

《1、 引言》
1、 引言
随着工业4.0的不断深化与推进,现代制造业正在从传统操作模式向智能模式转变[1],在此过程中各种先进制造模式和技术不断涌现[2‒4]。作为智能制造的关键推动者,工业互联网平台旨在实现面向服务的按需生产[5‒6]。工业互联网平台是物联网技术[7‒8]和云计算技术[9‒10]在工业领域的进一步延伸和实现,引起了学术界和工业界的广泛关注[11‒13]。在工业互联网平台的支持下,孤立的制造资源得以互相连接,各种制造资源被封装成可交付给客户的制造服务以完成不同的制造任务,从而实现分布式制造资源的统一管理与利用[14]。一个制造任务通常需要多个制造服务的协作完成[15],在工业互联网平台收到制造任务后,将该任务分解为多个可执行的子任务,并将每个子任务与一组候选服务进行匹配。制造服务协作方案是指每个候选服务集合中所选服务构成的服务组合。因此,工业互联网平台的主要功能之一是对制造服务进行编排以生成高质量的服务协作方案,即制造服务协作优化。
在服务协作优化过程中,必须同时满足客户提出的功能需求和制造数量需求,例如,提交给工业互联网平台的任务所需的产品数量通常不仅只有一个。为了提高协作解决方案的整体性能,同时选择多个服务并行完成一个子任务是合理且可行的。通过此种方式,制造服务能够得以充分利用,同时服务的协作方案的效率可以显著提高。此时,服务协作同时存在于两个维度:在纵向维度上,具有相似功能的服务集群并行完成一个子任务;在横向维度上,具有互补功能的多个服务集群依次完成整个任务,构成了一个复杂的协作网络。针对这种网络的服务协作优化不只包括服务的优化选择,同时也需对制造数量进行分配,即如何将一个子任务的制造数量合理分配给多个选定的制造服务。一个制造任务可能有数千种备选服务组合,同时在一个服务组合中,会有更多潜在的制造数量分配方案。因此,进行服务协作优化时,需同时考虑服务选择以及数量分配以生成高质量的服务协作方案。
为了服务在两个维度上的有效协作,合理的制造服务建模方法至关重要。在现有的服务协作优化研究中,一般假定服务调用时间和成本是固定的而不考虑要处理的具体数量[16‒17]。然而当涉及数量分配时,此种假定便违反了按需原则。此外,由于子任务由多个服务协作完成,因此子任务的数量分配方案在很大程度上依赖于服务的可用性。从整个工业互联网平台的角度来看,制造服务存在于企业内部和企业间层面,导致不同的粒度[18]。例如,一个制造服务可以对应于单个资源(如机床)、一组资源(如车间中的工作站),同时也可以是集团企业涉及不同下属公司的复杂生产过程。服务的可用性受其组件状态和构成关系的影响而随时间不断变化,在服务协作优化过程中必须对此进行考虑,否则难以保证协作解决方案的可行性和效率。
为了生成高质量的协作解决方案,本文提出了一种新的双维度制造服务协作优化(DMSCO)方法。所提出的方法考虑了制造服务的多粒度特征,同时包括横向维度的功能协作和纵向维度的数量协作。本文的主要贡献如下:
(1)通过分析制造服务的组件和结构,提出了一种多粒度服务建模方法,该方法能够将复杂服务(即复合服务和服务链)引入服务协作优化中。
(2)在考虑服务粒度的情况下,建立了同时考虑服务选择和数量分配的DMSCO集成优化模型,以总体服务协作解决方案的成本、可靠性和完成时间为优化目标。
(3)提出了一种多目标模因算法从而对集成优化模型进行求解,并在算法中嵌入竞争机制,根据局部搜索算子的贡献动态调整其选择概率。
本文的后续部分组织如下:第2节对相关工作进行回顾,第3节提出一种多粒度制造服务建模方法并建立DMSCO集成优化模型,第4节设计模型求解算法,第5节进行仿真实验,第6节给出相关结论。
《2、 相关工作》
2、 相关工作
《2.1 制造服务建模》
2.1 制造服务建模
作为制造服务协作的先决条件,物理资源虚拟化和制造服务建模得到了广泛的研究。研究人员最初专注于服务功能性和非功能性信息描述。Shi等[19]提出了一种制造资源层次模型,其中使用可扩展标记语言将从物理资源层提取的资源信息封装在资源表示层中,并在资源接口层中描述针对资源的操作以屏蔽资源的内部信息通信细节。Vichare等[20]针对由机器资源和辅助资源组成计算机数控(CNC)加工系统建立了统一的制造资源模型,该模型是一种标准的信息表示,能够定义CNC加工系统的各种元素并支持自动化工艺规划决策。Ameri和McArthur [21]通过属性推理规则和分类规则扩展了服务描述语言,从而增强其语义并实现了高级推理。Wang和采用Function block将物理资源的能力转化为制造服务,从而提供了一种可行的集成方法,能够以可互操作和灵活的方式协调各种制造资源。
事实上,制造服务通常存在多种粒度[18],随着研究的推进,多粒度制造服务的构建引起了研究人员的关注。不同粒度的服务共存使得服务协作方案更加高效和灵活。粗粒度服务可以作为一个整体被调用,进而快速满足任务的大部分需求[23‒24]。同时,细粒度服务可以灵活地满足其他个性化需求。Liu等[25]提出了由资源聚合功能和资源聚类算法组成的多粒度资源虚拟化方法,将物理资源封装到云服务中,以此衔接复杂制造任务和底层资源。Yu等[26]设计了一种基于数据挖掘技术的多级聚合服务规划方法,从而确定了在不同粒度下维护的制造服务的数量。Zhang等[27]提出了一种新的应用模式,即行业联盟的云制造,为此设计了多粒度制造服务的领域驱动开发方法,包括原子服务和粗粒度服务开发两个阶段,以实现按需提供制造资源。Li等[28]提出了一种基于资源服务之间依赖关系的资源服务链组合进化算法,以构建最优的粗粒度服务,从而提高制造服务的可重用性和选择效率。
《2.2 制造服务协作优化》
2.2 制造服务协作优化
现有的制造服务协作优化研究主要集中在优化服务选择和配置上。到目前为止,已经提出了大量的模型。Lu和Xu [29]研究了云制造环境中基于知识的服务组合和自适应资源规划方法,通过基于语义的系统促进了给定服务请求的快速资源分配。Ren等[30]提出了一种考虑制造业服务社会关系的服务选择模型,以最大化整体协同效应,从服务交互数据中抽取了5类的服务社会关系,并基于关系强度的加权聚合建立了服务协同效应模型。在考虑服务协作中的物流服务,Zhou等[31]分析并建立了物流和加工服务的协作优化模型,并将平均任务交付时间作为优化目标。Wu等[32]提出了一个多目标规划模型以同时优化协作解决方案的可持续性(经济、环境和社会绩效)和质量。Wang等[33]建立了一个多目标动态服务组合重构模型,其中根据真实的云制造过程引入了8个关键的实际约束,从而缩小了理论和应用之间的差距。
