

《1、 引言》
1、 引言
在所有自然灾害中,洪水是最常见的类型,对人类和财产安全都有很大的危害[1‒3]。伴随气候变化和人类活动,洪水的频率和强度也在增加[4]。自古以来,人类为抗击洪水做出了相当大的努力,包括各种结构性和非结构性方法[5]。结构性方法是作用最显著的防洪措施,如修建堤、坝、堰等。同时,洪水预报模型和系统等非结构性方法也在备灾规划、减轻洪水风险方面发挥了突出作用。近几十年来,随着计算机科学和水文科学的发展,洪水预测模型已用于在全球范围内解决洪水问题。然而,由于其复杂性和非线性,洪水预测仍旧是一项非常困难和重要的任务,需要先进的模型和更高的准确性。
一般来说,径流预测模型可以分为基于过程的模型和数据驱动模型[6‒7]。基于过程的模型可以追溯到1960年代,是一种明确表示水文状态变量和通量的数学公式。迄今为止,已经提出并广泛应用于径流预测的基于过程的水文模型,包括集总式和分布式模型[8]。例如,TOPMODEL是最早明确使用地形数据来反映模型公式中流域水文响应特征的模型之一[9],被用于不同地区的径流预测[10‒11]。SWAT [12]是一种半分布式水文模型,自诞生以来经历了持续的发展,相继集成了雷达降水[13]、地下水单元[14]、融雪单元[15]等多种模块,在径流预测方面表现良好[16‒17]。AWBM是一种集总式水文模型,可以使用每日降雨量来估算每日径流[18‒19]。尽管基于过程的模型具有应用广泛和可解释性强的优势,但在洪水预测方面仍然存在一些不足,如过度参数化、复杂度高、需要丰富的专家知识和对数据要求高等。
基于统计理论的数据驱动模型可以自动学习影响因素与径流之间的关系,不仅具有较低的成本,而且效率高。大量数据驱动的径流预测模型被提出并用于实践[20],包括人工神经网络(ANN)[21]、支持向量机(SVM)[22]、神经模糊网络[23]、自适应神经模糊推理系统(ANFIS)[24]、小波神经网络[25]和多层感知器(MLP)等。其中,ANN由于具有良好的泛化能力和较高的准确性,是上述所有模型中最受欢迎的径流预测模型,但是它未能对数据序列的时间依赖性进行建模并准确预测峰值。时间依赖性是指时间序列中先前数据与当前数据之间的自相关关系,往往难以用方程直接表达[26]。相比之下,具有门控机制的长短期记忆(LSTM)模型以其出色的性能、简单的架构和优越的时间依赖能力而脱颖而出。
