数据,对应参数列于表3。需要注意的是,所选的工艺参数均在实验工艺参数的范围内,以防止出现无法预测的情况。此外,为避免深度学习模型的训练受到不平衡的干扰,表3中与实验参数接近的12个计算情况被删除,因此剩下87组参数。本研究还检验了深度学习模型预测准确性的数据量敏感性,初步测试表明,以上数据量足以支持工艺参数和熔池尺寸的双向预测。
《表3》
表3 激光粉末床熔融机理模型采用的工艺参数
| Scanning speed (mm·s-1) | Laser power (W) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 125 | 150 | 175 | 200 | 225 | 250 | 275 | 300 | 325 | 350 | |
| 300 | S1 | S2 | S3 | S4 | S5 | S7 | S8 | S10 | S11 | ||
| 450 | S12 | S13 | S14 | S15 | S16 | S17 | S18 | S19 | S20 | S21 | S22 |
| 600 | S23 | S24 | S25 | S26 | S27 | S29 | S30 | S32 | |||
| 750 | S34 | S35 | S36 | S37 | S38 | S39 | S40 | S41 | S42 | S43 | S44 |
| 900 | S45 | S46 | S47 | S48 | S49 | S51 | S52 | S54 | |||
| 1050 | S56 | S57 | S58 | S59 | S60 | S61 | S62 | S65 | |||
| 1200 | S67 | S68 | S69 | S70 | S71 | S72 | S73 | S74 | S75 | S76 | S77 |
| 1350 | S78 | S79 | S80 | S81 | S82 | S83 | S84 | S85 | S86 | S87 | S88 |
| 1500 | S89 | S90 | S91 | S92 | S93 | S95 | S96 | S97 | S98 | S99 | |
本研究通过将机理模型计算结果与相应的实验数据进行比较来验证其准确性。图1(a)对比了不同工艺参数下的熔池宽度,并且显示平均误差在4%以内。又由图1(b)可知,实验和计算结果显示,熔池宽度与工艺参数之间存在具体相关性。图1(c)反映了熔池的深度值,其中实验结果与机理模型结果之间的平均误差为8.98%。熔池单道深度模型中出现的较大误差可能源于打印过程中匙孔和熔池深度的剧烈波动,这将在随后的章节中进行探讨。此外,图1(d)还显示了不同工艺参数下熔池的横截面。这些实验和机理模型的结果为支撑后续深度学习模型的训练提供了充足的数据集。在本研究中,机理模型除了扩充数据集以外,还能通过揭示熔池和沉积道的时空变化,进一步解释影响MLP模型预测精度的潜在原因[8]。
《图1》
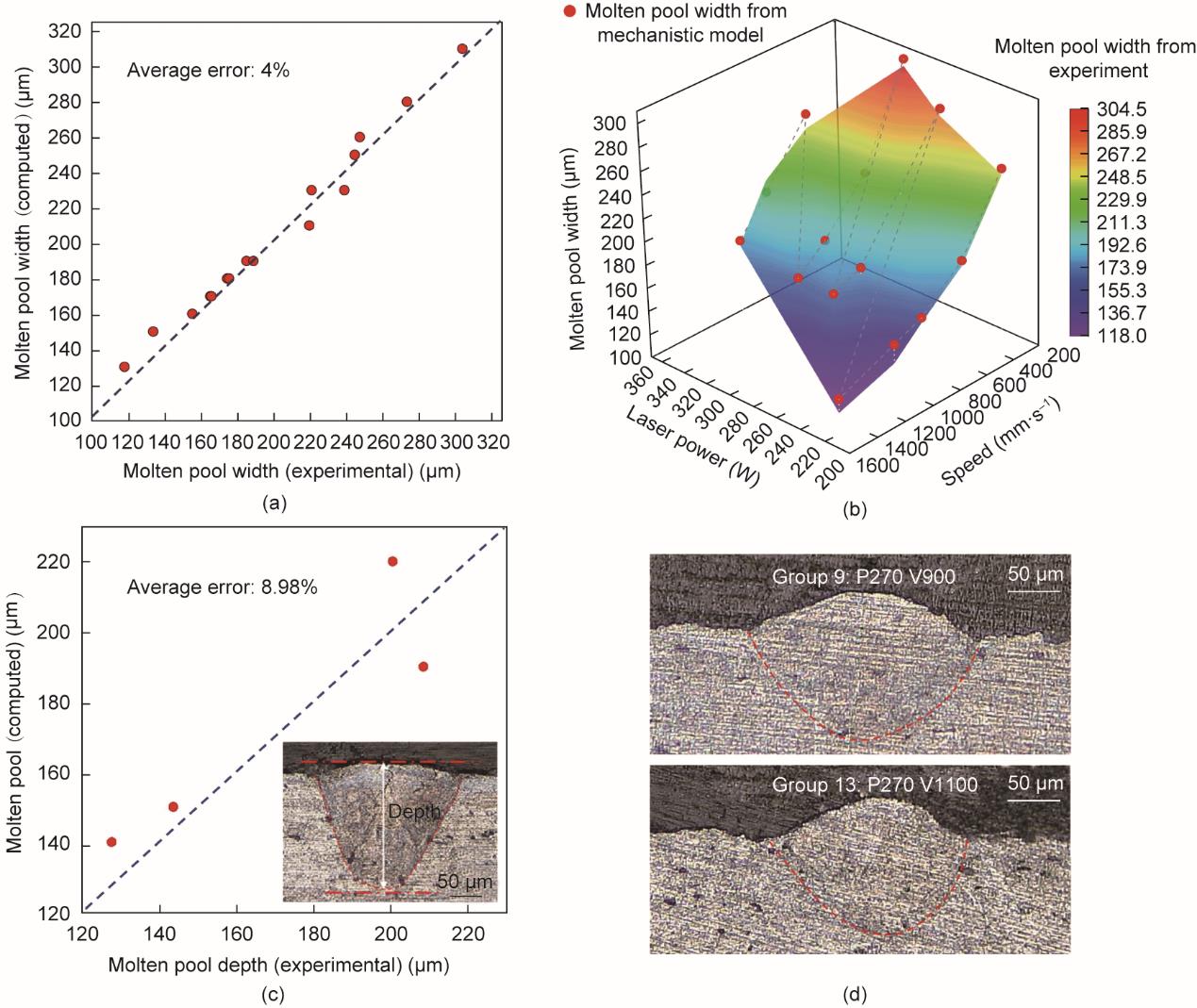
图1 机理模型的验证结果。(a)采用不同工艺参数得到的实验与机理模型熔池宽度对比;(b)不同工艺参数下的熔池宽度(彩图基于16组实验研究案例,红色数据点为机理模型得到的熔池宽度);(c)实验与机理模型所得熔池深度对比;(d)L-PBF打印AA2024样品的横截面。
《2.3 双向预测的深度学习模型》
2.3 双向预测的深度学习模型
《2.3.1. 正向与逆向预测》
2.3.1. 正向与逆向预测
如图2所示,MLP深度学习模型能被用于预测工艺参数与熔池尺寸之间的双向相关性。其中,正向预测通过输入工艺参数,使MLP模型预测出熔池尺寸;而逆向预测若想进行工艺参数的推断,则需要以熔池的具体尺寸作为前提条件。
