
2020, Volume 6, Issue 3
Engineering >> 2020, Volume 6, Issue 3 doi: 10.1016/j.eng.2019.09.010
A Geometric Understanding of Deep Learning
a DUT-RU Co-Research Center of Advanced ICT for Active Life, Dalian University of Technology, Dalian 116620, China
b Department of Computer Science, Stony Brook University, Stony Brook, NY 11794-2424, USA
c School of Computer Science, Wuhan University, Wuhan 430072, China
d School of Software, Tsinghua University, Beijing 100084, China
e Center of Mathematical Sciences and Applications, Harvard University, Cambridge, MA 02138, USA
Next Previous
Abstract
This work introduces an optimal transportation (OT) view of generative adversarial networks (GANs). Natural datasets have intrinsic patterns, which can be summarized as the manifold distribution principle: the distribution of a class of data is close to a low-dimensional manifold. GANs mainly accomplish two tasks: manifold learning and probability distribution transformation. The latter can be carried out using the classical OT method. From the OT perspective, the generator computes the OT map, while the discriminator computes the Wasserstein distance between the generated data distribution and the real data distribution; both can be reduced to a convex geometric optimization process. Furthermore, OT theory discovers the intrinsic collaborative—instead of competitive—relation between the generator and the discriminator, and the fundamental reason for mode collapse. We also propose a novel generative model, which uses an autoencoder (AE) for manifold learning and OT map for probability distribution transformation. This AE–OT model improves the theoretical rigor and transparency, as well as the computational stability and efficiency; in particular, it eliminates the mode collapse. The experimental results validate our hypothesis, and demonstrate the advantages of our proposed model.