LSTM是Hochreiter和Schmidhuber [27]提出的一种深度学习模型,用于解决长序列反向传播过程中信息存储复杂的问题。由于在长序列任务上的出色表现,LSTM自问世以来就被广泛应用于各个领域,尤其是时间序列领域。近年来,LSTM在水文学领域备受关注[28‒32]。例如,Kratzer等[33]在CAMELS(Catchment Attributes and Meteorology for Large-sample Studies)数据集中使用LSTM研究了241个流域的径流预测,并证明LSTM可以在大多数流域获得良好的模拟结果,同时,也验证了LSTM在流域尺度变换中的有效性,可见LSTM的巨大潜力。然而,峰值流量预测问题仍然是LSTM面临的重大挑战[34‒35]。
洪峰流量预测的挑战主要在于两个方面。一是如何识别径流预测的重要输入特征,另一个是如何优化模型的目标函数以获得良好的预测结果。虽然LSTM模型可以捕获输入数据序列(如降雨)的时间特征,但它忽略了时间特征的空间异质性。实际上,在实践中,不同的雨量站对径流预测的影响是不同的,因此,需要改进LSTM模型的结构。LSTM 通常以均方误差(MSE)作为模型优化的损失函数,但是,MSE对预测误差不同的样本不做区分,没有强调峰值流量预测的重要性。Ding等[36]利用极值理论在极端事件模型中设计了一种新的损失函数[极值损失(EVL)],其主要思想是调整极端事件的权重,使模型在参数优化过程中更加关注极端事件中的极值。因此,可以为LSTM设计新的损失函数,以提高其处理峰值流量预测的能力。
准确地预报淮河流域上游地区的洪水对整个淮河流域的洪水管理具有重要意义。淮河是中国七大河流之一,位于中国东部的长江和黄河之间。淮河流域由于属大陆性季风气候,大气系统复杂多变,易发洪水,约两年一次[37]。淮河上游流域是淮河上游的重要控制流域。在过去的几十年里,在淮河流域上游径流预测方面做了大量工作,例如,Liu等[38]使用完全分布式模型地形运动学近似和积分(TOPKAPI)以六小时的时间步长预测径流。Lv等[39]构建了循环预测的LSTM模型,并在小时洪水预报方面取得了良好的效果。然而,现有的研究大多是零散的,侧重于相对较快的小时径流预测或洪水事件分析,而缺乏长期连续的日径流预测。此外,在气候变化、人口增长和经济发展的背景下,淮河流域上游在过去几十年经历了显著的气候变化和土地利用变化[40‒41],对准确的径流预测有很大的需求。
本研究旨在提出一种增强型LSTM模型以提高日径流预测精度,促进防洪。研究目标如下:①探索近几十年淮河流域上游水文气象变量和土地利用的变化趋势;②使用增强型LSTM模型预测淮河流域上游的径流和洪水;③将改进后的LSTM模型与现有不同模型进行比较,证明其在研究区径流预测任务上的优越性。
《2、 研究区域和数据获取》
2、 研究区域和数据获取
《2.1 研究区域》
2.1 研究区域