《图2》
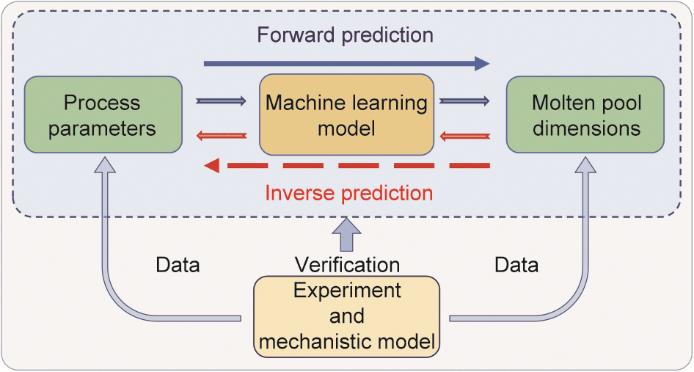
图2 实验数据和机理模型增强数据支持MLP模型正、逆向预测的示意图。
如图3所示,逆向预测可以进一步分为两种方案。根据方案1,熔池尺寸作为MLP模型的输入数据,而激光功率或扫描速度作为MLP模型的输出数据。根据方案2,MLP模型的输入为熔池尺寸和一项工艺参数的合集,输出结果是另一项工艺参数。例如,预测激光功率需要向MLP模型输入熔池宽度、深度和扫描速度。考虑到不同的激光功率和扫描速度的组合可能得到相同的熔池尺寸,本文提出了解决方案2。
《图3》
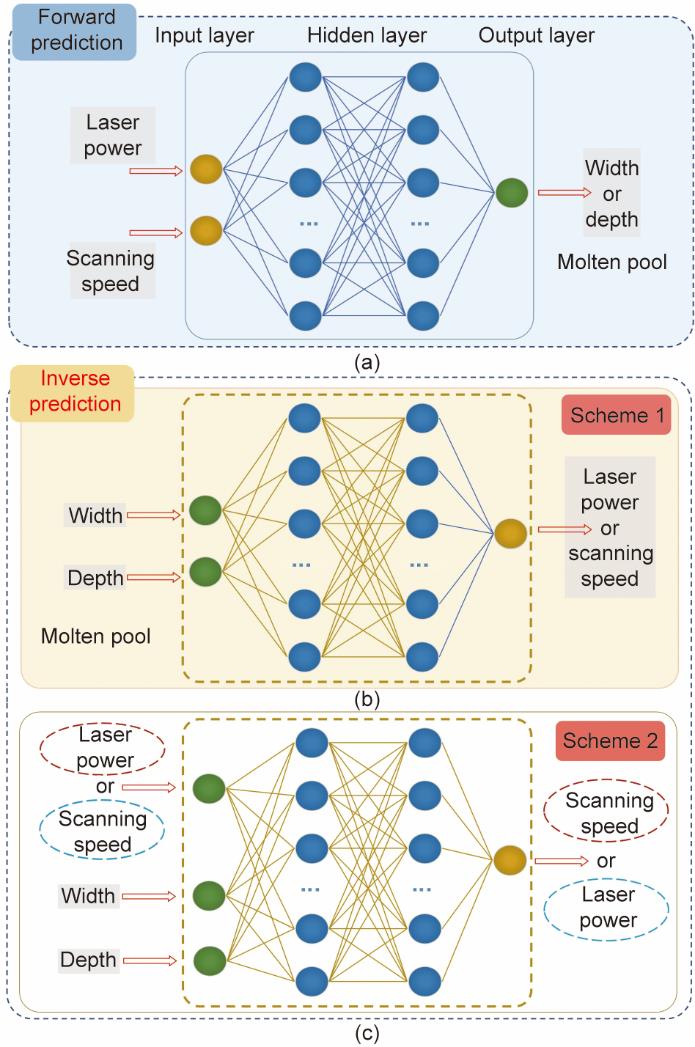
图3 双向预测示意图。(a)正向预测(通过工艺参数预测熔池尺寸);(b)逆向预测方案1(通过熔池尺寸预测工艺参数);(c)逆向预测方案2(输入端有三个变量,即一个工艺变量和两个熔池尺寸变量)。
在实际应用中,需要根据这两个方案下逆向MLP模型的预测结果,选择方案1或方案2来预测工艺参数。为确保正向和逆向预测结果的一致性,两种方案使用的数据集和MLP模型参数是一致的。需要注意的是,实验和机理模型在特定时间段内只进行了有限数量的案例研究。然而,经过良好训练的MLP模型已经具备了提供高质量网格无关结果的能力,即对于正向和逆向预测,任意输入都可以被有效地处理以生成相应的输出结果。
《2.3.2. 数据集分配》
2.3.2. 数据集分配
工艺参数和熔池尺寸的源数据是MLP模型深度学习训练的基础,而数据集的分配会影响最终的预测性能[45]。本研究使用的数据集由来自打印实验和机理模型的103组工艺参数和熔池尺寸组成,其中包括16组实验数据和87组机理模型数据。如表4所示,数据集被分成训练集、验证集和独立测试集三部分,三者的比例为70∶20∶13。在这三个数据集中,训练集被用于训练MLP模型,验证集被用于在迭代优化过程中检查MLP模型的预测精度。值得注意的是,训练集和验证集在优化过程中被反复使用。相比之下,独立测试集事先被保留,只用于检查最终应用阶段的最优MLP模型的预测精度。
《表4》
表4 不同数据集的组成
| Dataset | Amount of data |
|---|---|
| Training dataset | 70 groups (7:63) |
| Validation dataset | 20 groups (4:16) |
| Independent test dataset | 13 groups (5:8) |
为了避免MLP模型的潜在数据积累和预测偏差,相近的激光功率和扫描速度被均匀分散到三个数据集中。此外,考虑到量纲、工艺参数和熔池尺寸的差异,数据需要完成归一化后再被输入MLP模型[46]。因此,输入数据集中在0~1范围内,标准差为1。具体操作如下:
(1)
式中,
《2.3.3. MLP模型》
2.3.3. MLP模型
本文涉及的深度学习模型,是通过在Python 3.7环境下利用TensorFlow和Keras模块编写的MLP算法实现的[47]。MLP模型的权重和偏差通过Keras内部的随机初始化方法进行初始化。本研究还采用了修正线性单元函数(ReLU函数,回归神经网络中最常用的激活函数之一)以避免Sigmoid激活函数和双曲正切函数(Tanh)中的梯度消失问题[48]。
MLP模型的预测性能主要取决于三个因素:训练神经网络时样本特征的选择[49]、神经网络的优化算法以及隐藏层和神经元的确定。在本研究中,样本特征自然是工艺参数和熔池尺寸。在常用的优化算法中(包括均方根传播(RMSprop)、随机梯度下降(SGD)、自适应梯度(AdaGrad)和自适应矩估计(Adam)[50]),本研究采用了RMSprop算法,因为它能满足MLP模型的优化先决条件。关于隐藏层和神经元的选择,本研究提出并检验了多种组合,参数如表5和表6所示。此外,研究通过逐步增加神经节点和隐藏层,使机器学习模型的性能得到了提高,直到达到最佳性能[51]。MLP深度学习模型的优化路线如图4所示。特定数据集对于MLP模型的可学习性可以通过MLP模型的预测性能进行评估。
