
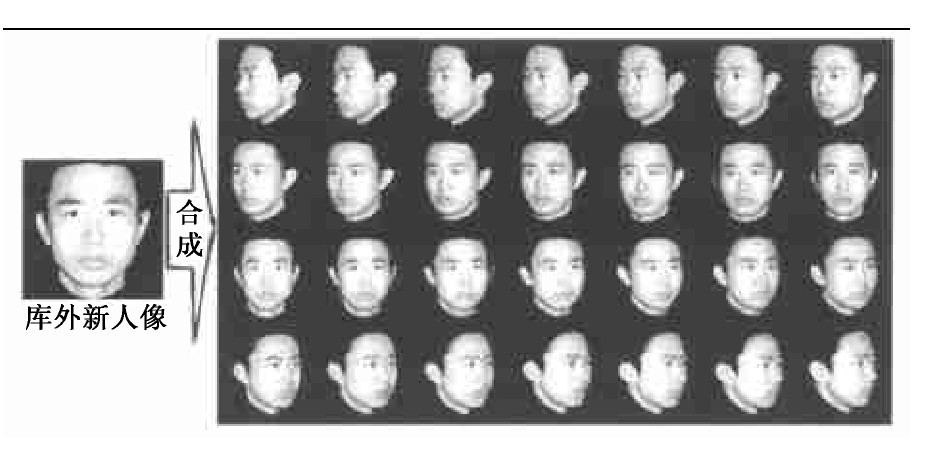






《1 引言》
1 引言
人像处理和人脸属性 (年龄、性别、人种等) 变换是计算机视觉和图像图形学领域的重要研究内容
利用线性人脸对象类模型建模的文献包括: Blanz与Vetter
建立线性人脸对象类模型的关键技术之一是模型匹配, 即如何求得最佳的人像模型表达 (近似全局最优) 。有效的技术包括随机梯度下降方法
《2 线性人脸对象类模型及模型匹配》
2 线性人脸对象类模型及模型匹配
《2.1人像对准模型》
2.1人像对准模型
在建立精确的像素级人像对准前, 需要先进行基于主要点特征的预对准
定义人脸图像I为一个集合映射:I∶R2→B, 其中B表示图像的灰度值集合, R是实数集合。I (x, y) 表示图像上某点的灰度值。设样本空间中的样本图像为Ir, I1, I2, …, IN, 其中Ir为参考图像 (也可以定义某种参考模型Imodel) , 样本数目为 (N+1) 。定义全局仿射变换Aj∶R2→R2, 可对图像进行平移、旋转和尺度变换, 其中A满足
式中S为尺度, θ为像平面旋转角度, tx, ty为2D平移的参数。预对准前后的像素坐标对应关系为
其中运算符‘。’表示全局仿射变换, Aj (x, y) = (xA, yA) , (xA, yA) 表示Ij中像素点 (x, y) 经过全局仿射变换后的坐标位置。对上述6个参数的确定需要已知至少3对相互对准的特征点坐标。
人脸形状包括图像中人脸的轮廓、大小和五官的位置分布信息。为了对形状进行有效标定, 选择多条线段作为特征描述单位, 将人脸对象按照生物外观形态特征分为脸庞、眼睛、眉毛、鼻子、嘴巴和耳朵 6 部分, 分别利用多条线段将这几部分标定出来, 得到 6 个线段集合, 相应的定义为S1, S2, S3, S4, S5, S6。这些线段集合中线段的数目分别定义为 n1, n2, n3, n4, n5, n6。特征线段的长度, 数量和位置的变化会对最终的对准效果产生显著的影响。定义特征线段l为一个映射∶l∶R4→l, 其中 l 表示特征线段集合, li (x1, y1, x2, y2) 表示特征线段集合中的一个特征, 即一条线段特征由2个端点的坐标来决定, 这样得到
特定人像与参考人像或参考模型的像素级对准, 意味着主要特征点、特征线段的位置和数目应该是一致的。这样定义参考特征集合表示为D1, D2, D3, D4, D5, D6, 满足