选取位于中国东部流域、面积为10 190 km2的淮河流域上游作为研究区。流域属亚热带季风湿润气候区,年均气温15.43 ℃。季风主要影响降水,年均降水量1043 mm,其中50%集中在6—9月。流域河网呈树枝状分布,平均径流深度约350 mm。流域属于盆地地形,地势西高东低,平均海拔47 m。其中大部分土地为耕地,有少量城市和林地。在流域内/周边建立了6个覆盖空间异质性的气象站,海拔最高的气象站位于上游,站号为57 285和57 390;站号为57 295、57 297和57 298的气象站位于该地区的中游,地势相对平坦;57 296号站点位于淮河上游出口,海拔最低。
《2.2 数据获取》
2.2 数据获取
从中国气象数据服务中心(https://data.cma.cn)收集了1951—2016年的日降水量、蒸发量和温度等气候数据。息县水文站1951—2016年日径流量数据由河南省水文局提供。本研究还使用了空间分辨率为30 m的SRTM1 DEM数据(https://glovis.usgs.gov)。1987年研究区土地利用分类使用Landsat 5 Thematic Mapper(TM)Collection 1 Level-1数据,2016年土地利用分类使用Landsat 8 Operational Land Imager(OLI)Collection 1 Level-1数据。
《3、 方法》
3、 方法
本研究应用世界气象组织推荐的基于非参数的Mann-Kendall检验[42]和线性回归方法来识别气象和水文变量的变化趋势。在介绍增强型LSTM模型之前,第3.1节先介绍LSTM模型的基本结构。为了与现有方法进行比较,在第3.2节中选择并简要介绍具有代表性的对比模型。为评估不同模型的性能,本节最后介绍具体的评估指标。
《3.1 LSTM网络》
3.1 LSTM网络
LSTM是从递归神经网络(RNN)[43]发展而来的。与RNN相比,LSTM增加了遗忘机制,一定程度上可以缓解梯度爆炸的问题。在LSTM的结构(图1)中,称为记忆单元的特定单元类似于累加器和门控神经元。记忆单元在下一个时间步中具有并行权重并联接到自身,复制其状态的实际值和累积的外部信号量。这种自联接是由LSTM内部的一个乘法门控制的,它自动学习并决定何时清除记忆单元中的记忆内容。为了便于理解,定义时间为下标t,隐藏状态为
《图1》
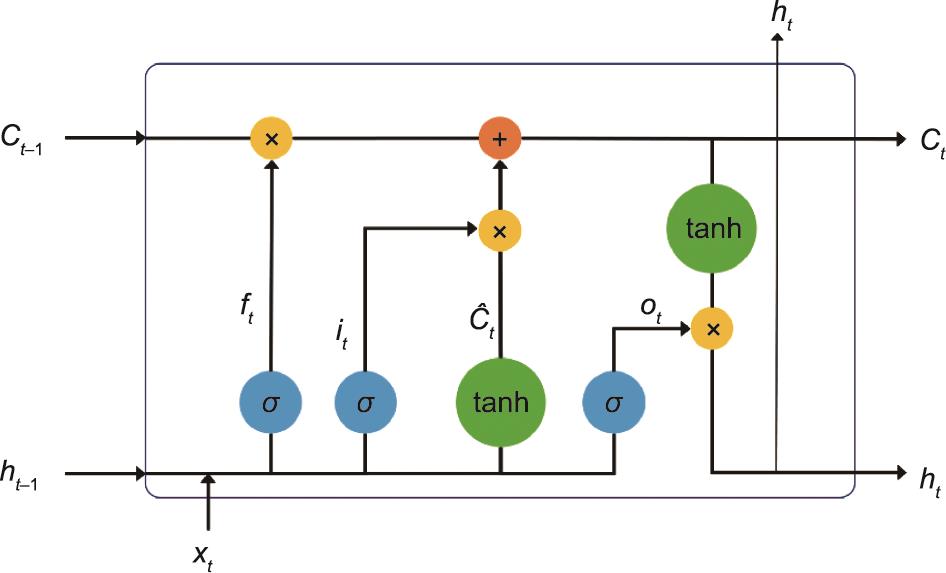
图1 LSTM模型结构。这里的下标“t”表示当前时间,
LSTM由三个门组成:输入门、输出门和遗忘门。它的前向传播过程可以用公式(1)~(6)来描述:
输入门:
(1)
输出门:
(2)
遗忘门:
(3)
细胞单元
(4)
(5)
(6)
式中,
与RNN相比,加入遗忘机制
《3.2 用于径流预测的增强型LSTM模型》
3.2 用于径流预测的增强型LSTM模型