Keywords
Generative ; Adversarial ; Deep learning ; Optimal transportation ; Mode collapse
Figures
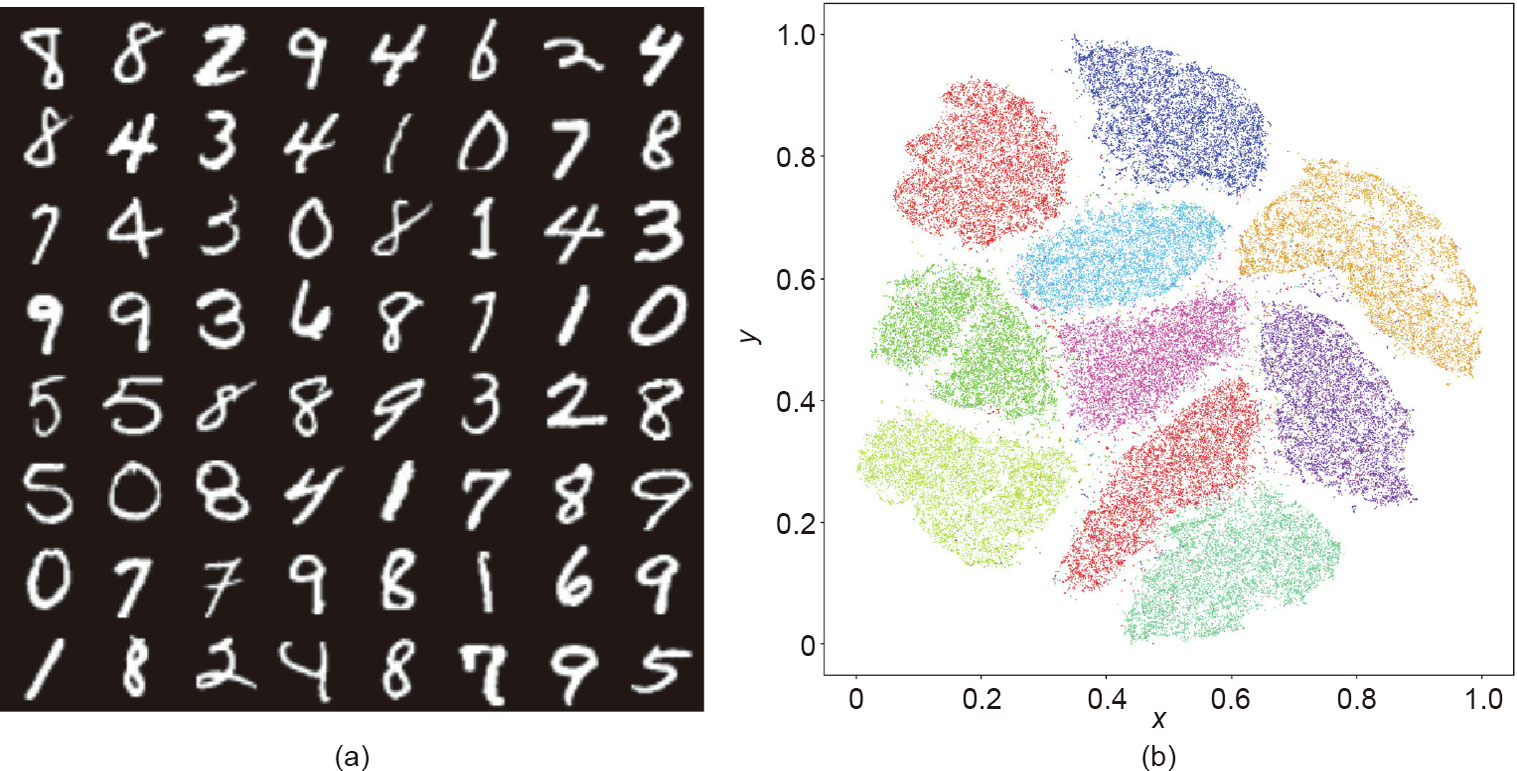
Fig. 1
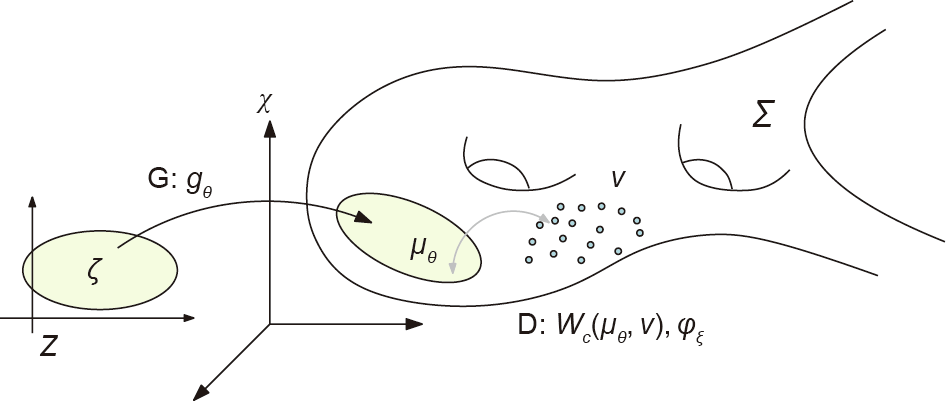
Fig. 2
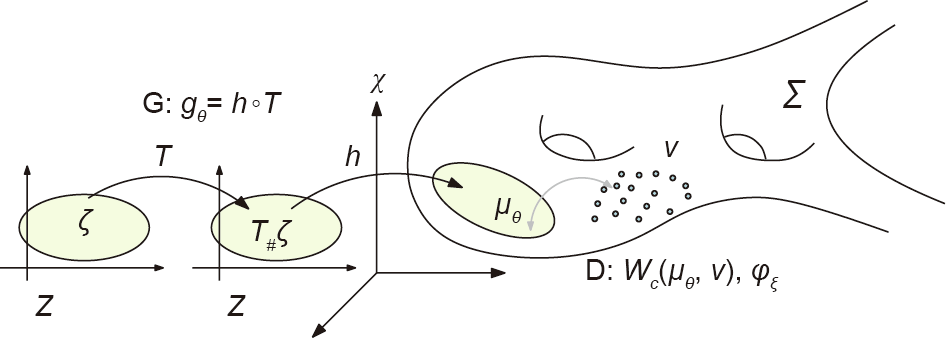
Fig. 3
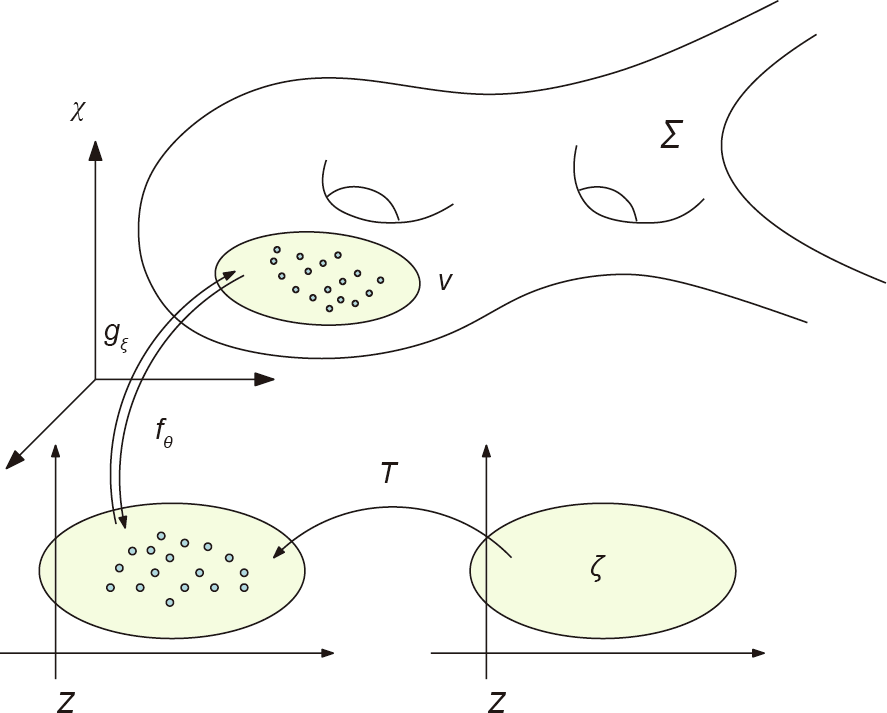
Fig. 4
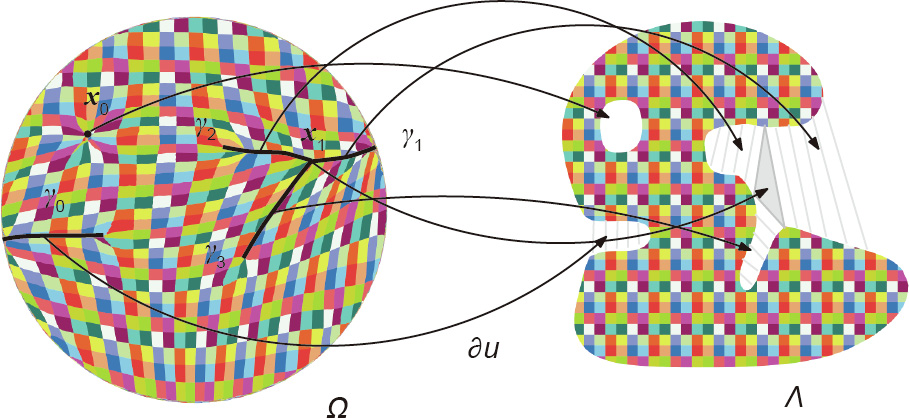
Fig. 5
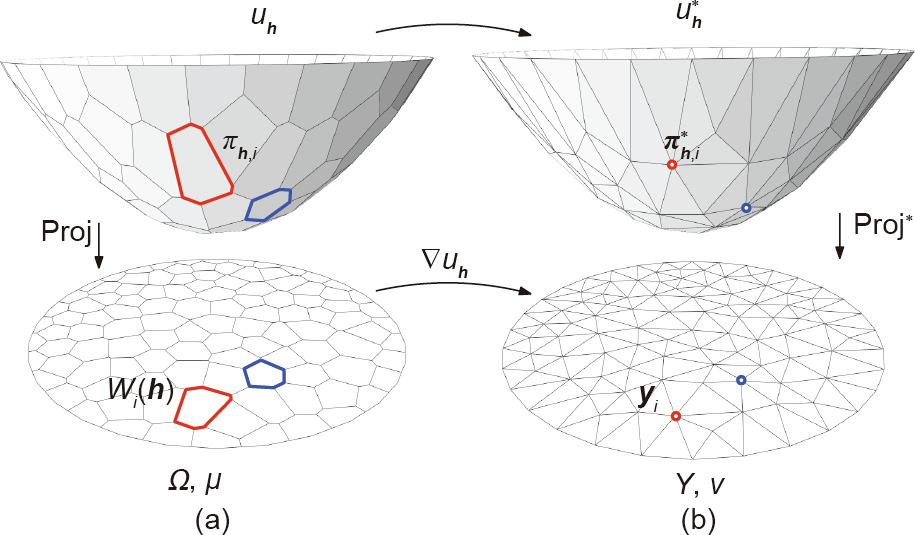
Fig. 6
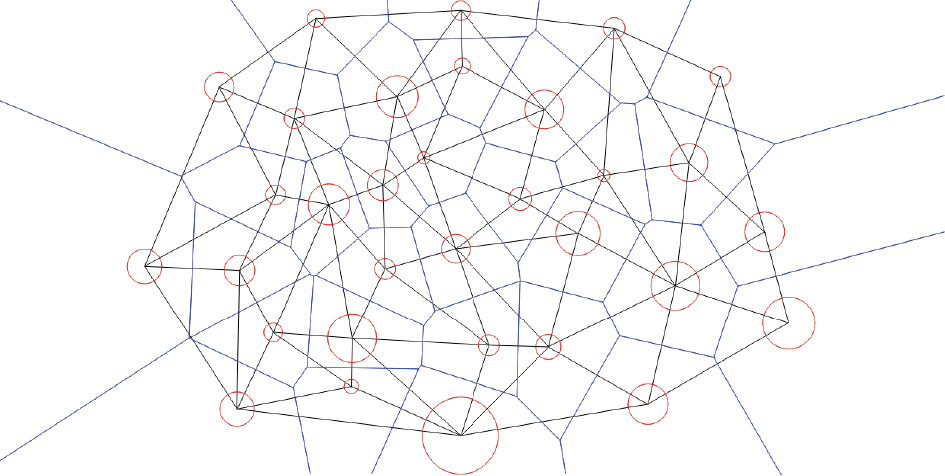
Fig. 7

Fig. 8

Fig. 9

Fig. 10
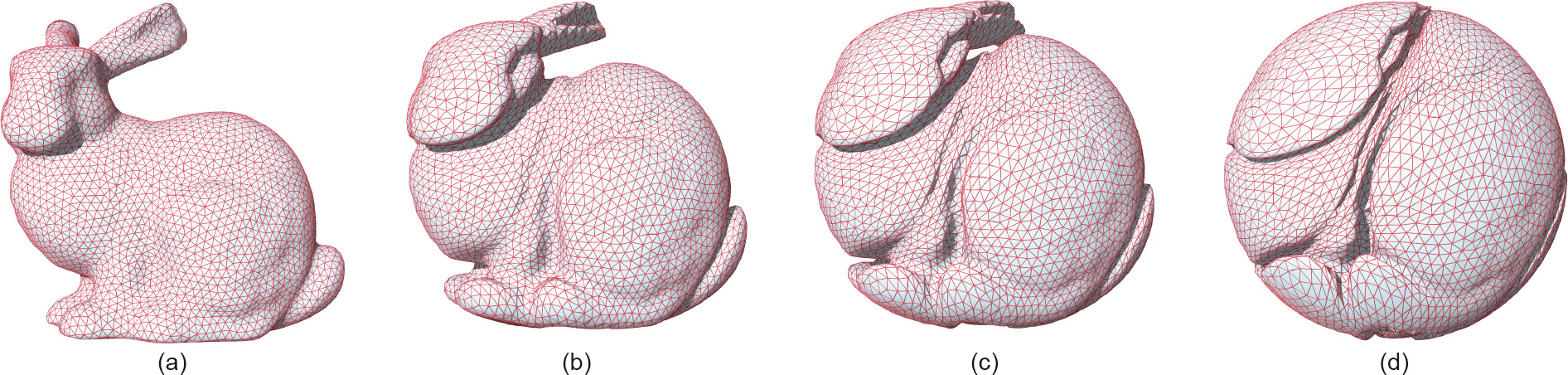
Fig. 11

Fig. 12

Fig. 13
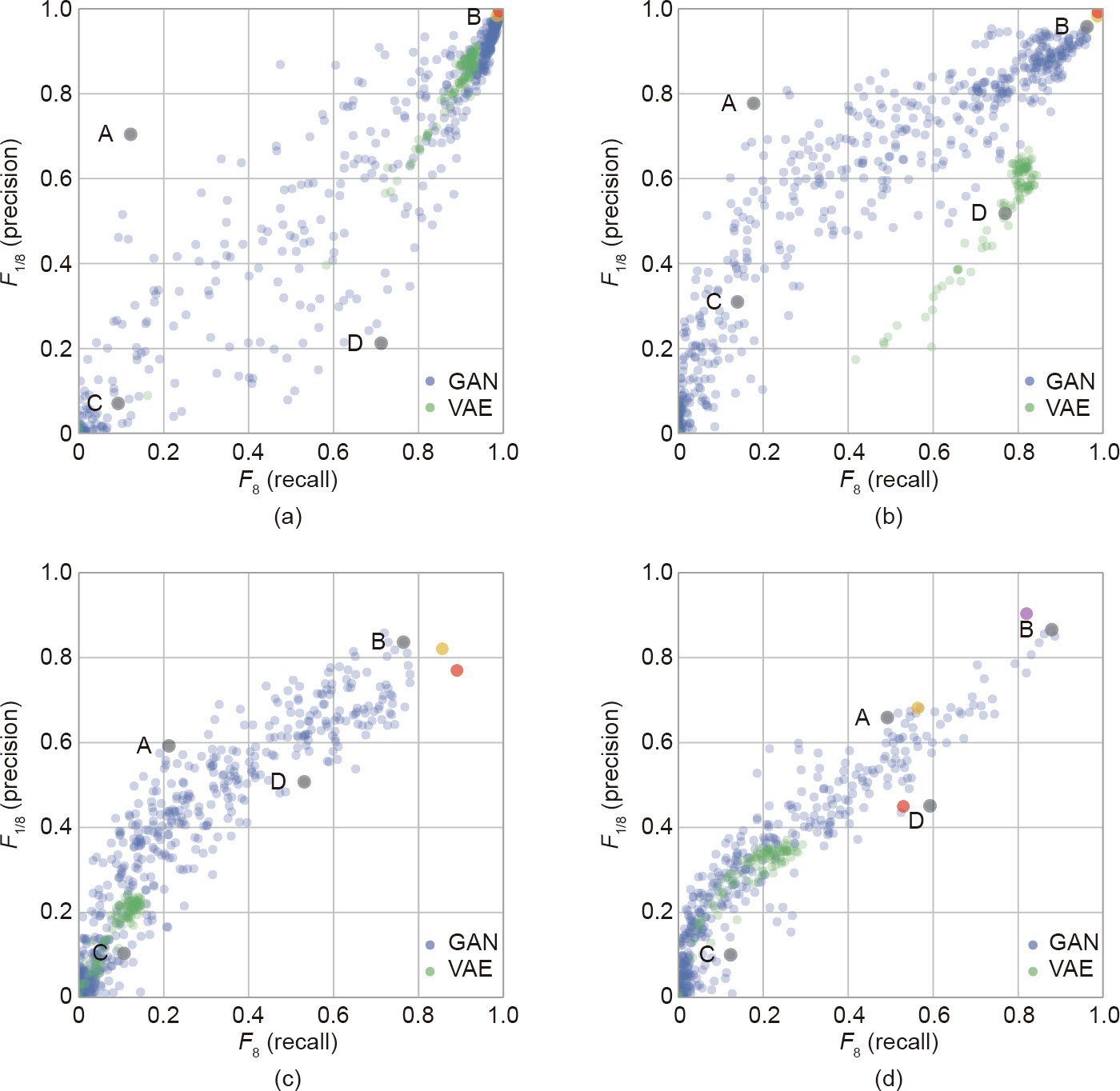
Fig. 14

Fig. 15
References
[ 1 ] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning; 2017 Aug 6–11; Sydney, Australia; 2017. p. 214–23.
[ 2 ] Tenenbaum JB, de Silva V, Langford JC. A global geometric framework for nonlinear dimensionality reduction. Science 2000;290(5500):2319–23. link1
[ 3 ] van der Maaten L, Hinton G. Visualizing data using t-SNE. J Mach Learn Res 2008;9(11):2579–605. link1
[ 4 ] Mescheder L, Geiger A, Nowozin S. Which training methods for GANs do actually converge? In: Proceedings of the 35th International Conference on Machine Learning; 2018 Jul 10–15; Stockholmsmässan, Sweden; 2018. p. 3478–87.