则人像对准的形状特征 (线段集合) 映射以及每个特征集合中的特征线段映射可以表示为
人像纹理表示基于形状特征的图像灰度信息。人像纹理对准是耦合形状信息的像素级的全局性稠密对准。
每幅经过预对准和形状标定的样本图像IAj与参考图像Ir间的像素级对准, 可以由
的2D人像纹理映射表示。
式 (6) 表示由Ir (或Imodel) 到IAj的映射, 例如
运算符‘。’表示纹理映射变换。
为了实现精确的像素级对准, 需要考虑在预对准的基础上进行纹理对准与形状对准的耦合。这样就得到新的人像纹理对准模型:
人像纹理对准模型是建立在人像形状标定模型的基础上的, 通过对人像形状标定模型中的6个特征集合的元素调整, 可以控制每个表达区域产生不同的对准结果。当然, 仅依靠主要特征的对准还无法实现完美的全局像素对准。但是通过特征集合间的合理配合可以达到理想效果。
《2.2线性对象类模型》
2.2线性对象类模型
线性对象类 (linear object class) 模型
假设Iobject 为一个对象元图像, 并表示为一个映射:Iobject∶R2→B, 其中Iobject (x, y) 表示对象图像中一个像素的点的灰度值。计算对象集合中每一个对象元到参考对象元图像Ir的稠密对准, 对准后的对象元图像表示为
其中p=[p0, p1, …, pN] 是线性模型的系数向量。结合基于对象形状的稠密对准, 线性组合
为了获得最佳的模型匹配和对象表达效果, 定义新图像和模型重构图像间的误差能量函数为
最佳的建模匹配求解过程是一个最优化问题。配合提出的新模型匹配技术 (基于相关性扰动的随机梯度下降算法、学习率自适应、非统一抽样和动态高斯金字塔分析) , 求解误差能量函数E (p) 达到全局近似最优解时的线性系数p, 就可以利用有限的样本集合描述最佳的模型匹配效果。计算出的局部最优线性系数解表示为p*= (p*0, p*1, …, p*N) ∈Rn+1, 使误差E (p*) 满足最小值。
线性对象类模型的表达效果生动、自然且有相当高的真实效果, 数据冗余少, 通过建立不同的对象元数据库, 可以获得不同特性的仿真效果。唯一的不足是该模型对于特定对象元的细节特征无法表达, 特别是在包括人脸图像在内的特殊对象类的表达中尤为突出。但是从应用的角度看, 该模型是相当有效和稳定的。加入一定的个体信息后建立的模型可以基本克服该模型的缺陷。