由于最优服务选择的是NP-hard问题[34],智能进化算法被广泛用于该问题的求解,可以以较少的计算资源获得模型的高质量解决方案[35]。Bouzary和Chen [36]设计了一种混合遗传算法进化算子的灰狼优化算法,通过提供更多的探索强度来避免狩猎过程中的局部最优停滞。Akbaripour和Houshmand [37]对算法搜索空间进行分析,证明了局部最优值聚集在搜索空间的一小部分,并据此设计了一种将帝国主义竞争算法与局部搜索算法相结合的混合方法。Zhang等[38]提出了一种新的基于遗传的超启发式算法,其中遗传算法充当高层启发式方法,以产生直接在搜索空间执行搜索的低层启发式方法的适当组合,进而解决不确定环境中面向多任务的最优服务选择问题。Zhou和Yao [39]提出了一种多目标混合人工蜂群算法,以优化服务质量和能耗。其中引入了带Lévy飞行的布谷鸟搜索,以保持解决方案的多样性,并设计了一种全面的学习策略,以确保算法的开发和探索之间的平衡。Zhang等[40]提出了一种改进的非支配排序遗传算法II(NSGA-II),结合Tabu搜索和增强的K-means机制,以优化参与服务协作的提供商、消费者和算子的长期/短期效用。
迄今为止,对双维度服务协作的探索仍然有限。一些相关研究同样仅关注于其中的服务选择问题[41‒42]。然而,当多个服务并行完成同一子任务时,将制造数量分配给所选服务对于制造服务协作优化是不可或缺的。Zhu等[43]针对数量分配进行研究但忽略了服务选择阶段,他们还将制造数量分配给所有候选服务。尽管缩短了完成时间,但由于涉及大量服务,协作解决方案的执行变得困难。此外,在先前的参考文献中,制造服务的可用性被假定为数值。尽管这样的解决方案可能适用于计算机科学领域,但制造业的情况更复杂。制造服务的可用性受到许多因素的影响,如服务结构、内部组件服务和已经占用的时间。因此,单个数值不能准确反映制造服务的可用性。
《2.3 概述》
2.3 概述
如上所述,制造服务建模和协作优化都得到了广泛的研究。但对服务协作优化的研究很少考虑服务粒度的特征,导致服务建模和协作优化之间的不一致。尽管在这方面做了一些努力[44‒45],但仍缺少对不同粒度服务可用性的详细描述。此外,现有的服务协作优化研究主要集中于选择满足功能需求的服务,而忽略了与数量相关的协作,需要进一步研究双维度服务协作的优化模型和具体算法。为此,本文提出了一种基于多粒度服务的服务选择和数量分配DMSCO方法。
《3、 问题制定》
3、 问题制定
《3.1 多粒度制造服务建模》
3.1 多粒度制造服务建模
在协作解决方案的总体性能中,总成本、可靠性和完成时间是客户最关心的问题,分别对应于服务的单位成本、可靠性以及处理速度。此外,解决方案的可行性受到服务可用性的限制。在建模制造服务时,本文主要关注这些属性。其中,服务的可用性是从时间的角度来构建的,即服务是否在特定时间段内可用。制造服务既存在于企业内部层面,也存在于企业间层面。根据其内部组件和结构,可以在三个粒度上对服务进行建模:资源服务、复合服务和服务链。表1列出了用于建模这些服务的符号,表2显示了服务表达式和属性。
《表1》
表1 用于多粒度制造服务建模的符号
| Notation | Description |
|---|---|
| Manufacturing service; referring to a resource service, a composite service, or a service chain | |
| Indexes of component services in a composite service or a service chain, where |
|
| Index of available durations of a resource service or a composite service, where |
|
| Unit cost, reliability, processing speed, and availability of |
|
| Set of component services in a composite service or service chain | |
| Set of execution constraints in a service chain | |
| Unit cost, reliability, processing speed, and availability of |
《表2》
表2 多粒度制造服务的建模
| Service granularity | Expression | Unit cost | Reliability | Processing speed | Availability |
|---|---|---|---|---|---|
| Resource service | |||||
| Composite service | |||||
| Service chain |
资源服务是由企业内的单个物理资源映射的简单服务。由于资源不能一直可用,因此服务的可用性表示为一系列可用的时间段,其中元素
复合服务包括多个相互依赖的资源服务,通常由单个企业提供。当向外部提供功能时,同时调用内部的组件服务V= {S1, S2, …,
服务链是由多个相关企业(如企业集团或联盟)提供的固定服务。它由一组组件(即资源或复合)服务V = {S1, S2, …,
《3.2 DMSCO模型》
3.2 DMSCO模型
在DMSCO模型中,制造任务T包含具有不同功能需求的I个子任务,每个子任务ST
《表3》
表3 DMSCO模型使用的符号
| Notation | Description |
|---|---|
| Index of subtasks, where |
|
| Index of manufacturing services in CS |
|
| Manufacturing task | |
| Amt | Total required amount of |
| CS | Manufacturing service collaboration solution for |
| Total cost, reliability, and finishing time, respectively, of CS to fulfill |
|
| ST |
|
| Amt |
Total required amount of ST |
| CSS |
Set of candidate manufacturing services for ST |
| CS |
Cluster of manufacturing services selected from CSS |
| Total cost, reliability, beginning time, and finishing time, respectively, of CS |
|
| Amt |
Processing amount distributed to |
