
2009, Volume 11, Issue 10
Strategic Study of CAE >> 2009, Volume 11, Issue 10
Towards instant service rebuilding after site corruptions
Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China
Next Previous
Abstract
The paper describes a new system protection method which is used for disaster recovery. It abandons the traditional data protection based DR(disaster recovery) achieves, replicates the whole system states, including data states together with service running states, and further introduces the method of parallel recovery to restore the interrupted services instantly. Compared with traditional techniques, the method can be independent from specific devices and applications. Different systems can share a unique DR system which is resource-saving.
Keywords
Figures
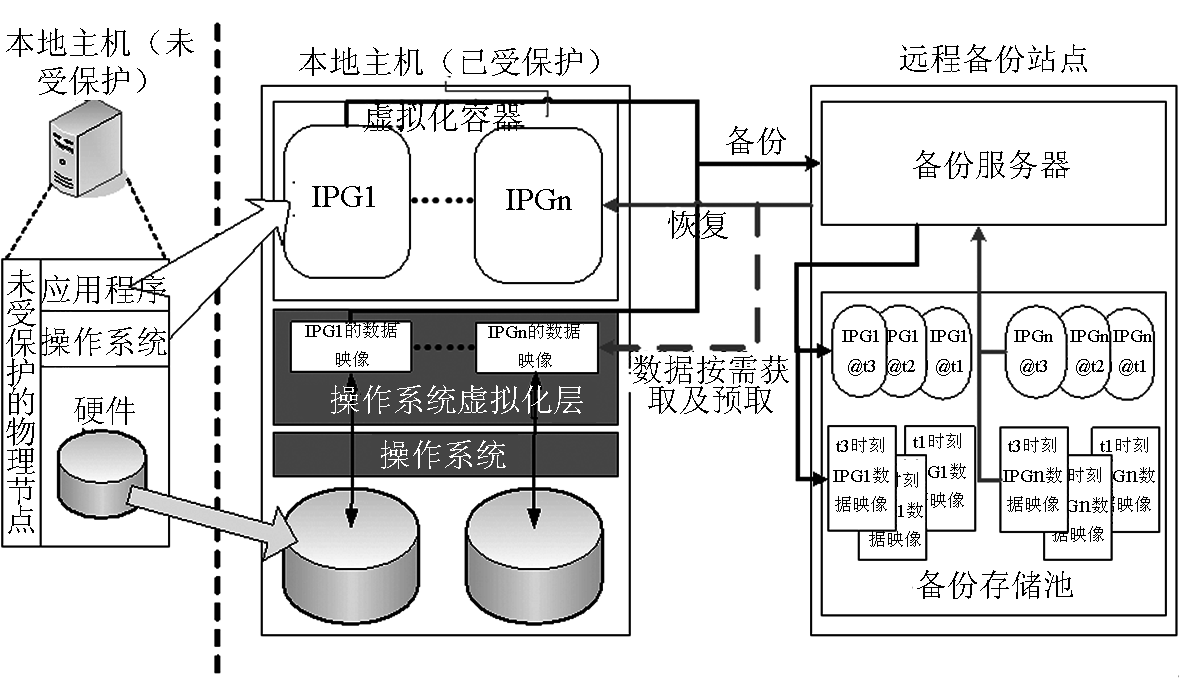
图1

图2
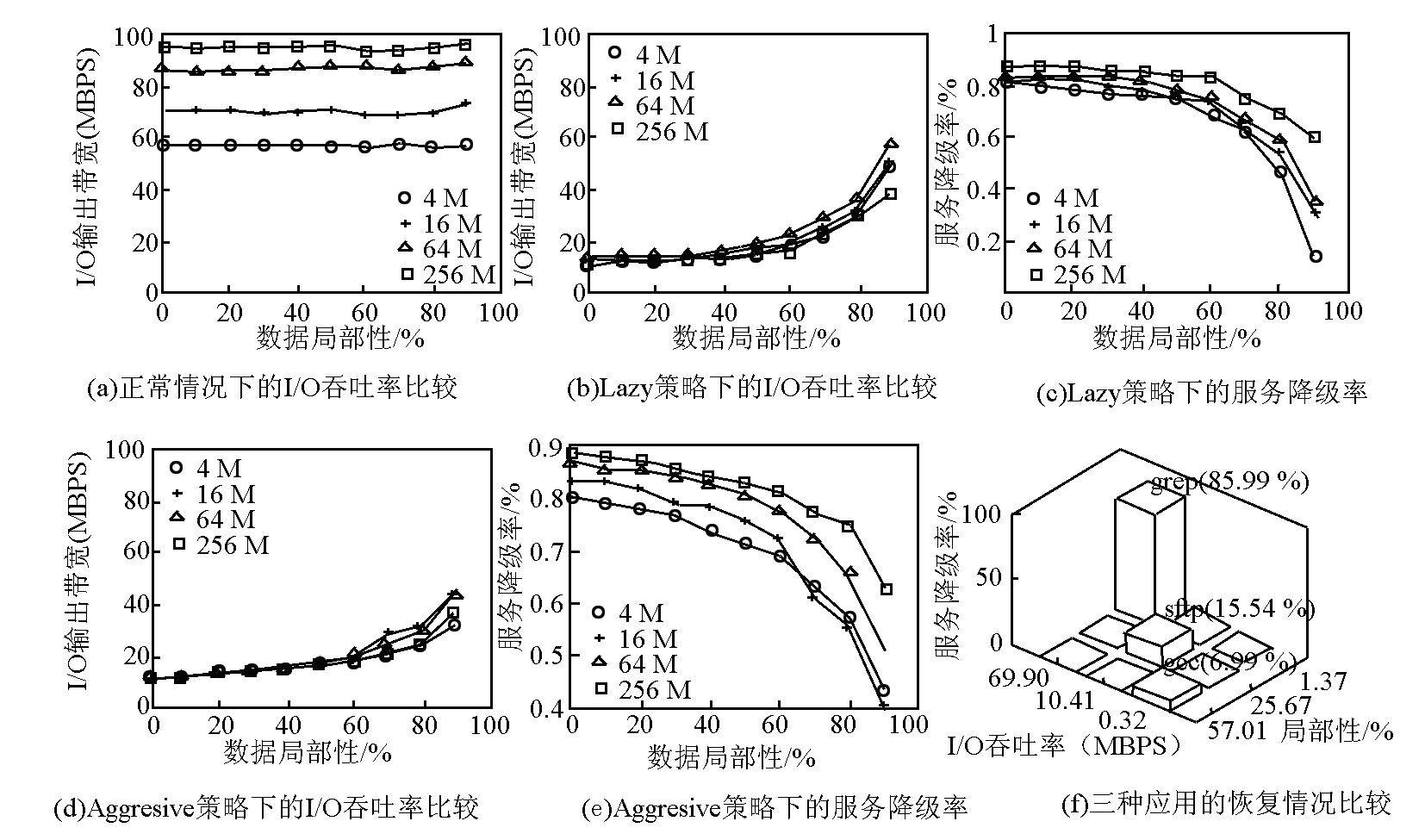
图3
References
[ 1 ] Brett J L,Landry.Dispelling 10 common disaster recovery myths: lessons learned from hurricane katrina and other disasters [ J ] . ACM Journal on Educational Resources in Computing, 2006 , 6 ( 4 ) link1
[ 2 ] Khalid Saleem, Steven Luis, Yi Deng, et al.Towards a Business Continuity Information Network for Rapid Disaster Recovery, DGO 2008 [ C] .Montreal, Canada, 2008
[ 3 ] Ken Fong.Contingency Planning and Disaster Recovery[ A] .ACM 1984 Annual Conference[ C] .1984
[ 4 ] Hector Garcia Molina, Christos A.Polyzois, Issues in disaster re- covery[ A] .the Thirty -Fifth IEEE Computer Society International Conference[ C] .1990
[ 5 ] Laden G, TaShma P, Yaffe E, et al.Fienblit, Architectures for Controller Based CDP[ A] .FAST 2007 [ C] .San Jose, CA,2007
[ 6 ] Akshat Verma, Kaladhar Voruganti, Ramani Routray, et al. SWEEPER: An Efficient Disaster Recovery Point Identification Mechanism[ A] .FAST 2008 [ C] .San Jose, CA,2008 link1