《表5》
表5 具有单个隐藏层的MLP模型的神经元数
| Model number | Neurons of the hidden layers |
|---|---|
| Model 1 | 10 |
| Model 2 | 32 |
| Model 3 | 48 |
| Model 4 | 64 |
| Model 5 | 80 |
《表6》
表6 具有多个隐藏层的MLP模型的神经元数
| Model number | The number of neurons in the hidden layer | ||||
|---|---|---|---|---|---|
| 1st layer | 2nd layer | 3rd layer | 4th layer | 5th layer | |
| Model 6 | 48 | 32 | — | — | — |
| Model 7 | 48 | 32 | 16 | — | — |
| Model 8 | 64 | 48 | 32 | 16 | — |
| Model 9 | 64 | 48 | 32 | 16 | 8 |
《图4》

图4 MLP深度学习模型的优化。a1, a2:外界输入;b1, bn, d1, dn:隐藏层的每个神经元接收到的上一层输入值;c1, cn, e1, en:隐藏层神经元经过激活函数处理产生的输出;f1:最终输出结果。
在MLP模型的训练过程中,K折交叉验证方法被用来评估过拟合和选择性偏差[48],本案例的K值设定为5。在训练过程中,MLP的预测结果必须经过分析,为后续的优化步骤提供反馈。均方误差(MSE)损失函数通常用于回归预测,但从均方误差很难直观地获得结果与实际值之间的偏离程度。因此,本研究采用绝对百分比误差[APE,公式(2)]和准确率[AR,公式(3)]来表示模型的预测性能。此外,本文还讨论了拟合优度指数(R2)。其表达式如公式4所示:
(2)
(3)
(4)
式中,
《3、 结果和讨论》
3、 结果和讨论
本节首先介绍了深度学习MLP模型的正向和逆向预测的优化,考虑了不同数量的隐藏层和神经元。随后研究了最优MLP模型在两种典型条件下的应用,使用保留的源数据和外部新数据进行检查。最后,评估了各种数据的可学习性和MLP模型的各种预测精度的机制。
《3.1 深度学习模型的优化》
3.1 深度学习模型的优化
《3.1.1. 正向预测》
3.1.1. 正向预测
图5为MLP模型优化过程中熔池宽度和深度的预测结果。使用表4所示的训练和验证数据集进行优化。MLP模型的参数见表5和表6。图5中的准确率由公式(3)计算得到。图5(a)为使用不同神经元的单一隐层对熔池宽度的预测结果,参考模型1~5。在这些情况下,熔池宽度的平均准确率随着神经元数量的增加而增加。模型6~9表明,熔池宽度的平均准确率约为95%,且对隐藏层数有较弱的依赖性。对于图5(a)所示的所有案例,最高预测精度接近100%,最低预测精度在80%以上。考虑到最低预测精度和平均预测精度,确定了熔池宽度预测的最优MLP模型为模型6。
《图5》
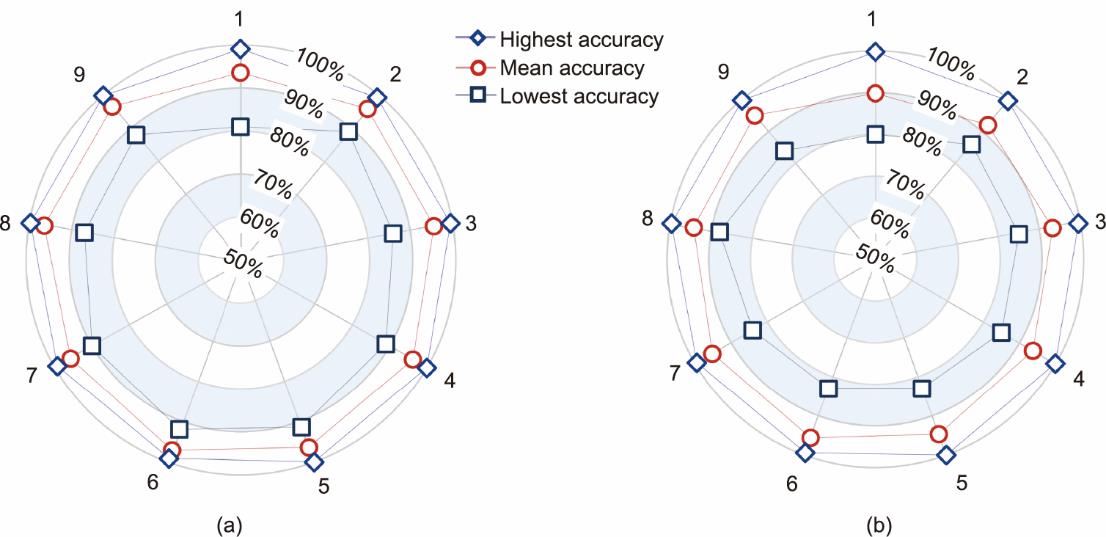
图5 使用不同的MLP深度学习模型对熔池尺寸的预测精度。(a)熔池宽度;(b)熔池深度。数字1~9是指表5和表6中所示的MLP模型。所使用的数据包括表4中的训练数据集和验证数据集。通过验证数据集获得了所提出的精度。