《3 模型匹配提升》
3 模型匹配提升
《3.1随机梯度下降及线性相关性扰动》
3.1随机梯度下降及线性相关性扰动
设标量函数E (p) 是一个光滑且非负的能量函数, 在其上任一点pk对应的梯度是一个向量, 其方向为此函数E (p) 增长最快的方向, 那么负梯度方向就为函数E (p) 下降最快的方向
迭代来更新p值, 就可以快速地找到函数的极小值
实现该算法的关键问题是如何选择学习率a、随机扰动ε以及迭代终止阈值η, ζ。为了使迭代收敛, 学习率a必须是随着每一步迭代逐次衰减的。通常学习率a满足
其中a0是初始化学习率向量, β (n) 是小于1的衰减函数, 通常取负指数函数e-xn, 整数n在区间[0, ∞) 逐次递增, 则有an= [a
学习率衰减过快或者过慢都会使p收敛到某一无效点, 无法找到函数的极小值。此外, 从算法优化角度来讲, 为了提高随机梯度下降的学习效率和系统鲁棒性, 利用高斯金字塔分解对每幅样本图像进行由粗到精的多分辨率处理, 在每级金字塔中学习率a可选择不同的衰减规律。随机扰动ε的选择对于该算法的鲁棒性以及寻找极小值的准确性尤为重要。这里赋予ε向量与梯度值满足相关性, 从而增加其扰动的针对性。定义具有与梯度值线性相关的随机扰动ε满足
其中, ε0是随机扰动振幅, ε0=[ε
利用相关性扰动的随机梯度下降求解能量函数E (p) 极小值甚至最小值, 需要得到其每个参数的偏导数:
适用于这实验条件的经验结论:初始化学习率a0=[1.0, 1.0, …, 1.0]N+1, 衰减因子β (n) =e-0.1n, 随机扰动振幅ε0=3.2 a0, 迭代终止阈值η, ζ=0-9, 随机数幅度δ=0.1。
《3.2学习率自适应》
3.2学习率自适应
在3.1节中提到的随机梯度下降法是依靠固定的学习率衰减幅度, 并结合相关性随机扰动实现全局极小值搜索的。这里还可以采用学习率自适应配合固定随机扰动的方法实现梯度下降法求解
其中q
可以看到第n+1次迭代时的学习率是由第n次迭代时的学习率和一个幅度因子决定的, 当相邻两次迭代时的偏导数异号时, 幅度因子小于1, 反之大于1。经验结论:1≤u≤1.1, 0.91≤v≤1。
《3.3非统一抽样》
3.3非统一抽样
抽样是一种非全面的信息获取, 是指从研究对象的全体中抽取一部分单位作为样本, 根据对所抽取的样本信息进行研究, 获得有关总体目标量的了解。这是文献