| Unit cost, reliability, processing speed, and availability of |
|
| Total cost, reliability, beginning time, and finishing time, respectively, of |
|
| Binary variable equal to 1 if Amt |
|
| Set of component services in a service chain |
|
| Set of execution constraints in a service chain |
|
| Processing speed and availability of |
|
| Beginning time and finishing time, respectively, of |
|
| Binary variable equal to 1 if Amt |
|
| Maximum total cost, reliability, and finishing time, respectively, of CS | |
| Minimum total cost, reliability, and finishing time, respectively, of CS |
《3.2.1. 纵向维度的协作》
3.2.1. 纵向维度的协作
考虑数量分配,首先制定了单个
(1)
(2)
(3)
(4)
(5)
其中,公式(5)表示Amt
对于服务链,
(6)
(7)
(8)
(9)
(10)
(11)
其中,公式(10)和公式(11)分别确保组件服务的可用性和正确的调用顺序。
对于服务集群CS
(12)
(13)
(14)
(15)
(16)
(17)
其中,公式(16)保证分配给CS
《3.2.2. 横向维度的协作》
3.2.2. 横向维度的协作
关于横向维度,服务协作解决方案CS的总成本C、可靠性R和完成时间F公式如下:
(18)
(19)
(20)
(21)
由于C、R和F的测量方法和单位不同,目标函数标准化如下,以同时优化度量:
(22)
(23)
(24)
《4、 提出的DMSCO模因算法》
4、 提出的DMSCO模因算法
服务选择已被证明是一个NP-hard问题[34]。因此,同时进行服务选择和数量分配的DMSCO同样是NP-hard问题。为了解决这个问题,开发了一种基于竞争的多目标模因算法(CMOMA)。
《4.1 CMOMA框架》
4.1 CMOMA框架
模因算法代表了一类元启发式算法,该算法将进化算法与局部搜索相结合[46]。所提出的CMOMA框架如图1所示,其中灰狼优化算法用于全局搜索,基于竞争的变邻域搜索算法用于局部搜索。为了适应DMSCO,设计了一种用于全局搜索的混合交叉算子。此外,为了充分探索搜索空间,通过快速非支配排序来更新种群并从种群中随机选择每个解的父体(领导者)进行交叉。
《图1》
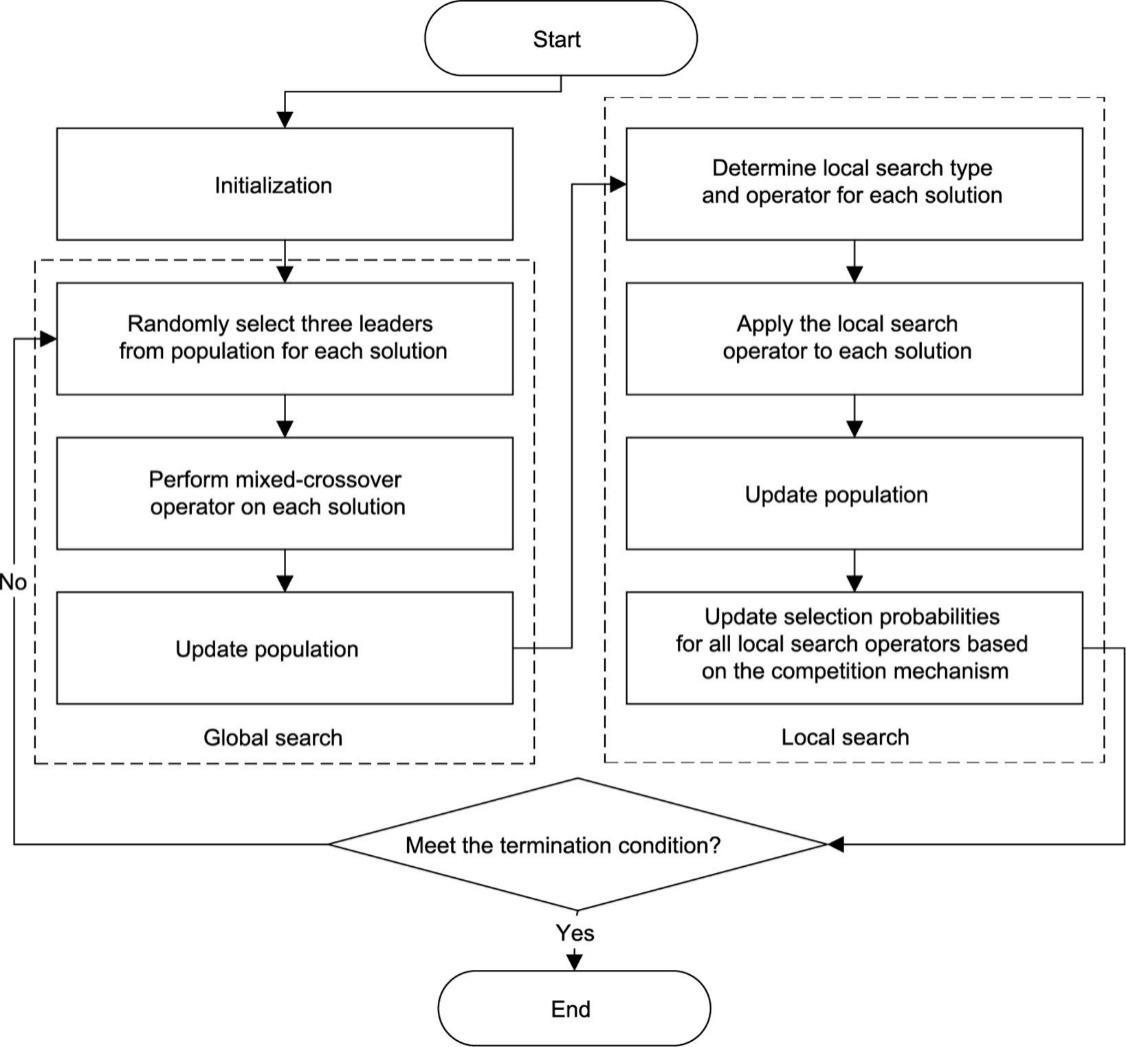
图1 CMOMA框架。
局部搜索在模因算法中具有重要意义,针对具体问题进行定制。本文开发了两类与服务选择和数量分配相对应的局部搜索算子,每类包括4个算子。进行局部搜索时,选择其中一个算子执行。此外,还设计了一种竞争机制来更新算子的选择概率。
《4.2 编码和解码》
4.2 编码和解码
为了适应DMSCO,提出了一种双向量编码方案,该方案涉及服务选择向量和数量分配向量。每个向量由对应于I个子任务的I个片段组成。由于子任务ST
《图2》
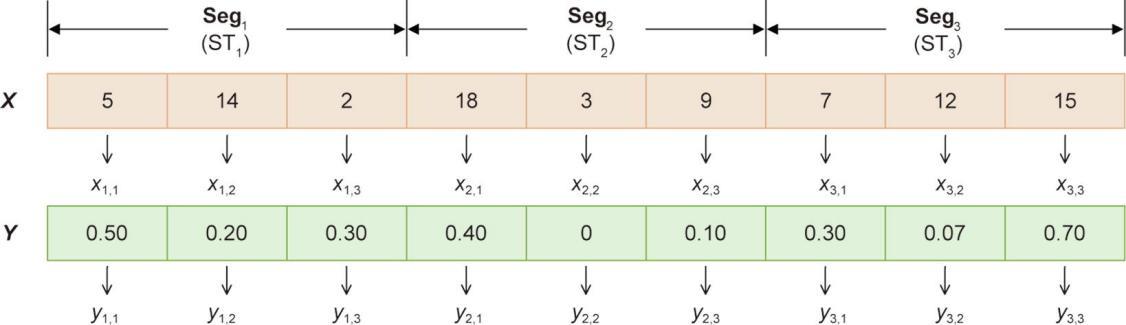
图2 编码方案示例。
在解码之前,检查的元素。如果
(25)
《图3》
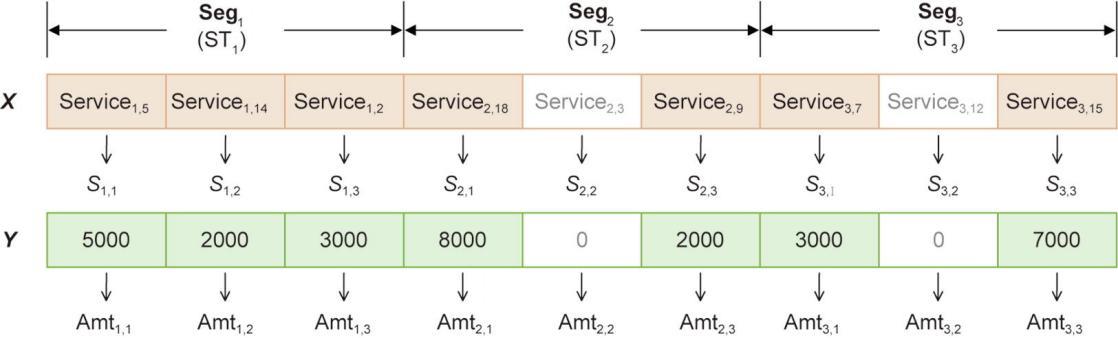
图3 解码方案示例。
《4.3 全局搜索》
4.3 全局搜索
全局搜索算法是从灰狼优化算法扩展而来的,灰狼优化算法是受灰狼狩猎行为启发的新兴进化算法[47]。在灰狼优化算法的每次迭代中,每个解在前三个最佳解α、β和δ的指导下更新其位置。与类似算法相比,优化器的特点是搜索速度快,易于实现。该算法最初是为解决连续优化问题而设计的。由于解中同时存在离散变量和连续变量,因此在所提出的算法中设计了混合交叉算子。对于,交叉算子表示为公式(26)和公式(27),其中rand()是返回[0, 1]中随机数的函数,
(26)
(27)
《图4》
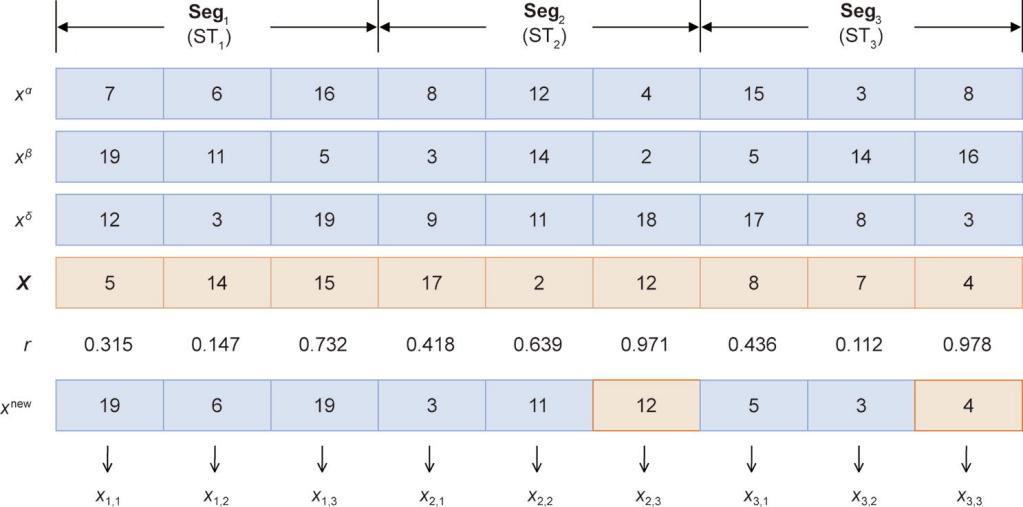
图4 X的交叉算子示例。
对于,采用灰狼优化算法中的原始交叉算子,如公式(28)~(31)所示,其中a在迭代期间从2线性减少到0,并且
(28)
(29)
(30)
(31)
关于多目标优化,大多数研究在灰狼优化算法中引入外部档案,以保存迄今为止获得的非支配解集,并利用轮盘赌方法从外部档案中选择执行交叉的父解。然而,由于外部档案只保留了非支配解集,可能会导致算法陷入局部最优。因此,本文采用快速非支配排序来更新种群。在选择父解时,种群中的所有解具有相同的被选概率。这样,不在非支配解集中的解有机会被选择,有利于跳出局部最优,充分探索搜索空间。有关快速非支配排序的详细信息,可参见参考文献[48]。
《4.4 基于竞争的变量邻域搜索》
4.4 基于竞争的变量邻域搜索
通过基于竞争的可变邻域搜索算法来执行局部搜索。设计两种类型的局部搜索算子分别用于服务选择和数量分配,每种类型包含4个算子。当对解执行局部搜索时,首先随机确定局部搜索类型,然后根据由竞争机制更新的概率从该类型中选择某一搜索算子。
《4.4.1. 局部搜索服务选择》
4.4.1. 局部搜索服务选择
由于高质量服务可以显著改善协作解决方案,因此局部搜索服务选择旨在用高质量服务替代低质量服务。这种类型包括三个面向目标的算子OS1、OS2和OS3,以及一个混合算子OS4。每个面向目标的算子对应于一个要优化的目标,并对解决方案中的所有片段执行相同的相应操作。混合算子对解中的每个片段随机执行针对不同目标的相应操作,致力于保持平衡。每个算子详情如下:
(1)总成本f1的OS1:对于X中的每个Seg
(2)可靠性f2的OS2:对于X中的每个Seg
(3)结束时间f3的OS3:对于X中的每个Seg
(4)OS4用于所有目标:对于X中的每个Seg
《4.4.2. 局部搜索数量分配》
4.4.2. 局部搜索数量分配
关于总成本和可靠性,如果将所选服务中相对低质量的服务分配给较少的子任务制造数量,则协作解决方案将更好。关于完成时间,按照为子任务所选服务的速度成比例的方式分配制造数量。相应地,设计了一个用于数量分配的局部搜索,包括三个面向目标的算子OA1、OA2和OA3,以及一个混合算子OA4。算子详情如下:
(1)总成本f1的OA1:对于Y中的每个Seg
(32)
(2)可靠性f2的OA2:对于Y中的每个Seg