[ 7 ] Weijun Xiao,Qing Yang.Can We Really Recover Data If Storage Subsystem Fails[ A] .ICDCS 2008 [ C] .Beijing, China,2008 link1
[ 8 ] Suparna Bhattacharya, Mohan C, Karen W, et al.Coordinating Backup /Recovery and Data Consistency Between Database and File Systems[ A] .SIGMOD 2002 [ C] .Madison, Wisconsin,2002 link1
[ 9 ] IPStor Snapshot Agents for Databases - At a Glance[ R] .Falcon- Stor Software, 2007 , http: //www.ids -g.com /Whitepapers /Fal- conStor /Brochures /Appdatabasesnapshots.pdf
[10] Brendan Cully, Geoffrey Lefebvre, Dutch Meyer,et al.Remus:High Availability via Asynchronous Virtual Machine Replication, NSDI 2008 [ C] .San Francisco, CA,2008
[11] Constantine P, Sapuntzakis, Ramesh Chandra, et al.Optimizing the Migration of Virtual Computers[ A] .OSDI 2002 [ C] .Boston, MA,2002 link1
[12] Steven Osman, Dinesh Subhraveti, Gong Su, et al, The Design and Implementation of Zap: A System for Migrating Computing Environments[ A] .OSDI 2002 [ C] .Boston, MA, 2002 link1
[13] Wei Huang, Jiuxing Liu, Matthew Koop, et al.Nomad: Migra- ting OS -bypass Networks in Virtual Machines [ A] .VEE 2007 [ C] .San Diego, CA,2007 link1
[14] Rob Bradford, Evangelos Kotsovinos, Anja Feldmann et al.Live Wide -Area Migration of Virtual Machines Including Local Per- sistent State[ A] .VEE 2007 [ C] .San Diego, CA,2007 link1
[15] Sanjay Kumar, Karsten Schwan.Netchannel: A VMM -level Mechanism for Continuous, Transparent Device Access During VM Migration[ A] .VEE 2008 [ C] .Seattle, WA,2008 link1
[16] Thomas C, Bressoud, Fred B.Schneider: Hypervisor -based Fault -tolerance[ A] .SOSP 1995 [ C] .Colorado, US, 1995 link1
[17] Weimin Zheng, Binxing Fang.Structure -independent disaster recovery: concept, architecture and implementations[ J] .Science in China Series F, 2009 , 52 ( 5 ) :813 -823 link1