在实际应用中, 为了对整体和细节同时把握, 采用多步抽样的方法来产生非统一抽样效果。首先对样本集合中所有的元素用一定数量的等概率抽样, 然后对所关注的细节特征 (整群) 进行再抽样, 甚至对于更加重要的细节特征多次抽样。对于多次抽样的数据概率统称为再抽样率。定义元素总体为nALL, 再抽样元素总体为nRE, 则再抽样率为
细节特征整群的定义以及位置的划分需要根据实际的研究对象来定。不同的再抽样率可以表达不同的估计效果, 可操作性较强。
为了引入动态高斯金字塔分析, 介绍分层随机抽样 (stratified sampling) 的概念
《3.4动态高斯金字塔分析》
3.4动态高斯金字塔分析
高斯金字塔 (Gaussian pyramid)
《图1》
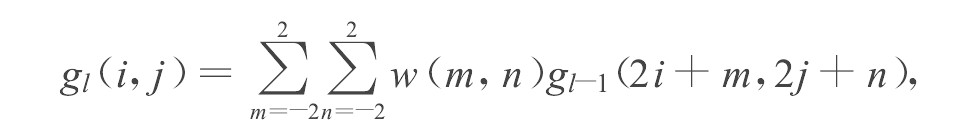
其中N表示高斯金字塔的最大级数, Cl和Rl表示第l级像素矩阵的列与行的维数, 1<l<N+1, 0≤i<Cl, 0≤j<Rl。 由于滤波窗的大小为5×5, 所以最顶2级的图像尺寸不能都小于5×5。原参考图像的维数与高斯金字塔级数的关系表示为:C=MC2N+1, R=MR2N+1, 其中MC和MR是整数。一个256×256的8 b灰度图像最高可以建立一个7级的高斯金字塔, 高一级图像是前一级图像维数的1/4, 图像的宽和高是前一级图像的一半。第7级图像尺寸是4×4像素单位。
这里采用的5×5滤波核是可分离的, 即
动态高斯金字塔 (dynamic Gaussian pyramid) 分析是结合非统一抽样技术的分层多分辨率分析方法。在迭代求精的分析过程中, 定义两种动态分析策略:
1) 建立满级高斯金字塔 即最大限度的创建高斯金字塔图像级, 例如对于N×M像素单位的参考图像可分的最大级数为nmax, 其中 (min {N, M}) 1/nmax≥5。整个多分辨率计算过程是从最高一级开始依次迭代到最低一级或者某一次低级终止。在每一级迭代前进行最优非统一抽样率的估计, 然后在该抽样率下随机抽取样本点。这就意味着非统一抽样率在不同级的分析过程中是自适应的改变和调整的。通常情况下, 由于高一级图像的分辨率低于低一级图像, 高一级迭代时的主特征再抽样率预测值也会低于低一级图像的预测值。在该分析策略中需要强调的是, 最终迭代终止的金字塔分级不一定是最高级, 因为在某些场合次于最高一级的计算结果反而优于最高级的计算结果, 产生这种差异的主要原因是观察者的主观评价与实际计算的客观评价具有非一致性。