[ 5 ] Villani C. Optimal transport: old and new. Berlin: Springer Science & Business Media; 2008. link1
[ 6 ] Gu DX, Luo F, Sun J, Yau ST. Variational principles for Minkowski type problems, discrete optimal transport, and discrete Monge–Ampère equations. Asian J Math 2016;20(2):383–98. link1
[ 7 ] Peyré G, Cuturi M. Computational optimal transport. Found Trends Mach Learn 2019;11(5–6):355–607. link1
[ 8 ] Solomon J. Optimal transport on discrete domains. 2018. arXiv:1801.07745.
[ 9 ] Cuturi M. Sinkhorn distances: lightspeed computation of optimal transportation distances. Adv Neural Inf Process Syst 2013;26:2292–300. link1
[10] Solomon J, de Goes F, Peyré G, Cuturi M, Butscher A, Nguyen A, et al. Convolutional wasserstein distances: efficient optimal transportation on geometric domains. ACM Trans Graph 2015;34(4):66. link1
[11] Lei N, Su K, Cui L, Yau ST, Gu XD. A geometric view of optimal transportation and generative model. Comput Aided Geom Des 2019;68:1–21. link1
[12] Benamou JD, Brenier Y, Guittet K. The Monge–Kantorovitch mass transfer and its computational fluid mechanics formulation. Int J Numer Methods Fluids 2002;40(1–2):21–30. link1
[13] Jean-David Benamou BDF, Oberman AM. Numerical solution of the optimal transportation problem using the Monge–Ampère equation. J Comput Phys 2014;260:107–26. link1
[14] Nicolas P, Gabriel P, Oudet E. Optimal transport with proximal splitting. SIAM J Imaging Sci 2014;7(1):212–38. link1
[15] Bengio Y, Mesnil G, Dauphin Y, Rifai S. Better mixing via deep representations. In: Proceedings of the 30th International Conference on Machine Learning; 2013 Jun 16–21; Atlanta, GA, USA; 2013. p. 552–60.
[16] Salakhutdinov R, Larochelle H. Efficient learning of deep Boltzmann machines. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics; 2010 May 13–15; Chia Laguna Resort, Italy; 2010. p. 693–700.
[17] Kingma DP, Welling M. Auto-encoding variational Bayes. 2013. arXiv:1312.6114.
[18] Rezende DJ, Mohamed S, Wierstra D. Stochastic backpropagation and approximate inference in deep generative models. 2014. arXiv:1401.4082.
[19] Makhzani A, Shlens J, Jaitly N, Goodfellow I, Frey B. Adversarial autoencoders. 2015. arXiv:1511.05644.
[20] Tolstikhin I, Bousquet O, Gelly S, Schoelkopf B. Wasserstein auto-encoders. 2017. arXiv:1711.01558.
[21] He X, Yan S, Hu Y, Niyogi P, Zhang HJ. Face recognition using laplacianfaces. IEEE Trans Pattern Anal Mach Intell 2005;27(3):328–40. link1
[22] Arandjelovic´ O. Unfolding a face: from singular to manifold. In: Proceedings of the 9th Asian Conference on Computer Vision; 2009 Sep 23–27; Xi’an, China; 2009. p. 203–13.
[23] Salimans T, Karpathy A, Chen X, Kingma DP. PixelCNN++: Improving the PixelCNN with discretized logistic mixture likelihood and other modifications. 2017. arXiv:1701.05517.
[24] Oord Ad, Kalchbrenner N, Kavukcuoglu K. Pixel recurrent neural networks. 2016. arXiv:1601.06759.
[25] Van Den Oord A, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, et al. WaveNet: a generative model for raw audio. 2016. arXiv:1609.03499.
[26] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. 2014. arXiv:1406.2661.
[27] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville AC. Improved training of wasserstein GANs. 2017. arXiv:1704.00028.
[28] Miyato T, Kataoka T, Koyama M, Yoshida Y. Spectral normalization for generative adversarial networks. 2018. arXiv:1802.05957.
[29] Zoran D, Weiss Y. From learning models of natural image patches to whole image restoration. In: Proceedings of the 2011 International Conference on Computer Vision; 2011 Jun 6–11; Barcelona, Spain; 2011. p. 479–86.