(3)结束时间f3的OA3:对于Y中的每个Seg
(33)
(4)所有目标的OA4:对于Y中的每个Seg
《4.4.3. 竞争机制》
4.4.3. 竞争机制
随着算法的迭代执行,不同目标的优化进度通常不同。因此开发一种竞争机制,将更多的计算资源分配给具有更多改进空间的目标。在该机制中,具有相同类型的算子相互竞争以获得更高的选择概率。根据算子对解的影响更新概率。如果一个算子改进了一个解决方案,它将被激励获得更高的概率;否则将被抑制。
为了量化当前迭代中算子的影响,在局部搜索之后更新种群,并识别和分类应用了局部搜索算子的解决方案。以服务选择的局部搜索为例,OS
(34)
(35)
在上述公式中,如果OS
(36)
(37)
(38)
《5、 仿真实验》
5、 仿真实验
通过仿真实验对所提CMOMA的性能进行评估,每个解均同时确定服务选择方案和所选服务的数量分配方案。实验中所涉及的算法采用Java(JDK 14)实现,运行环境为Windows 10(64)、32 GB RAM、2.2 GHz Intel Core i7-8750H。同时为了提高运行效率,所有算法均以并行方式进行解码。
《5.1 性能指标和测试案例》
5.1 性能指标和测试案例
本文采用世代距离(GD)、反向世代距离(IGD)、超体积(HV)和解集覆盖率(SC)作为算法的性能评价指标。
(1)GD为收敛性指标,其计算方式如公式(39)所示。GD越小,表示算法收敛性越好。
(39)
(2)IGD为综合性指标,用于同时评价解集的收敛性和多样性,其计算方式如公式(40)所示。IGD越小,表示解集的综合表现越好。
(40)
(3)HV为目标空间中的解集所覆盖的范围,其计算方式如公式(41)所示。HV越大,表示解集越优。
(41)
(4)SC用于测量两个非支配解集U和V之间的支配关系,可对解集的量进行比较,其计算方式如公式(42)所示。当C(U, V)大于C(V, U)时,表示解集U质量更好。
(42)
实验基于文献[40]中采用的原则生成测试实例,即具有较高可靠性或较快处理速度的制造服务的单位成本较高,反之亦然。如表4所示,生成了21个实例用于评估算法性能,其中子任务的数量有三种:15、30和45。在每种规模中,使用复杂服务(即复合服务和服务链)的子任务的比例从20%增加到80%,增长间隔为10%。资源服务的可用时间(包括复杂服务中的组件资源服务)随机生成。本文中每个子任务有50个候选服务,最多可以选择三个服务。
《表4》
表4 测试实例中不同服务的比例
| Test instance | Number of subtasks | Test instance | Number of subtasks | Test instance | Number of subtasks | Proportion | ||
|---|---|---|---|---|---|---|---|---|
| Service chain | Composite service | Resource service | ||||||
| 1 | 15 | 8 | 30 | 15 | 45 | 10% | 10% | 80% |
| 2 | 9 | 16 | 15% | 15% | 70% | |||
| 3 | 10 | 17 | 20% | 20% | 60% | |||
| 4 | 11 | 18 | 25% | 25% | 50% | |||
| 5 | 12 | 19 | 30% | 30% | 40% | |||
| 6 | 13 | 20 | 35% | 35% | 30% | |||
| 7 | 14 | 21 | 40% | 40% | 20% | |||
《5.2 协调系数的敏感性分析》
5.2 协调系数的敏感性分析
为了更新局部搜索算子的选择概率,竞争机制中的参数η是CMOMA中需要调整的唯一参数,并影响算法的性能。理论上,当更新选择概率时,较大的η值会导致算法集中关注对定向目标的影响。相比之下,较小的η值会使算法注意到对其他目标的影响。
为了研究η对CMOMA的影响并选择合适的η值,进行了一组实验。首先,测试了0.4、0.6、0.8和1.0四个值,以大致确定η的合理范围。在每个值上,CMOMA在中型实例11上独立执行20次,每次执行的运行时间为15 s。初步实验后,种群规模设置为200。图5显示了具有标准偏差的IGD的平均值。帕累托最优前沿由在所有η值下运行CMOMA获得的非支配解组成。如图5所示,η < 0.8是CMOMA的理想范围,其中算法保持了较好的性能,即当更新选择概率时,考虑对定向目标的更多影响有利于算法的性能。为了细化η,在[0.8, 1.0]中进行了进一步的测试,步长为0.02。图6描述了具有95%置信区间的HV均值。尽管差异不明显,但相比之下,[0.9, 1.0]中的η比[0.8, 0.9]中η具有优势。然而,随着η的增加,算法的性能会逐步降低。特别在η = 1点,即不包括其他目标影响的情况下,可以观察到明显的性能下降。这一现象表明,定向目标和其他目标的影响是至关重要的,需要在这两个方面之间取得平衡。在测试值中,当η = 0.9时,CMOMA达到较高的HV平均值,置信区间较窄。因此,η被设置为0.9以均衡不同目标的影响。此外,从全局角度来看,HV的轨迹显示出轻微的波动,但当η > 0.8时通常保持稳定,说明η在适当范围内是不敏感的,这也同时验证了CMOMA的鲁棒性。
《图5》
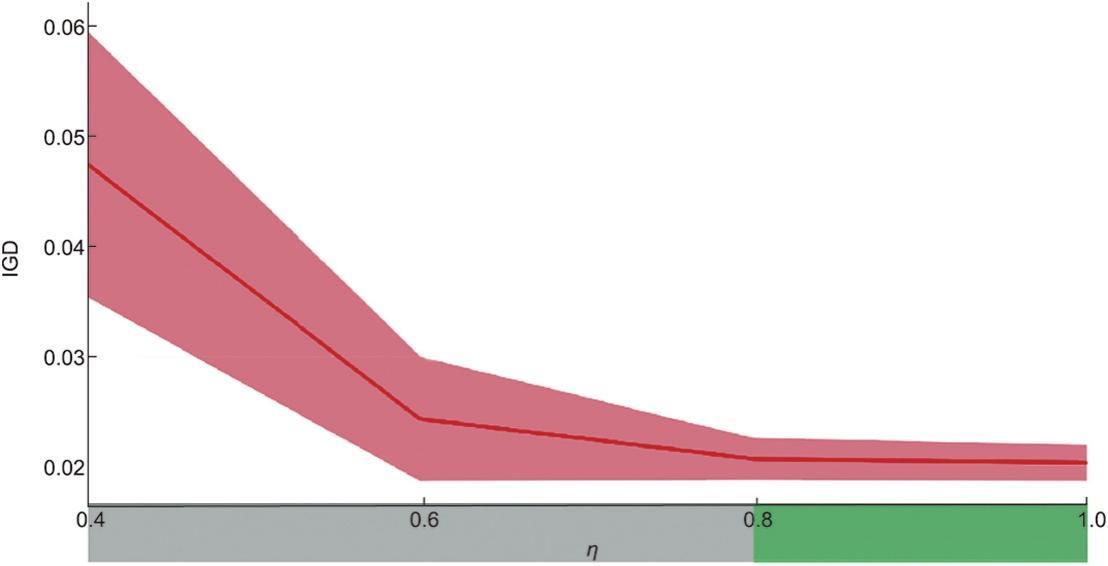
图5 实例11上具有不同η值的标准偏差的IGD平均值。
《图6》
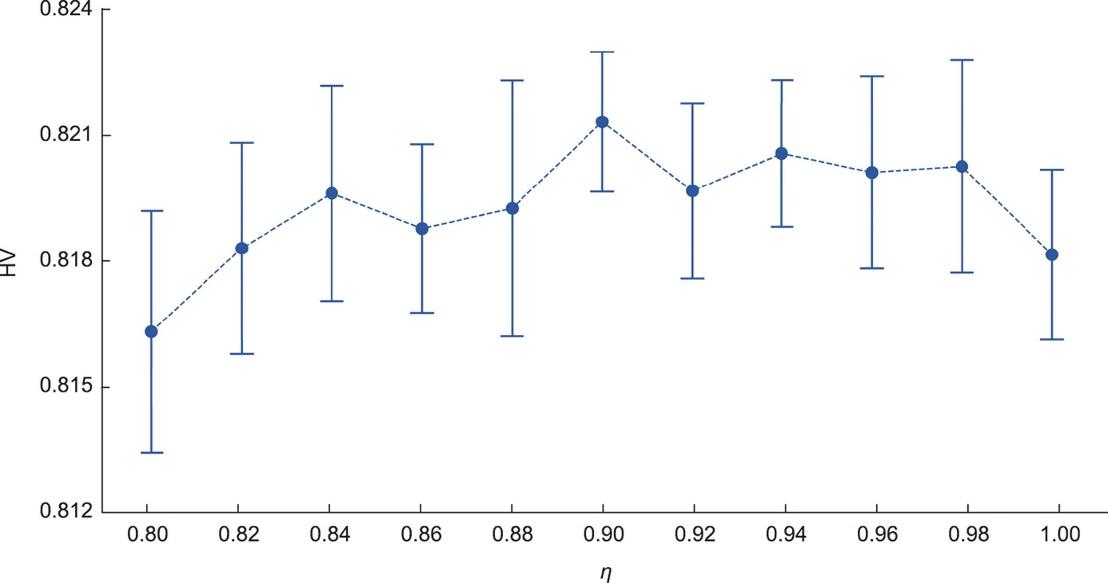
图6 实例11上不同η值下具有95%置信区间的HV均值。
《5.3 竞争机制的绩效验证》
5.3 竞争机制的绩效验证
为了验证竞争机制的有效性,开发了一种CMOMA变体,即固定概率多目标模因算法(FMOMA)用于比较。该变体去除了竞争机制,并采用固定的等概率来选择局部搜索算子。两种算法在每个实例上重复20次,每次重复的运行时间相同(小、中、大型实例分别为10 s、15 s和20 s)。表5显示了GD、IGD和HV的平均值。为了计算IGD,同时采用三个先进的多目标算法的结果,即NSGA-II [48]、SPEA-2 [49]和多目标灰狼优化算法(MOGWO)[50](在下一章中具体讨论)结果以构建帕累托最优前沿。对每个案例进行0.05显著性水平的独立双样本t检验。下面分别使用符号“+”“=”“-”表示CMOMA的结果在统计上优于、类似或低于FMOMA。很明显,CMOMA在所有实例上都获得最佳GD值。从统计角度也证实了这一优势,证明了CMOMA的较好收敛性。对于IGD,CMOMA在20个实例上获得最佳值,其中15个实例的结果显著优于FMOMA。就HV而言,尽管在统计意义上两种算法在7个实例上的结果相似,CMOMA总是比FMOMA产生更好的结果。总之,CMOMA在综合指标方面优于FMOMA。