2) 建立非满级高斯金字塔 即创建有限的高斯金字塔图像级数, 例如对于最大级数为6级的图像只创建5级或4级。整个多分辨率的计算过程是从最低一级开始迭代到最高一级终止。每一级的非统一抽样率依然是自适应的改变和调整。这种策略主要应用于图像分辨率过低以及重构图像过于光滑的情况。
《4 实验与分析》
4 实验与分析
《4.1人脸图像实验样本》
4.1人脸图像实验样本
实验中采用两种人像样本:德国Max-Planck 研究所的200幅高加索人脸图像样本
《4.2实验1 人像对准及线特征控制》
4.2实验1 人像对准及线特征控制
图2描绘了从一幅MPI的256×256的8 b灰度男性人像 (特定人像) 到一幅女性人像 (参考人像) 的对准效果, 3次实验中人脸特征线段数目与分布如表1所示。特定人像和对准人像相比, 可以明显看出整体上以及特定人脸局部的对准变换效果。例如人脸轮廓的缩小, 耳朵部分变窄, 眉毛上翘等;特定人像矢量场描述对准过程中图像像素的位移矢量分布。在实验2和实验3中, 采用了不同的特定人脸形状线段特征数目 (参见表1) 进行对准处理。实验2中, 不对耳朵部分进行特征标定, 并且在脸部轮廓靠近眼角周围去除两处线段特征的标定。实验3中, 去除额头部分的7条线段特征, 并且在耳朵轮廓处增加2条线段特征。实验显示标线部位像素位移量明显增大, 未标线部位像素位移量明显降低, 特征线段增减可有效控制人像对准效果。
《4.3实验2 线性相关性扰动下的随机梯度下降》
4.3实验2 线性相关性扰动下的随机梯度下降
实验中对原图像进行高斯金字塔分层, 对每级高斯金字塔人像随机抽样300个像素点, 采用随机梯度下降, 线性相关性扰动和学习率自适应技术进行人像重构。选择经验参数:初始化学习率a0=[1.0, 1.0, …, 1.0]N+1, 衰减因子β (n) =e-0.1n, 随机扰动振幅ε0=3.2 a0, 迭代终止阈值η, ζ=10-9, 随机数幅度δ=0.1, 学习率自适应参数1≤u≤1.1, 0.91≤v≤1
Table 1 Feature numbers of experimental face shape
《表1》
部位名称 |
脸庞 | 眼睛 | 眉毛 | 鼻子 | 嘴巴 | 耳朵 |
特征集合 |
S1 | S2 | S3 | S4 | S5 | S6 |
ni (实验1) |