图5(b)表明,熔池深度的最低预测精度随着神经元数量的增加先增加后减少,隐层的预测精度也呈现相同的趋势。预测准确率最高为100%,最低为80%。总体而言,熔池深度预测的最优MLP模型为模型8。图5(a)和(b)所示的平均预测精度和最低预测精度意味着熔池宽度的预测比熔池深度的预测更准确。基本机制将在第3.3节中探讨。
《3.1.2. 逆向预测》
3.1.2. 逆向预测
图6描述了不同MLP模型下激光功率和扫描速度的两种逆向预测方案的结果。所使用的数据为表4所示的训练和验证数据集,APEs由公式(2)计算。从图6中可以看出,无论激光功率和扫描速度如何,方案1的预测误差一般都高于方案2。将使用方案1和方案2的预测结果进行比较,可以推断出在逆向预测过程中必须考虑工艺参数的依赖性。因此,逆向预测方法在后续章节中使用了方案2。
《图6》

图6 两种逆预测方案使用不同的MLP深度学习模型的预测误差。(a)激光功率作为预测输出,(b)扫描速度作为预测输出。模型编号对应表5、表6中提出的MLP模型。
图7说明了不同MLP模型对工艺参数进行逆向预测时预测精度的变化,与图6中的方案2相对应。在图中,模型1~5的预测精度分别显示了使用不同神经元的单一隐层对激光功率和扫描速度的预测精度。在这些情况下,激光功率和扫描速度的平均预测精度都随着神经元数量的增加而增加。对于模型6~9,使用不同数量的隐藏层显示了激光功率和扫描速度的预测结果。从图7(b)中可以看出,模型6和模型7的扫描速度的最低预测精度随着隐藏层数的增加而增加。然而,模型8和模型9的预测精度下降,这可能是由于L-PBF数据过度拟合造成的。
《图7》
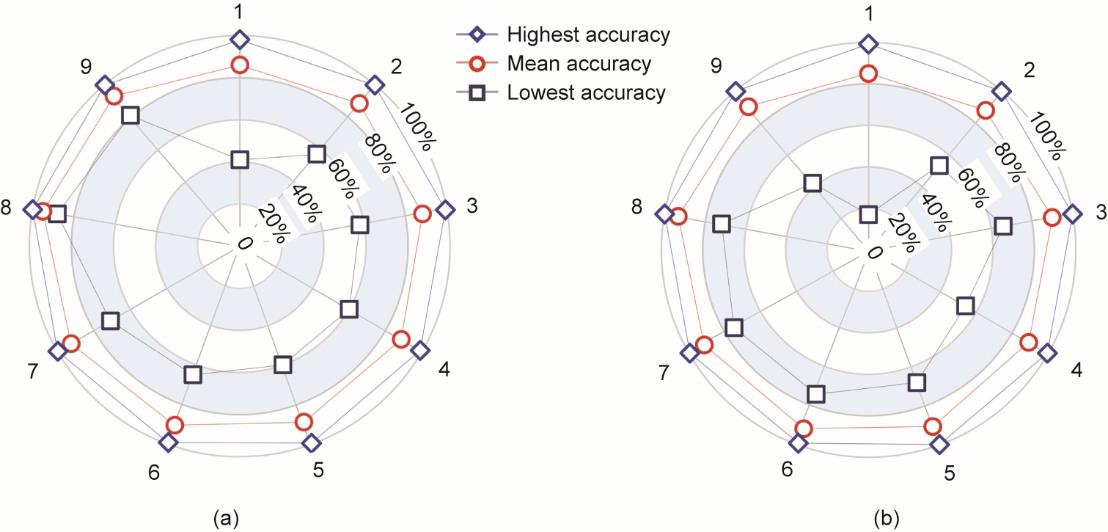
图7 不同MLP深度学习模型对工艺参数的预测精度。(a)激光功率作为预测输出;(b)扫描速度作为预测输出。
如图7所示,激光功率和扫描速度的平均预测精度均约为90%。一般来说,激光功率的预测比扫描速度的预测更准确。在图7(a)中的9组MLP模型中,对激光功率的预测准确率最高为99.9%,最低为41.0%。考虑到最低精度和平均精度,激光功率预测的最优模型为模型8。对扫描速度的最高预测精度为99.9%,最低为17.0%,如图7(b)所示。考虑到9个MLP模型的最低精度和平均精度,扫描速度预测的最优模型为模型8。
《3.2 深度学习模型的应用》
3.2 深度学习模型的应用
《3.2.1. 正向预测》
3.2.1. 正向预测
在使用训练和验证数据集进行优化后,本节将研究MLP模型在预测原始保留数据集和外部数据集中的性能。如表7所示,保留的数据集,即独立的测试数据集,来自于由表4所示的实验和机理模型结果组成的源数据集。外部数据集是通过对表4中所示的源数据集进行内插和外推来生成的。内插数据集的构造考虑了与训练和验证数据集相同的工艺参数范围,但在源数据中没有相同的值。相比之下,外推数据集的构造超出了源数据的工艺参数的范围。
《表7》
表7 MLP模型对来自不同数据集的工艺参数的应用
| Dataset | Dataset number | Laser power (W) | Scanning speed (mm·s-1) |
|---|---|---|---|
| Independent test dataset | 1 | 125 | 1350 |
| 2 | 150 | 600 | |
| 3 | 100 | 600 | |
| 4 | 325 | 450 | |
| 5 | 300 | 750 | |
| 6 | 250 | 450 | |
| 7 | 200 | 900 | |
| 8 | 350 | 1200 | |
| 9 | 220 | 1100 | |
| 10 | 300 | 300 | |
| 11 | 270 | 900 | |