《表5》
表5 所有测试实例中CMOMA和FMOMA的GD、IGD和HV的均值和两样本检验结果
| Test instance | GD | IGD | HV | |||
|---|---|---|---|---|---|---|
| CMOMA | FMOMA | CMOMA | FMOMA | CMOMA | FMOMA | |
| 1 | 1.1402 × 10-3 | 1.3180 × 10-3+ | 2.3340 × 10-2 | 2.3355 × 10-2= | 7.9977 × 10-1 | 7.9802 × 10-1= |
| 2 | 8.9269 × 10-4 | 1.0554 × 10-3+ | 2.1670 × 10-2 | 2.2390 × 10-2+ | 8.2696 × 10-1 | 8.2328 × 10-1+ |
| 3 | 9.2624 × 10-4 | 1.1366 × 10-3+ | 2.0485 × 10-2 | 2.1510 × 10-2+ | 8.1010 × 10-1 | 8.0836 × 10-1= |
| 4 | 1.0683 × 10-3 | 1.3717 × 10-3+ | 1.9490 × 10-2 | 2.1390 × 10-2+ | 8.5031 × 10-1 | 8.4925 × 10-1= |
| 5 | 9.0086 × 10-4 | 1.2245 × 10-3+ | 2.0115 × 10-2 | 2.1690 × 10-2+ | 8.5315 × 10-1 | 8.5117 × 10-1+ |
| 6 | 8.8471 × 10-4 | 1.1432 × 10-3+ | 1.7660 × 10-2 | 1.8415 × 10-2+ | 8.5614 × 10-1 | 8.5769 × 10-1= |
| 7 | 1.0415 × 10-3 | 1.4650 × 10-3+ | 1.7275 × 10-2 | 1.8140 × 10-2+ | 8.8252 × 10-1 | 8.8138 × 10-1= |
| 8 | 7.9311 × 10-4 | 1.0661 × 10-3+ | 1.9570 × 10-2 | 2.0410 × 10-2+ | 7.7647 × 10-1 | 7.7718 × 10-1= |
| 9 | 8.7197 × 10-4 | 1.0704 × 10-3+ | 1.9740 × 10-2 | 1.9670 × 10-2= | 8.0296 × 10-1 | 7.9883 × 10-1+ |
| 10 | 7.6937 × 10-4 | 1.0079 × 10-3+ | 1.9885 × 10-2 | 2.0125 × 10-2= | 8.1026 × 10-1 | 8.0704 × 10-1+ |
| 11 | 7.8789 × 10-4 | 1.0368 × 10-3+ | 2.0765 × 10-2 | 2.1170 × 10-2= | 8.2136 × 10-1 | 8.1340 × 10-1+ |
| 12 | 7.7134 × 10-4 | 1.0219 × 10-3+ | 1.7870 × 10-2 | 1.9090 × 10-2+ | 7.9085 × 10-1 | 7.8832 × 10-1= |
| 13 | 8.7732 × 10-4 | 1.0757 × 10-3+ | 1.8085 × 10-2 | 1.9780 × 10-2+ | 8.4326 × 10-1 | 8.3691 × 10-1+ |
| 14 | 7.9210 × 10-4 | 1.0462 × 10-3+ | 1.8105 × 10-2 | 1.9375 × 10-2+ | 8.3489 × 10-1 | 8.2903 × 10-1+ |
| 15 | 7.4785 × 10-4 | 1.0317 × 10-3+ | 1.9610 × 10-2 | 2.0175 × 10-2= | 7.6262 × 10-1 | 7.5633 × 10-1+ |
| 16 | 7.0934 × 10-4 | 1.0484 × 10-3+ | 1.8290 × 10-2 | 2.0220 × 10-2+ | 7.9199 × 10-1 | 7.8373 × 10-1+ |
| 17 | 6.9929 × 10-4 | 1.0574 × 10-3+ | 1.9605 × 10-2 | 2.0405 × 10-2= | 7.9177 × 10-1 | 7.8538 × 10-1+ |
| 18 | 7.0551 × 10-4 | 1.0221 × 10-3+ | 1.7440 × 10-2 | 1.8970 × 10-2+ | 8.0302 × 10-1 | 7.9714 × 10-1+ |
| 19 | 8.1797 × 10-4 | 1.0681 × 10-3+ | 1.8055 × 10-2 | 2.0265 × 10-2+ | 8.1730 × 10-1 | 8.0498 × 10-1+ |
| 20 | 8.2308 × 10-4 | 1.1589 × 10-3+ | 1.8810 × 10-2 | 2.0905 × 10-2+ | 8.0723 × 10-1 | 7.9788 × 10-1+ |
| 21 | 7.6813 × 10-4 | 1.1156 × 10-3+ | 1.8935 × 10-2 | 2.1415 × 10-2+ | 8.0504 × 10-1 | 7.9633 × 10-1+ |
为了评估质量,表6显示SC指标的结果。C(CMOMA, FMOMA)在所有情况下的均值明显大于C(FMOMA, CMOMA),表明CMOMA在搜索高质量解决方案方面的优势。为了更直观地表示,图7用线性回归趋势线描述了SC结果。随着实例大小的增加,CMOMA的优势变得明显。特别是,在大型实例中,FMOMA的解集中约有一半解被由CMOMA的解集中的解支配。在相同规模的实例内部中,观察到类似的结论。随着复杂服务比例的增加,CMOMA的优势得到了增强。这主要归因于竞争机制,使得算法能够为局部搜索算子找到合适的选择概率。综合以上所有分析,可验证CMOMA优于FMOMA,设计的竞争机制有助于提高性能。
《表6》
表6 CMOMA和FMOMA在所有测试实例上的SC均值比较
| Test instance | Test instance | ||||
|---|---|---|---|---|---|
| 1 | 27.75% | 17.95% | 12 | 37.35% | 11.25% |