14 | 8 | 4 | 3 | 2 | 6 |
ni (实验2) |
12 | 8 | 4 | 3 | 2 | 0 |
ni (实验3) |
7 | 8 | 4 | 3 | 2 | 8 |
图3显示了200幅MPI人像样本和80幅AI&R样本的库内重构效果。第一行图像是2幅MPI和2幅AI&R原图像, 第二行图像是利用本文技术产生的重构图像, 第三行图像是差图像, 显示重构图像与实际图像的灰度值差异, 差图像灰度颜色越重则差异越大。结果显示主要的重构误差集中于五官与脸庞的轮廓区域。由于线性对象模型本身是有损的, 这种误差不可避免。但是, 并不影响重构结果的主观相似度。
图4显示了人像库外新图像的重构效果。选择100幅MPI人像样本组成实验图像库1, 其他100幅为库外人像。第一列图像是原图像, 第二列图像是重构图像, 第三列图像是差图像。比较图3与图4, 结果显示库外人像重构误差大于库内人像重构。库外人像重构结果的重构误差仍然主要集中于五官与脸庞的轮廓区域。
《4.4实验3 非统一抽样与动态高斯金字塔分析》
4.4实验3 非统一抽样与动态高斯金字塔分析
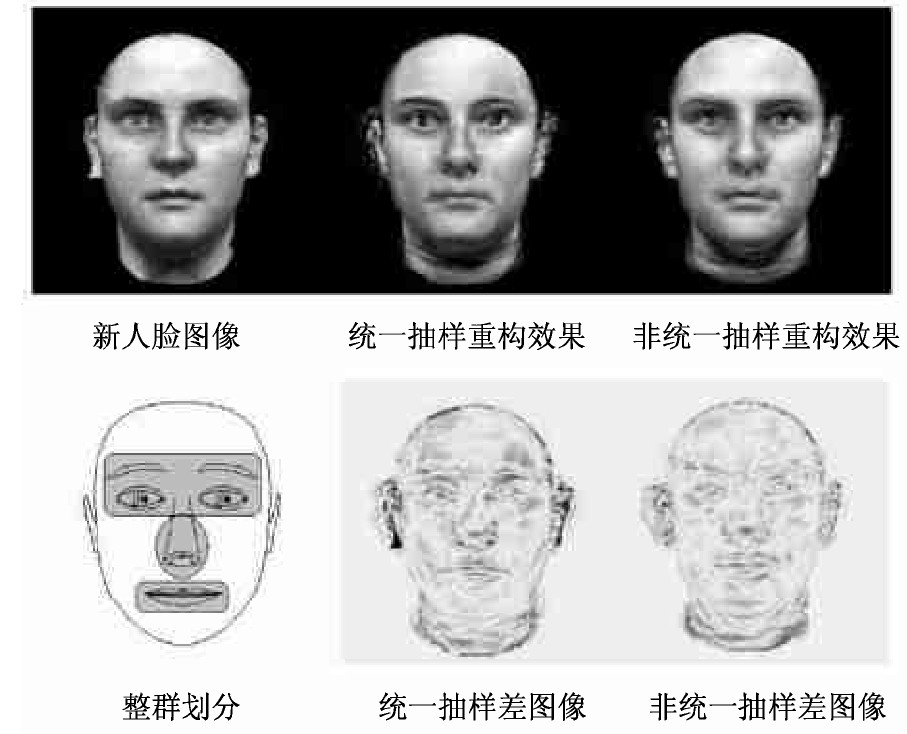
在图5的实验中, 选择100幅MPI人脸图像作为库内样本, 输入一幅数据库外的新图像, 分别利用统一抽样和非统一抽样方法对新图像进行重构, 整群区域划分在眼睛, 眉毛、嘴巴和鼻子的细节部分。将两种重构结果分别与原图像进行差运算获得差图像, 结果显示非统一抽样在整群部位的确有明显的重构改善效果 (差图像变淡) 。这种改善也直接反映在正面的主观评价中。
迭代过程中对每一幅对准样本建立6级的动态高斯金字塔, 从第1级开始动态选择300个抽样点作为估计样本, 以rrs=0.35为估计值, 并且动态的调整五官特征的再抽样率。每一级迭代结束后的准线性系数作为下一级的输入, 同时调整再抽样率和整群区域的边界坐标。为了对重构图像效果进行客观评价, 定义像素灰度值之间的平均距离差函数:
其中W表示图像宽度, H表示图像高度。DE反映出特定图像与重构图像间的相似程度。DE越小则客观的重构效果越好。
图6显示了一幅MPI库外新图像与200幅平均脸图像。图7 显示了对于图6人脸图像动态高斯金字塔分析的实验结果。其中每行结果显示一个特定再抽样率下的迭代计算过程。图7a为每一个特定再抽样率下的抽样模板, 即随机抽样点的密度分布, 图7b至图7g分别显示第6级到第1级的重建效果。迭代方向从高层到低层, 上一级迭代终止时的线性系数作为下一级的输入参数。
