
2019, Volume 21, Issue 6
Strategic Study of CAE >> 2019, Volume 21, Issue 6 doi: 10.15302/J-SSCAE-2019.10.001
Software Architecture of Fogcloud Computing for Big Data in Ubiquitous Cyberspace
1. College of Computer Science and Technology, National University of Defense Technology, Changsha 410073, China;
2. Chinese Academy of Engineering, Beijing 100088, China;
3. Zhejiang Lab, Hangzhou 310012, China
Next Previous
Abstract
The cyberspace has expanded from traditional internet to ubiquitous cyberspace which interconnects human, machines,things, services, and applications. The computing paradigm is also shifting from centralized computing in the cloud to combined computing in the front end, middle layer, and cloud. Therefore, traditional computing paradigms such as cloud computing and edge computing can no longer satisfy the evolving computing needs of big data in ubiquitous cyberspace. This paper presents a computing architecture named Fogcloud Computing for big data in ubiquitous cyberspace. Collaborative computing by multiple knowledge actors in the fog, middle layer, and cloud is realized based on the collaborative computing language and models, thereby providing a solution for big data computing in ubiquitous cyberspace.
Keywords
fogcloud computing ; ubiquitous cyberspace ; big data ; Internet of Things ; cloud computing
Figures
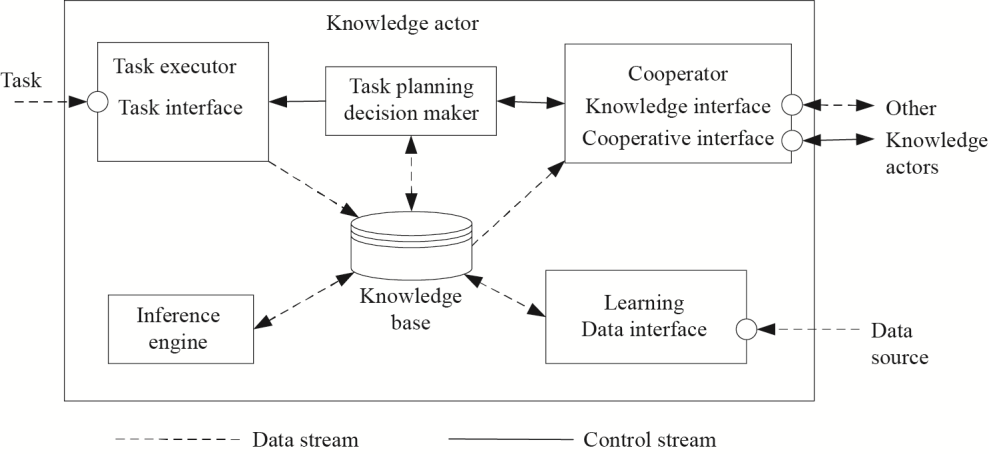
Fig. 1

Fig. 2
References
[ 1 ] Schroeder B, Gibson G. A large-scale study of failures in high performance computing systems [J]. IEEE Transactions on Dependable and Secure Computing, 2009, 7(4): 337-350. link1
[ 2 ] Luo J Z, Jin J H, Song A B, et al. Cloud computing: Architecture and key technologies [J]. Journal on Communications, 2011 (7): 3-21. Chinese. link1
[ 3 ] Bonomi F, Milito R, Zhu J, et al. Fog computing and its role in the internet of things [C]. Helsinki: Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, 2012. link1
[ 4 ] Shi W, Cao J, Zhang Q, et al. Edge computing: Vision and challenges [J]. IEEE Internet of Things Journal, 2016, 3(5): 637-646. link1
[ 5 ] Liu D Y, Yang K, Chen J Z. Agents: Present status and trends [J]. Journal of Software, 2000, 11(3): 315-321. Chinese. link1
[ 6 ] Olfati-Saber R, Fax J A , Murray R M. Consensus and cooperation in networked multi-agent systems [J]. Proceedings of the IEEE, 2007, 95(1): 215-233. link1
[ 7 ] Mayer-Schonberger V, Cukier K. Big data: A revolution that will transform how we live, work, and think [M]. Boston: Houghton Mifflflin Harcourt, 2013.
[ 8 ] Sicari S, Rizzardi A, Grieco L A, et al. Security, privacy and trust in Internet of Things: The road ahead [J]. Computer Networks, 2015, 76(15): 146-164. link1
[ 9 ] Fang B X, Jia Y, Li X, et al. Big search in cyberspace [J]. IEEE Transactions on Knowledge and Data Engineering, 2017, 29(9): 1793-1805. link1
[10] López G, Quesada L, Guerrero L A. Alexa vs. Siri vs. Cortana vs. Google Assistant: A comparison of speech-based natural user interfaces [C]. Los Angeles: International Conference on Applied Human Factors and Ergonomics, 2017. link1
[11] Baker M. Real, unreal, and hacked [J]. IEEE Pervasive Computing, 2018, 17(1): 104-112 link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