| 2 | 28.55% | 14.43% | 13 | 42.05% | 11.63% |
| 3 | 31.23% | 13.70% | 14 | 41.00% | 12.83% |
| 4 | 31.38% | 16.03% | 15 | 36.05% | 9.75% |
| 5 | 34.40% | 13.25% | 16 | 43.93% | 8.58% |
| 6 | 30.20% | 14.65% | 17 | 44.25% | 6.35% |
| 7 | 28.88% | 16.58% | 18 | 44.05% | 8.65% |
| 8 | 32.78% | 10.33% | 19 | 41.53% | 10.78% |
| 9 | 33.00% | 11.00% | 20 | 50.03% | 8.10% |
| 10 | 33.38% | 11.70% | 21 | 53.33% | 8.18% |
| 11 | 41.13% | 9.33% |
《图7》
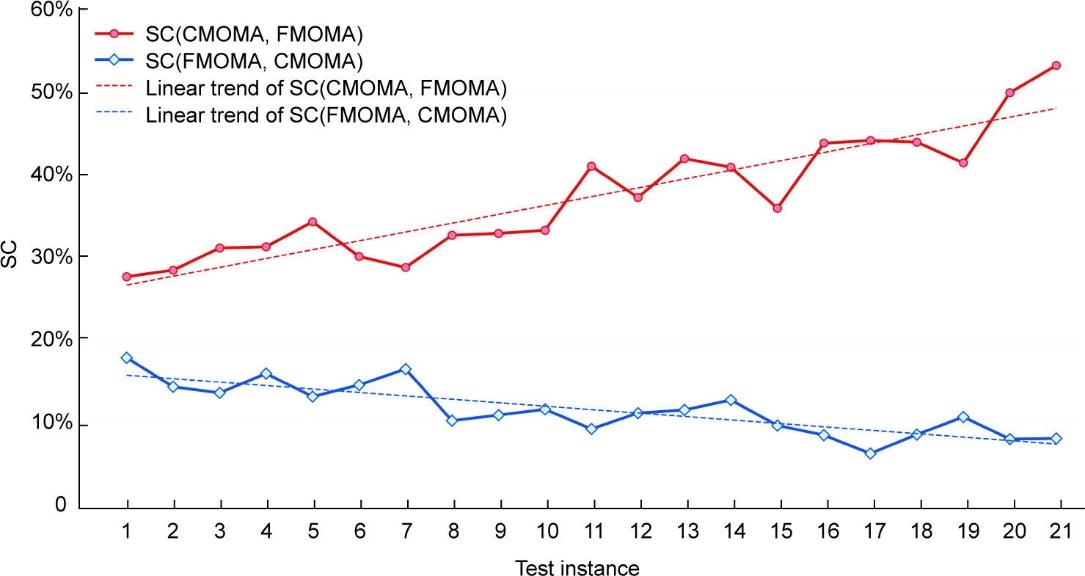
图7 CMOMA和FMOMA在所有测试实例上的SC结果。
《5.4 与其他算法的比较》
5.4 与其他算法的比较
为了进一步评估CMOMA的性能,将其与经典和新兴的多目标算法(即NSGA-II、SPEA-2和MOGWO)进行了比较。实验设置与第5.3节所述相同。此外,执行田口方法(Taguchi method)来调整比较算法的参数以获得最佳性能。对于NSGA-II,交叉概率为1,变异概率为0.02;对于SPEA-2,交叉概率为1,变异概率为0.03。MOGWO不需要预定义的参数。
表7至表10显示了GD、IGD、HV和SC的比较结果。可以看出,CMOMA在所有指标中都取得了最好的结果。关于GD,CMOMA在21个实例中的20个实例上显著优于NSGA-II,并且在所有实例上都显著优于SPEA-2和MOGWO。在IGD方面,CMOMA均显著优于比较算法。NSGA-II和SPEA-2的性能相当,超过了MOGWO。然而,它们的结果均差于CMOMA,尤其是在大型实例上。对于HV,CMOMA在所有实例上的结果都保持在0.8左右,这意味着CMOMA的非支配解始终覆盖了大部分的目标空间。相反,NSGA-II、SPEA-2和MOGWO的性能较差,在中型和大型实例上可以看到显著的性能下降。在质量比较方面,CMOMA具有巨大的优势。CMOMA的解集中解支配了SPEA2和MOGWO解集中绝大部分解。除了第一个实例之外,CMOMA的结果明显好于NSGA-II的结果,特别是在大型实例上。
《表7》
表7 CMOMA、NSGA-II、SPEA-2和MOGWO在所有测试实例上的GD均值和两样本检验结果
| Test instance | CMOMA | NSGA-II | SPEA-2 | MOGWO |
|---|---|---|---|---|
| 1 | 1.1402 × 10-3 | 1.1716 × 10-3= | 1.8564 × 10-3+ | 2.5177 × 10-3+ |
| 2 | 8.9269 × 10-4 | 1.1832 × 10-3+ | 1.5757 × 10-3+ | 2.3667 × 10-3+ |
| 3 | 9.2624 × 10-4 | 1.2792 × 10-3+ | 1.9651 × 10-3+ | 2.6771 × 10-3+ |
| 4 | 1.0683 × 10-3 | 1.3604 × 10-3+ | 1.9080 × 10-3+ | 3.1077 × 10-3+ |
| 5 | 9.0086 × 10-4 | 1.3917 × 10-3+ | 2.1230 × 10-3+ | 3.7516 × 10-3+ |
| 6 | 8.8471 × 10-4 | 1.2978 × 10-3+ | 1.6351 × 10-3+ | 2.7415 × 10-3+ |
| 7 | 1.0415 × 10-3 | 1.3033 × 10-3+ | 1.8277 × 10-3+ | 4.1431 × 10-3+ |
| 8 | 7.9311 × 10-4 | 8.9139 × 10-4+ | 1.0697 × 10-3+ | 1.6005 × 10-3+ |
| 9 | 8.7197 × 10-4 | 1.1159 × 10-3+ | 1.3992 × 10-3+ | 2.2571 × 10-3+ |
| 10 | 7.6937 × 10-4 | 9.7697 × 10-4+ | 1.1289 × 10-3+ | 2.0441 × 10-3+ |
| 11 | 7.8789 × 10-4 | 1.0573 × 10-3+ | 1.2310 × 10-3+ | 2.1723 × 10-3+ |
| 12 | 7.7134 × 10-4 | 9.5573 × 10-4+ | 1.2966 × 10-3+ | 2.2548 × 10-3+ |
| 13 | 8.7732 × 10-4 | 1.0020 × 10-3+ | 1.5837 × 10-3+ | 3.1690 × 10-3+ |
| 14 | 7.9210 × 10-4 | 1.0903 × 10-3+ | 1.2610 × 10-3+ | 2.4987 × 10-3+ |
| 15 | 7.4785 × 10-4 | 1.0657 × 10-3+ | 1.2482 × 10-3+ | 1.9489 × 10-3+ |
| 16 | 7.0934 × 10-4 | 1.0747 × 10-3+ | 1.1446 × 10-3+ | 1.8948 × 10-3+ |
| 17 | 6.9929 × 10-4 | 9.4979 × 10-4+ | 1.1071 × 10-3+ | 2.2707 × 10-3+ |
| 18 | 7.0551 × 10-4 | 9.8959 × 10-4+ | 1.2360 × 10-3+ | 2.4601 × 10-3+ |
| 19 | 8.1797 × 10-4 | 1.1376 × 10-3+ | 1.2641 × 10-3+ | 2.2323 × 10-3+ |
| 20 | 8.2308 × 10-4 | 1.1959 × 10-3+ | 1.4157 × 10-3+ | 2.7575 × 10-3+ |
| 21 | 7.6813 × 10-4 | 1.1232 × 10-3+ | 1.1994 × 10-3+ | 2.6607 × 10-3+ |
《表8》
表8 CMOMA、NSGA-II、SPEA-2和MOGWO在所有测试实例上的IGD均值和两样本检验结果
| Test instance | CMOMA | NSGA-II | SPEA-2 | MOGWO |
|---|---|---|---|---|