在主观评价实验中, 选择20位不同观察者来快速的评价出重构效果的最佳结果。如表2所示的主观评价结果, 由于所有的观察者都只选择第1至第3级的结果, 故表中只列出上述数据。其中, 100 % 认为图7f的整体效果最佳。60 % 认为再抽样率为0.6的重构图像效果普遍较好, 其他40 % 认为再抽样率为0.3的重构图像效果普遍较好。
在客观评价中, 利用公式 (20) 的平均距离差函数来计算图7中每幅重构图像与原图像 (图6) 间的相似程度。表3 显示图7中每幅重构图像与原图像间的平均距离差。
《图8》
《图9》
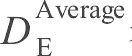
第1级到第3级的距离差平均值
《图10》
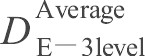
《图11》
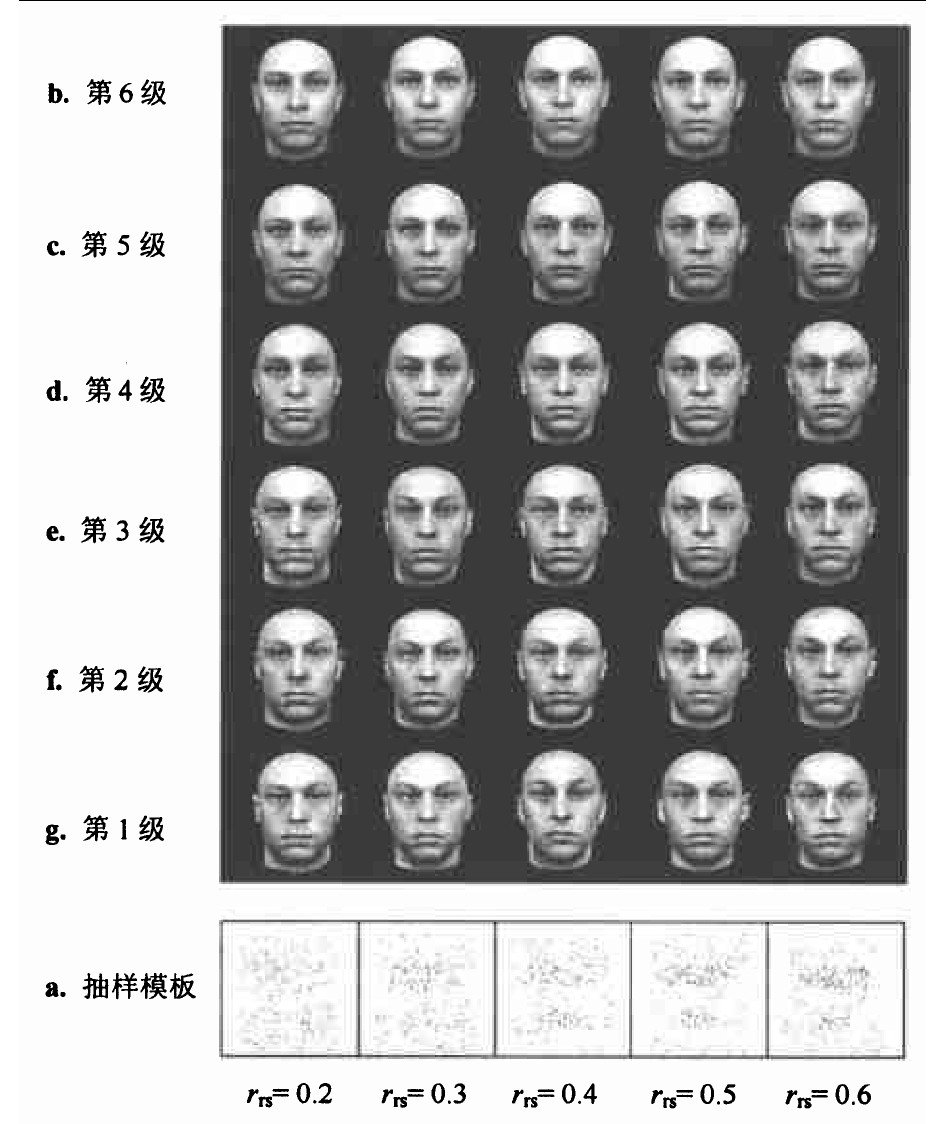
Fig.7 Comparison of the reconstructed faceimage in Fig.6 by dynamic Gaussianpyramid analysis
Table 2 Subjective quality evaluation of Fig.7
《表2》
| 第3级 | 第2级 | 第1级 | 最佳行 | ||||
rrs=0.2 |
1 | 5% | 0 | 0 | 0 | 0 | 0 |
rrs=0.3 |
3 | 15% | 2 | 10% | 8 | 40% | 40% |
rrs=0.4 |
1 | 5% | 11 | 55% | 0 | 0 | 0 |
rrs=0.5 |
11 | 55% | 1 | 5% | 0 | 0 | 0 |
rrs=0.6 |
4 | 20% | 6 | 30% | 12 | 60% | 60% |
总和 |
20 | 100% | 20 | 100% | 20 | 100% | |
最佳列 |
0 | 100% | 0 | ||||
Table 3 Average distance of reconstructions in Fig.7
《表3》
| 第6级 | 第5级 | 第4级 | 第3级 | 第2级 | 第1级 | DAverageE-3level | |