《3.2.1. 集成特征提取器到LSTM模型中》
3.2.1. 集成特征提取器到LSTM模型中
增强型LSTM模型的流程图如图2所示,包括四个模块:输入层、特征提取器、预测器和输出层。与原始LSTM模型不同,增强型LSTM模型具有集成的特征提取器,旨在确定径流预测任务的关键特征。在本文中,假设不同站点的降水可能对径流产生不同的贡献,为河南省息县水文站的每个气象站提出了一个单独的特征提取器。
《图2》

图2 用于日径流预测的增强型LSTM模型框架。
特征提取器由三个LSTM组成。具体而言,它以降水量(P)、条件累积降水量(CCP)和时刻
随后,使用残差连接技术将从每个特征提取器得到的每个站点的输出特征与步长为τ的历史径流拼接在一起。最后,使用LSTM预测时间
《3.2.2. 用于改进峰值径流预测的损失函数》
3.2.2. 用于改进峰值径流预测的损失函数
MSE是典型的用于回归问题的损失函数,公式如下:
(7)
式中,
上述公式表明,无论径流预测误差是高还是低,MSE不对其进行区分。然而,峰值径流预测误差是洪水预报中更关注的问题,而正常径流预测的误差相对来说并没那么重要。鉴于此,本研究设计了两个新的损失函数来增加峰值损失的重要性,以提高峰值径流预测的准确性。
(1)Peak error tanh(PET)。由于极值径流的误差比正常径流的误差大,所以在MSE中可以对较大的误差增加权重。本文在MSE外添加了一个tanh函数,以放大较大的误差同时减少较小的误差的影响。公式如下:
(8)
其函数曲线如图3所示。自变量越大,函数值也越大;自变量越小,函数值也相应变小。从而达到放大较大误差,减少小误差的目的。
《图3》
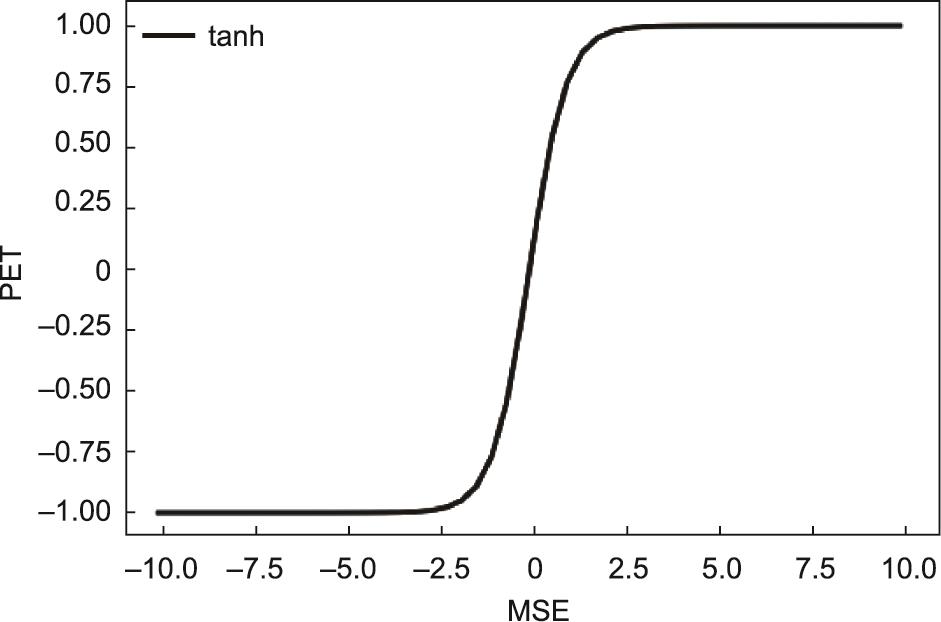
图3
(2)Peak error swish(PES)。
《图4》
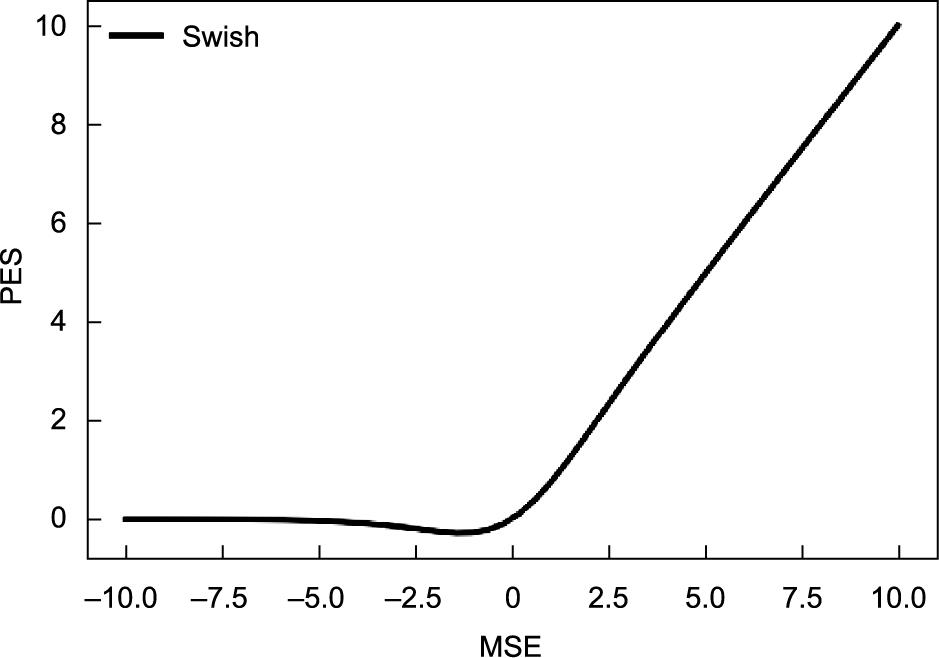
图4 Swish函数图像。
融合
(9)
《3.2.3. 增强型LSTM模型的训练过程》
3.2.3. 增强型LSTM模型的训练过程
增强型LSTM模型训练采用了mini-batch训练技术。批量大小为64,epoch大小为200,Adam优化器用于训练模型。本研究使用了三个损失函数进行对比,分别是MSE、PET和PES。为了使每个输入数据的特征保持在相同的数值范围内,使用公式(10)对数据进行归一化。
(10)
式中,
《3.3 径流预测对比模型》
3.3 径流预测对比模型
为了验证增强型LSTM模型对日径流预测的有效性,三个数据驱动模型[支持向量回归(SVR)、ANN、门控循环单元(GRU)]和4个集总式水文模型(AWBM、Sacramento、SimHyd、Tank Model)被选作对比模型。