[18] Recovery time objective, Wikipedia [ EB /OL] .http: //en.wiki- pedia.org /wiki /Recovery_time_objective
[19] Kimberly Keeton, Cipriano Santos, Dirk Beyer, et al.Designing for disasters[ A] .FAST 2004 [ C] .San Francisco, CA,2004 link1
[20] Erik Vanden Meersch.Designing Highly Available Architectures: A Methodology[ A] .Sun BluePrints Online,2002
[21] Jim Metzler, Rethinking MTTR.IT Impact Breifs [ A] .Issue 4 , May 2007 , http: //www.netscout.com /docs /itimpactbriefs / NetScout iib Metzler 0407 Rethinking MTTR.pdf
[22] Jim Gray.Why do computers stop and what can be done about it? [ R] .Technical Report 85.7 , PN87614 ,1985
[23] Kimberly Keeton, Dirk Beyer, Ernesto Brau,et al,On the Road to Recovery: Restoring Data after Disasters, In Eurosys 2006 , Leuven, Belgium,2006
[24] Oren Laaden, Jason Nieh.Transparent Checkpoint -Restart of Multiple Processes on Commodity Operating Systems, USENIX 2007 [ C] .Santa Clara, CA,2007
[25] Stephen Soltesz, Herbert Potzl, Marc E,Containerbased Operat- ing System Virtualization: A Scalable, High -performance Alter- native to Hypervisors[ A] .Eurosys 2007 [ C] .Lisbon, Portugal, 2007 link1
[26] Michael Nelson, Beng Hong Lim,Greg Hutchins.Fast Transpar- ent Migration for Virtual Machines[ A] .USENIX 2005 [ C] .Ana- heim, CA, 2005 link1
[27] Christopher Clark, Keir Fraser, Steven Hand, et al.Andrew Warfield, Live Migration of Virtual Machines [ A] .NSDI 2005 [ C] .Boston, MA,2005 link1
[28] Hongliang Yu, Dongdong Zheng, Ben Y,et al.Understanding us- er behavior in large -scale video -on -demand systems [ A] . Eurosys 2006 [ C] .Leuven, Belgium,2006 , http: //hpc.cs.tsin- ghua.edu.cn /granary link1











 京公网安备 11010502051620号
京公网安备 11010502051620号