[30] Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X. Improved techniques for training GANs. 2016. arXiv:1606.03498.
[31] Heusel M, Ramsauer H, Unterthiner T, Nessler B, Klambauer G, Hochreiter S. GANs trained by a two time-scale update rule converge to a Nash equilibrium. 2017. arXiv:1706.08500.
[32] Sajjadi MS, Bachem O, Lucic M, Bousquet O, Gelly S. Assessing generative models via precision and recall. 2018. arXiv:1806.00035.
[33] Lucic M, Kurach K, Michalski M, Gelly S, Bousquet O. Are GANs created equal? A large-scale study. 2018. arXiv:1711.10337.
[34] Bojanowski P, Joulin A, Lopez-Paz D, Szlam A. Optimizing the latent space of generative networks. 2017. arXiv:1707.05776.
[35] Li K, Malik J. Implicit maximum likelihood estimation. 2018. arXiv:1809.09087.
[36] Hoshen Y, Malik J. Non-adversarial image synthesis with generative latent nearest neighbors. 2018. arXiv:1812.08985.
[37] Dinh L, Krueger D, Bengio Y. NICE: non-linear independent components estimation. 2014. arXiv:1410.8516.
[38] Dinh L, Sohl-Dickstein J, Bengio S. Density estimation using real NVP. 2017. arXiv:1605.08803.
[39] Kingma DP, Dhariwal P. Glow: generative flow with invertible 1 1 convolutions. 2018. arXiv:1807.03039.
[40] LeCun Y, Chopra S, Hadsell R, Ranzota MA, Huang FJ. A tutorial on energybased learning. In: Bakir G, Hofman T, Schölkopf T, Smola A, Taskar B, editors. Predicting structured data. Cambridge: The MIT Press; 2006. link1
[41] Dai J, Lu Y, Wu Y. Generative modeling of convolutional neural networks. In: Proceedings of the 3rd International Conference on Learning Representations; 2015 May 7–9; San Diego, CA, USA; 2015.
[42] Nijkamp E, Hill M, Zhu S, Wu Y. On learning non-convergent nonpersistent short-run MCMC toward energy-based model. 2019. arXiv:1904. 09770.
[43] Bonnotte N. From Knothe’s rearrangement to Brenier’s optimal transport map. SIAM J Math Anal 2013;45(1):64–87. link1
[44] Brenier Y. Polar factorization and monotone rearrangement of vector-valued functions. Commun Pure Appl Math 1991;44(4):375–417. link1
[45] Caffarelli L. Some regularity properties of solutions of Monge–Ampère equation. Commun Pure Appl Math 1991;44(8–9):965–9. link1
[46] Alexandrov AD. Convex polyhedra. New York: Springer; 2005. link1
[47] Guo X, Hong J, Lin T, Yang N. Relaxed wasserstein with applications to GANs. 2017. arXiv:1705.07164.
[48] Lei N, Guo Y, An D, Qi X, Luo Z, Gu X, et al. Mode collapse and regularity of optimal transportation maps. 2019. arXiv:1902.02934.
[49] Kingma DP, Ba J. Adam: a method for stochastic optimization. 2014. arXiv:1412.6980.
[50] Srivastava A, Valkov L, Russell C, Gutmann MU, Sutton C. VeeGAN: reducing mode collapse in GANs using implicit variational learning. 2017. arXiv:1705.17761.
[51] Lin Z, Khetan A, Fanti G, Oh S. PacGAN: the power of two samples in generative adversarial networks. 2017. arXiv:1712.04086.
[52] Dumoulin V, Belghazi I, Poole B, Mastropietro O, Lamb A, Arjovsky M, et al. Adversarially learned inference. 2016. arXiv:1606.00704.
[53] LeCun Y, Cortes C, Burges CJC. The MNIST database of handwritten digits. Available from: http://yann.lecun.com/exdb/mnist/. link1
[54] Xiao H, Rasul F, Vollgraf R. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms. 2017. arXiv:1708.07747.
[55] Krizhevsky A. Learning multiple layers of features from tiny images. Technical report. Toronto: University of Toronto; 2009. link1
[56] Zhang Z, Luo P, Loy CC, Tang X. From facial expression recognition to interpersonal relation prediction. Int J Comput Vis 2018;126(5):550–69. link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