SVR是SVM [22]在回归任务中的一个重要应用。SVR的工作原理是找到一个回归平面,以便一组中的所有数据都最接近该平面。为了实现非线性数据的回归任务,SVR还可以使用非线性核得到一个超平面来拟合数据。SVR因其简单、高效和卓越的性能而受到青睐。ANN模型是根据生物神经网络模拟大脑功能的信息处理系统[21,48],该系统由输入层、隐藏层和输出层组成。作为经典的机器学习模型之一,它也是大多数深度学习模型的基础。由于ANN结构的高度灵活性,可以根据具体应用设计合适的网络结构和损失函数。ANN学习对训练数据中的错误具有鲁棒性,现在已成功应用于许多领域。
GRU是RNN衍生模型的一种[49]。在很多情况下,它的表现与LSTM类似,但更容易训练,并且极大地提高了训练效率。SVR和ANN都是应用广泛且具有代表性的传统数据驱动模型。为了验证所提出的模型相对于传统数据驱动方法的先进性,选择SVR和ANN进行比较。此外,将所提出的模型与GRU(与LSTM具有相似效果)进行比较,可以表明增强型LSTM的结构优势。
AWBM是一种流域水平衡模型,它通过每日或每小时的数据将降雨和蒸散与径流联系起来[18],计算洪水水文模型的降雨损失。该模型包含5个存储模块,包括三个地表存储、一个基流存储和一个地表径流路径存储。Sacramento [50]是一个具有16个参数的以每天的时间步长执行的集总式流域水平衡模型,产流可分为直接径流、地表径流、土壤流、快速地下水和慢速地下水5部分。线性水库模拟介质流动、快速地下水和慢速地下水。SimHyd是一个具有7个参数的概念性降雨径流模型,其中包含拦截损失、土壤水分和地下水三个参数[51]。Sugawara等[52]开发了tank模型来解释集水区的水流现象。该模型简单,由4个垂直串联的水箱组成,降雨被倒入顶箱,蒸发量从顶箱向下减去。当每个水箱被排空时,蒸发间隙从下一个水箱开始,直到所有水箱都被排空。侧面出口的输出是计算出的径流[53]。上述4种经典的集总式水文模型在世界范围内已被成功应用于流域径流模拟和预测。
《3.4 评估指标》
3.4 评估指标
要评估不同(环境)模型的性能,请参考Bennett等[54]发表的文献。本研究选取Nash-Sutcliffe模型效率系数(NSE)、平均绝对误差(MAE)、均方根误差(RMSE)、相对误差(RE)、合格率(QR)和
(11)
(12)
(13)
(14)
(15)
(16)
式中,
《4、 结果和讨论》
4、 结果和讨论
《4.1 水文气象变量的趋势分析》
4.1 水文气象变量的趋势分析
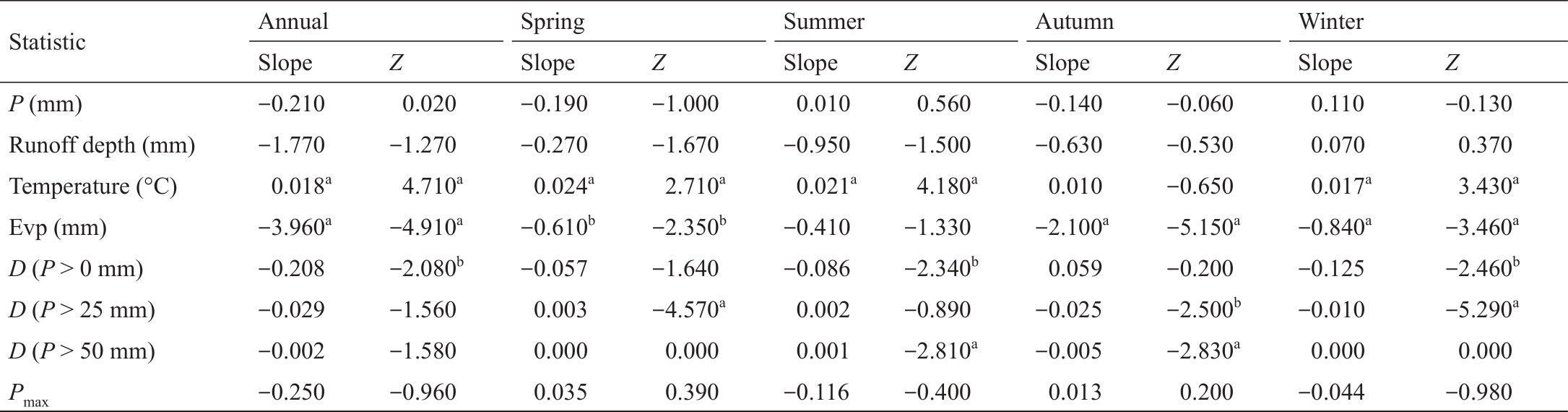