| 12 | 270 | 300 | |
| 13 | 270 | 600 | |
| Interpolation dataset | 14 | 180 | 700 |
| 15 | 130 | 400 | |
| 16 | 310 | 800 | |
| 17 | 210 | 500 | |
| 18 | 330 | 660 | |
| 19 | 260 | 430 | |
| Extrapolation dataset | 20 | 390 | 1500 |
| 21 | 400 | 1350 | |
| 22 | 375 | 1200 | |
| 23 | 360 | 1050 | |
| 24 | 390 | 900 | |
| 25 | 400 | 750 | |
| 26 | 375 | 600 | |
| 27 | 360 | 450 |
(1)独立测试数据集的预测。首先,通过在独立测试数据集中使用激光PBF案例对熔池尺寸进行前向预测,以检验最优MLP模型的性能。图8(a)和(b)给出了目标熔池宽度和预测熔池宽度的比较。目标熔池宽度是来自于实验和机理模型结果的源数据,而对于相同的工艺参数,预测的熔池宽度来自MLP模型。数据点和渲染的颜色图都显示了目标和预测结果的近似值。图8(c)进一步显示了预测的准确性。结果表明,熔池宽度的最高预测准确率接近100.0%,平均预测准确率为96.6%,最低预测准确率大于90.0%。计算出的R2值相应地为0.97。
《图8》
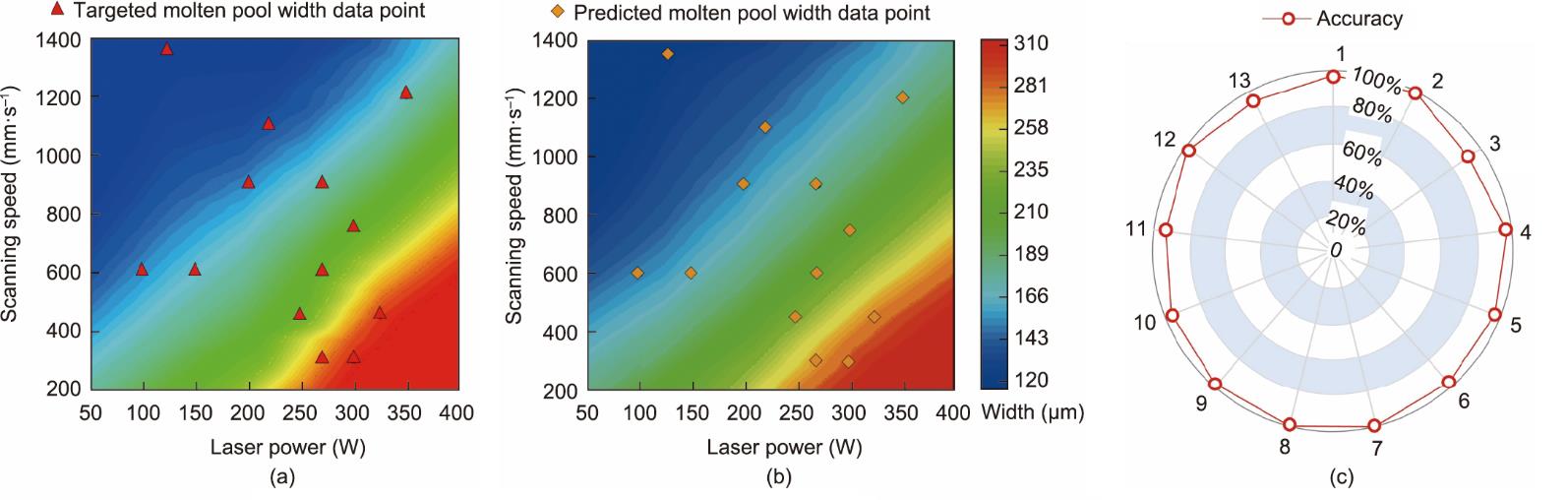
图8 利用独立的工艺参数对熔池宽度的预测结果。(a)目标熔池宽度;(b)由MLP模型预测的熔池宽度;(c)对独立测试数据集中所有情况的预测精度。数字1~13是指表7中的独立测试数据集的情况。
图9(a)和(b)显示了独立测试数据集在相同工艺参数下的目标熔池深度和预测熔池深度。数据点和渲染的颜色分布非常接近,如图9(a)和(b)所示,表明使用MLP模型与源数据预测结果的一致性。此外,图9(c)显示最高的预测准确率为98.4%,最低的准确率为89.0%,分别对应于第5和第12种情况。熔池深度的平均预测精度为94.5%,R2值为0.97。因此,所有具有独立测试数据集的案例都表明MLP模型对预留的激光PBF案例具有较高的预测精度。
《图9》

图9 利用独立的工艺参数对熔池深度的预测结果。(a)目标熔池深度;(b)由MLP模型预测的熔池深度;(c)对独立测试数据集中所有情况的预测精度。
(2)对插值和外推数据集的预测。除了将MLP模型应用于保留源数据的情况,还使用各种具有内插和外推数据的激光PBF情况进一步验证了MLP模型。前者是为了在源数据的相同范围内评估工艺参数的MLP模型的性能,后者是为了测试MLP模型对源数据范围以外条件的适用性。图10显示了在工艺参数内插和外推下熔池宽度的预测结果。在图10(a)和(b)中,与外推工艺参数对应的激光功率在350~400 W之间。这一范围确保了外推的基本要求,并进一步防止由工艺参数超出加工设备的最大激光功率范围所引起的误差。图10(c)表明,熔池宽度的预测精度均在90%以上,插值情况下的结果优于外推情况。R2值也说明了这一点,对于插值和外推情况,其值分别为0.95和0.93。在外推工艺参数下,熔池宽度的最高、平均和最低预测准确率分别为98.0%、97.3%和96.6%。
《图10》
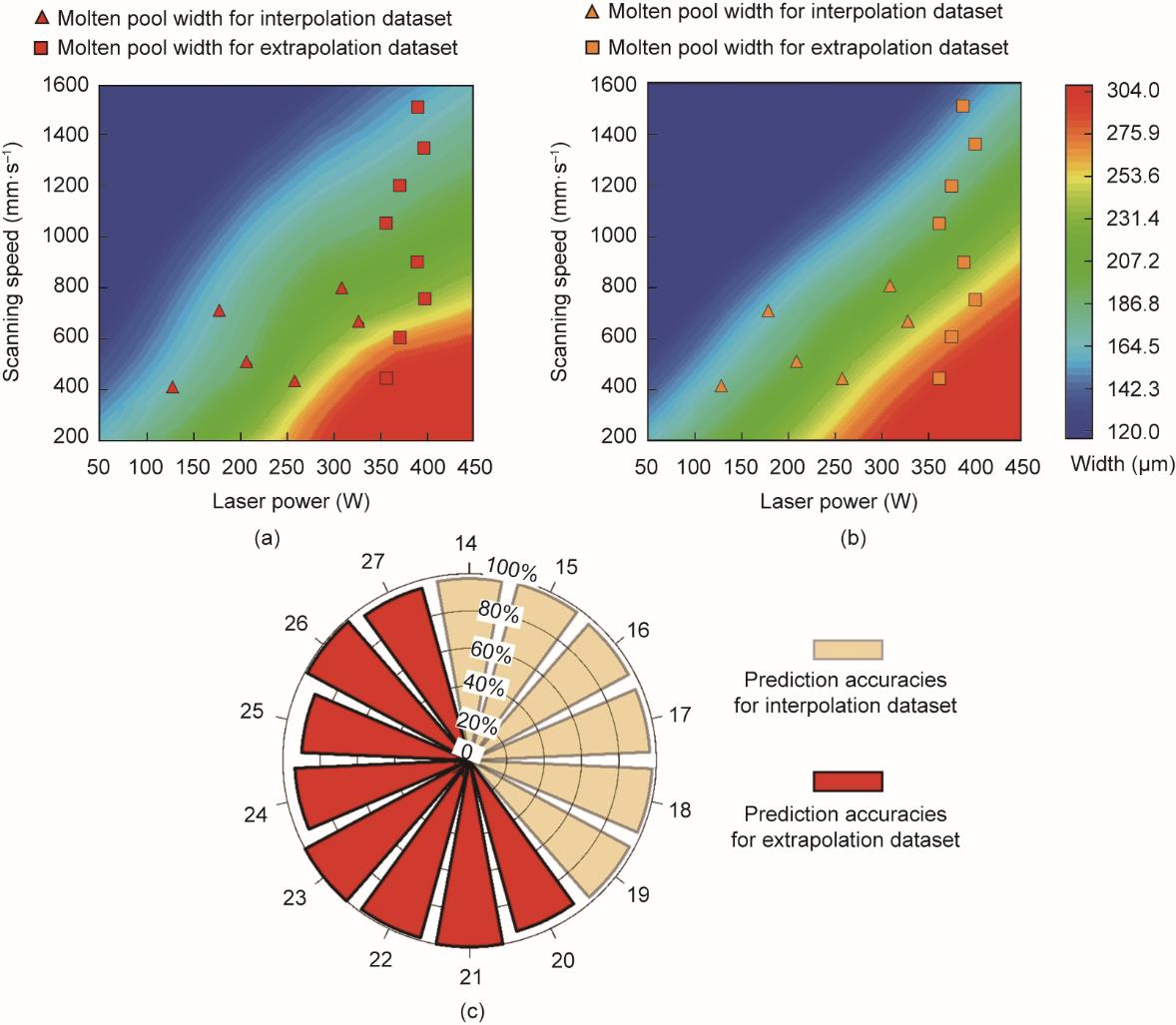
图10 对插值和外推数据集的熔池宽度的预测结果。(a)通过机理模型获得的目标熔池宽度;(b)由MLP模型预测的熔池宽度;(c)在内插和外推数据集中,所有情况下的预测精度。数字14~27为表7中的插值和外推数据集。