| 1 | 2.3340 × 10-2 | 7.2065 × 10-2+ | 1.0358 × 10-1+ | 1.5891 × 10-1+ |
| 2 | 2.1670 × 10-2 | 6.1960 × 10-2+ | 9.6220 × 10-2+ | 1.4701 × 10-1+ |
| 3 | 2.0485 × 10-2 | 5.6040 × 10-2+ | 8.9475 × 10-2+ | 1.4169 × 10-1+ |
| 4 | 1.9490 × 10-2 | 6.0020 × 10-2+ | 8.8250 × 10-2+ | 1.3948 × 10-1+ |
| 5 | 2.0115 × 10-2 | 7.9250 × 10-2+ | 1.0278 × 10-1+ | 1.5871 × 10-1+ |
| 6 | 1.7660 × 10-2 | 5.7635 × 10-2+ | 9.4770 × 10-2+ | 1.5045 × 10-1+ |
| 7 | 1.7275 × 10-2 | 7.0960 × 10-2+ | 8.8365 × 10-2+ | 1.5922 × 10-1+ |
| 8 | 1.9570 × 10-2 | 1.0879 × 10-1+ | 1.2709 × 10-1+ | 1.8022 × 10-1+ |
| 9 | 1.9740 × 10-2 | 1.3424 × 10-1+ | 1.4818 × 10-1+ | 2.0281 × 10-1+ |
| 10 | 1.9885 × 10-2 | 1.4195 × 10-1+ | 1.5176 × 10-1+ | 2.0302 × 10-1+ |
| 11 | 2.0765 × 10-2 | 1.3806 × 10-1+ | 1.4424 × 10-1+ | 1.9940 × 10-1+ |
| 12 | 1.7870 × 10-2 | 1.5765 × 10-1+ | 1.5572 × 10-1+ | 2.1148 × 10-1+ |
| 13 | 1.8085 × 10-2 | 1.4425 × 10-1+ | 1.4284 × 10-1+ | 1.9310 × 10-1+ |
| 14 | 1.8105 × 10-2 | 1.5876 × 10-1+ | 1.5185 × 10-1+ | 2.0712 × 10-1+ |
| 15 | 1.9610 × 10-2 | 1.6540 × 10-1+ | 1.6076 × 10-1+ | 2.1196 × 10-1+ |
| 16 | 1.8290 × 10-2 | 1.8027 × 10-1+ | 1.7266 × 10-1+ | 2.2438 × 10-1+ |
| 17 | 1.9605 × 10-2 | 1.8536 × 10-1+ | 1.6972 × 10-1+ | 2.2557 × 10-1+ |
| 18 | 1.7440 × 10-2 | 1.7498 × 10-1+ | 1.7019 × 10-1+ | 2.1648 × 10-1+ |
| 19 | 1.8055 × 10-2 | 1.9341 × 10-1+ | 1.8550 × 10-1+ | 2.3061 × 10-1+ |
| 20 | 1.8810 × 10-2 | 1.7300 × 10-1+ | 1.6607 × 10-1+ | 2.0930 × 10-1+ |
| 21 | 1.8935 × 10-2 | 1.8195 × 10-1+ | 1.7194 × 10-1+ | 2.1275 × 10-1+ |
《表9》
表9 CMOMA、NSGA-II、SPEA-2和MOGWO在所有测试实例上的HV均值和两样本检验结果
| Test instance | CMOMA | NSGA-II | SPEA-2 | MOGWO |
|---|---|---|---|---|
| 1 | 7.9977 × 10-1 | 7.2323 × 10-1+ | 6.4637 × 10-1+ | 5.6612 × 10-1+ |
| 2 | 8.2696 × 10-1 | 7.3936 × 10-1+ | 6.5293 × 10-1+ | 5.8092 × 10-1+ |
| 3 | 8.1010 × 10-1 | 7.2721 × 10-1+ | 6.4423 × 10-1+ | 5.7386 × 10-1+ |
| 4 | 8.5031 × 10-1 | 7.5772 × 10-1+ | 6.8929 × 10-1+ | 6.0273 × 10-1+ |
| 5 | 8.5315 × 10-1 | 7.6331 × 10-1+ | 7.0096 × 10-1+ | 6.1010 × 10-1+ |
| 6 | 8.5614 × 10-1 | 7.6245 × 10-1+ | 6.7799 × 10-1+ | 5.8590 × 10-1+ |
| 7 | 8.8252 × 10-1 | 7.5996 × 10-1+ | 7.0769 × 10-1+ | 5.9014 × 10-1+ |
| 8 | 7.7647 × 10-1 | 5.8710 × 10-1+ | 5.4731 × 10-1+ | 4.7669 × 10-1+ |
| 9 | 8.0296 × 10-1 | 6.1238 × 10-1+ | 5.6919 × 10-1+ | 5.0286 × 10-1+ |
| 10 | 8.1026 × 10-1 | 6.0328 × 10-1+ | 5.6409 × 10-1+ | 5.0319 × 10-1+ |
| 11 | 8.2136 × 10-1 | 6.0780 × 10-1+ | 5.7310 × 10-1+ | 5.0382 × 10-1+ |
| 12 | 7.9085 × 10-1 | 5.7480 × 10-1+ | 5.4932 × 10-1+ | 4.8258 × 10-1+ |
| 13 | 8.4326 × 10-1 | 5.8471 × 10-1+ | 5.6201 × 10-1+ | 4.9909 × 10-1+ |
| 14 | 8.3489 × 10-1 | 5.9109 × 10-1+ | 5.8402 × 10-1+ | 5.0734 × 10-1+ |
| 15 | 7.6262 × 10-1 | 5.2343 × 10-1+ | 5.1068 × 10-1+ | 4.5009 × 10-1+ |
| 16 | 7.9199 × 10-1 | 5.2316 × 10-1+ | 5.1511 × 10-1+ | 4.6096 × 10-1+ |
| 17 | 7.9177 × 10-1 | 5.3436 × 10-1+ | 5.2781 × 10-1+ | 4.6419 × 10-1+ |