在探索研究区气象水文要素变化趋势时,采用Mann-Kendall方法和线性回归方法,在年和季节尺度上分析了1951—2016年降水量、径流深度、温度和水面蒸散发的变化。统计结果如表1所示。此外,图5展示了这些水文气象变量的年际变化。
《表1》
表1 1951年和2016年淮河流域上游水文气象变量年尺度和季尺度趋势分析统计资料
《图5》
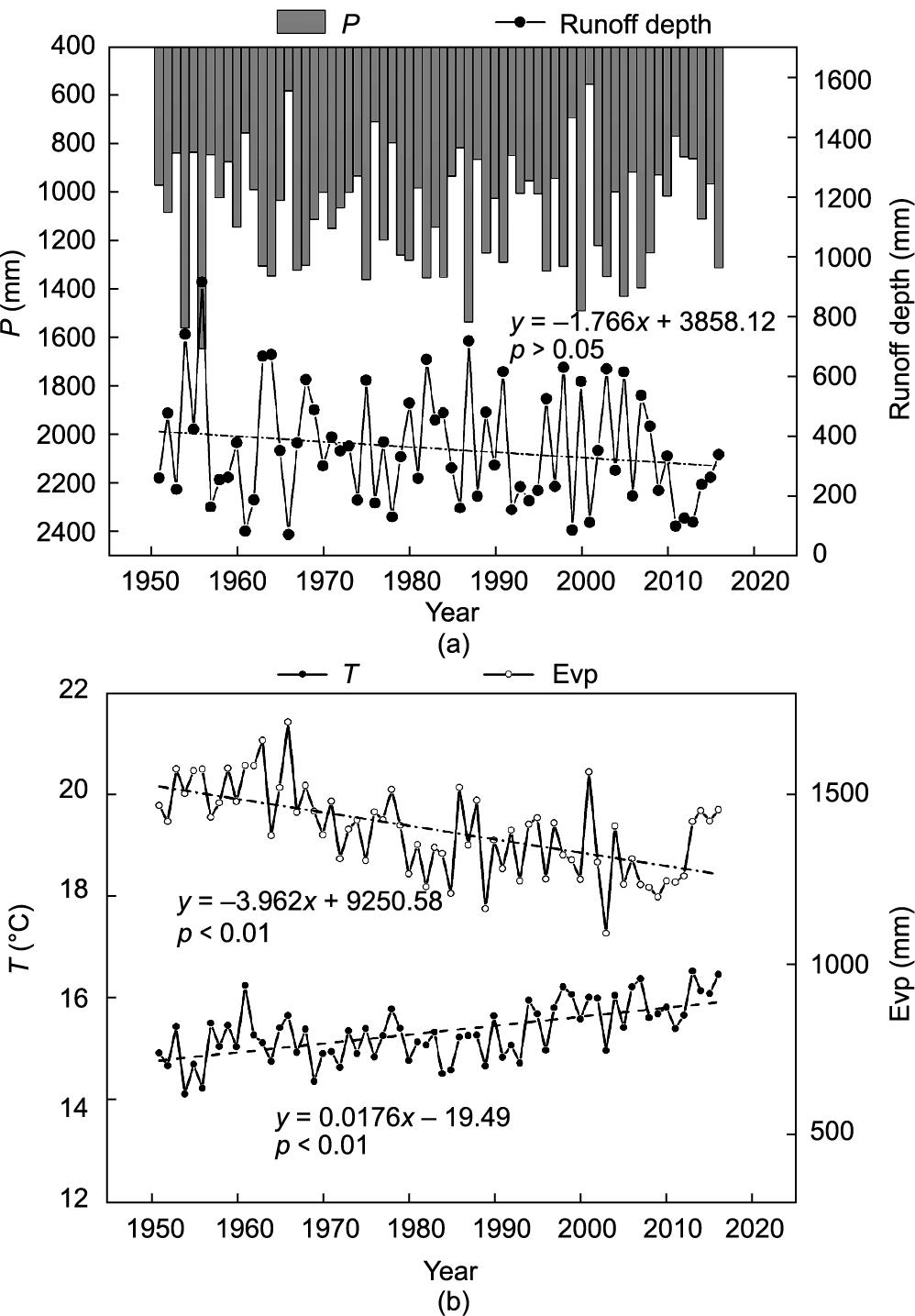
图5 中国淮河流域上游1951—2016年间水文气象变量的年际变化。(a)降水和径流深;(b)温度和水面蒸散发。
总体上可以看出,淮河流域上游地区降水和径流深度在年尺度上没有显著下降趋势。温度有明显的上升趋势(每10年上升0.18 ℃),相对低于1951—2018年中国平均温度上升速率(每10年上升0.24 ℃)[56]。图5(b)显示年水面蒸散发有显著下降趋势(3.96 mm·a-1),类似于Han等[57]的发现。淮河流域上游存在蒸发悖论,这可以归因于太阳辐射、相对湿度和风速的变化。
具体来看,与年降水量一致,春季和秋季降水量呈不显著下降趋势,而夏季和冬季降水量呈不显著上升趋势。除冬季径流深(增加不显著)外,季节径流深变化趋势与年尺度一致(减少不显著)。除秋季外,四季气温明显回升。水面蒸散发在季节尺度上的变化趋势与年尺度一致,但夏季下降趋势(0.41 mm·a-1)不显著。
此外,还研究了不同降水强度的天数(表1)。降雨天数(P > 0)在95%的置信水平上呈下降趋势,并且在季节尺度上保持一致,尤其是在夏季和冬季。降水量大于25 mm和50 mm的天数在年尺度和季节尺度上主要呈下降趋势。年最大降水量变化不大。因此,流域极端降水事件在气候变化背景下并未表现出明显变化。
总体而言,1951—2016年淮河流域上游地区气温明显升高,蒸发量显著减少,降水和径流稳定。尽管水文气象变量发生变化,但淮河上游水文状况总体保持稳定。
《4.2 淮河流域上游土地利用变化》
4.2 淮河流域上游土地利用变化
除了气候变化,土地利用变化是水文循环的另一个关键驱动因素。例如,土地利用变化可能通过改变下垫面的特征来影响径流的产生和形成过程。不同的土地变化模式(如造林、毁林、城市化)对径流产生不同的影响。为更好地了解土地利用对径流变化的影响,将淮河流域上游土地利用分为5类(水体、森林、居住区、农田和裸地),使用随机森林算法根据Landsat图像分析了1987年和2016年的土地利用状况。1987年和2016年土地利用分类结果见附录A中的图S1,1987—2016年土地利用变化转移矩阵见表2。
《表2》
表2 中国淮河流域上游1987年到2016年的土地利用变化转移矩阵(km)
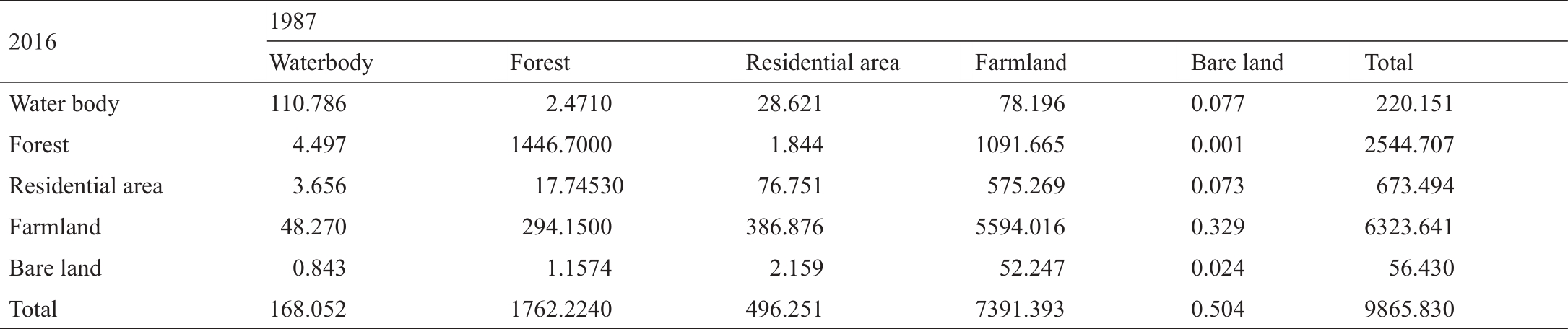