图11显示了通过内插和外推得到的熔池深度低于工艺参数的预测结果。如图11(a)和(b)所示,预测的熔池深度接近目标熔池深度。在图11(c)中,插值情况下熔池深度的平均预测准确率为94.66%。平均预测精度表明,在同一参数范围内,即使采用不同的区间,也可以准确地预测深度。在外推的工艺参数下,最高精度约为100%,熔池深度的平均预测精度为95.99%。两种情况下的R2值都是0.95。
《图11》
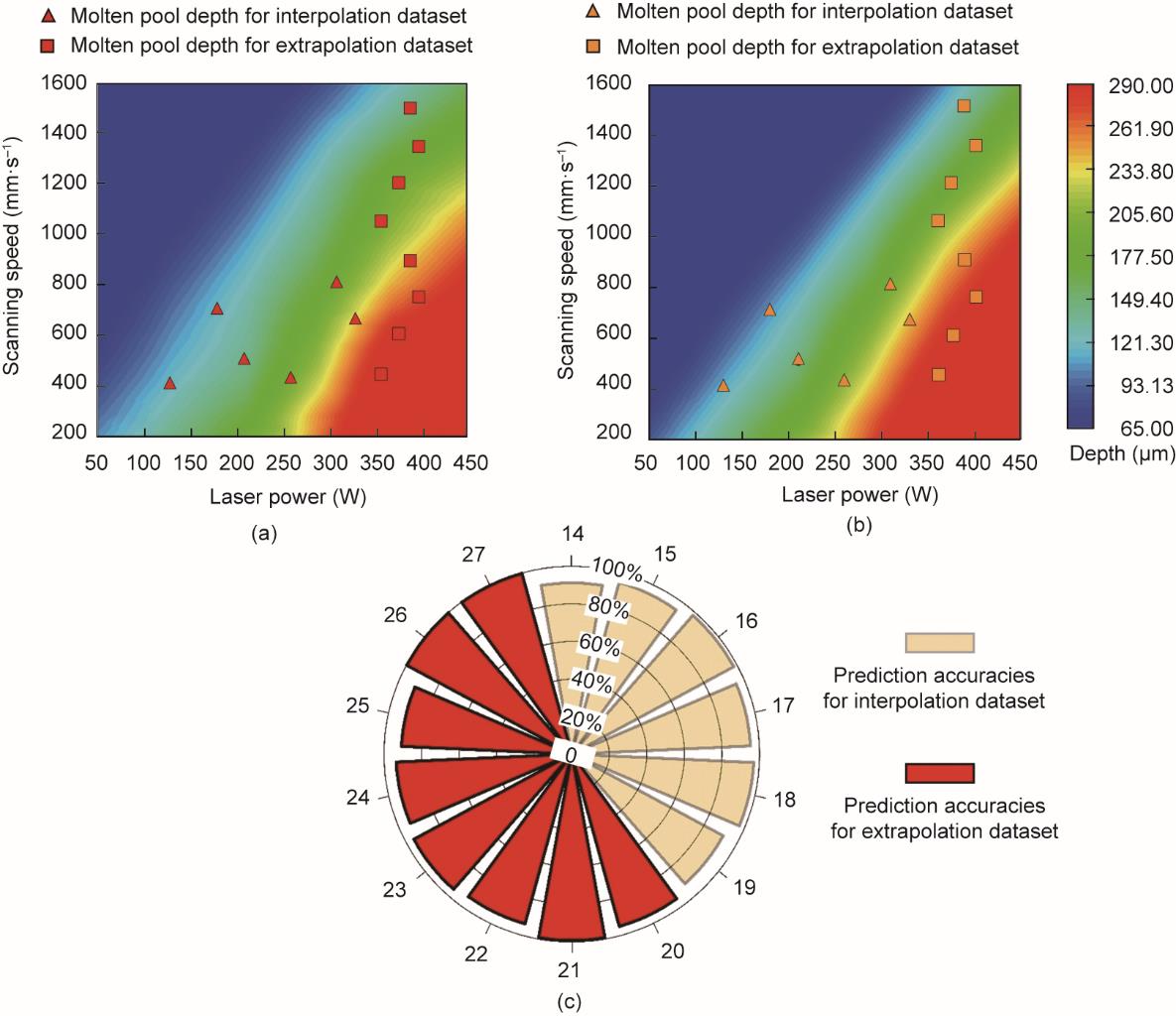
图11 对插值和外推数据集的熔池深度的预测结果。(a)通过机理模型获得的目标熔池深度;(b)由MLP模型预测的熔池深度;(c)在内插和外推数据集中,所有情况下的预测精度。
《3.2.2. 逆向预测》
3.2.2. 逆向预测
在通过第2.3.2节描述的方法使用训练和验证数据集进行优化之后,在本节中检查了MLP模型在独立测试、内插和外推数据集的逆向预测中的性能。
(1)激光功率预测。图12显示了使用三种不同类型的数据集预测激光功率的结果。应该注意的是,模型输入是扫描速度及相应的熔池宽度和深度,而预测的输出是激光功率。如图12(b)所示,当使用独立的工艺参数预测激光功率时,最高预测准确率为99.9%,最低预测准确率为84.0%,分别对应于第1种和第9种情况。相应的R2值是0.96。所有案例的平均AR都在90%以上。对三种输入下激光功率的预测结果表明,训练良好的MLP逆向预测模型具有较高的精度。
《图12》
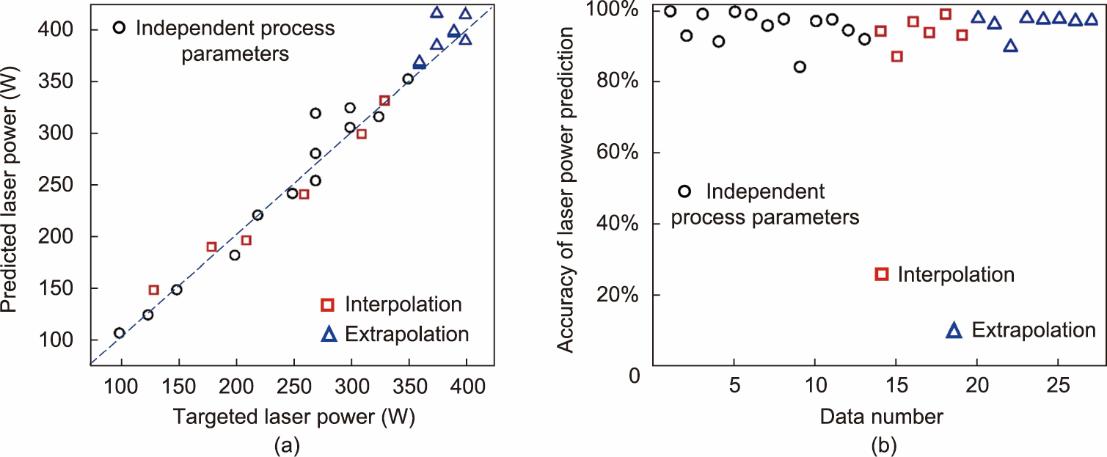
图12 使用表7所示的各种数据集预测激光功率。(a)目标和预测激光功率;(b)MLP模型的预测精度。模型输入是熔池的宽度、深度和扫描速度;预测的输出是激光功率。
(2)扫描速度预测。图13显示了在三种不同类型的数据下扫描速度的预测结果。需要注意的是,模型输入是激光功率及相应的熔池宽度和深度,而预测的输出是扫描速度。图13表明扫描速度的预测精度比激光功率的预测精度波动更大。通过平均精度评价,插值和外推实例的预测精度均低于独立实例的预测精度。独立测试用例、插值用例和外推用例的R2值分别为0.97、0.86和0.93。如图13(b)所示,独立测试数据集的最高和平均预测准确率分别为98.8%和93.0%。对于插值和外推数据集,扫描速度的最高预测准确率超过99%,平均准确率分别为91%和90%。可以观察到,扫描速度的最低预测精度出现在较慢的扫描速度时,对应于较高的线能量密度。低预测精度和低扫描速度背后的机制将在第3.3节中解释。
《图13》
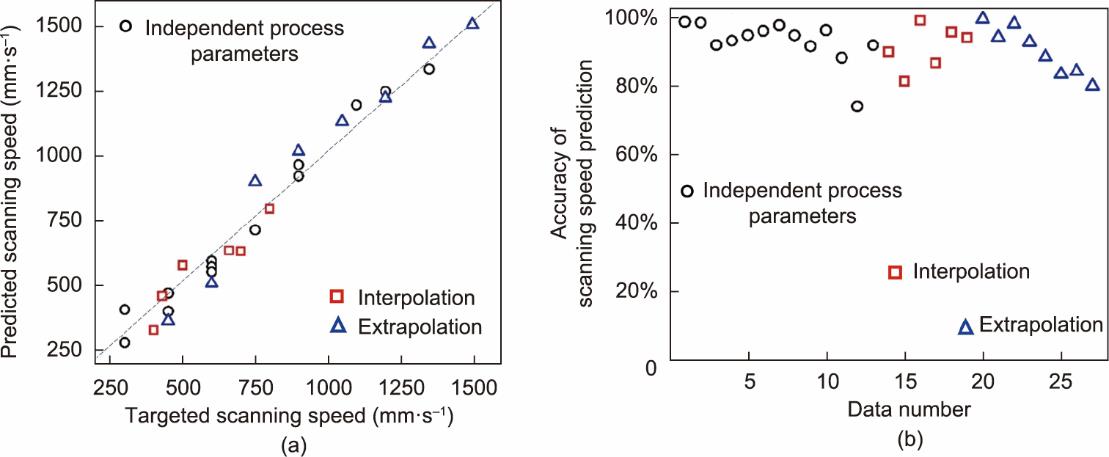
图13 使用表7中所示的各种数据集的预测扫描速度。(a)目标和预测扫描速度;(b)MLP模型的预测精度。
简而言之,上述结果证明了该模型对工艺参数和熔池尺寸的良好预测精度,包括独立试验、插值条件和外推条件。这些正向和逆向预测性能表明训练有素的MLP模型在各种激光PBF条件下的可靠性。
《3.3 数据的可学习性》
3.3 数据的可学习性
MLP模型作为一种数据驱动的方法,其性能在很大程度上取决于数据集的特点。需注意的是,并非所有的数据都适合深度学习模型的训练和预测[52]。虽然快速从少量数据中学习并适应的能力是理想的[53],但对于深度学习模型而言,合格的候选数据通集常包括具有物理意义或统计规律的数据。本节将针对L-PBF制造过程,从数据的数量和质量两个指标出发,检验数据的可学习性。
《3.3.1. 数据集数量和预测准确性》
3.3.1. 数据集数量和预测准确性