rrs=0.2 |
17.085 | 16.139 | 14.747 | 15.080 | 14.659 | 14.271 | 14.670 |
rrs=0.3 |
16.867 | 16.287 | 14.126 | 14.565 | 14.242 | 14.106 | 14.304 |
rrs=0.4 |
17.582 | 16.643 | 14.556 | 14.433 | 13.689 | 17.171 | 15.098 |
rrs=0.5 |
16.979 | 16.165 | 15.155 | 14.120 | 14.398 | 16.591 | 15.036 |
rrs=0.6 |
16.894 | 16.034 | 15.064 | 14.621 | 15.211 | 15.746 | 15.193 |
DAverageE-3level |
17.081 | 16.254 | 14.730 | 14.564 | 14.440 | 15.577 |
《图12》
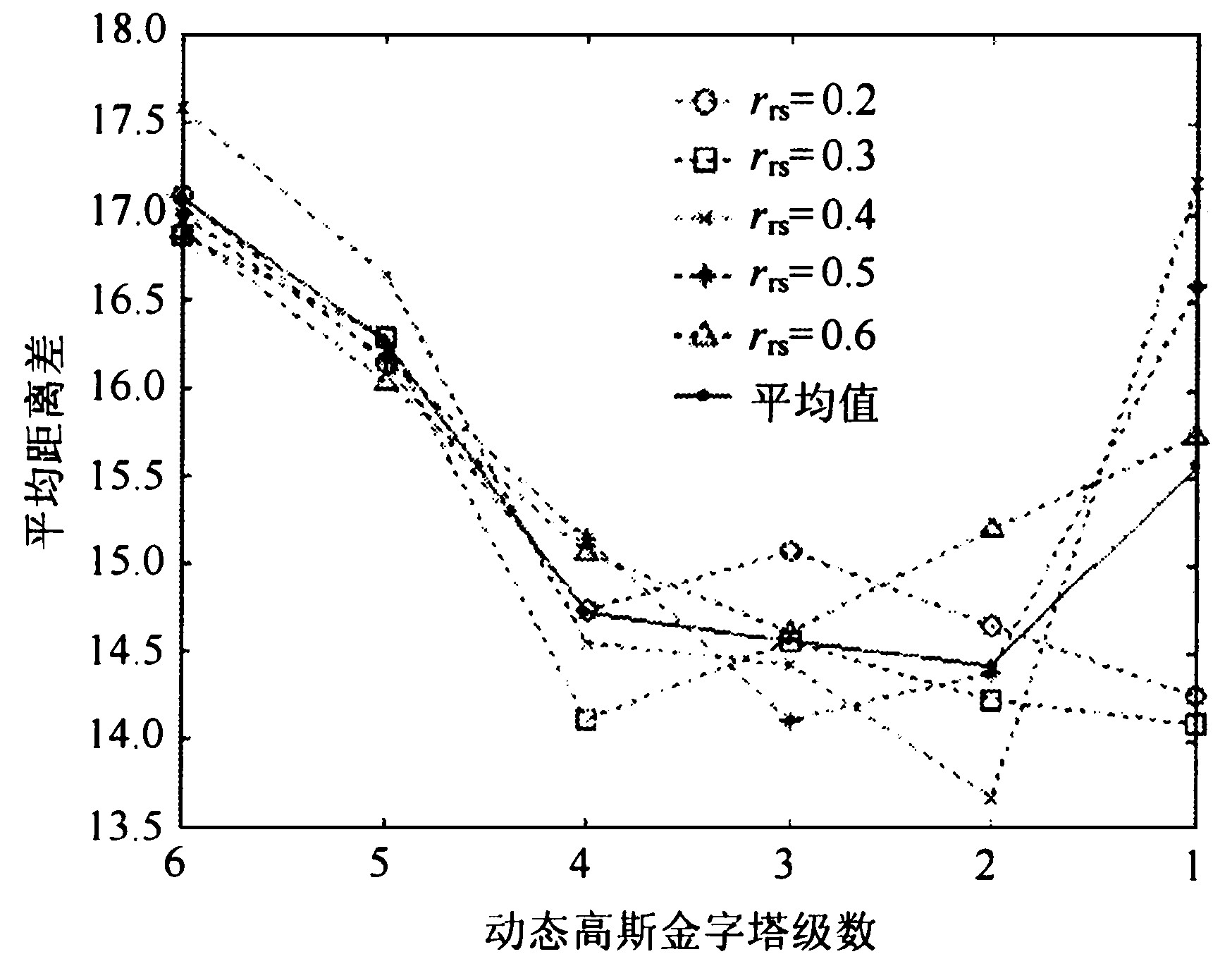
Fig.8 Average distances between reconstructed image and the original image
《5 应用》
5 应用
线性人脸对象类模型的一个有效应用就是从有限的人像信息恢复出近似完整的人脸3D视点信息。这里提出一种基于2D单输入的人像的非完整视点续变合成技术框架
《6 结论》
6 结论
笔者研究了线性人脸对象类模型的稳健建模和细节匹配控制问题, 提出了模型匹配的提升技术, 利用线性相关性扰动下的随机梯度下降算法, 配合学习率自适应方法计算全局近似最优解, 结合不等概率抽样和整群抽样技术动态调整每级高斯金字塔图像的抽样分布 (非统一抽样和动态高斯金字塔分析) 提升模型匹配鲁棒性和准确性。实验结果表明, 线性相关性扰动下的随机梯度下降算法和学习率自适应技术可以有效计算模型匹配;基于非统一抽样方法的动态高斯金字塔分析可以有效控制线性对象类细节的逼真重构效果, 主观评价与客观评价的图像重建结果相吻合。最后提出的结合模型匹配提升技术的人像非完整视点续变合成技术框架可有效应用于对象或场景立体视点变换的视频分析与合成。











 京公网安备 11010502051620号
京公网安备 11010502051620号