直观上看,附录A中的图S1显示耕地面积减少,而居住区和森林覆盖率明显扩大。从数量上看,以多种形式减少的耕地面积约1100 km2,主要转化为居住区和林地。居住区面积扩大了约180 km2,大量增加的不透水地表面积可能导致城市内涝。耕地面积减少和森林面积增加(约780 km2)与中国政府提出的“退耕还林”倡议相一致。该倡议旨在在发展经济的同时保护生态环境。由于森林在调节降雨和减少洪峰方面具有重要作用,因此森林面积的增加可能使更多的水用于涵养水源而导致洪水减少。
《4.3 基于增强型LSTM模型的径流预测》
4.3 基于增强型LSTM模型的径流预测
由于部分气象站1951—1959年降水数据缺失,本文选取1960—2016年作为研究时段用于验证增强型LSTM模型在淮河流域上游的径流预测。具体而言,1960年1月至2005年10月期间的数据用于训练,其余数据(2005年11月至2016年12月)用于测试。预测第d天的日径流时,输入数据为降水量(
《表3》
表3 不同径流预测模型的性能比较

《图6》
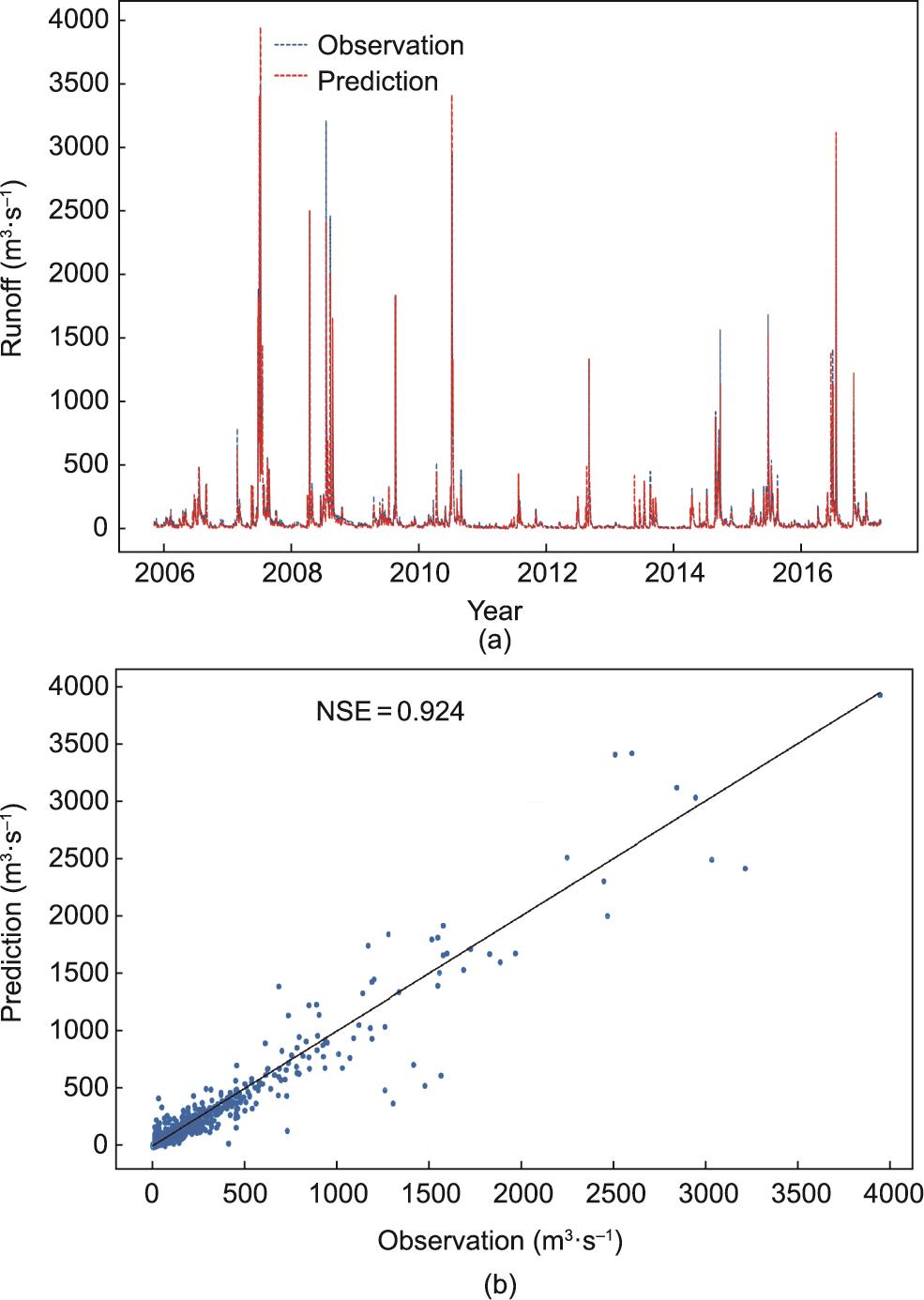
图6 中国淮河流域上游2005年11月至2016年12月期间基于以PET为损失函数的增强型LSTM模型的观测和预测径流。
为了进一步评估增强型LSTM模型对极端径流(洪水)预测的性能,本文计算了预测极端径流的QR和
《图7》

图7 中国淮河流域上游基于以PES为损失函数的增强型LSTM的峰值径流预测性能评估。
在评估不同气象站降水量对径流预测的贡献时,计算了提取的站点特征(图1中每个气象站的特征提取器的输出)与测试期间(2005年11月至2016年12月)预测径流之间的皮尔逊相关系数(PCC)。结果如表4所示,PCC越高,该特征对径流预测的影响越大。
《表4》
表4 提取的站点特征与具有不同损失函数的预测径流之间的PCC

表4表明,当模型的损失函数为MSE和PES时,提取的站点特征与预测径流呈负相关;相反,当使用PET作为损失函数时,它们呈现正相关关系。相关系数的绝对值是最关键的信息,代表了气象站提取的特征与预测径流之间的相关性。而正负符号由模型内部的参数训练过程决定,与整个模型协同工作,自动消除模型内部符号的影响。粗体数据表示相关性最强。可以看出,PES显著提高了站点特征与预测径流之间的相关系数,在57 285号站点的PCC最高为-0.672。此外,海拔高的气象站比靠近水文站的气象站对径流预测的贡献更大。例如,海拔第一和第二高的57390号和57285号站点的PCC比靠近水文站的站点更高。
《4.4 与所选对比模型的比较》
4.4 与所选对比模型的比较