考虑到数据驱动的本质,数据集的数量是深度学习模型训练的关键因素。在本小节中,使用不同的L-PBF案例数据集(实验数据及混合实验和机理模型数据)进行MLP模型的训练,并比较了模型的预测性能。以熔池宽度的预测精度为例进行了比较,并采用了与MLP模型相同的优化方法。对于实验数据,表1中列出的案例用于训练、验证和独立测试。表7中列出的内插和外推数据集进一步用于验证训练的最佳模型的实际性能。相比之下,表4中列出的案例用于混合实验和机理模型数据。预测结果如表8所示。
《表8》
表8 不同数据下熔池宽度的预测结果
| Dataset | Training: validation: independent test | Mean prediction accuracy for independent test dataset | Mean prediction accuracy for interpolation dataset | Mean prediction accuracy for extrapolation dataset |
|---|---|---|---|---|
| Experimental data | 11:3:2 | 59.0% | 48.5% | 68.3% |
| Experimental and modeling data | 70:20:13 | 96.6% | 97.3% | 96.3% |
如表8所示,当仅使用实验数据时,熔池宽度的平均预测精度明显较低。例如,当纯实验数据用于训练和验证MLP模型时,独立测试数据集的平均预测精度仅为59.0%,相比之下,当使用混合数据时,平均准确率为96.6%。因此,为了获得适当的预测精度,应该生成更大量的数据。在本研究中,研究了16组到100多组数据的测试案例,根据预测准确性和准备效率,确定了表4中所示的数据量。简而言之,可以得出结论,充足的数据是准确预测L-PBF的MLP深度学习模型的先决条件,而机理模型可以作为增强数据集的有力工具。
《3.3.2. 数据集质量和预测精度》
3.3.2. 数据集质量和预测精度
除了数量,数据集的质量也可能影响MLP模型的预测精度。图14(a)显示了在正向预测期间熔池宽度的预测精度总体上高于熔池深度的预测精度。此外,当使用更高的能量密度时,深度的预测精度降低。图14(b)显示了逆预测精度随线性能量密度的变化。可以观察到,当使用较高的线性能量密度时,扫描速度的预测精度明显较低。图14(c)显示了熔池尺寸随线性能量密度的变化。可以观察到,当线性能量密度超过0.5 J∙mm-1时,熔池深度的变化显著分散。熔池深度和宽度的标准偏差分别为67.09和49.46。这些偏差的差异源于L-PBF过程中熔池的物理性质。
《图14》

图14 预测精度和熔池尺寸随线性能量密度的变化。(a)熔池尺寸的前向预测精度;(b)工艺参数的逆预测精度;(c)熔池尺寸随线性能量密度的变化。
图15比较了在L-PBF的不同线性能量密度下获得的熔池和沉积道特征。图15(a)和(b)显示了三维温度场和沉积道剖面。从图15(f)可以观察到,熔池深度沿着扫描方向显著变化。相反,当使用0.2 J∙mm-1的线性能量密度时,图15(e)中的沉积道的底部波动较小。此外,沉积道宽度的变化都是微不足道的,如图15(c)和(d)所示。这些差异可能源于L-PBF过程中的热传递和流体流动机制。产生了深且易变的小孔,小孔在很大程度上决定了制造过程中熔池的穿透深度[54‒55]。值得注意的是,小孔的形状和大小取决于液态金属的剧烈流动和粉末颗粒的飞溅,这在高能量密度条件下会更加严重[2,56‒57]。由于熔池沿小孔深度方向的敏感性较大,熔池深度的波动大于宽度的波动。因此,当使用MLP模型时,熔池深度的预测精度低于宽度的预测精度。
《图15》
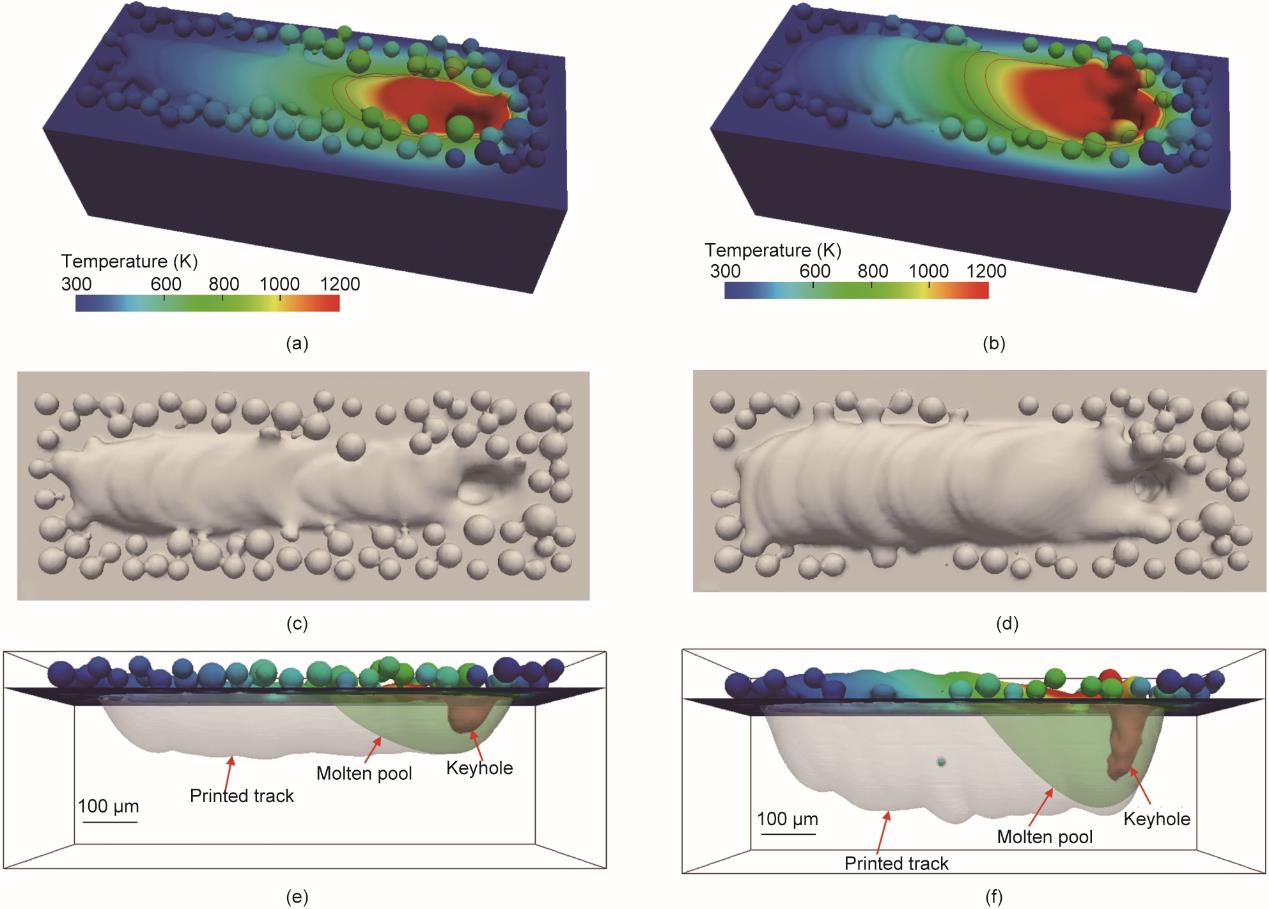
图15 不同工艺条件下获得的熔池和沉积道特征。(a)、(c)、(e)220 W和1100 mm∙s-1,线性能量密度为0.2 J∙mm-1;(b)(d)(f)300 W和600 mm∙s-1,线性能量密度为0.5 J∙mm-1。(a)和(b)提供构建的3D视图,(c)和(d)为俯视图,(e)和(f)为打印区域和熔池的纵向视图。