| 18 | 8.0302 × 10-1 | 5.2764 × 10-1+ | 5.1421 × 10-1+ | 4.6993 × 10-1+ |
| 19 | 8.1730 × 10-1 | 5.2730 × 10-1+ | 5.2423 × 10-1+ | 4.7525 × 10-1+ |
| 20 | 8.0723 × 10-1 | 5.1571 × 10-1+ | 5.1236 × 10-1+ | 4.5845 × 10-1+ |
| 21 | 8.0504 × 10-1 | 5.0620 × 10-1+ | 5.0290 × 10-1+ | 4.5930 × 10-1+ |
《表10》
表10 CMOMA与NSGA-II、SPEA-2和MOGWO在所有测试实例上的SC均值比较
| Test instance | ||||||
|---|---|---|---|---|---|---|
| 1 | 20.93% | 19.35% | 55.43% | 2.70% | 89.64% | 0.13% |
| 2 | 32.73% | 11.60% | 54.65% | 3.78% | 92.09% | 0.13% |
| 3 | 39.73% | 11.03% | 75.53% | 1.18% | 97.25% | 0.05% |
| 4 | 39.53% | 9.20% | 63.05% | 2.48% | 95.83% | 0.15% |
| 5 | 45.25% | 8.85% | 66.08% | 2.15% | 96.74% | 0.05% |
| 6 | 55.08% | 8.35% | 65.93% | 3.15% | 98.28% | 0.03% |
| 7 | 47.53% | 8.28% | 66.45% | 3.00% | 99.51% | 0 |
| 8 | 38.93% | 6.25% | 57.23% | 1.35% | 97.41% | 0 |
| 9 | 56.88% | 3.08% | 77.70% | 0.23% | 99.86% | 0 |
| 10 | 50.55% | 4.78% | 68.30% | 1.05% | 99.14% | 0 |
| 11 | 61.75% | 1.95% | 84.78% | 0.40% | 100.00% | 0 |
| 12 | 55.30% | 3.68% | 83.31% | 0.65% | 99.77% | 0 |
| 13 | 49.60% | 3.03% | 79.80% | 0.45% | 100.00% | 0 |
| 14 | 56.03% | 2.70% | 81.28% | 0.45% | 100.00% | 0 |
| 15 | 57.63% | 1.55% | 77.43% | 0.43% | 99.37% | 0 |
| 16 | 72.15% | 0.73% | 86.78% | 0.18% | 99.93% | 0 |
| 17 | 70.30% | 0.80% | 89.95% | 0.05% | 100.00% | 0 |
| 18 | 61.80% | 1.08% | 92.90% | 0.05% | 99.87% | 0 |
| 19 | 63.74% | 0.98% | 83.06% | 0.35% | 100.00% | 0 |
| 20 | 70.45% | 0.58% | 90.90% | 0.05% | 100.00% | 0 |
| 21 | 82.11% | 0.45% | 98.20% | 0.00% | 100.00% | 0 |
由上述分析可以得出,随着实例大小的增加,CMOMA的优势变得更加明显。为了进一步探索验证此结论,图8显示了每种算法在不同规模实例上随机运行获得的非支配解。在小型实例中,NSGA-II达到了有限的帕累托前沿,并呈现出相对良好的分布,超过了SPEA-2。然而,在中型和大型实例上,NSGA-II的性能明显下降。NSGA-II、SPEA-2和MOGWO的解决方案接近且集中在一个小区域,未能充分探索目标空间。相比之下,CMOMA在所有实例上的解占据了很大的空间,并覆盖了比较算法的大部分解。这种优势主要源于局部搜索算子和竞争机制,这使得算法能够充分而高效地搜索。
《图8》
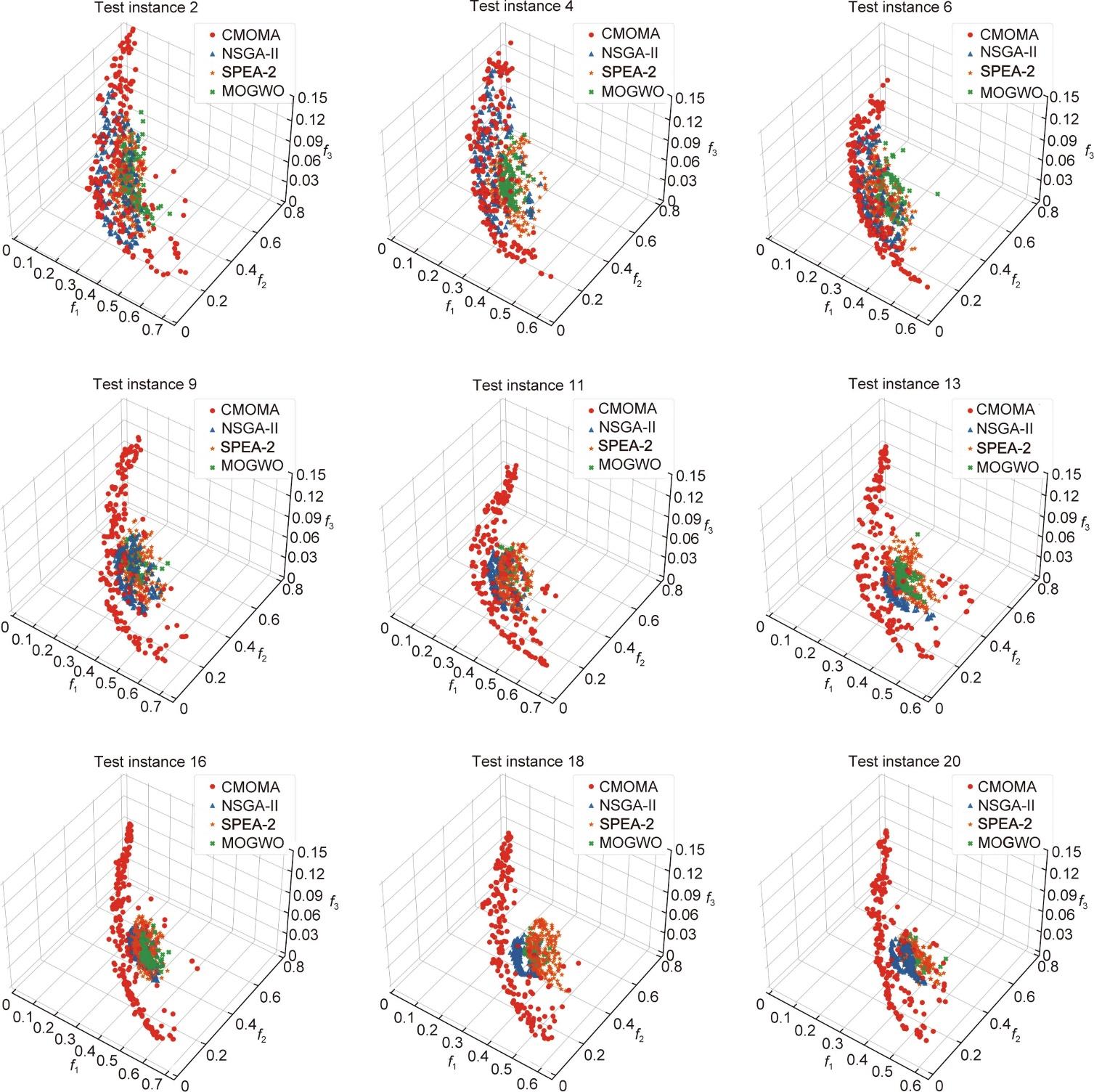
图8 通过在小型测试实例(2、4和6)、中型测试实例(9、11和13)和大型测试实例(16、18和20)上随机运行CMOMA、NSGA-II、SPEA-2和MOGWO获得的非主导解。
本文通过研究任务的子任务按顺序完成的模式,说明了所提出的DMSCO方法的有效性。这是一种基本模式,可以简单地扩展至其他模式。例如,为了适应存在并行子任务的模式,只需进行两处修改。首先,将公式(20)F =
《6、 结论》
6、 结论
随着工业互联网平台在制造业中的应用,高质量的制造服务协作方案必不可少。本文提出了一种双维度的服务协作优化方法来优化服务选择和数量分配,以提高解决方案的质量。在本研究中,制造服务在三个粒度上进行建模,并讨论了它们的组件和结构以确保协作方案的可行性。与以前的工作不同,资源制造服务的可用性被定义为与之相关的物理资源的可访问周期序列,复杂服务的可用性受组件服务及其关系的影响。然后制定DMSCO模型,以同时优化服务选择和数量分配。设计了一种嵌入竞争机制的CMOMA对模型求解,同时进行了大量实验,结果表明所提出算法的优越性。具体而言,CMOMA在所有考虑的指标中都优于没有竞争机制的FMOMA,从而验证了该机制的有效性。与NSGA-II、SPEA-2和MOGWO相比,CMOMA也表现出优异的性能。此外,随着实例大小的增加,CMOMA优于比较算法的优势变得明显。
本文旨在为工业互联网平台引入一种新型的双维度协作模式,从而为利益相关者提供新的见解。本研究基于单独的服务优选进行扩展,所提的DMSCO易于相关从业者理解,并与现有流程兼容。同时,本研究中的实验结果揭示了所提的方法在复杂生产过程和大批量生产场景中的应用潜力,如汽车、设备和家用电器制造。生产过程中的每一个环节可以平均分配给多个制造服务,从而提高整体服务协作的性能。然而,需要注意的是,本文中的制造服务建模侧重于物理加工资源,而工业互联网平台也包含其他类型的资源,如软件和物流资源。在未来研究中,将通过真实场景和实验验证与评估所提出的方法。同时,可对如何加强制造服务建模的表达能力以及构建相应的服务协作模型展开进一步研究。此外,本文主要关注满足客户需求的服务协作方案。由于服务提供商的利益也至关重要,因此关于如何同时提高双方的满意度值得研究。











 京公网安备 11010502051620号
京公网安备 11010502051620号