不同模型的径流预测结果如表3所示。总体而言,数据驱动模型在日径流预测任务上优于集总式水文模型。在数据驱动模型中,增强型LSTM模型取得了比SVR、ANN和GRU等对比模型更好的结果。GRU虽然结构更简单,训练效率更高,但整体性能略低于增强型LSTM。在洪水预报结果中,它们的性能差异更加明显,这表明增强型LSTM模型结构和两个损失函数(PET和PES)提高了模型预测径流和洪水的能力。具体而言,以PET作为损失函数的增强型LSTM 模型取得了最高的NSE(0.924)。然而,对于洪峰预测,使用PES的增强型LSTM模型表现最好,QR为92.3%,洪水期间的NSE(
在训练过程中,需要首先对数据进行归一化,故MSE通常介于0和1之间。因而PET损失函数在快速上升阶段不存在输出饱和问题,但上升速率逐渐减小。一种可能的解释是PET从整体上放大了MSE,MSE越大,PET越大(MSE在0~1范围内)。因此,模型在优化参数时,是整体优化的,所以径流的整体预测结果较好。而当横轴在0和1之间时,PES近似线性,但事实并非如此。PES降低了MSE,但PES的一阶导数逐渐增加并趋近于一个常数值。因此,当MSE接近于0时,PES的上升速度较慢,而当MSE接近1时,PES的上升速度较快。一阶导数的单调递增可能是PES对改善具有更大误差的洪水流量有更好的效果的原因。
淮河上游洪水集中在6—8月份,且多由暴雨引发,给中下游带来巨大的防洪压力。为保护大部分社会财产和人民群众生命安全,淮河中下游已运行部分以农业和工业为主的蓄洪区,并在上游修建了多座水库。增强型LSTM可以及时准确地预测洪峰到达时间和流量,对水库和蓄洪区的运行具有重要意义。另外,水库对径流也有很大的影响。因此,部分预测误差可能是由水库引起的,未来的工作可以考虑引入水库对径流预测的影响。
《5、 结论》
5、 结论
为了提高径流预测的准确性,本研究提出了一种增强型LSTM模型。在原始LSTM模型的基础上,设计了一个特征提取器用于提取具有判别力的特征,并引入了两种用于洪峰预测的新型损失函数(PET和PES)。以淮河流域上游为研究对象,应用增强型LSTM模型评估1960—2016年日径流预测结果。
研究时段内,淮河流域上游气候温暖干燥,水文状况相对稳定。土地利用在1987年至2016年间发生了变化,主要从耕地变为森林和居住区。结果表明,增强型LSTM在日径流预测时表现良好(达到0.924的最高NSE),优于对比模型(即SVR、ANN、GRU、AWBM、Sacramento、SimHyd和Tank Model)。在洪峰预测方面,以PES为损失函数的增强型LSTM模型表现最好,QR为92.3%,洪水期间的NSE(











 京公网安备 11010502051620号
京公网安备 11010502051620号