《3.3.3. 输入和输出变量的相关性评估》
3.3.3. 输入和输出变量的相关性评估
为了揭示工艺参数与熔池尺寸之间的相关性,采用了皮尔逊相关系数(PCC)和最大信息系数(MIC)。对表3所示的99个病例进行了数据分析。PCC可用于测量变量之间的线性相关程度,其中相关程度与系数的绝对值成正比。MIC可用于寻找变量之间的线性或非线性相关性[58]。0和1之间的MIC值越高,表示相关性越强。如图16所示,扫描速度与熔池宽度有更密切的关系,而激光功率与熔池深度有更密切的关系。此外,还计算了工艺参数与熔池尺寸相关性分析的显著性水平。发现激光功率在熔池宽度和深度之间的显著性值分别为6.46×10-9和1.86×10-17。熔池宽度和深度之间的扫描速度显著值分别为1.78×10-19和1.84×10-10。因此,工艺参数与熔池尺寸的相关性分析结果具有重要意义。
《图16》
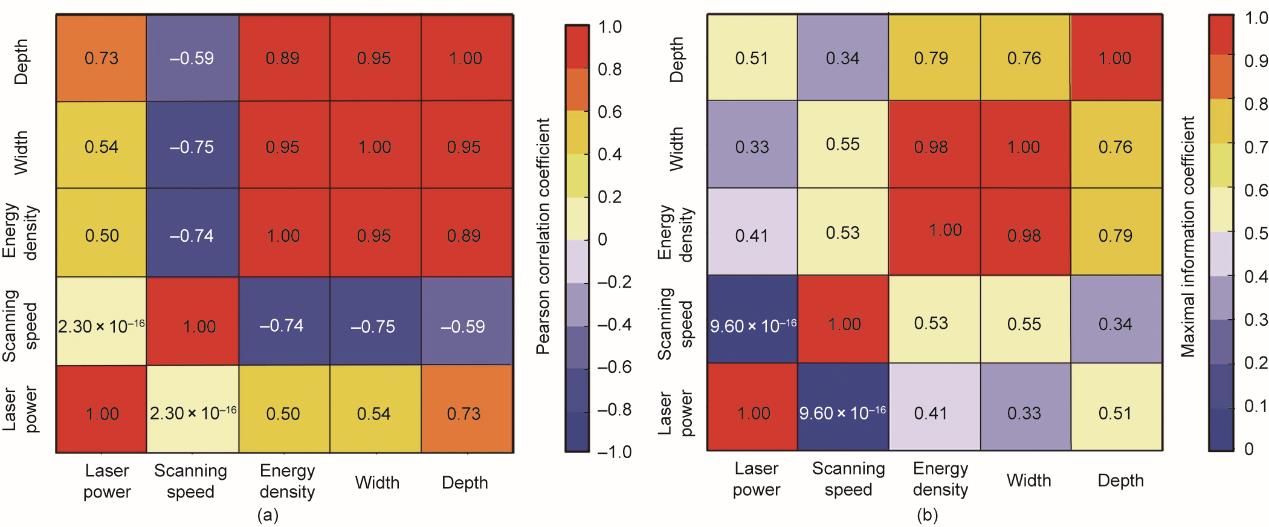
图16 参数相关性分析。(a)PCC系数;(b)MIC系数。
为了进一步探索熔池尺寸与工艺参数之间的相关性,使用了四组新的输入变量,如图17所示。只有一个单一的熔池尺寸和一个单一的工艺参数用于MLP模型的输入。应该注意的是,在图3中,熔池宽度和深度都用于逆向预测的方案1和2中的MLP模型的输入。图17(a)显示了当熔池深度包括在MLP输入中时,激光功率的平均预测精度较高。相反,图17(b)显示出当熔池宽度包括在MLP输入中时,扫描速度的平均预测精度较高。比较表明,与熔池宽度相比,熔池深度更与激光功率相关。
《图17》
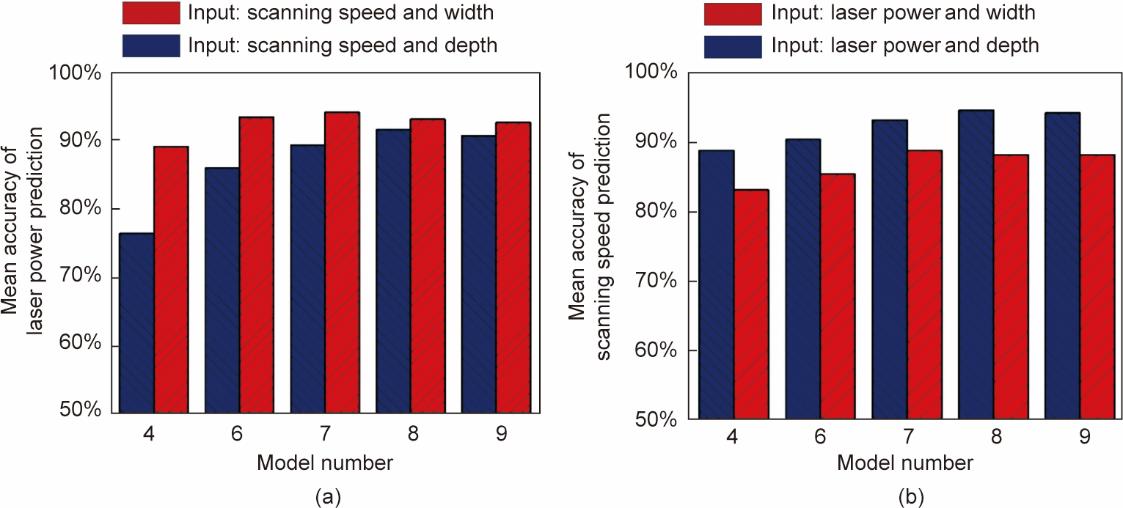
图17 逆向预测不同输入情形下的结果。(a)激光功率预测平均准确率;(b)扫描速度预测平均准确率。
《4、 结论》
4、 结论
给定多维打印零件,熔池特性对L-PBF的构建质量有显著影响。本研究结合实验、高保真机理模型和MLP深度学习模型,对L-PBF过程中的关键工艺参数和熔池特性进行双向预测。评估了预测精度对数据集可学习性的依赖性。从这项工作中可以得出以下结论:
(1)熔池的正向和逆向预测可以实现预测L-PBF的尺寸和关键工艺参数,预测精度接近99.9%。从L-PBF工艺参数——特别是内插值和外推值——到熔池尺寸的正向预测有助于在实验之前预测熔池特性,而从熔池尺寸到工艺参数的逆向预测在需要特定熔池尺寸时是有用的。
(2)MLP模型的预测精度与数据集的多少密切相关。通过机理模型增加数据集,最高预测精度为97.3%。相比之下,当仅使用实验数据进行MLP模型训练时,最高预测精度为68.3%,最低为48.5%。因此,一个经过良好测试的机理模型可以有效地解决实验数据不足的问题。
(3)MLP模型的预测精度很大程度上取决于数据集的质量。例如,发现工艺参数对熔池深度的正向预测精度低于对熔池宽度的正向预测精度。原因是熔池深度由于复杂的瞬态匙孔特征而表现出较差的数据规律性。
(4)MLP模型的参数是预测精度的重要组成部分。准确的预测需要合适的优化方法、激活函数以及隐藏层和神经元。
这项研究为探索L-PBF中的高度非线性关联提供了一条有意义的途径。尽管预测是通过工艺参数和熔池特性来举例说明的,但是所提出的方法对于需要对具有复杂相互依赖性的变量进行正向和逆向预测的其他条件来说也是可行的。此外,所提出的框架可以作为AM数字孪生的关键构建模块,从而促进智能AM设备和流程的未来发展[2,6,59‒61]。











 京公网安备 11010502051620号
京公网安备 11010502051620号




